用RISC-V打造GPU?太行了_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。1小时前
圖形處理單元 (GPU) 擅長並行處理,但由於其功耗和麪積限制,以及缺乏合適的編程框架,在超低功耗邊緣設備 (TinyAI) 中仍未得到廣泛應用。
為了應對這些挑戰,本研究引入了嵌入式 GPU (e-GPU),這是一個專為 TinyAI 設備設計的開源且可配置的 RISC-V GPU 平台。其廣泛的可配置性可實現面積和功耗優化,而專用的 Tiny-OpenCL 實現則提供了一個針對資源受限環境的輕量級編程框架。
為了展示其在實際場景中的適應性,我們將 e-GPU 與可擴展異構節能平台 (XHEEP) 集成,為 TinyAI 應用實現了加速處理單元 (APU)。所提出的系統的多個實例,採用不同的 e-GPU 配置,採用台積電 (TSMC) 的 16 nm SVT CMOS 技術實現,工作頻率為 300 MHz,電壓為 0.8 V。
為了確保符合 TinyAI 的約束條件,我們對它們的面積和漏電特性進行了分析。而為了評估運行時開銷和應用級效率,我們採用了兩個基準測試:通用矩陣乘法 (GeMM) 和biosignal處理 (TinyBio) 工作負載。GeMM 基準測試用於量化 TinyOpenCL 框架引入的調度開銷。
結果表明,對於大於 256 × 256(或等效問題規模)的矩陣,延遲可以忽略不計。然後,我們使用 TinyBio 基準測試來評估基線主機的性能和能耗改進。結果表明,具有 16 個線程的高端 e-GPU 配置可實現高達 15.1 倍的加速,並將能耗降低高達 3.1 倍,同時僅產生 2.5 倍的面積開銷,並在 28 mW 的功率預算內運行。
簡介
基於機器學習的即時計算需求日益增長,推動了邊緣計算的快速發展。通過在本地處理數據而非依賴雲服務器,邊緣計算可以降低延遲、增強隱私性並提高能源效率,使其成為眾多邊緣應用的理想解決方案。然而,這些工作負載限制了計算性能、即時響應能力和功耗,因此需要專門的硬件架構。應對這些挑戰的一種有效方法是採用異構架構,將主機中央處理器 (CPU) 與特定領域的加速器集成,以平衡效率和性能。
在這些加速器中,圖形處理單元 (GPU) 已被證明在利用數據並行性進行機器學習和信號處理任務方面尤為有效。當與主機 CPU 結合使用時,GPU 可形成加速處理單元 (APU),從而實現一個統一的平台,能夠高效處理通用任務和計算密集型工作負載。
雖然存在各種 GPU 實現方案,從高性能到嵌入式解決方案,但它們在超低功耗邊緣設備(TinyAI)環境下的權衡利弊仍未得到深入研究。這些電池供電的設備在嚴格的功耗限制下運行,通常在幾十毫瓦的範圍內,因此需要高效的 GPU 架構。
它們小巧的外形也對面積造成了嚴格的限制,完整的片上系統 (SoC) 僅佔用幾平方毫米的面積。此外,由於缺乏文件系統和多線程支持,傳統的 GPU 編程框架(例如標準開放計算語言 (OpenCL) 實現)無法使用,因此需要進行自定義優化。
由於上述限制,超低功耗設備通常依賴於專用加速器,例如粗粒度可重構陣列 (CGRA:coarsegrained reconfigurable arrays )、脈動陣列(systolic arrays)以及近內存或內存計算解決方案,而 GPU 在該領域的潛力仍未被充分開發。
本研究通過引入一個開源且可配置的 RISC-V 平台——嵌入式 GPU (e-GPU),探討了將 GPU 用於 TinyAI 應用的可行性及其利弊權衡。該平台的廣泛可配置性使其能夠實現面積和功耗優化,以滿足該領域的需求。此外,一種定製的微型開放計算語言 (Tiny-OpenCL) 實現克服了上述限制,並提供了專為資源受限設備開發的輕量級編程框架。為了證明所提平台在實際場景中的適應性,我們將 e-GPU 與可擴展異構節能平台 (X-HEEP) 相結合,實現了適用於 TinyAI 工作負載的 APU。
所提出的系統的多個實例,具有不同的 e-GPU 配置,採用台積電 (TSMC) 的 16 nm SVT CMOS 技術實現,工作頻率為 300 MHz,電壓為 0.8 V。我們分析了它們的面積和漏電特性,以確保其符合 TinyAI 的約束條件。為了評估運行時開銷和應用級效率,我們採用了兩個基準測試:通用矩陣乘法 (GeMM) 和bio-signal processing (TinyBio) 工作負載。GeMM 基準測試用於量化 Tiny-OpenCL 框架引入的調度開銷,而 TinyBio 基準測試用於評估相對於基線主機的性能和能耗改進。
本研究的主要貢獻如下:
