“中科院系”兩家科技巨頭合併:國產算力格局要變天?_風聞
正解局-正解局官方账号-解读产业,发现价值。产业/城市/企业。23分钟前
 美國又下手了。
美國又下手了。
這兩天,國內外媒體都在報道,美國切斷部分對華半導體技術出口。
據説,這次,美國政府切斷了部分美國企業向中國出售半導體設計軟件的渠道。電子設計自動化(EDA)三巨頭Cadence、Synopsys、Siemens EDA都可能“斷供”,而這三家佔據了中國電子設計自動化市場的80%以上。
前兩年,大家還關心的是芯片製造等看得見的技術。
但現在,看不見的技術博弈,也不斷浮出水面。
最近,國內廠商也沒閒着。前幾天,國內算力產業發生了一場“地震”:海光信息要通過換股吸收合併中科曙光。
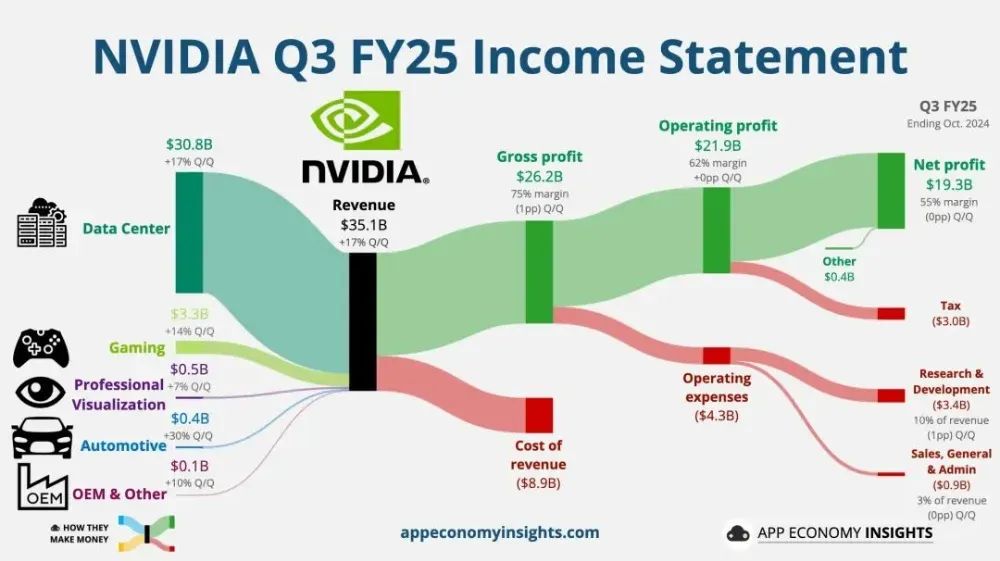
這個消息之所以這麼引發震動,是因為兩家企業都是業內的“巨頭”:海光信息是國內芯片界的頂樑柱,專攻高端CPU和AI芯片,市值3100多億;中科曙光則是服務器、雲計算領域的老牌企業,市值也有900多億。
國內廠家打響爭奪算力“生態”爭奪戰。
 目前中美算力競爭,單純比拼“硬算力”的時代正逐漸成為過去,而下一階段的競爭,焦點則聚集在了“生態”上。
目前中美算力競爭,單純比拼“硬算力”的時代正逐漸成為過去,而下一階段的競爭,焦點則聚集在了“生態”上。
先看看最近美國在算力上,對中國都幹了什麼:
5月14日,美國商務部果斷撤銷拜登政府時期擬定的《AI擴散規則》,轉而推出更為嚴苛的AI芯片出口管制新規。這一《AI擴散規則》原本就將全球劃分成三六九等,中國被無情地歸入全面禁運GPU芯片的第三等級。
然而,對於這樣的政策,英偉達CEO黃仁勳在台北國際電腦展上卻表示:美國對華人工智能芯片的出口管制,實際上“一敗塗地”。
從算力市場的份額上看,英偉達近些年在中國算是吃了大虧。
黃仁勳自己透露,在拜登政府剛開始搞AI管制那會,英偉達在中國市場那可是“一家獨大”,份額高達95%,妥妥的行業霸主。但現在,其市場份額一路狂跌到只剩50%,幾乎攔腰斬半。
這背後的原因,正是美國的出口管制。
 黃仁勳在媒體上談美國對中國人工智能出口管制
黃仁勳在媒體上談美國對中國人工智能出口管制
美國不讓英偉達賣先進的AI芯片給中國,中國企業轉頭就去支持本土的芯片研發。
像華為的昇騰芯片、寒武紀的思元芯片,這些國產“新星”開始嶄露頭角,迅速搶佔市場,硬生生從英偉達嘴裏分走了一半的蛋糕。
然而,市場份額的變化,並沒有從根本上改變國內對英偉達算力的依賴。
説白了,芯片不只是硬件,軟件生態才是命脈。
在這方面,英偉達的CUDA平台是個巨大的開發者生態,全球無數AI模型、深度學習框架像PyTorch、TensorFlow,都圍繞CUDA優化,國內相當部分大廠的AI系統也大多基於CUDA開發。
比如,有一個頭部大廠推AI算力服務時,經常拿英偉達的GPU集羣做賣點,比如他們提供的基於H20芯片的智算服務,直接用CUDA生態支持客户快速部署大模型。
即便部分大廠有自己的芯片,但也只是用在邊緣計算或者特定場景,真正的大模型訓練還是得靠英偉達的硬件和CUDA軟件棧。
 英偉達的觸角已經遍佈各個領域
英偉達的觸角已經遍佈各個領域
