百度百科陷"詞條維權”困局:個人隱私、錯誤信息如何止?_風聞
快消前瞻-昨天 18:32
“證明我是我”——這個曾在行政審批中飽受詬病的悖論,正在互聯網知識平台重演。
上海楊浦的朱先生近日發現,百度百科上關於自己的詞條不僅存在事實性錯誤,更在修正過程中陷入隱私讓渡與程序困局。
當知識共享平台異化為個人信息"失控區",其背後折射的是否是平台機制的缺陷?
未經授權建立個人詞條還出現事實錯誤
開放編輯與責任缺失的雙重困境
根據正在新聞報道,近日,上海楊浦。朱先生在查詢資料時發現個人信息被他人編輯並上傳至百度百科,該百科內容與實際不符,信息有誤。
截圖自正在新聞
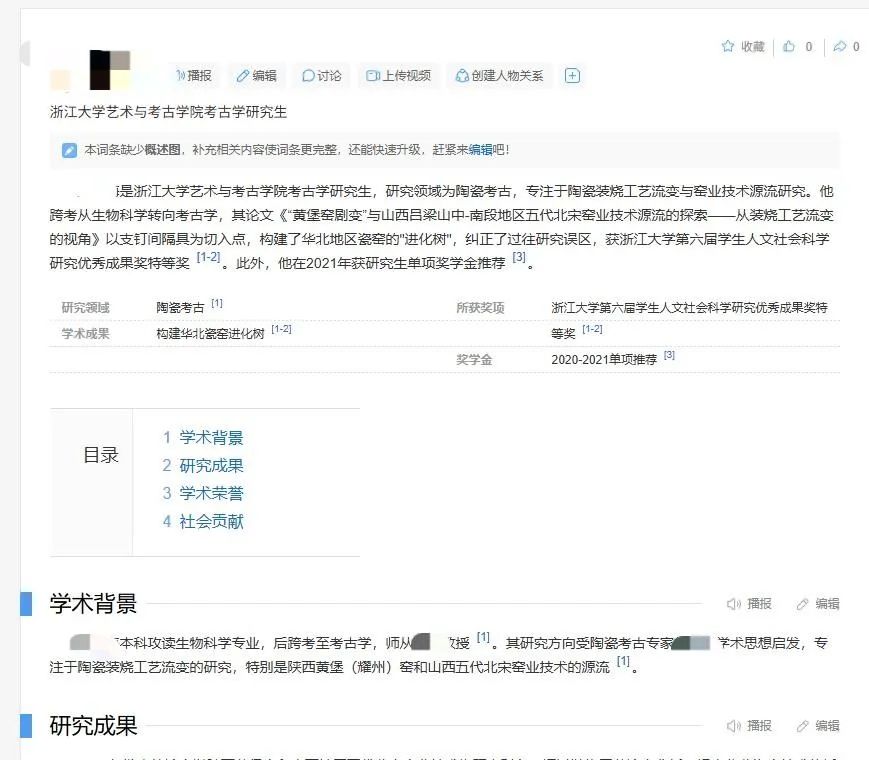