我們提倡將領域專用 GPU 作為 TinyAI 領域的合適解決方案。我們提出了 e-GPU ,這是一個專為 TinyAI 工作負載設計的開源、可配置的 RISC-V GPU 平台。我們分析了該應用領域的編程侷限性,並介紹了一個適用於資源受限設備的 Tiny-OpenCL 框架。我們探討了將 GPU 用於 TinyAI 應用的可行性及其利弊權衡。我們發佈了一個開源存儲庫,其中包含完整的 e-GPU1,以便研究人員根據其 TinyAI 領域定製該平台。
本文的其餘部分組織如下:第 2 節討論相關工作。第 3 節總結背景概念。第 4 節介紹 e-GPU 硬件,而第 5 節重點介紹 e-GPU 軟件。第 6 節解釋了與主機的集成。第 7 節概述了實驗設置,第 8 節展示了實驗結果。最後,第 9 節總結了全文。
行業最新進展
本節分析了與我們的平台設計選擇最相關的商業和學術 GPU 解決方案。
A.商用 GPU
商用邊緣 GPU 市場呈現多元化格局,各種解決方案都在平衡性能和功耗。高通的 Adreno GPU 集成在驍龍 SoC 中,為移動和邊緣應用提供高效的計算能力。尤其是 Adreno 600 系列,它廣泛用於機器學習推理,並採用了先進的節能機制。同樣,嵌入在各種 SoC 中的 ARM Mali GPU 也已發展出功耗優化的架構。MaliG52 和 Mali-G72 系列中的細粒度電源門控等創新技術提高了能效,使其適用於低功耗場景。另一個關鍵廠商,Imagination Technologies 的 PowerVR GPU,則優先考慮高能效性能,其 Series8XT 在邊緣設備中展現了極具競爭力的計算能力。
儘管取得了這些進步,但商用 GPU 並非專為 TinyAI 應用而設計。它們的功耗通常在數百毫瓦到幾瓦之間,超出了這些應用的嚴格要求,這些應用需要數十毫瓦的功率水平。此外,這些 GPU 的專有性阻礙了詳細的性能和功耗特性描述,從而限制了它們在研究和節能設計探索中的應用。
B.學術 GPU
學術 GPU 研究專注於開發適用於各種計算領域的可編程和可配置架構。表一基於以下六個基本特性比較了不同的 GPU 平台:(1) 開源代碼,方便快速訪問;(2) 開源指令集架構 (ISA),方便自定義擴展;(3) 可配置性,以適應特定應用需求;(4) 可綜合的寄存器傳輸級 (RTL) 代碼,用於精確的性能和功耗評估;(5) 可與主機 CPU 集成,用於研究 CPU-GPU 交互;以及 (6) 適用於 TinyAI 應用的超低功耗設計。
學術 GPU 解決方案涵蓋從軟件模擬器到硬件實現的各種類型。
1) 軟件模擬器
GPGPU-Sim模擬基於 CUDA 的 GPU,模擬 NVIDIA Fermi 和 GT200 等架構。gem5-gpu [14] 擴展了這一功能,集成了 gem5的 x86 CPU 和內存模型,從而促進了 CPU-GPU 交互的研究。另一個例子是 Multi2Sim [16],它模擬了 AMD Evergreen GPU 系列以及多線程 x86 處理器。
雖然軟件模擬器有助於快速探索架構,但它們對 TinyAI 研究而言存在重大侷限性,包括缺乏可綜合的 RTL 代碼(這阻礙了準確的功耗和能耗分析);缺乏開源 ISA(限制了擴展機會);以及它們主要側重於高性能計算,因此不適用於超低功耗邊緣應用。
(2)硬件實現
一些學術界的 GPU 項目提供了可綜合的 RTL 代碼,從而深入瞭解功耗和性能指標。
Skybox 是一個基於 RISC-V 的 GPU 框架,專為圖形研究而設計,並支持 Vulkan API。然而,它依賴於與主機 PC 的 PCIe 通信,因此不適合集成到通常用於超低功耗應用的 SoC 中。
ZJX-RGPU將 RISC-V CPU 和片段引擎集成到一個 12.25 mm² 的芯片中,工作頻率為 200 MHz,功耗約為 20 mW,但其閉源特性和有限的文檔限制了其在架構探索中的應用。
Vortex 作為一款支持 OpenCL 和 OpenGL 的可配置 RISC-V GPU,代表了一項重大進步。
該芯片採用 15 nm 教育單元庫,由單個計算單元綜合而成,在 300 MHz 頻率下功耗為 46.8 mW。
然而,如果不進行大量修改,其硬件無法原生綜合,而且它面向 PC 級主機環境。這些特性阻礙了它集成到 SoC 中,而輕量級互連和緊密的軟硬件耦合對於超低功耗應用至關重要。
