光芯片,即將起飛!_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。1小时前
大型語言模型(LLMs)正在迅速逼近當代計算硬件的極限。例如,據估算,訓練GPT-3大約消耗了1300兆瓦時(MWh)的電力,預測顯示未來模型可能需要城市級(吉瓦級)的電力預算。這種需求促使人們探索超越傳統馮·諾依曼架構的計算範式。
本綜述調查了為下一代生成式AI計算優化的新興光子硬件。我們討論了集成光子神經網絡架構(如馬赫-曾德干涉儀陣列、激光器、波長複用微環諧振器),這些架構能夠實現超高速矩陣運算。同時,我們也研究了有前景的替代類神經設備,包括脈衝神經網絡電路和混合自旋-光子突觸,它們將存儲與計算融合在一起。本文還綜述了將二維材料(如石墨烯、過渡金屬二硫族化合物,TMDCs)集成進硅基光子平台,用於可調製器和片上突觸元件的研究進展。
我們在這種硬件背景下分析了基於Transformer的大型語言模型架構(包括自注意力機制和前饋層),指出了將動態矩陣乘法映射到這些新型硬件上的策略與挑戰。隨後,我們剖析了主流大型語言模型的內部機制,例如chatGPT、DeepSeek和Llama,突出了它們架構上的異同。
我們綜合了當前最先進的組件、算法和集成方法,強調了在將此類系統擴展到百萬級模型時的關鍵進展與未解問題。我們發現,光子計算系統在吞吐量和能效方面有可能超越電子處理器幾個數量級,但在長上下文窗口、長序列處理所需的存儲與大規模數據集的保存方面仍需技術突破。本綜述為AI硬件的發展提供了一條清晰的路線圖,強調了先進光子組件和技術在支持未來LLM中的關鍵作用。
引言
近年來基於Transformer的大型語言模型(LLMs)的快速發展極大地提高了對計算基礎設施的需求。訓練最先進的AI模型現在需要巨大的計算與能耗資源。例如,GPT-3模型在訓練期間估計消耗了約1300兆瓦時的電力,而行業預測表明,下一代LLM可能需要吉瓦級的電力預算。這一趨勢與大規模GPU集羣的使用同時出現(例如,Meta訓練Llama 4時使用了超過10萬個NVIDIA H100 GPU的集羣)。與此同時,傳統硅基芯片正接近其物理極限(晶體管特徵尺寸已達約3納米),馮·諾依曼架構也受限於“存儲器–處理器”瓶頸,從而限制了速度與能效。這些因素共同凸顯出LLMs日益增長的計算需求與傳統CMOS電子硬件能力之間的鴻溝。
這一挑戰促使人們探索替代計算範式。光子計算利用光來處理信息,天然具有高帶寬、超強並行性與極低熱耗散等優勢。近期在光子集成電路(PICs)上的進展,使得構建神經網絡基本模塊成為可能,例如相干干涉儀陣列、微環諧振器(MRR)權重陣列,以及用於執行密集矩陣乘法與乘-加操作的波分複用(WDM)方案。這些光子處理器利用WDM實現了極致的並行性與吞吐能力。
