4位圖靈獎得主佈道,2大冠軍機器人登台,“AI春晚”果然又高又硬_風聞
量子位-量子位官方账号-21分钟前
白交 發自 北京
量子位 | 公眾號 QbitAI
什麼?人形機器人冠軍們竟然同台了——
此前榮獲半程馬拉松長跑冠軍天工、拳擊冠軍宇樹G1,首次在智源大會相遇,並且各自還秀上了一波技能。
首先來看宇樹,雖然身形小巧,但是打拳動作十分靈活,感覺多日不見技藝精進了不少。

而這邊天工機器人迎來了2.0版本,「長腿」運動員已經成為過去式,轉而到室內做起家務來,現場為大家準備起甜點來。

沒想到天工你,還有另外一幅面孔?!
此外,還遇上了銀河通用的機器人在現場取貨送貨。僅需你的一句語音指令,它就完成這些操作。

如果不看大會名字,可能還以為這又是在哪裏舉辦的機器人盛會。
而這,就是一年一度的“AI春晚”啓幕現場,跟往屆一樣規格拉滿~
剛剛官宣再次創業後首次亮相的Bengio,談到了AI安全,面對當前大模型已經呈現出類生物主體行為,他提出了雙重解決方案:
一是研發以無私科學家為原型的非代理性、可信賴人工智能系統,專注於理解世界而非自主行動;二是推動全球協同治理,建立國際監管框架與技術驗證機制。

此外,強化學習之父Richard Sutton、姚期智、Joseph Sifakis在內四位圖靈獎得主坐鎮,Physical Intelligence創始人以及Linux執行董事都來了。
而國內當前最受矚目的明星公司和明星機器人也都一一亮相。
這邊大佬們思想碰撞,那邊機器人摩拳擦掌,看點多多,乾貨也滿滿。
每次智源大會都會有重磅發佈,此次首次亮相的“悟界”系列大模型,它包括四款模型——
原生多模態世界模型Emu3;
全球首個腦科學多模態通用基礎模型見微Brainμ;
具身大腦RoboBrain 2.0;
全原子微觀生命模型OpenComplex2。
可以看到,不僅有世界模型、還有腦科學模型,跨度從宏觀世界到微觀世界……咱就是説已經有點眼花繚亂了。

悟界系列大模型此次智源大會一大亮點是重磅發佈了“悟界”系列大模型。這是悟界的首次亮相,也是智源正式從悟道到悟界的跨越,此前悟道系列模型已經來到了3.0版本。
對於此次「跨越」,智源研究院院長王仲遠表示,這是件水到渠成的的事情,背後源於對於技術趨勢的判斷:
大模型正在從大語言模型向原生多模態大模型,向世界模型方向演進。悟道的“道”代表了大語言模型系統化方法和路徑的探索,而悟界的“界”則代表了虛實世界邊界的不斷突破。
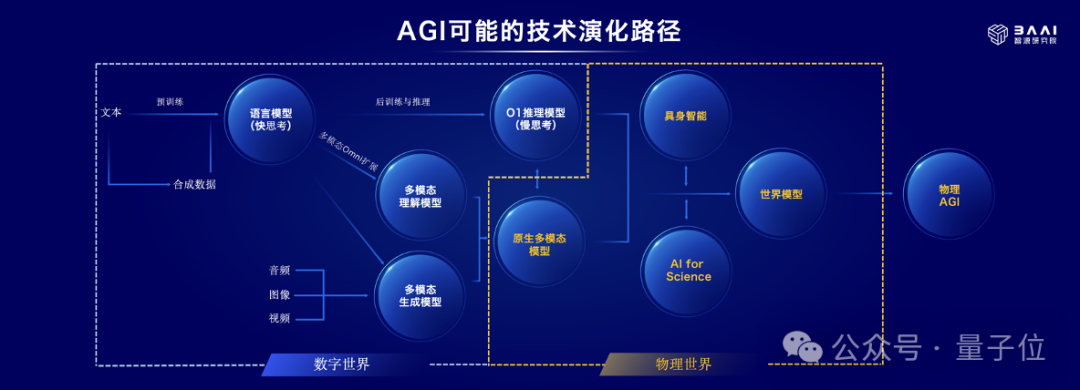
核心變化在於兩個方面:
從數字世界邁向物理世界,過去的“悟道”系列大模型主要利用互聯網數據進行訓練,從而掌握了理解數字世界知識的能力。而“悟界”的目標是旨在讓人工智能能夠感知和理解物理世界,首先推進與物理世界的交互,解決實際生產生活中的問題。
從理解宏觀世界到探索微觀世界,在進入物理世界後,模型也就不僅僅關注宏觀層面,比如具身智能,同樣也關注微觀層面,比如幫助進一步揭示世界以及生命的本質。
因此,基於這樣的判斷,整個“悟界”系列其實是圍繞“物理AGI”方向的探索。
具體來看。
第一款模型就是去年10月份就發佈的全球首個原生多模態世界模型Emu3。它實現了三個「統一」,包括統一了多模態學習,統一了文字、圖像、視頻等這些原生模態,統一了理解和生成能力。