6月5日,朱先生告訴《正在新聞》,百度百科上對他的信息闡釋跟事實相差甚遠,比如他在浙大研究領域是石器微痕,並不是陶瓷,同時在研究成果這部分,自己並不是首次將支釘間隔具作為核心研究工具,編輯的十分不嚴謹。

朱先生嘗試修正自己的詞條,選擇了“本人編輯”的方法。最開始朱先生提供了自己的畢業證,隨後又被要求其他證明材料,到最後甚至要求朱先生人臉識別。朱先生表示,連支付軟件都未開啓人臉識別,百度憑什麼要求他人臉識別才可以編輯這些錯誤的材料。
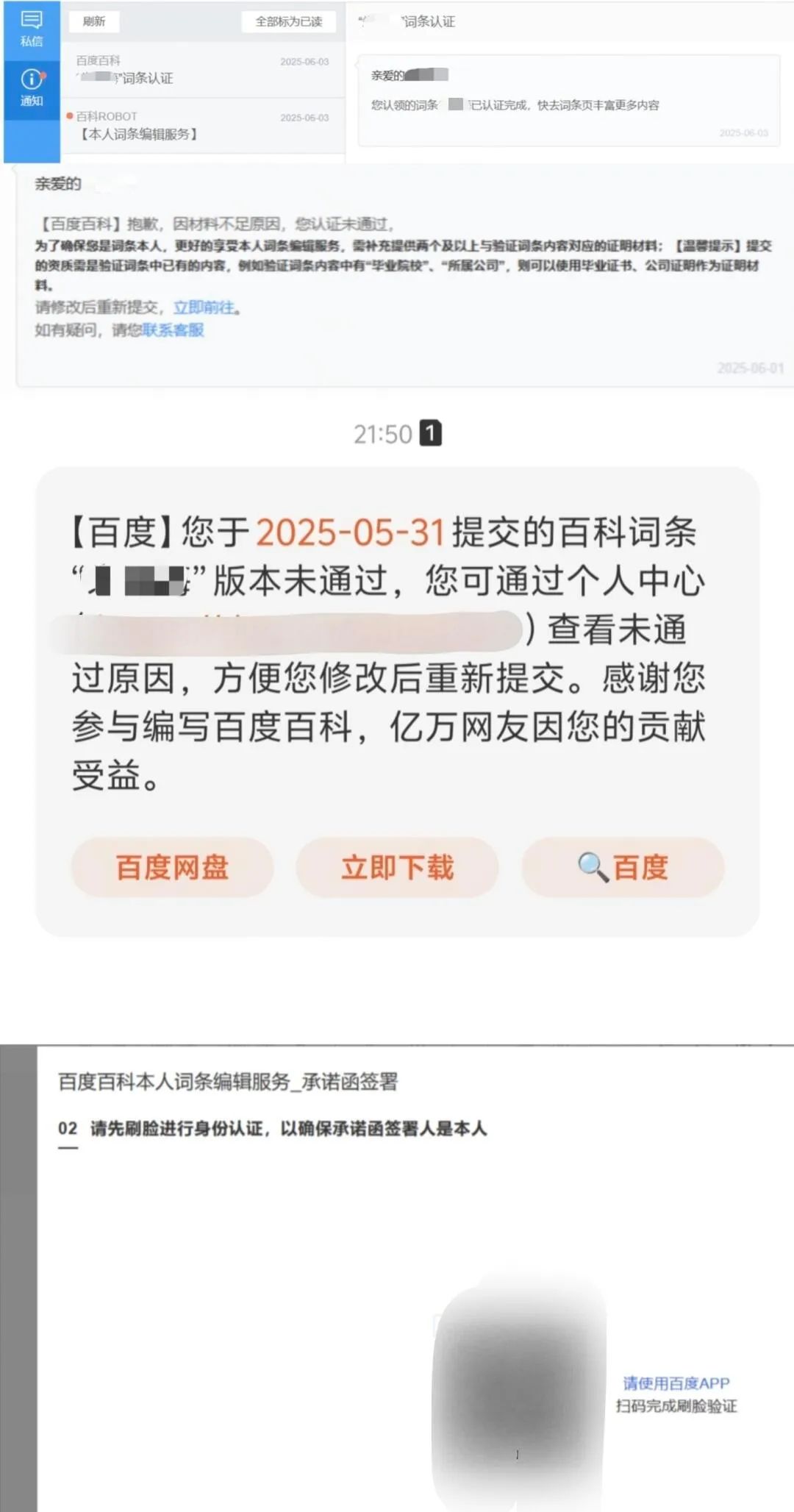
同時,朱先生表示,如果要建立個人百科詞條,要麼是當事人本人來編輯,要麼是公眾人物由他人編輯。百度百科未經授權建立個人詞條還出現了事實錯誤,對自己造成了困擾;更正錯誤信息時還索要多個材料,侵犯自己的隱私權。朱先生認為百度沒有權力也沒有理由來做這些事情。