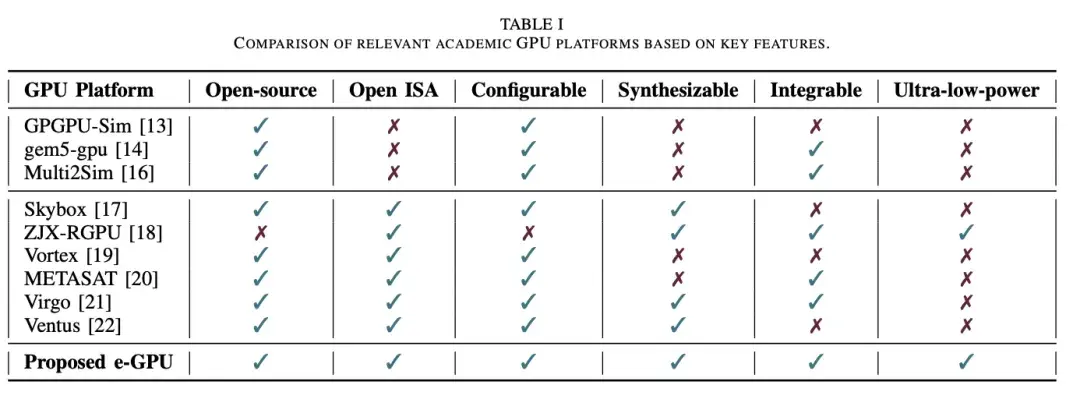 METASAT 平台將 Vortex 適配至安全關鍵型 RISC-V SoC,並將其與 NOEL-V 處理器和 SPARROW 單指令多數據 (SIMD) 加速器集成。該平台設計為在 RTEMS 和 XtratuM 虛擬機管理程序下運行,消除了對 OpenCL 的依賴,並支持在分區即時環境中使用 GPU。然而,其 GPU 繼承了 Vortex 的侷限性,僅作為將 GPU 集成到未來空間系統的概念驗證,而非 TinyAI 計算的解決方案,因為 TinyAI 計算的能源效率是其首要關注點。
METASAT 平台將 Vortex 適配至安全關鍵型 RISC-V SoC,並將其與 NOEL-V 處理器和 SPARROW 單指令多數據 (SIMD) 加速器集成。該平台設計為在 RTEMS 和 XtratuM 虛擬機管理程序下運行,消除了對 OpenCL 的依賴,並支持在分區即時環境中使用 GPU。然而,其 GPU 繼承了 Vortex 的侷限性,僅作為將 GPU 集成到未來空間系統的概念驗證,而非 TinyAI 計算的解決方案,因為 TinyAI 計算的能源效率是其首要關注點。
Virgo 基於 Vortex 構建,引入了具有集羣級矩陣單元的分解式 GPU 架構,與核心耦合設計相比,提高了數據重用率並降低了能耗。雖然 Virgo 實現了高能效且完全開源,但它面向大規模 GEMM 運算和數據中心級深度學習工作負載,這限制了其在問題規模較小的 TinyAI 場景中的靈活性。此外,Virgo 依賴於相對複雜的內存層次結構和跨計算單元的複雜同步機制,這可能難以適應面積和功耗受限的極簡 SoC 設計。
Ventus 基於 RISC-V 矢量擴展 (RVV) 構建,並引入了高性能 GPGPU 架構,其中包含用於單指令多線程 (SIMT) 執行、預測分支、同步和張量運算的自定義指令。它可擴展至 16 個計算單元和 256 個 Warp,與 Vortex 相比,CPI 提升高達 87.4%,指令數減少 83.9%。然而,Ventus 專為大規模 FPGA 部署而設計,尚未集成到 SoC 中,其目標平台是 PC 級主機。雖然綜合結果報告使用了台積電 12 納米工藝庫進行頻率和麪積評估,但並未提供低功耗或流片優化。因此,Ventus 的目標客户是高吞吐量應用和架構研究,而非 TinyAI 場景。
背景
本節根據標準 OpenCL 定義總結了所需的術語。這些術語根據平台、執行和運行時模型進行組織。平台模型定義了主機系統與負責執行內核的計算設備之間的關係。執行模型描述了內核的啓動方式,以及如何在可用硬件上組織和執行工作項和工作組。最後,運行時模型指定了內核在硬件級別的執行行為,包括線程調度、同步和執行資源的利用率。
A.平台模型
在平台模型中,主機是指運行 OpenCL 主機代碼的主系統,通常為 CPU,負責管理和調度跨計算設備的內核執行。設備是指執行 OpenCL 內核的加速器,例如 GPU。每個設備由一個或多個計算單元組成,這些計算單元是負責執行工作組的架構模塊。計算單元內包含多個處理單元,它們是最低級別的執行資源,執行工作項的算術和邏輯運算。
B.執行模型
執行模型控制計算的組織和啓動方式。主機代碼從主機端協調執行過程,向設備發出命令並管理數據傳輸。內核是在計算設備上運行的 OpenCL 函數,由多個工作項並行執行。每個工作項對應一個內核執行實例,並對輸入數據的不同部分進行操作,該部分由唯一的全局 ID 標識。工作項被分組到工作組中,並分配給計算單元。組內的工作項可以通過本地內存共享數據,並使用屏障相互同步。全局大小指定要啓動的工作項總數,而本地大小則決定每個工作組中有多少個工作項。
C.運行時模型
運行時模型描述了內核在硬件層面的執行方式。線程表示在處理單元上運行的內核實例,維護其自己的私有寄存器集。線程通常被分組到 Warp 中,Warp 是同步執行的線程集,這意味着它們共享相同的程序計數器並同時執行相同的指令。根據硬件功能,多個 Warp 可以在流水線中同時處於活動狀態,從而實現細粒度的並行性和對執行資源的高效利用。
e-GPU 硬件
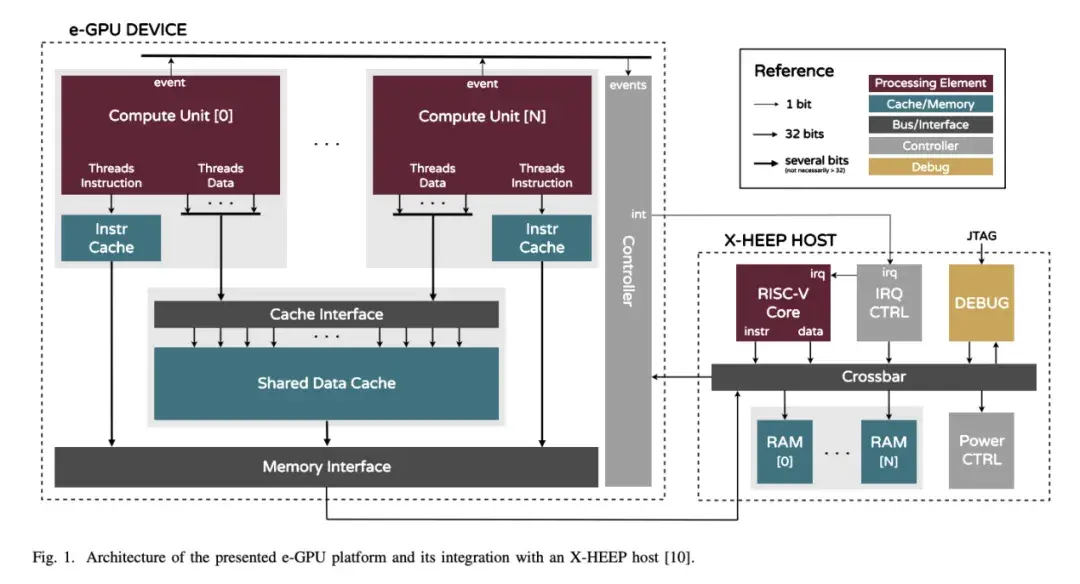
本節介紹 e-GPU 架構及其軟硬件協同設計決策,旨在最大限度地減少面積、功耗和能耗,同時使平台適應 TinyAI 領域。圖 1 展示了擬議 e-GPU 的架構,表 II 列出了可通過 SystemVerilog 參數訪問的可配置旋鈕。
A.計算單元
計算單元基於 Vortex 內核。它採用亂序 RISC-V 架構,並具有內部可配置選項,允許調整並行線程和併發 Warp。調整線程數量可以通過改變處理單元的數量來修改數據並行性,而配置 Warp 數量則可以通過細粒度多線程併發執行多個 Warp,從而提高資源和內存帶寬利用率。