它無需擴散模型或組合式架構的複雜性,通過研發新型視覺tokenizer將圖像/視頻編碼為與文本同構的離散符號序列,構建模態無關的統一表徵空間,實現文本、圖像、視頻的任意組合理解與生成。
基於Emu3下一個token預測這種極簡的思想以及自迴歸架構,模態容易擴展,同時進行可控的交互。
比如拓展腦信號這種模態。這也就是悟界第二款模型:全球首個腦科學多模態通用基礎模型見微Brainμ。
基於Emu3的底層架構,將fMRI、EEG、雙光子等神經科學與腦醫學相關的腦信號統一token化,利用預訓練模型多模態對齊的優勢,可以實現多模態腦信號與文本、圖像等模態的多向映射,並實現跨任務、跨模態、跨個體的統一通用建模,以單一模型完成多種神經科學的下游任務。
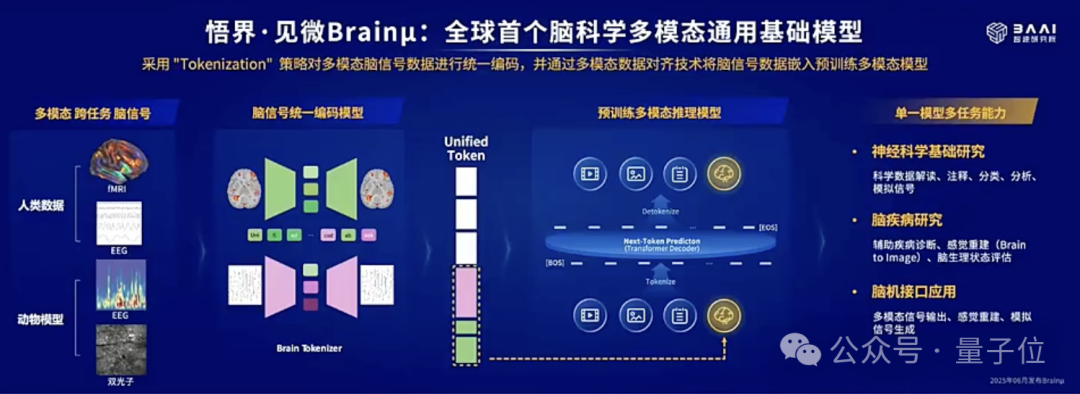
作為神經科學領域跨任務、跨模態、跨個體的基礎通用模型,Brainμ可同步處理多類編解碼任務,兼容多物種動物模型(包括小鼠狨猴獼猴)與人類數據,實現科學數據註釋、交互式科學結論解讀、大腦感覺信號重建及模擬刺激信號生成。
在自動化睡眠分型、感官信號重建與多種腦疾病診斷等任務中,作為單一模型其性能顯著超越現有的專有模型,實現了SOTA。
最終以單一模型完成多種神經科學的下游任務,比如科學數據註釋、交互式科學結論解讀、大腦感覺信號重建及模擬刺激信號生成。