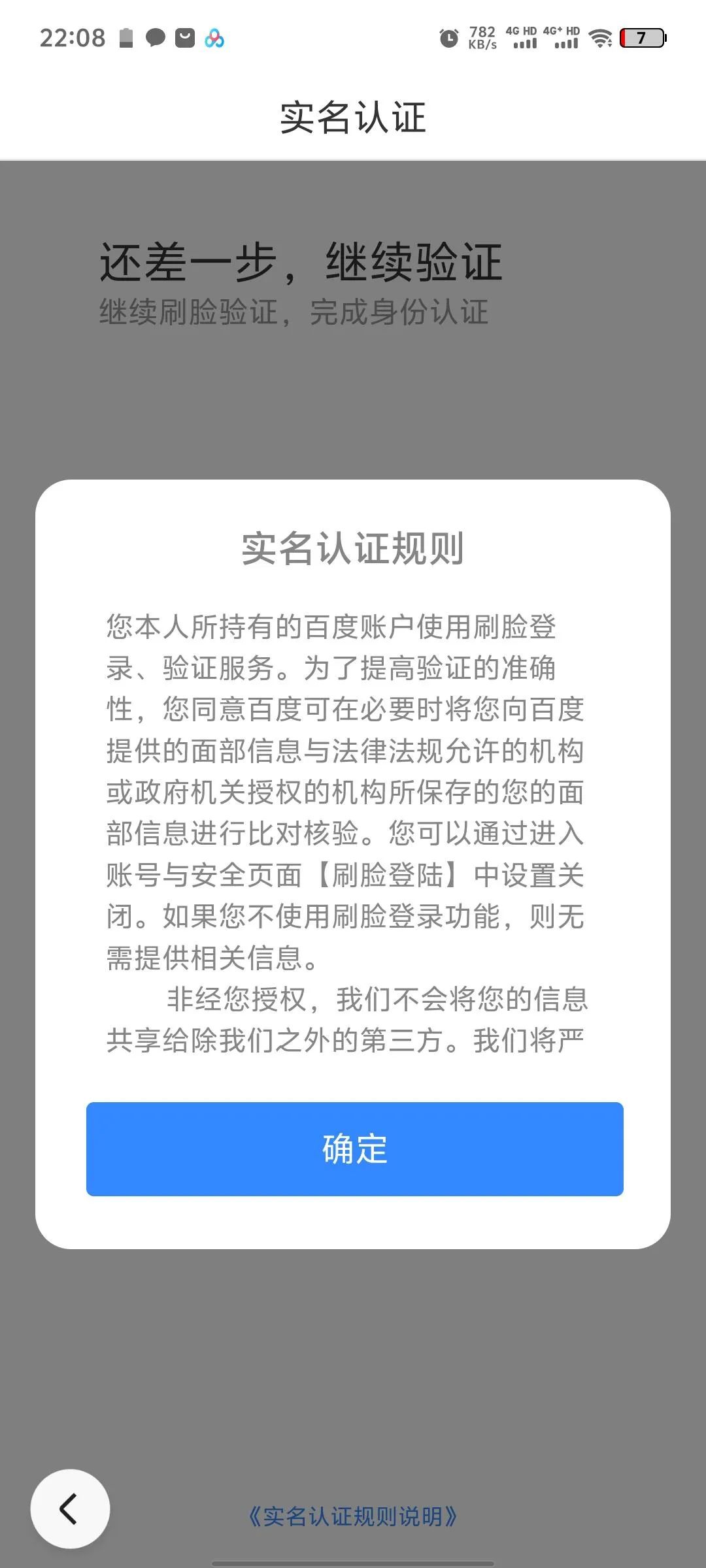
6月6日,百度百科客服對朱先生表示,刪除詞條流程繁瑣是因為擔心有人惡性刪除,刷臉的環節已經反饋給技術人員,如果目前詞條內容對朱先生造成困擾,需要刪除的話,將轉至侵權組同事做備案,協助處理。

事實上,快消前瞻在社交平台檢索發現,不少網友也遇到過類似問題。
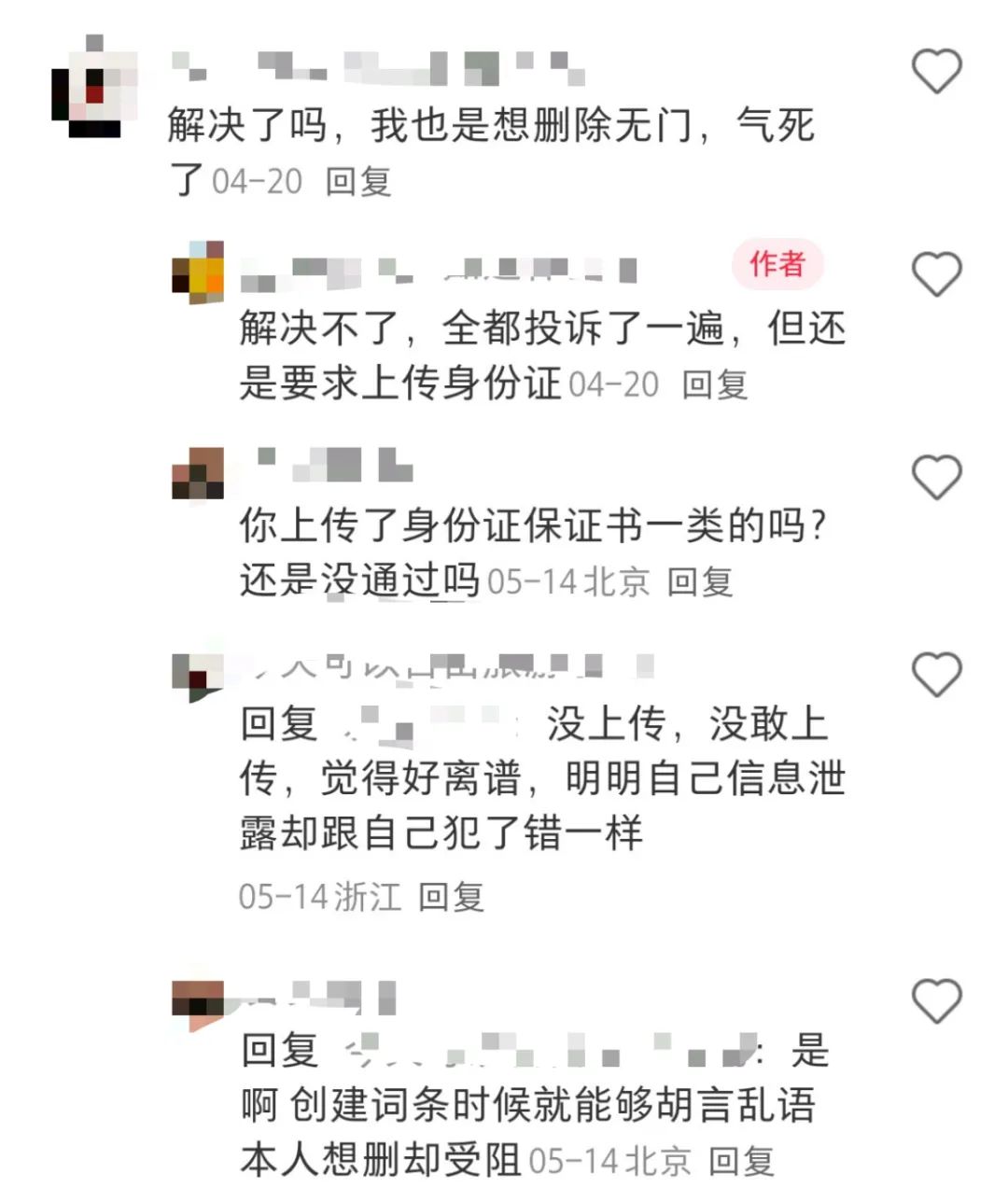
在小紅書平台,有網友稱“百度詞條侵犯隱私,刪除困難重重”,表示自己莫名其妙在百度百科有不符合自己信息的詞條,申請刪除不僅需要身份證正反面、還需要手寫保證函和人臉識別認證來“證明我是我”。該網友認為自己的個人隱私和信息權利受到侵害,隨後該網友向當地12345進行了相關投訴,但並未有何進展。


截圖自小紅書平台
在該帖子下面,同樣有網友表示自己也是“刪除無門”,認為“創建詞條的人能夠胡言亂語,本人想刪卻受阻”。
在黑貓投訴平台,也有網友投訴稱,自己在多年前曾經在一家公司工作,為了幫助該企業,義務免費進行宣傳編寫了詞條。然而多次申請刪除條該詞條,百度百科的工作人員總是以各種理由拒絕刪除,該網友表示自己早就從那家工作單位辭職,而且由於自己目前在新的單位工作,已經嚴重影響了個人生活以及工作。
除此之外,還有網友投訴百度百科“涉嫌上架虛假詞條,侵犯品牌權益”,該網友表示自己公司旗下持有商標證書的品牌標識,在百度百科詞條顯示卻是其它公司,且無商標證書。該網友稱其公司曾多次申請修改詞條,均不予以通過,百度百科給出的理由是證據不足。該網友表示對方沒有證據基礎,為何可以登上百科詞條。
AI污染下知識庫的“遞歸危機”
如何保證百科的權威?