與此同時,將二維材料(如石墨烯與TMDCs)集成入PIC中,催生了超高速的電吸收調製器與可飽和吸收體,成為片上的“神經元”與“突觸”。作為光學的補充,自旋電子類神經設備(如磁隧道結和斯格明子通道)提供非易失性突觸存儲和類神經脈衝行為。這些光子與自旋電子類神經元件從物理機制上實現了存儲與處理的合一,為能效優化的AI計算開闢新途徑。
將基於Transformer的LLM架構映射到這些新型硬件平台上,面臨諸多挑戰。Transformer中的自注意力層涉及動態計算的權重矩陣(query、key和value),這些權重依賴於輸入數據。設計可重構的光子或自旋電路以實現這種數據依賴型操作,正成為活躍研究領域。此外,在光子/自旋子媒介中實現模擬非線性(如GeLU激活函數)與歸一化仍是重大技術難題。
為應對上述問題,研究者提出了許多“硬件感知”的算法設計策略,如適用於光子計算的訓練方法以及能容忍模擬噪聲和量化誤差的神經網絡模型。
本綜述餘下部分結構如下:
第2節:介紹光子加速器架構,包括相干干涉儀網絡、微環權重陣列與基於波分複用的矩陣處理器;
第3節:探討二維材料在光子芯片上的集成(如石墨烯/TMDC調製器、光子憶阻器);
第4節:分析替代類神經設備,特別是自旋電子在類神經計算中的應用;
第5節:總結主流LLM與Transformer架構原理,並探討如何將其映射到光子芯片上,強調在光子與類神經硬件上實現注意力機制與前饋層的策略;
第6節:介紹脈衝神經網絡的機制與實現算法;
第7節:指出系統層面的關鍵挑戰並展望未來方向。
本綜述力圖為下一代AI硬件發展繪製出基於光子與自旋電子技術的完整路線圖。
光子神經網絡與光子計算的前沿器件
光子神經網絡(PNN:Photonic neural networks)依託多種光學器件之間的協同作用實現高效計算:微環諧振器利用共振效應進行波長複用與光頻梳生成,為多波長信號處理奠定基礎 ;馬赫-曾德干涉儀(MZI:Mach-Zehnder interferometer)陣列通過相位調製實現光學矩陣運算,是神經網絡中核心線性變換的關鍵元件 ;超構表面通過亞波長結構調控光波的相位與幅度,能在衍射域內執行高度並行的光學計算 ;4f系統通過傅里葉變換在衍射域中實現線性濾波功能;而新型激光器則通過電光轉換機制實現非線性激活功能。這些器件集成了光場調控、線性變換與非線性響應能力,構建出高速、低功耗、強並行的全光計算架構。