目前,智源正在與國內前沿的基礎神經科學實驗室、腦疾病研究團隊和腦機接口團隊深入合作,包括北京生命科學研究所、清華大學、北京大學、復旦大學與強腦科技****BrainCO,拓展Brainμ的科學與工業應用。
以上就是智源研究院在多模態基礎模型上面的探索。通過多模態基礎模型,可以讓AI真正感知、理解世界,進一步與這個世界進行交互,這就推動了具身智能的發展。
王仲遠談到了當前具身智能發展面臨的四大瓶頸,包括硬件不成熟、數據短缺、模型能力弱、以及落地應用難。
這其實構成了一種循環悖論,那麼如何破局?
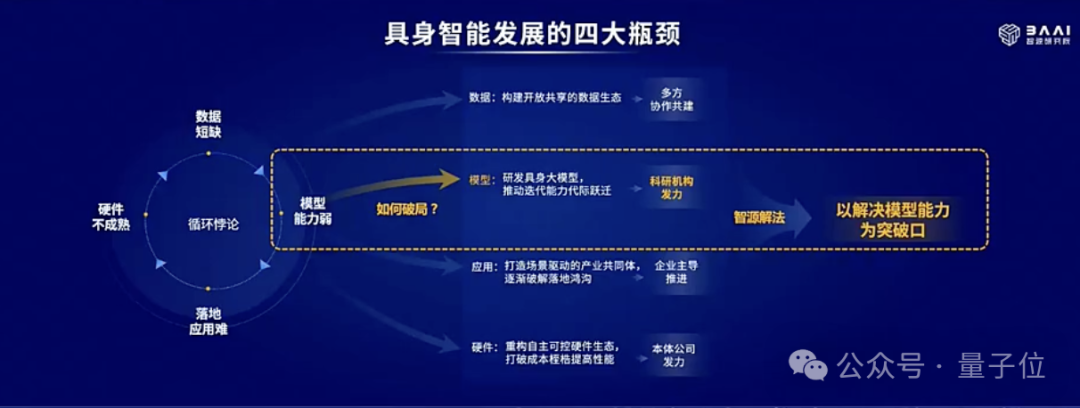
智源研究院選擇的突破口是模型。當前具身智能模型仍然面臨着不好用、不通用以及不易用的特點。
不好用指的是具身大模型還遠沒有到ChatGPT的時刻;不通用指的是具身大模型很多都只能用於一個本體,或者同一品牌的本體;不易用指的是大小腦本體的適配難度比較高。
隨着跨本體具身大小腦協作框架RoboOS 2.0與具身大腦RoboBrain 2.0的發佈,這些痛點都得到了一一解決。
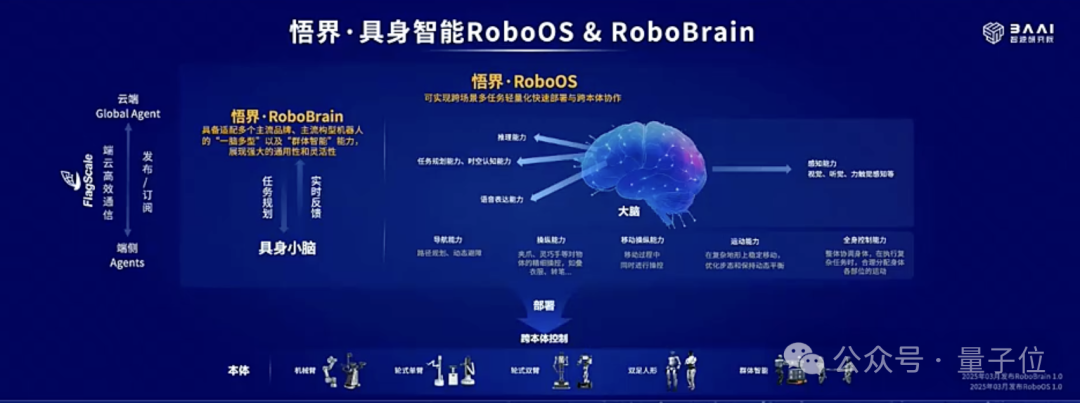
相較於1.0版本,2.0在很多能力方面都有升級。