由於功耗和麪積限制,我們移除了浮點單元,優先執行整數和定點運算,因為該平台的目標是基於整數的 TinyAI 模型。此外,我們還擴展了 RISC-V ISA,添加了自定義的 SLEEP REQ 指令,以提高能效。在內核處理結束時,該指令會等待所有先前獲取的指令執行完畢,然後向 GPU 控制器生成事件,以指示操作完成。此機制使 GPU 控制器能夠在計算單元不再使用時,通過時鐘或電源門控(如果可用)將其關閉,從而提高整體能效。在設計時,可以根據面積、功耗和處理需求進行配置。
B.內存層級
內存層級採用統一架構,其中主機主內存和 e-GPU 全局內存映射到主機上的同一物理內存。這種共享內存模型無需在不同的內存區域之間進行顯式數據傳輸,從而增強了可編程性。特別是,在主機主內存和 e-GPU 全局內存之間移動輸入和輸出數據時,不再需要複雜的顯式雙緩衝方案。
每個計算單元都包含一個私有指令緩存,以減少內存訪問延遲並提高性能,而跨計算單元使用共享數據緩存。
緩存邏輯基於 Vortex 緩存,並採用直接映射、多存儲體架構和行交錯尋址方案。即使前一個 Warp 因緩存未命中而停滯,對未完成請求的支持也允許後續 Warp 發出新的緩存訪問。在設計時,可以根據目標應用程序的具體需求調整緩存大小、存儲體數量和行大小。我們集成了專用的內存包裝器,以便為每個指令庫無縫實例化生產級 SRAM 宏。
每個計算單元都連接到一個私有指令緩存。當多個計算單元執行同一個內核時,這種設計可以提高計算單元數量增加時的可擴展性,並避免共享指令緩存可能產生的衝突。事實上,無法保證每個計算單元在每個時鐘週期都獲取相同的指令。因此,擁有獨立的私有指令緩存有助於減少未命中並減輕性能下降。此外,當不同的計算單元執行不同的內核時,獨立的緩存可以提高局部性。
在數據方面,所有計算單元共享一個公共數據緩存。這種設計在主機較慢的主存儲器和計算單元較快的寄存器文件之間提供了一箇中間存儲層,從而提高了數據訪問效率。此外,使用共享緩存可以在計算單元之間直接共享數據,而無需與主機主存儲器進行額外的數據傳輸。
輸入數據在第一個內核開始時從主機加載到共享數據緩存中,並在中間內核的整個執行過程中保持可用狀態(假設緩存足夠大,可以容納整個工作集)。這種方法通過最大限度地減少數據傳輸來提高性能,最終提高能效。
最後,我們重新設計了數據緩存接口,以支持所有計算單元並行發出的多線程請求。每個計算單元同時發出多個請求,每個活動線程一個,但會收到一個統一的響應。輸入和輸出數據會根據請求線程進行選擇性屏蔽。這種對多維請求的支持,通過在未發生存儲體衝突的情況下實現對共享緩存的併發訪問,提高了帶寬利用率。
在系統邊界,內存接口能夠有效地將緩存請求調整到主機內存事務。這些事務的管理分為三個步驟。(1) 發生未命中時,緩存請求整條多字線,然後將其序列化為單獨的 32 位事務(transactions)。 (2)緩存協議被轉換為OBI 協議,這是一種在邊緣系統中廣泛採用的低功耗總線協議。(3)仲裁器(arbiter)管理對共享輸出端口的訪問,確保公平高效的資源分配。
C.控制器
我們設計了一個專用控制器來管理 e-GPU 的操作。一組內存映射的配置寄存器支持諸如重置、啓動和停止加速器等操作。此外,該控制器集成了一個電源控制器,該控制器與第四章 A 節中描述的低功耗 RISC-V 擴展協同工作。內核啓動後,電源控制器會監控每個計算單元的執行結束事件。一旦收到事件,相應的計算單元就會關閉電源。一旦收到所有事件,表明所有計算單元都已完成執行,控制器就會生成外部中斷通知主機 CPU。
e-GPU 軟件
本節介紹 Tiny-OpenCL 框架,這是一個輕量級且高度優化的 OpenCL 實現,旨在編譯可在 e-GPU 上執行的內核。該框架最大限度地提高了與現有 GPU 軟件的兼容性,同時確保了跨平台的可移植性。
 A.Tiny-OpenCL 框架
A.Tiny-OpenCL 框架
該框架包含以下軟件組件:(1) SIMT RISC-V 擴展 API ,用於訪問底層計算單元功能,例如激活和停用線程和 Warp、通過拆分和合並處理分歧以及管理同步屏障;(2) 啓動函數,負責初始化 e-GPU 並執行必要的設置操作,包括計算每個線程的堆棧指針;(3) 調度函數,用於協調可用計算資源(計算單元、線程和 Warp)中工作項的執行,確保高效的工作負載分配。這些組件使用標準 RISC-V GNU 工具鏈預編譯為靜態庫。
隨後,解析器腳本對 OpenCL 內核進行分析,執行必要的代碼轉換,將其轉換為具有等效功能的標準 C 函數。然後,可以使用 RISCV GNU 工具鏈編譯此 C 函數,生成相應的目標文件。這些轉換可以與現有的編譯工具無縫集成,無需專用的編譯器。內核處理和編譯完成後,會與 Tiny-OpenCL 靜態庫鏈接,生成最終的二進制文件。