因為切換到國產芯片,比如華為的MindSpore或者寒武紀的框架,意味着要重寫代碼、重新適配,整個過程費時費力,這導致許多企業即使面對國產芯片的價格優勢,仍優先選擇英偉達的H20或B40芯片,以避免生態切換的高昂成本。
其實不只英偉達,即使是目前在AI計算上有些掉隊的英特爾,也知道全棧生態的重要性,近些年弄了個叫OneAPI的開發工具鏈,目標是“你寫一套代碼,CPU、GPU、FPGA、AI加速器都能跑”,降低開發者的遷移成本。
還有像Sovereign Cloud、AI PC、AI開發套件、Gaudi訓練平台、Edge AI解決方案等等,目的是讓你無論是搞邊緣部署、雲上訓練,還是在本地搞推理,選它家全套就能打通上下游。
説白了,它要讓客户“少折騰”,形成生態綁定。
 單從算力上看,國內不少企業在單卡算力上,下足了功夫,像華為的昇騰 920,單卡算力直接突破900 TFLOPS,性能把降級版的英偉達 H20狠狠甩在後面;壁仞、燧原也號稱訓練卡性能接近A100,但最終都因生態的短板,難以與英偉達匹敵。
單從算力上看,國內不少企業在單卡算力上,下足了功夫,像華為的昇騰 920,單卡算力直接突破900 TFLOPS,性能把降級版的英偉達 H20狠狠甩在後面;壁仞、燧原也號稱訓練卡性能接近A100,但最終都因生態的短板,難以與英偉達匹敵。
而這次海光、曙光的合併,正是國內在構建算力生態上邁出的重要一步。
為什麼這麼説?
 海光、曙光都算是中科院系企業。
海光、曙光都算是中科院系企業。
兩家企業各有所長。
海光信息在算力方面,專攻的是高端處理器,比如深算系列的DCU(數據中心計算單元,類似NVIDIA的GPU)和X86架構的CPU。這些芯片是國產算力的“心臟”,特別適合AI訓練、科學計算、數據中心這些需要超強算力的場景。
海光的設計強在性能和低功耗,比如他們的深算三號DCU,在單卡峯值算力與英偉達H20相近,但是價格要比H20便宜不少,十分適合大規模部署。
而中科曙光,則更擅長把芯片、存儲、散熱這些硬件組裝成服務器、高性能計算機,甚至是整個數據中心的解決方案。他們的強項在系統級優化,例如怎麼讓服務器跑得又快又穩定,怎麼用液冷技術給機器降温,還有怎麼把硬件和雲計算軟件搭在一起,提供從設備到服務的整套方案。
 以前,曙光的服務器和海光的芯片分屬於不同主體,這中間的“隔閡”着實不小,嚴重拖了優化的後腿。
以前,曙光的服務器和海光的芯片分屬於不同主體,這中間的“隔閡”着實不小,嚴重拖了優化的後腿。
從技術適配角度來講,海光設計芯片時,沒辦法完全針對曙光服務器的“脾性”來。服務器內部空間佈局、散熱系統設計、供電線路規劃等,都是圍繞通用芯片標準去做的,導致海光芯片的性能因過熱受限,無法發揮全部算力。
在數據交互層面,曙光服務器的數據傳輸協議和緩存機制,也是按行業常見芯片來設定的。海光芯片的數據處理節奏、帶寬需求時,就容易出現“堵車”情況,傳輸延遲增加,運算時間大幅延長,極大影響數據處理效率。
更重要的是,從供應鏈安全的角度來説,自2019年海光、曙光雙雙被美國列入實體清單,面臨芯片斷供後,二者的整合,無疑是補齊產業鏈,增強自主性的重要一環。
這兩家合併,技術上就像“心臟”和“身體”合體了,二者能自然互補。