據介紹,RoboOS 2.0是全球首個基於具身智能SaaS平台的開源框架,它支持無服務器一站式輕量化機器人本體部署,同時,RoboOS 2.0也是全球首個支持MCP的跨本體具身大小腦協作框架,旨在構建具身智能領域的“應用商店”生態。
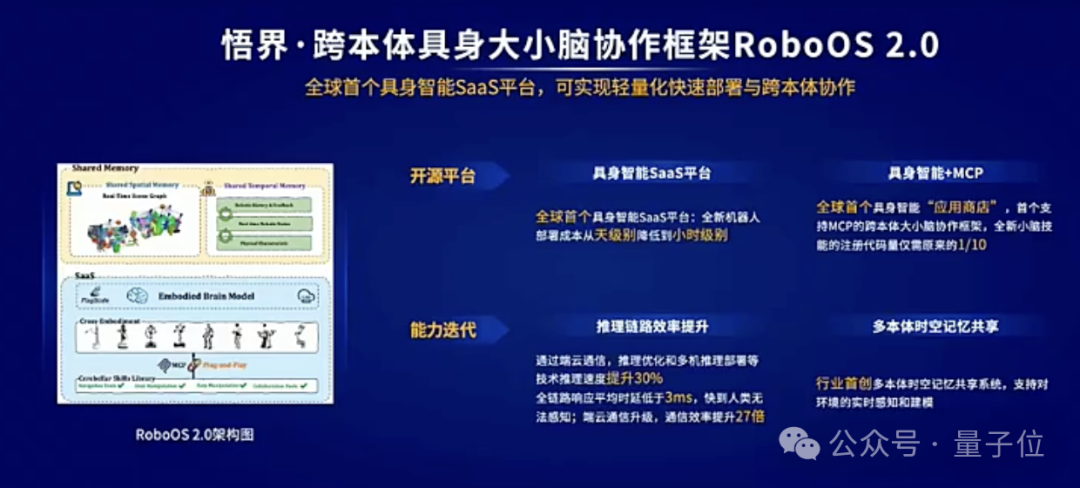
在該框架下,可一鍵下載並部署來自全球開發者創建的相同型號機器人本體的小腦技能,完成大小腦的無縫整合。RoboOS 2.0實現了小腦技能的免適配註冊機制,顯著降低開發門檻,典型場景下,相關代碼量僅為傳統手動註冊方式的****1/10。
相較於1.0,RoboOS 2.0對端到端推理鏈路進行了系統級優化,整體性能提升達30%,全鏈路平均響應時延低至****3ms以下,端雲通信效率提升27倍。
在功能層面,新增了多本體時空記憶場景圖(Scene Graph)共享機制,支持動態環境下的即時感知與建模;同時引入多粒度任務監控模塊,實現任務閉環反饋,有效提升機器人任務執行的穩定性與成功率。
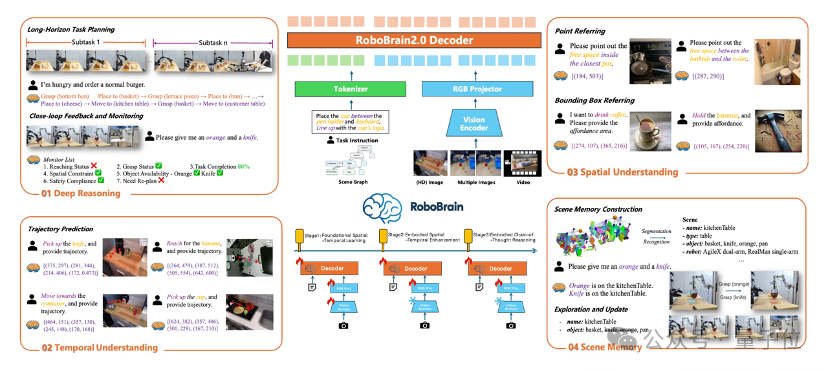
再來看具身大腦RoboBrain 2.0,相比1.0,在多項空間推理與任務規劃指標上超越主流大模型。