在內核地址空間中,保留了一塊內存區域用於存放內核參數,這些參數由主機在執行前寫入。這些參數包括執行參數,例如全局和本地大小、指向輸入和輸出緩衝區的指針以及其他配置細節。
為了增強靈活性,該框架允許用户自定義表 II 中列出的參數。這些參數包括內核的基地址,該基地址用作 e-GPU 的啓動地址,並允許執行位於系統內任意地址偏移量的內核。此外,還可以配置線程堆棧的位置和大小,以確保根據目標應用程序的特定需求進行正確的映射和大小調整。
B.Tiny-OpenCL 執行
OpenCL 運行時(如第 VI-C 節所述,在主機上運行)啓動 e-GPU 加速後,內核執行開始,並經歷三個階段:啓動、調度和處理。在啓動階段,每個計算單元以單線程模式執行,這意味着只有一個線程和一個 Warp 處於活動狀態。在此階段,將執行啓動函數以初始化系統。這包括激活所有並行線程和併發 Warp,併為每個線程和 Warp 設置堆棧指針等資源。初始化完成後,計算單元將返回單線程模式,然後開始調度階段。在調度階段,將調用調度函數。這些函數從內核參數區域讀取全局和本地大小,以確定工作組的數量以及每個工作組的工作項數量。這些值將與從控制和狀態寄存器 (CSR) 檢索的硬件資源信息(計算單元、線程和 Warp)相結合。基於這些數據,調度函數會激活必要的資源,並將工作項分配到可用線程中,以最大限度地提高並行度並最大限度地縮短執行時間。此外,它們還會停用未使用的資源,以降低功耗並提高整體能效。
 一旦工作項在線程上啓動,處理階段就開始了。在此階段,用户定義的內核將執行目標算法。輸入和輸出參數從內核參數區域獲取,工作項會根據其全局 ID(可以表示為一維或二維索引)計算其特定的數據部分。由於調度函數會預先執行邊界檢查,因此用户內核無需處理此類邏輯。
一旦工作項在線程上啓動,處理階段就開始了。在此階段,用户定義的內核將執行目標算法。輸入和輸出參數從內核參數區域獲取,工作項會根據其全局 ID(可以表示為一維或二維索引)計算其特定的數據部分。由於調度函數會預先執行邊界檢查,因此用户內核無需處理此類邏輯。
APU 系統
本節介紹如何將 e-GPU 與主機集成,以實現 TinyAI 應用的 APU。本節首先詳細介紹 e-GPU 接口,然後介紹所選的主機系統及其配置。最後,介紹一個輕量級的主機端 Tiny-OpenCL 運行時,旨在克服資源受限設備固有的編程限制。
A.e-GPU 接口
e-GPU 公開以下端口:(1) 用於配置的從 OBI 端口;(2) 用於從主機主內存讀寫內核指令和數據的主 OBI 端口;以及 (3) 連接到主機中斷控制器的中斷線,該中斷線會在內核完成時通知 CPU。
e-GPU 在專用電源域內運行,可實現精細的電源管理。時鐘門控可在短暫空閒期間降低功耗,而電源門控可在長時間不活動期間完全關閉加速器。這些機制的控制信號連接到主機電源管理器,從而確保高效且自主的能源管理。
B.主機配置
X-HEEP 系統因其可配置和可擴展的架構而被選為平台的主機,這有助於加速器集成。所選配置包括:(1) 一個輕量級 CPU ,針對執行控制任務進行了優化,同時將性能密集型計算卸載到加速器,確保低功耗;(2) 兩個 32 KiB 的 SRAM 組,配置為連續尋址模式,為 CPU 和加速器提供獨立的內存分配,並減少訪問衝突;(3) 一個完全連接的交叉開關,提供高帶寬數據傳輸能力;(4) 一箇中斷控制器,用於管理內部和外部中斷;(5) 一個電源控制器,負責管理內部和外部節能策略,包括時鐘門控和電源門控;(6) 一個調試單元,用於通過 JTAG 實現完整的系統控制;(7)可擴展加速器接口 (XAIF),配置一個 OBI 主接口、一個 OBI 從接口和一箇中斷接口,用於連接 e-GPU 的相應端口。圖 1 展示了連接的細節。
C.Tiny-OpenCL 運行時
標準的開源 OpenCL 實現(例如 PoCL)需要能夠運行操作系統的主機來支持其運行時,該運行時負責與加速器交互並控制加速器。然而,X-HEEP 是一款 RISC-V 微控制器,缺乏運行 Linux 等操作系統所需的 ISA 支持。因此,它依賴於 Newlib,這是一個針對邊緣系統優化的開源 C 標準庫,它提供了一整套基本功能,包括 I/O、內存和字符串實用程序,通常在缺乏支持文件系統和多線程的完整操作系統時使用。
由於缺乏文件系統,主機應用程序必須編譯為單個二進制文件,從而無需進行動態庫鏈接。同樣,由於缺乏多線程,主機應用程序只能在單線程中執行。為了克服這些限制,第五節介紹的 Tiny-OpenCL 框架擴展了一個專用運行時,該運行時專為支持 Newlib 的微控制器(例如 X-HEEP)設計。該運行時使用標準 GNU RISC-V 工具鏈編譯,並實現了標準 OpenCL 運行時 API 的一個子集。這些函數提供從主機對 e-GPU 的完全控制,包括初始化數據緩衝區、配置內核參數、內核調度以及通過等待操作完成來實現同步。