本節將介紹當前光學神經網絡實現中常用的器件。
微環諧振器
微環諧振器(MRRs)(見圖1)的重要性不僅體現在它們在波分複用(WDM)中的作用,還體現在其獨特的濾波特性,例如光頻梳生成。WDM允許不同波長的信號在同一波導中同時傳播而不會產生干擾:通過設計微環的半徑與折射率以支持特定的共振波長,滿足共振條件的光將耦合進環形腔體中持續振盪,在透射譜上表現為明顯的吸收凹槽。
而光頻梳則源於高Q值(低損耗)微腔中的參量振盪:當注入連續波(CW)泵浦激光後,光子會經歷非線性效應(如Kerr非線性),從而自發地產生等間距的光譜線,形成梳狀頻譜。WDM與頻梳生成的結合,使多波長信號可通過共享波導進行合成與傳輸,實現波長複用與空間複用的統一。
微環的其他特性也得到了利用。例如,利用微環的熱光效應,在微環上加入了具有激射閾值的相變材料,實現了類似神經網絡中ReLU函數的非線性效果。
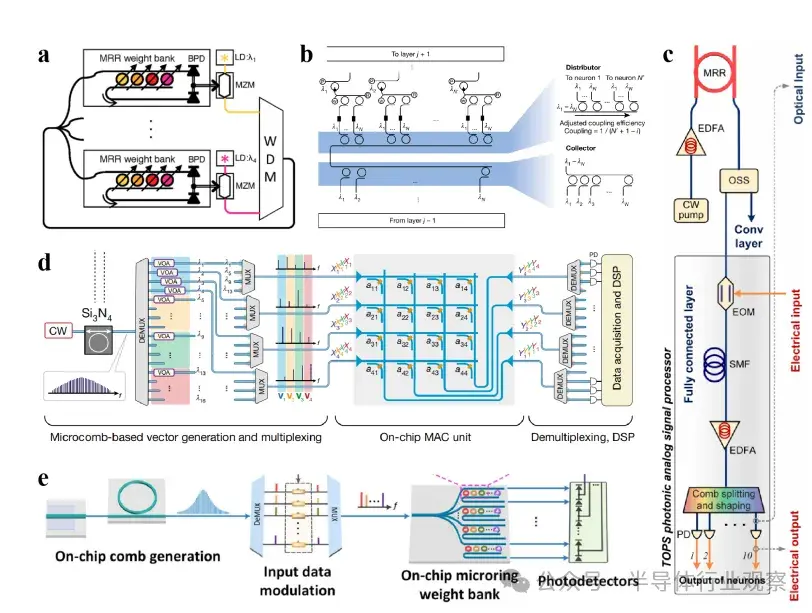 圖1:微環諧振器a)通過微環諧振器權重陣列可實現類神經光學神經網絡(ONN); b)展示了全光脈衝神經網絡的原理與實驗設置;c)開發了一種基於時間-波長複用的光子卷積加速器;d)提出了一種基於微梳與相變材料的片上光計算架構;e)展示了用於情緒識別的微梳卷積ONN芯片設計
圖1:微環諧振器a)通過微環諧振器權重陣列可實現類神經光學神經網絡(ONN); b)展示了全光脈衝神經網絡的原理與實驗設置;c)開發了一種基於時間-波長複用的光子卷積加速器;d)提出了一種基於微梳與相變材料的片上光計算架構;e)展示了用於情緒識別的微梳卷積ONN芯片設計
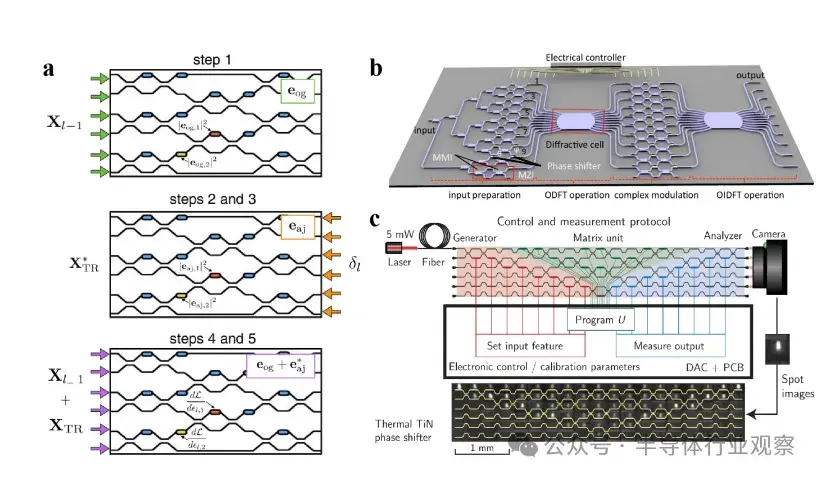 圖2:馬赫-曾德干涉儀(MZI)a)提出了支持即時在線學習的ONN訓練方法;b)展示了結合MZI與衍射光學元件的集成光子神經網絡架構;c)演示了基於MZI陣列的光子神經網絡的在線反向傳播訓練方法
圖2:馬赫-曾德干涉儀(MZI)a)提出了支持即時在線學習的ONN訓練方法;b)展示了結合MZI與衍射光學元件的集成光子神經網絡架構;c)演示了基於MZI陣列的光子神經網絡的在線反向傳播訓練方法
馬赫-曾德爾干涉儀
(Mach-Zehnder Interferometer)