或許能實現如華為昇騰芯片一般的“芯片設計-服務器製造-雲計算服務”全鏈條佈局。
 海光高性能國產處理器
海光高性能國產處理器
舉例來説,華為昇騰的鯤鵬CPU和泰山服務器,搭配華為雲的AI服務,能讓客户直接在雲端跑複雜的大模型,成本比用國外方案低30%-40%。
海光和曙光合並後,也可能推出一套類似的組合拳,比如用深算DCU、天闊服務器和自家的雲平台,幫客户跑AI任務,速度快,價格低,還全是國產貨,特別適合“東數西算”或者金融、電信這些對安全要求高的場景。
 在目前的中美算力博弈中,黃仁勳、蘇姿豐(AMD CEO)等“華裔軍師”給美國的策略,着實有點東方智慧的味道,像是“以柔克剛”。
在目前的中美算力博弈中,黃仁勳、蘇姿豐(AMD CEO)等“華裔軍師”給美國的策略,着實有點東方智慧的味道,像是“以柔克剛”。
他們的思路是,美國在芯片和算力上技術領先,尤其是NVIDIA、AMD的GPU,全球AI、數據中心、雲計算都離不開這些“硬通貨”。
與其用“剛性策略”,將技術捂得死死的,搞嚴格的出口管制,不如放開手腳,讓美國芯片和算力方案佔領全球市場。
這招頗有“潤物細無聲”的意思,通過市場滲透和技術鎖定,悄悄把全球算力生態綁在美國的戰車上。
而中國目前的戰略,跟美國有很大不同。總結起來更像是“高築牆,廣積糧”。
所謂“築牆”是把算力產業鏈的每個環節攥在自己手裏,比如海光信息和中科曙光的合併,就是把芯片設計(海光的DCU、CPU)和服務器製造(曙光的“天闊”系列)捏成一個整體,再加上雲計算服務,打造從芯片到系統的全鏈條。
這種整合是為了不被國外卡脖子,確保國內的AI、數據中心、政務、金融系統用上國產貨,穩住“基本盤”。
“積糧”則是猛堆產量和規模,而所謂的“積糧”,不只是堆量,還得建好“磨坊”,確保AI、雲計算這些核心場景的需求能自己説了算。同時用國內超大市場來“倒逼”積糧。
具體來説,是要求政務、電信、金融這些領域國產設備。比如,三大運營商2024年採購的服務器中,60%用國產芯片(海光、華為為主),這直接拉動海光DCU的出貨量增長50%。
而華為的昇騰910B,專為大模型優化,去年在國內推理市場份額也達到了30%。
從總體上看,在目前的算力博弈中,中國仍然是處於“守勢”。
在這一階段,海光-曙光這樣的整合,主要是把產業鏈的“硬實力”攢齊,成本降下來,性能提上去。
但要轉向戰略相持,光攢硬實力還不夠,得在“軟實力”的生態上下狠功夫。
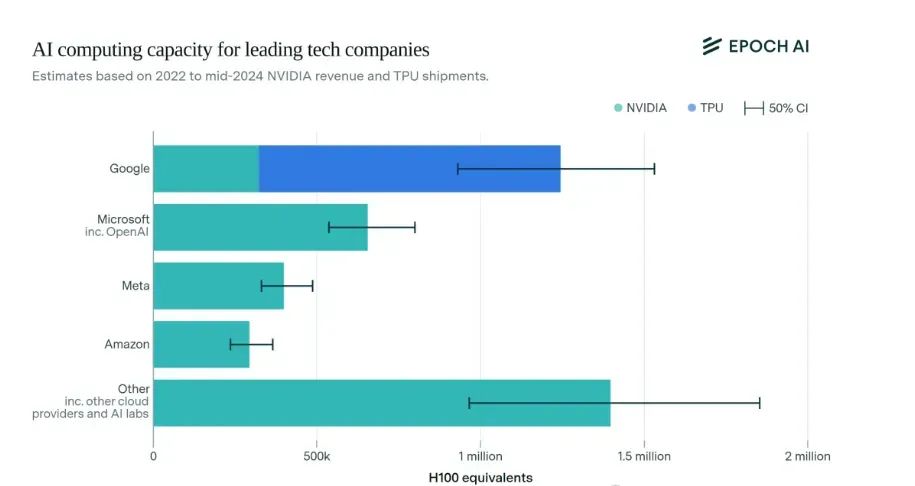 目前美國公司仍然佔據着算力霸權
目前美國公司仍然佔據着算力霸權
但生態這東西,就像一片田地,先種下的,總會有先發優勢,後者不僅要面臨時間差上的壓力,還得面臨前者本身所具有黏性的挑戰。
因此,國產企業並沒有試圖一步取代CUDA,而是先在國內“精耕細作”,用低成本和場景優勢吸引用户,再慢慢向外擴散。
2024年,國內AI框架的黏性已經初見成效,華為的MindSpore在國內的開發者社區增長了50%。
刀越磨越快。
中國廠家們也瞄準東南亞、非洲等新興市場,用低價+定製化方案搶地盤,避開NVIDIA的歐美“主場”,在實戰中不斷提升技術。
這種在夾縫裏生長的韌性,不是一夜爆發的奇蹟,而是像種樹一樣,穩紮穩打,才能慢慢長出自己的“算力森林”。