實驗數據顯示,RoboBrain 2.0的任務規劃準確率相較RoboBrain 1.0實現了74%的效果提升。
在空間智能方面,RoboBrain 2.0在原有可操作區域(Affordance)感知與操作軌跡(Trajectory)生成能力的基礎上,實現了17%的性能提升。同時,RoboBrain 2.0增加了空間推理能力(Spatial Referring),既包含機器人對相對空間位置(如前後、左右、遠近)及絕對距離的基礎感知與理解能力,也實現了對複雜空間的多步推理能力。
此外,RoboBrain 2.0還新增了閉環反饋以及具身智能的深度思考能力——
閉環反饋使機器人能夠根據當前環境感知和任務狀態,即時調整任務規劃與操作策略,以應對複雜環境中的突發變化和擾動;深度思考能力則支持機器人對複雜任務進行推理分解,進一步提升整體執行準確率與任務完成的可靠性。
現在,RoboOS 2.0與RoboBrain 2.0已全面開源,包括框架代碼、模型權重、數據集與評測基準。目前,智源研究院已與全球20多傢俱身智能企業建立戰略合作關係。

真實的物理世界不僅包括宏觀世界,還包括微觀世界。如果説具身智能解決的是宏觀世界的各種需求,那麼AI在微觀世界的賦能,就可以是生命科學。
悟界系列第四個模型是OpenComplex2全原子微觀生命模型。
當下AI模型對蛋白質結構的預測就像一張張靜態的幻燈片,但自然界的相互作用更像是持續變化的動態視頻。
OpenComplex2基於FloydNetwork圖擴散框架以及多尺度原子精度表示兩大關鍵技術創新,有效突破了生物分子在功能活動中可及的動態構象分佈預測的瓶頸,從而能夠建模生物分子系統中各種原子組分之間複雜的依賴關係,且無需對構象空間施加先驗約束,更加真實地還原生物分子的構象多樣性和動態特性。
此外,還能同時捕捉原子級、殘基級和基序級(motif level)的相關性,從而在建模過程中兼顧關鍵的局部結構細節與全局構象變化,為揭示生物功能提供更加全面的結構基礎。

基於這種能力,OpenComplex2在生物分子動態特性預測、柔性系統及超大型複合物建模、生物分子相互作用精細化分析等關鍵任務中性能卓越,突破了靜態結構預測的瓶頸。

以上就是悟界系列模型的全部亮相,可以清晰地看到智源研究院的技術路徑以及在這路徑上的相關探索。
除了悟界系列模型之外,在開源模型方面,王仲遠還分享了通用向量模型BGE系列、小時級開源輕量長視頻理解模型Video-XL-2、開源全能視覺生成模型OmniGen模型進展。
下一代AI如何發展?
本屆智源大會在現場議程和嘉賓設置上,均與往屆有些不同。
大會規格依然頂級,但顯著的變化在於更多產業新鋭力量的深度參與。例如,首次設立的大模型產業CEO論壇,就匯聚了面壁、愛詩、生數、智譜等前沿企業的創始人與掌舵者,同台論道。
這側面印證了大模型技術正加速向產業縱深落地,這些身處一線的玩家走向舞台中央,釋放其產業勢能。