MZI 陣列(見圖2)可有效執行光學矩陣-向量乘法(MVM)運算:它由兩個光學耦合器/分束器和兩個調製器(可通過外部電路控制)組成。輸入光通過分束器被分成兩路,調製器調節兩路之間的相位差,最後通過光學耦合器重新組合成干涉光。每個 MZI 對光信號執行二維酉變換(複數域的正交變換),在數學上等價於一個 2×2 的酉矩陣。當多個 MZI 按特定拓撲結構(如網格)級聯時,它們的整體行為可對應於高維酉矩陣的分解,因為任意 N 維酉矩陣都可以分解為一系列二維酉變換。因此,MZI 陣列可以實現類似於神經網絡中權重矩陣的可編程酉變換。
輸出的光信號可進一步通過光電手段進行轉換,並與電子器件集成,實現非線性激活函數,從而完成神經網絡的前向傳播。
超表面(Metasurface)
超表面在神經網絡應用中的運行主要依賴於“面”之間的光的衍射與干涉。超表面是一種由亞波長尺度結構單元組成的材料,能夠調製光波的性質,包括相位、幅度、偏振和頻率。這些結構通常具有超薄、輕質和高集成密度(支持大規模並行)的特點,其實現方式多樣,如基於絕緣體上硅(SOI)的設計、複合惠更斯超表面、單層全息感知器等。由於衍射和干涉本質上是線性過程,因此要實現非線性計算需要額外機制,如利用超表面材料的光電效應 。
多層衍射架構(見圖3)通過堆疊的二維表面作為高密度排列的神經元層實現。通過控制每個衍射層中空間位置處的相對厚度或材料特性,可調節光的相位和幅度。或者, 在一塊平面表面上製造一維高對比透射陣列超表面(見圖4),例如,在標準 SOI 基底上蝕刻空氣槽(後續可填充二氧化硅),槽的間距(晶格常數)和寬度固定,通過改變槽的長度來控制相位。
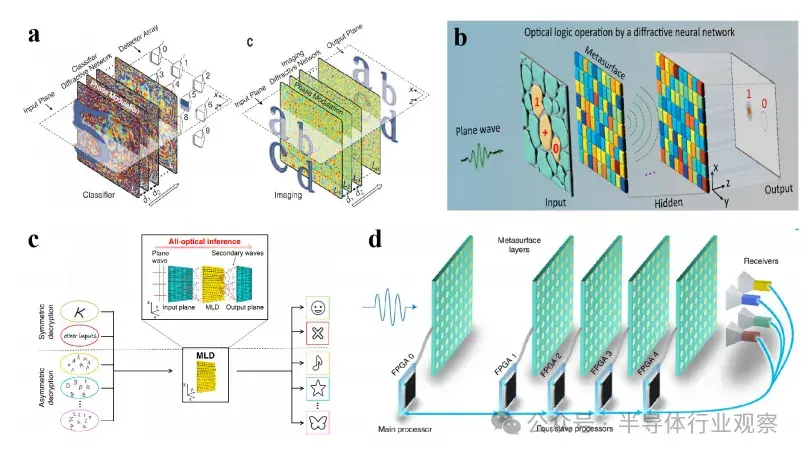 圖3:二維超表面
圖3:二維超表面
a) 二維衍射深度神經網絡(D2NN)中推理機制的概念圖示。
b) 通過衍射光學神經網絡(DONN)實現邏輯運算的實驗配置。
c) 納米打印的光學感知器實現芯片級計算。
d) 利用數字型超原子陣列的可重構DONN架構。
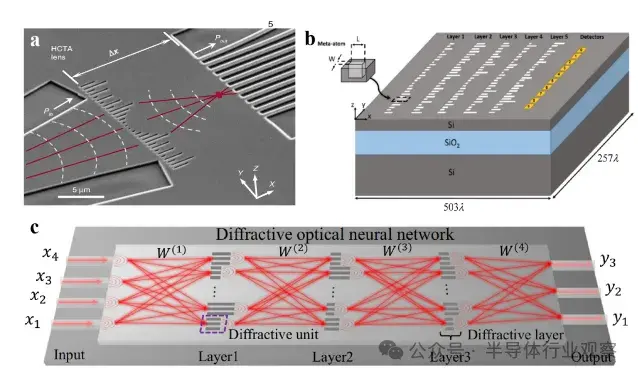 圖4:一維超表面
圖4:一維超表面
a) 一維DONN在光子機器學習中的實驗驗證。
b) 基於仿真的芯片級DONN驗證,支持光速計算。
c) 介電超表面實現用於傅里葉變換與空間微分的芯片級波前控制。
圖5:4f系統
a) 使用4f光學系統的混合光電卷積神經網絡(CNN)。
b) 完全光學神經網絡(ONN)架構,將深度衍射神經網絡集成於4f成像系統的傅里葉平面上。
4f 系統(見圖5)利用光場信號(如圖像)通過第一枚透鏡進行傅里葉變換。在透鏡後的傅里葉面上,調製設備(如相位掩膜、空間光調製器 SLM)對頻譜進行濾波或加權調整。經調製後的頻譜再通過第二枚透鏡進行反傅里葉變換,生成輸出光場。超表面材料可替代傳統透鏡間的調製設備 。