根據公開資料,百度百科,是百度在2006年4月20日推出第三個基於搜索平台建立的社區類產品,這是繼百度貼吧、百度知道之後,百度再度深化其知識搜索體系。
2007年1月10日,百科首頁第一次改版。新增百科任務、百科之星、上週貢獻榜等欄目。
2007年4月2日,百科蝌蚪團正式成立,4月10日,百科蝌蚪團第一批成員出現,4月26日蝌蚪團首頁上線。
2007年4月19日,詞條頁面改版,改良詞條頁面的行高和行寬,在詞條頁面的底部增加了漢英詞典解釋,改進歷史版本頁面。
2007年5月百科編輯詞條積分調整;6月開放分類檢索升級,歷史版本增加翻頁功能,百科優質版本標準出台;9月高級編輯器上線,百科任務改版。11月百科推出相關詞條,可以在百度知道里搜索到百科詞條。
根據百度百科官網顯示,截至快消前瞻發稿前(2025年6月7日)百度百科已經收錄了29029332個詞條,編輯次數超2.6億次,參與詞條編輯的網友超過799萬人,幾乎涵蓋了所有已知的知識領域。

截圖自百度百科官網
快消前瞻通過體驗百度百科進行詞條創建,發現可以創建的詞條主題包括人物、產品品牌、醫療、企業類等內容,創建詞條也明確要求“不許添加廣告性質”“不編寫虛假、捏造、惡搞、缺乏依據的內容”,明確規定了不能侵犯他人合理權益。

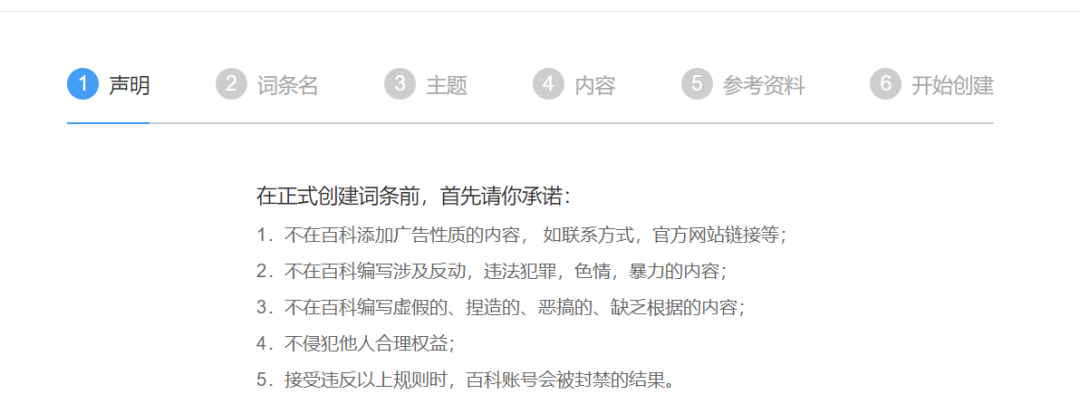
截圖自百度百科官網
但值得注意的是,社交媒體上,不少網友表示百度百科詞條上存在信息“錯誤”。
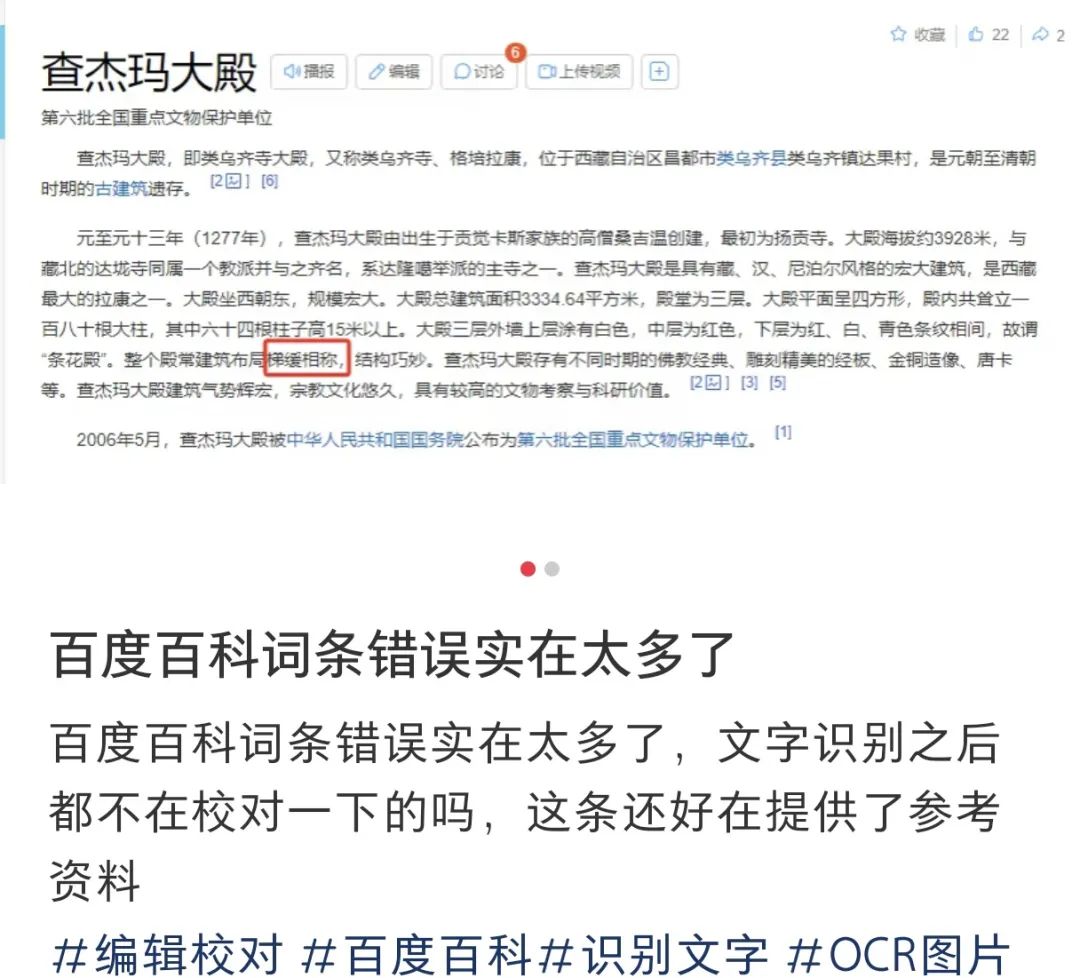
截圖自小紅書平台