實驗設置
本節介紹我們實驗中所選用的 e-GPU 配置。然後,介紹所採用的基準測試,這些基準測試旨在證明所提出的平台能夠滿足 TinyAI 代表性應用領域——生物信號處理——的嚴格要求。隨後,本節詳細介紹了我們系統的實現,並描述了用於提取性能、功耗和麪積指標的方法。
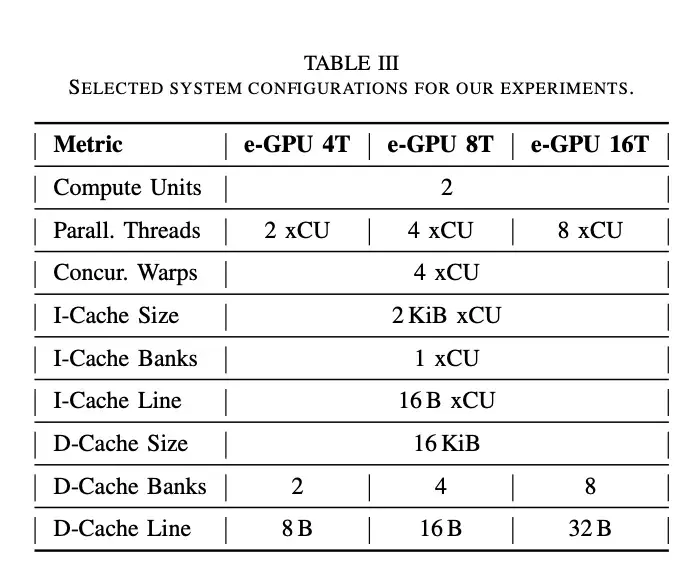
A.e-GPU 配置
表三總結了所選的配置。每個實例包含兩個計算單元,並行線程數量不斷增加,每個計算單元從 2 到 8 個不等。此設置可提供足夠的性能來執行內核,同時保持面積和功耗之間的平衡。為了降低內存訪問延遲,每個計算單元配備了四個併發 Warp。鑑於共享數據緩存的訪問延遲為四個週期,此配置允許緩存流水線被四個未完成的請求填充,從而實現每個週期一次訪問的最大吞吐量。
指令緩存採用單存儲體配置。這種佈局節省面積和功耗,有助於提高整體能效。16 B 的指令行大小(四條指令)可最大限度地提高空間局部性並增強內核代碼的預取,而 4 KiB(每個計算單元 2 KiB)的總指令緩存大小可確保我們基準測試的每個內核都能適應。
共享數據緩存採用多存儲體配置,並採用行交錯尋址。它包含兩個存儲體,每個計算單元一個,以最大限度地提高並行訪問效率。行大小設置為 T x 4 B,其中 T 表示每個計算單元的並行線程數。這種設計允許所有線程在訪問連續內存位置時同時讀取數據,因為一次緩存行讀取就足夠了。最後,總數據緩存大小為 16 KiB,用於容納所需的內核數據,從而最大限度地減少緩存與主機主內存之間的流量。
B.基準測試
我們採用了兩個基準測試:GeMM 和 TinyBio 工作負載。GeMM 基準測試包含大小遞增的通用矩陣乘法核,範圍從 32 × 32 到 256 × 256。相比之下,TinyBio 領域包含專門用於分析從人體獲取的生物信號並提取有意義特徵的核 。其中,我們選擇了 MBio-Tracker 應用程序 ,它是專門為測量認知工作負載而開發的。該應用程序具有四個階段的流水線:預處理、描繪、特徵提取和預測。這些異構核融合了各種複雜度和內存需求各不相同的算法,使其成為我們實驗的理想選擇。在預處理過程中,對原始輸入數據應用有限脈衝響應 (FIR) 濾波器。在描繪階段,識別濾波信號的波峯和波谷,以確定吸氣和呼氣時間。然後使用提取的值計算時域特徵,例如平均值、中值和均方根 (RMS),而通過對濾波信號執行 Stockham 快速傅里葉變換 (FFT) 來獲得頻域特徵。最後,使用支持向量機 (SVM) 算法來估計認知工作量。
C.方法論
每個系統均採用台積電 (TSMC) 的 16 nm FinFETSVT CMOS 技術進行綜合,工作頻率為 300 MHz,電壓為 0.8 V。綜合後進行仿真,提取開關活動進行功耗分析。這些數據隨後用於估算功耗。
 實驗結果
實驗結果
本節介紹並分析了我們的實驗結果。首先對每個系統進行靜態特性描述,然後分析使用 e-GPU 的相關開銷。接下來,我們介紹 TinyBio 基準測試的特性描述。最後,我們進行總體討論,重點探討如何有效利用每個系統。
A.靜態特性描述
圖 2 顯示了所分析系統面積的細分。e-GPU 系統的總面積從 0.24 平方毫米到 0.38 平方毫米不等。這些結果證明了所提出的系統在 TinyAI 應用中部署的可行性,因為目標設備的小尺寸對面積有着嚴格的限制,整個 SoC 通常只有幾平方毫米。此外,e-GPU 的面積開銷僅為獨立主機系統(佔用 0.15 平方毫米)的 1.6 到 2.5 倍,而運行 TinyBio 基準測試時,其速度提升高達 3.6 到 15.1 倍,如圖 4 所示。
分解總面積的貢獻後,指令緩存在所有 e-GPU 配置中保持不變。這是預料之中的,因為在增加線程數和性能時,指令緩存不會進行修改或擴展。
相比之下,數據緩存的面積略有增加,儘管其總容量在不同配置之間保持不變。這種增加源於內存層次結構的調整,旨在在更高並行度(即更高線程數)下最大化內存訪問帶寬。具體而言,需要更多緩存端口(每個線程一個端口)和更大的緩存行(每個線程一個字)。更大的線尺寸是通過增加bank數量來實現的:4線程e-GPU使用兩個bank,8線程版本使用四個bank,16線程版本使用八個bank。相比於使用相同總尺寸的單個bank,拆分成多個子bank的面積效率較低。