其他類型激光器
激光器作為一種具有高相干性、單色性和方向性的獨特光源,也被應用於光神經網絡(ONN)(見圖6)。
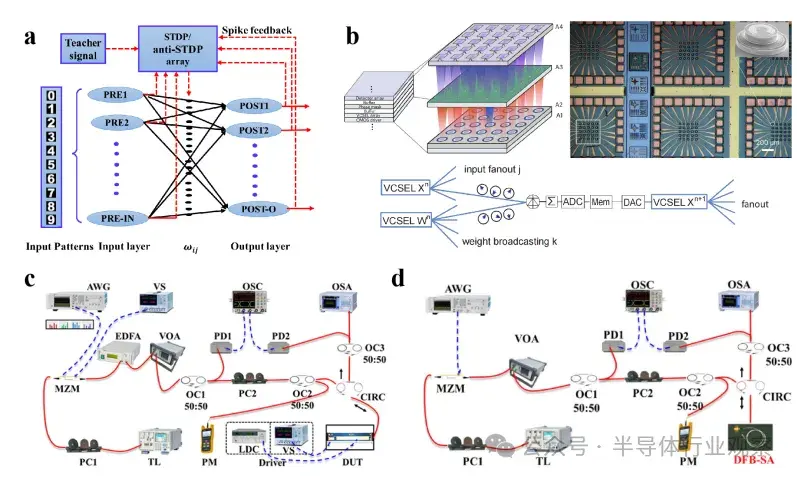 圖6:其他類型的激光器
圖6:其他類型的激光器
a) 使用垂直腔面發射激光器(VCSELs)的全光尖峯神經網絡(SNN)理論分析。
b) 基於VCSEL的全光SNN進行有監督學習。
c) 用於SNN中軟硬協同計算的FP-SA神經元芯片。
d) 基於分佈反饋-飽和吸收(DFB-SA)激光器的光子集成尖峯神經元的實驗演示
例如,垂直腔面發射激光器(VCSEL)在研究中已被理論提出並在實驗中驗證。在 VCSEL 中,電流通過電極注入有源區,電子與空穴在量子阱層中複合,產生光子。這些光子在兩個分佈式布拉格反射鏡(DBR)之間來回反射,多次穿過有源區並被放大。當增益(光放大能力)超過腔體損耗(吸收、散射等)時,達到閾值條件,激光輸出就會產生。一項研究利用了 VCSEL 陣列的特性:在被主激光器鎖模時可以保持相同的初始相位。在該研究中,特徵數據被編碼為電信號來調節一個 VCSEL 的泵浦電壓,從而調節其輸出光的相位;同樣,權重矩陣的每一列也被編碼為電信號,調節其他 VCSEL 的輸出光相位。利用光束分離器和耦合器,使代表 MNIST 數據的 VCSEL 的輸出光與其他 VCSEL 的輸出光干涉,光電探測器收集光信號,並將其求和成電信號,作為下一層 VCSEL 陣列的輸入,實現前向傳播。在最終輸出層,輸出電信號最強的光電探測器對應於輸出標籤。
另一個例子是帶有腔內可飽和吸收體(SA)的分佈反饋激光器(DFB-SA)。DFB 激光器的腔體內含有周期性光柵結構,可提供光反饋以實現單波長輸出。可飽和吸收體(SA)區域位於激光腔高反射端附近。在低泵浦電平下,SA 吸收光子,抑制激光輸出;在高泵浦電平下,SA 釋放光脈衝(Q開關效應)。因此,當增益電流超過 DFB-SA 的自脈衝閾值時,SA 的週期性吸收調製會產生脈衝輸出,其輸出頻率與泵浦強度呈非線性正相關,可作為脈衝神經網絡(SNN)的基本單元。在此結構中,DFB 激光器也可以被傳統法布里-珀羅(FP)激光器取代 。
利用二維材料製造集成光子芯片
集成光子芯片作為下一代 AI 硬件的關鍵技術之一,正逐步崛起。這類芯片利用光進行計算和通信,具有高速與高能效的優勢。為了實現這一應用,將二維(2D)材料,主要是石墨烯和過渡金屬二硫族化物(TMDCs),集成到芯片中,能夠顯著提升功能與性能。本節將探討這些材料的特性、集成技術、應用場景以及其在 AI 光子芯片應用中面臨的挑戰。