除此之外,隨着AI時代的來臨,不少用户反映百度百科詞條中出現了大量AI生成的內容,導致許多基礎詞條出現了事實性錯誤。

根據公開信息,最常見的百科語料庫包括維基百科和百度百科,它們以免費、開源、多語言支持和高文本價值為特點。這些知識經過人工精心整理,準確性較高,能夠幫助模型建立對各類事物的基本認知,如歷史事件、科學概念等。
由於這些百科內容易於獲取,不少人工智能機構通常會選擇特定語言的百科數據進行爬取和過濾,作為預訓練語料庫的一部分。因此,它們在預訓練語料庫中的出現頻率較高,是大語言模型(LLMs)知識庫的基礎。
然而,隨着AI大模型將百科作為核心語料,錯誤信息正通過"遞歸效應"加速擴散。
中國人民大學新聞學院教授劉海龍在接受市象的採訪中指出,“未來我們得到的內容可能是AI生產的東西佔主導,這些東西又成為新的語料餵給AI,然後AI又會加工AI生產的東西,不斷反覆。這就會出現‘遞歸效應’,出現尼采講的‘永恆循環’。”
AI帶來的信息傳播負面效應日益顯現。這一現象並非難以察覺,越來越多的人已開始感受到AI對信息傳播的顛覆性影響。
根據環球網報道,目前,維基百科為應對人工智能生成內容帶來的挑戰,推出了維基人工智能清理項目(WikiProject AI Cleanup),並強調內容的可驗證性:要求編輯在文章歷史中註明是否使用了大型語言模型(LLM)。
知識平台的權威,永遠建立在真實性與信任的基石之上。
百度百科作為中文互聯網的重要知識庫,其權威性的確立不僅關係到用户信任,也影響到整個信息傳播的生態。未來,百度百科更需要一個尊重個體權利、敬畏知識真實性的解決方案。