不僅嘉賓陣容頂級,機器人展示同樣規格拉滿,除了開幕式上的人機同台,會場還設置了AI科研體驗區,讓人們感知這些技術如何從實驗室來到我們身邊。

下一代AI如何發展似乎已經具象化了,不過具體怎麼做?如何做?還得看各方大佬們的觀點和探索。
在本屆智源大會開幕式上,其實已經有了不少答案,比如像Bengio提出的安全隱憂需要解決,以及“悟界”所呈現出來對物理世界的感知理解與交互上的探索……
還有強化學習之父Richard Sutton談到了當前正熱的智能體這一形態的發展。他表示AI正從依賴人類靜態數據的 “人類數據時代” 邁入通過互動與經驗學習的 “體驗時代”,強調智能體需像人類和動物一樣從動態交互中生成新知識,而強化學習是實現這一目標的核心路徑。

此外,他還倡導去中心化合作替代中心化控制,通過信任、協調和市場機制引導AI與人類共生。
還有Linux基金會執行董事Jim Zemlin談到開源的必要性,2025年是開源AI元年,開源正成為全球AI創新核心驅動力。中國企業,如DeepSeek發佈開源大模型,引發技術生態變革,印證開源打破壟斷、加速迭代的作用。

面對當前市場氛圍正酣的具身智能,Physical Intelligence聯合創始人兼CEO Karol Hausman認為,VLA模型是關鍵突破,可讓機器人通過互聯網數據學習,無需體驗每個場景,還能與其他機器人連接獲取數據。

此外他還與宇樹科技創始人王興興,銀河通用創始人兼CTO、北京大學助理教授、智源具身智能研究中心主任王鶴,穹徹智能聯合創始人、上海交通大學教授盧策吾,北京人形機器人創新中心總經理熊友軍,就具身智能的不同技術路線、商業化路徑探索、典型應用場景拓展、產業生態構建等議題展開深度討論。
他們認為短期內人形機器人因數據採集、人機交互和環境適應優勢是重要載體,長期看隨着AGI發展會多樣化。對於VLA模型泛化性,雖面臨機器人環境複雜等挑戰,但通過合成數據、多場景訓練等可提升適應性。

能夠看到的是,多模態、強化學習、智能體、具身智能都成為了下一代AI發展的關鍵詞。
這離不開產業界和學術界等多方探索,其中智源研究院所在的生態位就很關鍵。
從成立之初,智源研究院定位就是“做高校做不了,企業不願意做的事情”。如今這一定位其實得以更加具象體現。
一方面,它承擔起基礎研究的資源投入和風險。高校擁有頂尖人才,但在大模型時代,基礎研究需要龐大的工程團隊、計算資源和企業化的運作方式,這是高校難以承擔的;而企業這邊面臨着巨大的資金壓力和業務壓力,對於風險高的前沿探索往往不願意參與。
比如就像原生多模態這個方面的探索,與企業為快速落地而先強化語言模型增添模態的方式不同,智源選擇在基礎架構上實現模態的統一和泛化,挖掘模型的通用性潛力。
而具身智能目前也是在技術路線不收斂的早期階段,智源的跨本體具身大腦探索也是其中一條高風險路徑。
另一方面,智源研究院通過鏈接產業與高校、以及技術開源的方式來完善整個AI產業的生態。
智源打造的覆蓋模型、算法、數據、評測、系統的大模型開源技術體系FlagOpen,截至目前,已開源約200個模型和160個數據集。
其中,模型全球總下載量超6.4億次,開源數據集下載量近****113萬次,開源項目代碼下載量超140萬次。
此次智源大會有30餘位AI公司創始人/CEO,100餘位全球青年科學家、200餘位人工智能頂尖學者和產業專家在此匯聚,也是智源研究院生態影響力的體現。
好了,本屆“AI春晚”還在繼續。這兩天圍繞多模態、深度推理、下一代AI路徑、Agent智能體、具身智能、AI4S、AI產業、AI安全、AI開源等熱門話題,總共有20個論壇180餘場報告。
感興趣的朋友可以繼續關注哦~