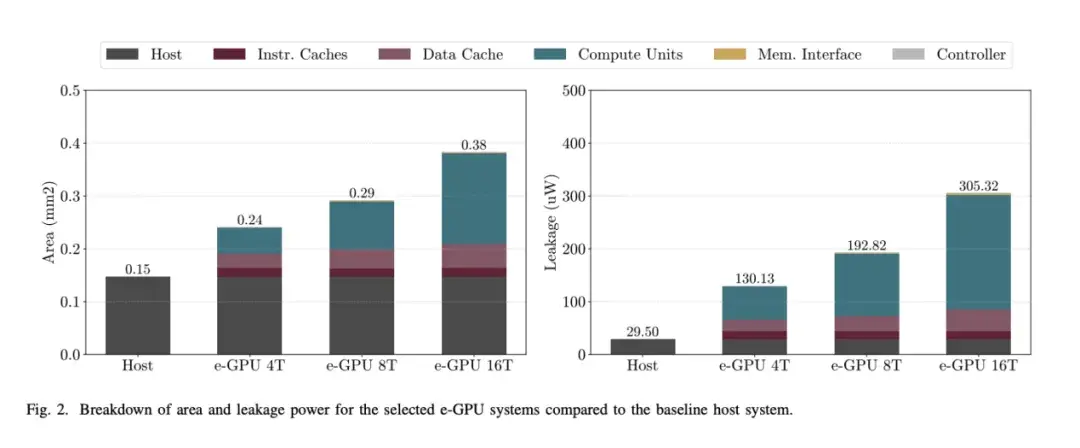 最後,隨着性能配置的提升,計算單元的面積顯著增加,其貢獻也幾乎翻了一番。這種增長反映了集成更多資源的需求,例如更多運算單元、更大的寄存器文件和擴展的控制邏輯,以便高效地支持更多並行線程。
最後,隨着性能配置的提升,計算單元的面積顯著增加,其貢獻也幾乎翻了一番。這種增長反映了集成更多資源的需求,例如更多運算單元、更大的寄存器文件和擴展的控制邏輯,以便高效地支持更多並行線程。
如圖 2 所示,分析漏電功耗時也觀察到了類似的趨勢。e-GPU 系統的漏電功耗範圍為 130.13 µW 至 305.32 µW,與功耗為 29.50 µW 的獨立主機系統相比,其開銷是前者的 4.4 倍至 10.3 倍。這進一步證明了所提設計對於 TinyAI 應用的適用性,因為此類應用的電池供電設備必須遵守嚴格的功耗預算,通常在數十毫瓦的量級。
總體而言,面積和泄漏分析一致表明,最顯著的變化集中在計算單元內部,而除數據緩存中的適度調整外,緩存保持相對穩定。這些結果凸顯了所提出的 e-GPU 架構的可擴展性,證實了其能夠在嚴格的 TinyAI 部署約束下有效地權衡面積和泄漏開銷,從而實現顯著的性能提升,如圖 4 所示。
B.開銷特性
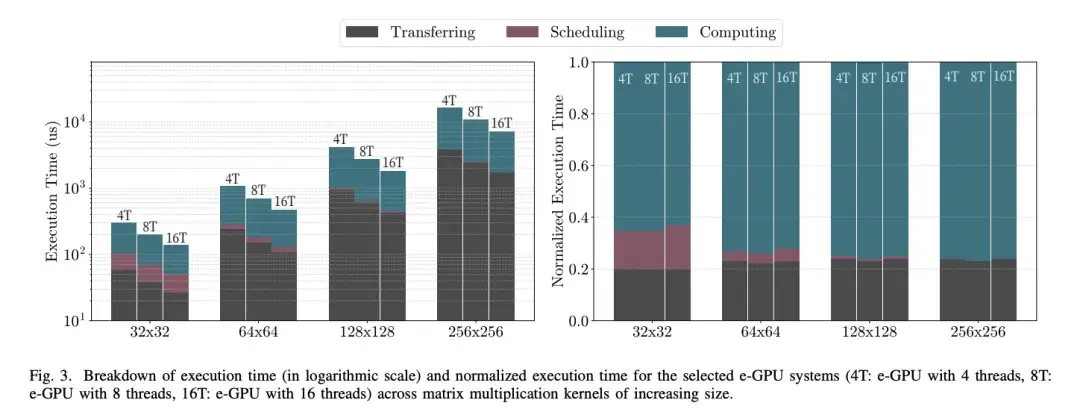
圖 3 展示了在所選 e-GPU 系統上執行的矩陣乘法的開銷與計算時間的細分,矩陣乘法的規模隨時間遞增。
開銷分為兩種類型:傳輸和調度。傳輸是指用內核數據填充數據緩存所花費的時間。這發生在內核執行之前,數據從主機內存移動到 e-GPU 緩存,帶寬為 32 位/週期。假設緩存足夠大,可以容納整個工作集,則傳輸的數據將在後續的內核執行過程中保持駐留,從而提高性能和能效。由於需要傳輸的數據越來越多,因此傳輸延遲會隨着矩陣規模的增大而增加,對於高端 e-GPU 系統,傳輸延遲從大約 27 µs 增加到 1.7 ms。
在矩陣大小固定的情況下,使用更多並行線程來提升性能會略微減少傳輸時間。這可以歸因於逐漸增大的緩存行,這使得每次讀取未命中時可以將更多數據預取到數據緩存中。因此,計算和數據傳輸之間的重疊會增加,從而減少僅用於數據移動的時間比例。
總體而言,傳輸開銷在不同矩陣大小下穩定在執行時間的 20% 以上,因為傳輸時間的增加會被性能逐步提升帶來的計算延遲的減少所抵消。
與傳輸互補的是,調度表示分配計算資源併為其指派工作項所需的時間。e-GPU 依賴於第五節中描述的 Tiny-OpenCL 框架提供的運行時調度。隨着工作項數量的增加,這種開銷會變得更加明顯,因為必須對可用資源執行更多迭代。
在我們的實驗中,我們配置了矩陣乘法內核,使工作項數量與可用線程數(計算單元 × 併發 Warp × 並行線程)匹配。這種方法優化了調度時間並提升了內核的整體性能。因此,無論系統性能或矩陣規模如何增加,調度時間都保持在約 25 µs 的恆定水平。
然而,隨着問題規模的增加,其對總執行時間的相對貢獻會從約 15% 降至不到 1%。這證明了所提出的 Tiny-OpenCL 框架的可行性,它提供了高度的靈活性和改進的可編程性,並且對於大於 256 × 256(或同等問題規模)的矩陣,其開銷幾乎可以忽略不計。
C.TinyBio 基準測試特性
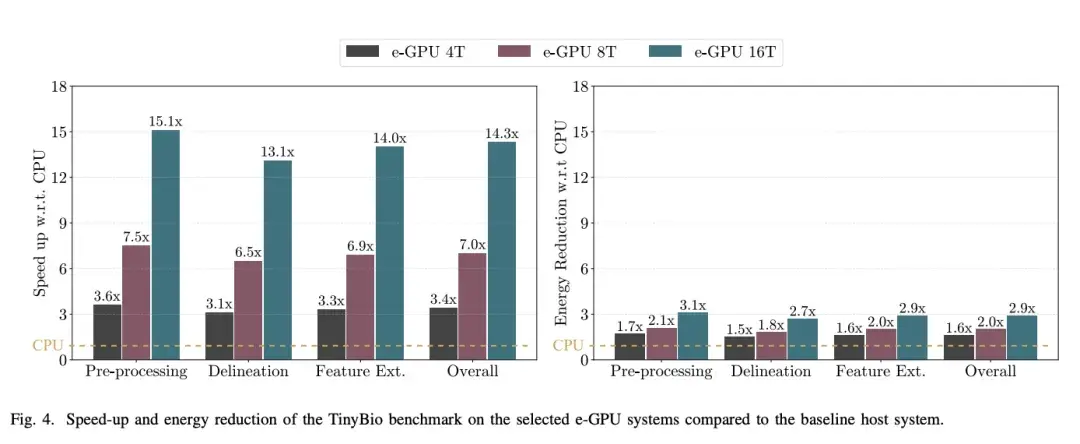
圖 4 展示了第 VII-B 節中描述的 TinyBio 基準測試的每個內核在所分析的 e-GPU 系統上執行時,相對於基準主機系統所實現的加速和能耗降低情況。
 在預處理階段,執行 FIR 濾波器。該算法高度可並行化,因為每個輸出樣本可以獨立計算,從而允許多個線程同時處理不同的樣本。計算涉及固定數量的乘法累加運算,這些運算可以高效地映射到 e-GPU 的處理單元。此外,FIR 濾波器表現出規則且連續的內存訪問模式,增強了局部性並實現了高效的合併內存訪問,從而最大限度地降低了延遲並最大限度地提高了帶寬利用率。
在預處理階段,執行 FIR 濾波器。該算法高度可並行化,因為每個輸出樣本可以獨立計算,從而允許多個線程同時處理不同的樣本。計算涉及固定數量的乘法累加運算,這些運算可以高效地映射到 e-GPU 的處理單元。此外,FIR 濾波器表現出規則且連續的內存訪問模式,增強了局部性並實現了高效的合併內存訪問,從而最大限度地降低了延遲並最大限度地提高了帶寬利用率。
得益於這些有利特性,e-GPU 系統相對於主機系統實現了 3.6 倍到 15.1 倍的加速,從而將能耗降低了 1.7 倍到 3.1 倍。