石墨烯和 TMDCs 的關鍵特性
石墨烯因其優異的光學與電子性能,在光子學領域引發革命。儘管其厚度僅為一個原子層,卻能在寬光譜範圍內吸收約 2.3% 的入射光,這使其在光學調製與探測方面非常有效。此外,石墨烯超快的載流子遷移率支持高速調製與低功耗運行,這對於能效至上的 AI 硬件至關重要 。同時,石墨烯表現出強烈的非線性光學特性,可用於頻率變換、全光開關及其它高級功能,使其在該領域的重要性進一步提升。
另一方面,TMDCs(如 MoS₂ 和 WS₂)以可調帶隙和強激子效應補充了石墨烯的不足。這些材料在單層狀態下具有直接帶隙,增強了光與物質的相互作用,因而特別適用於光電探測器和波導。TMDCs 也展現出強非線性光學響應,能在芯片上實現倍頻和參量放大等高級功能。
基於上述材料特性與優勢,石墨烯與 TMDCs 顯然是推動 AI 光子芯片發展的關鍵材料。
集成技術
將二維材料集成到光子芯片中涉及多種先進封裝工藝,主要包括:
轉印法(Transfer Printing):將二維材料的薄層剝離後轉印至硅基底,無需粘合劑,能保持其本徵光學性能,並實現對光子結構(如波導、諧振器)的精確定位。
混合集成(Hybrid Integration):將石墨烯或 TMDCs 與現有硅光平台結合,增強光-物質相互作用。例如,石墨烯已用於在微環諧振器中實現高速調製器,該混合器件可實現太赫茲級別調製速度,同時保持低功耗 。
範德華異質結構(Van der Waals Heterostructures):通過堆疊不同的二維材料,形成具有可調帶隙和各向異性折射率的異質結構。這些結構被視為優化波導約束因子的理想方案。
近期的研究還表明,採用與 CMOS 工藝兼容的技術,可以實現基於石墨烯器件的晶圓級集成。這一突破為大規模生產含二維材料的光子芯片奠定了基礎。
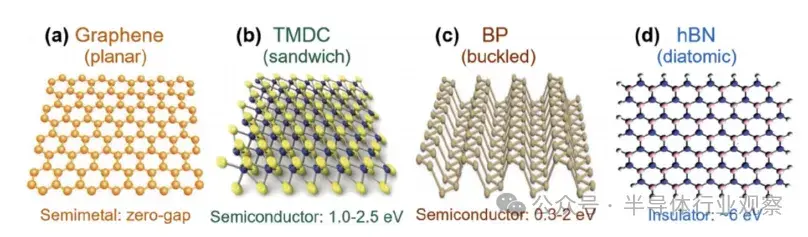 圖7:晶體結構
圖7:晶體結構
a) 石墨烯,b) 過渡金屬二硫化物(TMDC),c) 黑磷,d) 六方氮化硼(h-BN)晶體結構圖。
 圖8:圖示(左)與光學顯微鏡圖像(右)展示了目前主要的機械方法之一——柔性剝離與轉印法的步驟。步驟如下:
圖8:圖示(左)與光學顯微鏡圖像(右)展示了目前主要的機械方法之一——柔性剝離與轉印法的步驟。步驟如下:
a) 將材料沉積在玻璃基底上,
b) 小心地將圖案化的聚二甲基硅氧烷(PDMS)印章“上墨”,
c) 將“上墨”後的印章接觸加熱的硅/二氧化硅(Si/SiO₂)基底,
d) 撕開印章,留下沉積材料。
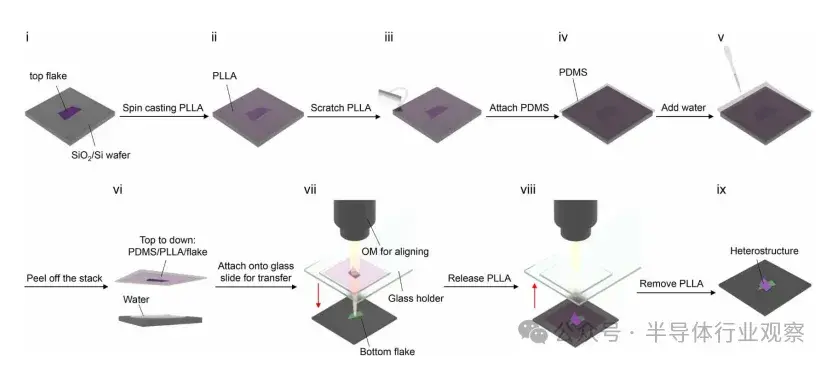 圖9:不使用腐蝕劑構建範德華異質結構的水浸法流程示意圖。
圖9:不使用腐蝕劑構建範德華異質結構的水浸法流程示意圖。
光子芯片中的應用
集成石墨烯和過渡金屬二硫化物(TMDCs)的光子芯片在人工智能工作負載中展現出變革性的應用:
一、光調製器
基於石墨烯的調製器已展示出卓越的速度和帶寬性能——通過將石墨烯與硅波導集成,研究人員實現了能夠在超過100 GHz頻率下運行的調製器。這些調製器特別適用於人工智能系統中所需的高速數據傳輸應用場景。
二、光電探測器
石墨烯在光電探測器中的應用頗為令人驚訝,由於其頻率無關的吸收特性以及在與強吸光材料結合使用時所展現的極高載流子遷移率,使得其性能優於傳統材料 [graphenea]。研究在使用混合石墨烯-量子點光電探測器方向取得進展,這類探測器被作為寬帶圖像傳感器集成到CMOS相機中,以實現高響應率 [graphenea]。
總體而言,二維材料在波導集成光電探測器方面具有多項優勢,包括尺寸最小化、信噪比提升以及在寬帶寬和高量子應用中的效率提高。
TMDCs被用於製造在可見光和紅外波段均具有高響應率的光電探測器,利用其物理特性提升探測性能。這類探測器使AI驅動的邊緣設備能夠高效獲取數據 [26]。混合石墨烯-量子點光電探測器也在研究中,旨在在保持CMOS兼容性的前提下進一步增強寬帶探測能力 [26]。
三、波導
範德瓦爾斯材料的使用使得超薄波導得以實現,並具有低傳播損耗的特性。通過將硅光子學與波導集成的石墨烯相結合,實現了全可調性、寬帶和高速運行等特性。
總體而言,這種波導應用使光子電路得以小型化,同時保持AI硬件所需的性能指標,在該領域推動顯著進步 。
 圖10:依賴二維材料的波導集成光電探測器技術路線圖。
圖10:依賴二維材料的波導集成光電探測器技術路線圖。
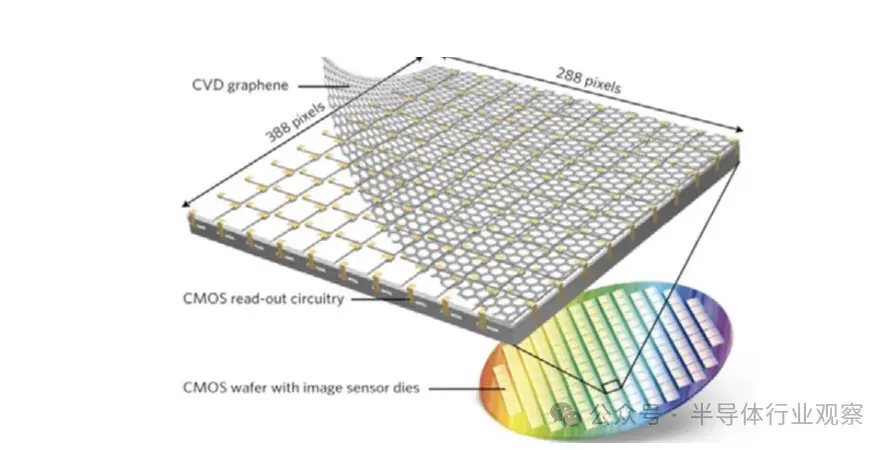 圖11:集成在CMOS電路中的石墨烯-量子點光電探測器。
圖11:集成在CMOS電路中的石墨烯-量子點光電探測器。
非線性光學
TMDCs表現出強烈的非線性響應,從而開啓了諸如頻率轉換和全光信號處理等高級功能的大門。這些能力對於在芯片上直接實現非線性光學功能及實現芯片級量子計算至關重要 。
基於石墨烯的器件也展現出在類腦架構如光子神經網絡方面的潛力——近期一項研究提出了一種嵌入微環諧振器中的基於石墨烯的突觸模型,能夠使用多波長技術構建大規模神經網絡,這一方法有望顯著加速大語言模型的訓練過程。