相比之下,描繪階段的特點是使用控制密集型算法來檢測局部最大值和最小值。此工作負載僅部分可並行化,無法充分利用 e-GPU 的功能。此外,GPU 並未針對涉及頻繁分支的控制主導代碼進行優化,這些代碼使用線程屏蔽將不同的執行路徑序列化,從而降低了並行效率。
儘管存在這些限制,e-GPU 系統在主機上仍實現了 3.1 倍至 13.1 倍的速度提升,同時能耗降低了 1.5 倍至 2.7 倍。
在特徵提取階段,執行 Stockham FFT 算法。與傳統的 Cooley-Tukey FFT 不同,Stockham FFT 通過在每個階段重新排序數據,消除了單獨的位反轉置換的需要。它採用雙緩衝(乒乓)方案,在兩個數組之間交替存儲中間結果。在每個 log2 (N) 階段,它都通過常規和順序內存訪問執行獨立的蝶形運算,這使得它特別適合並行架構。計算結束時,輸出數據已經處於正確的順序,無需顯式的最終置換步驟。
然而,此階段的主要限制在於需要順序階段之間的同步,這降低了可用的並行度並限制了整體性能。儘管如此,e-GPU 系統仍實現了 3.3 倍至 14.0 倍的速度提升,同時能耗降低了 1.6 倍至 2.9 倍。
總體而言,從完整的應用角度考慮,eGPU 系統在處理階段實現了 3.4 倍至 14.3 倍的整體性能提升,同時能耗降低了 1.6 倍至 2.9 倍。
D.總體討論
評估系統的特性凸顯了在為 TinyAI 應用設計或選擇平台時必須考慮的關鍵權衡因素。
基準主機系統複雜度最低,非常適合計算需求適中且資源限制嚴格的場景。其輕量級設計確保了最小的面積和功耗,這對於能源供應嚴重受限的應用(例如電池供電的邊緣設備)至關重要。然而,這些優勢是以犧牲計算能力為代價的。主機 CPU 難以高效地處理更密集的 TinyAI 工作負載,導致執行時間延長,從而導致總體能耗增加。隨着 TinyAI 應用越來越需要更強大的處理能力來支持更復雜的模型和數據分析,基準主機 CPU 在這些用例中的適用性越來越差。
相比之下,與主機系統相比,e-GPU 系統在面積和漏電方面都引入了適度的開銷。然而,這些額外的成本被性能和能效的顯著提升所抵消。 e-GPU 的加速比可達 3.6 倍至 15.1 倍,能耗比則為 1.7 倍至 3.1 倍。這些改進對於 TinyAI 應用尤其重要,因為這些應用需要處理密集型數據,但仍必須在有限的面積和功耗預算內運行。儘管由於 SIMT 架構在管理不同分支時固有的低效率,控制密集型工作負載對 e-GPU 來説仍然更具挑戰性,但該系統能夠有效地處理此類情況,從而保持性能和能效。
總體而言,e-GPU 系統是 TinyAI 應用的高效且多功能的解決方案。其架構成功地平衡了計算吞吐量、能效和靈活性,解決了資源受限環境中面臨的關鍵挑戰。通過顯著提升性能並降低能耗,同時保持適中的面積和功耗,e-GPU 滿足了現代 TinyAI 工作負載的嚴格要求。
 結論
結論
對即時機器學習計算日益增長的需求加速了邊緣計算的採用,本地數據處理可以增強延遲、隱私和能效。然而,這些工作負載對計算性能、面積和功耗施加了嚴格的限制,因此需要專門的硬件解決方案。在現有的加速器中,GPU 在利用數據並行性進行機器學習和信號處理任務方面具有強大的潛力。然而,它們在 TinyAI 設備環境中的利弊權衡在很大程度上尚未得到探索。
為了應對這些挑戰,本研究引入了 eGPU,這是一個專為 TinyAI 應用設計的開源且可配置的 RISC-V GPU 平台。其廣泛的可配置性可實現細粒度的面積和功耗優化,而專用的 Tiny-OpenCL 框架則提供了一個專為資源受限環境量身定製的輕量級靈活編程模型。
e-GPU 與 X-HEEP 主機集成,以實現針對 TinyAI 應用優化的 APU。所提出的系統的多個實例具有不同的 e-GPU 配置,採用台積電 (TSMC) 16 nm SVT CMOS 技術實現,工作頻率為 300 MHz,電壓為 0.8 V。分析了它們的面積和漏電特性,以確保符合 TinyAI 的約束條件。
為了評估運行時開銷和應用級效率,我們使用了兩個基準測試:GeMM 和 TinyBio 工作負載。GeMM 基準測試用於量化 Tiny-OpenCL 框架引入的調度開銷。結果表明,對於大於 256 × 256(或等效問題規模)的矩陣,延遲可以忽略不計。然後,使用 TinyBio 基準測試來評估相對於基線主機的性能和能耗改進。結果表明,高端 e-GPU 配置可實現高達 15.1 倍的加速,並將能耗降低高達 3.1 倍,同時僅產生 2.5 倍的面積開銷,並在 28 mW 的功耗預算內運行。
通過提供一個開源且高度可配置、具有競爭優勢的面積、功耗和可編程性的 GPU 平台,這項工作為 TinyAI 應用的 GPU 平台的進一步研究奠定了基礎,為靈活且節能的邊緣計算開闢了新的機遇。