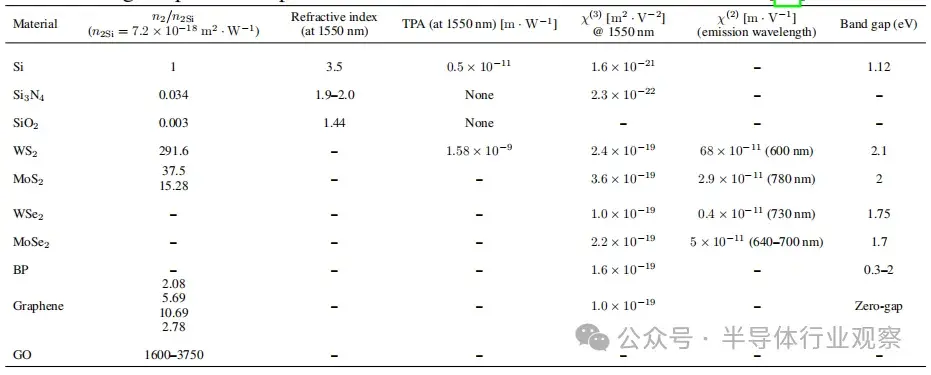 表1:在技術上具有重要意義的電信波長下,常見二維材料與用於硅及硅混合集成方案中的CMOS兼容平台主材的二階和三階非線性光學參數。該表表徵了多種混合波導的非線性響應,展示了二維材料在當前AI背景下的性能潛力。
表1:在技術上具有重要意義的電信波長下,常見二維材料與用於硅及硅混合集成方案中的CMOS兼容平台主材的二階和三階非線性光學參數。該表表徵了多種混合波導的非線性響應,展示了二維材料在當前AI背景下的性能潛力。
案例研究:基於光子芯片的AI硬件
集成二維材料的光子芯片因其能夠以接近光速的速度執行計算任務,而比現有技術更快,因此在AI硬件方面展現出極大前景。例如:
麻省理工學院的研究人員展示了一種能夠以光學方式執行深度神經網絡計算的全集成光子處理器。該芯片通過集成非線性光學功能單元(NOFUs)實現了超低延遲和極低功耗,在不到半納秒內完成了機器學習分類任務的關鍵計算,同時準確率超過92%(與現有技術表現一致)。此芯片還採用商用工藝製造,為這一新技術的規模化鋪平了道路。
哥倫比亞大學開發了一種節能的數據傳輸方法,通過在光子芯片上利用Kerr頻率梳,使研究人員能夠通過不同且精確的光波長傳輸清晰信號。這一創新提高了帶寬密度並降低了能耗,這兩者都是提升大型語言模型訓練系統可擴展性的關鍵因素。
Black Semiconductor公司新設立了名為FabONE的總部,專注於開發基於石墨烯的光子連接解決方案,以實現更快速的芯片間互連。這項技術將推動高性能計算、人工智能、機器人技術、自動駕駛等領域的發展,特別是在AI模型的超高速訓練過程方面。
這些突破性進展凸顯了集成二維材料的光子芯片在加速AI基礎設施革命方面的潛力,特別是在速度、可擴展性和能效方面的瓶頸突破。
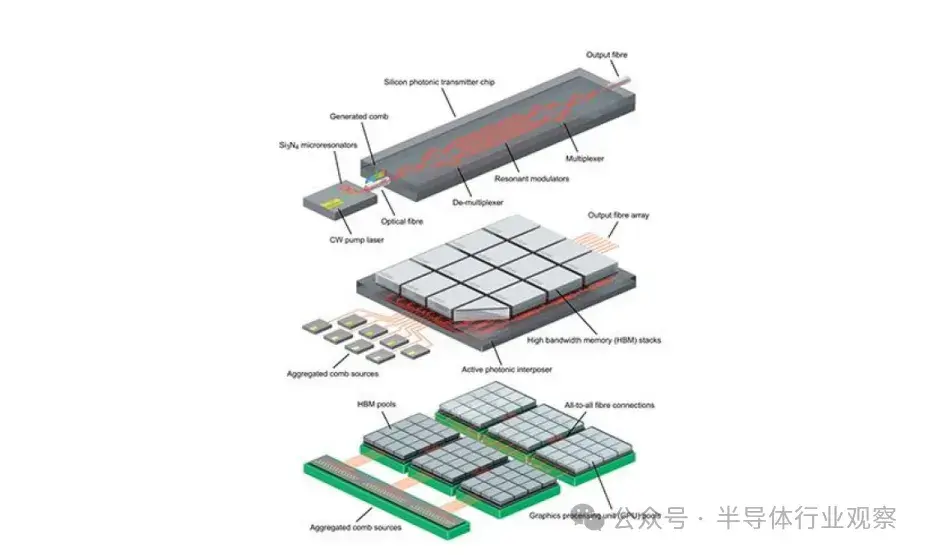 圖12:基於克爾頻率梳驅動的硅光子鏈路的分層結構藝術示意圖。
圖12:基於克爾頻率梳驅動的硅光子鏈路的分層結構藝術示意圖。
挑戰與未來方向
儘管潛力巨大,與所有新技術一樣,要充分實現二維材料在集成光子學中的價值,還面臨諸多挑戰:
一、可擴展性
超薄二維材料的脆弱性在大規模製造過程中帶來挑戰,需要在轉印技術和晶圓級合成方面取得進展,才能使這項技術真正具備可擴展性 。
二、材料穩定性
包括石墨烯和TMDCs在內的一些二維材料在環境條件下會降解。為了讓這項技術得到廣泛採用,必須開發保護塗層、封裝技術或一般性的保存方法,以保障其長期可靠性 [38]。
三、集成複雜性
要實現與現有CMOS工藝的無縫集成,需要在各種技術手段和界面工程上進一步優化,才能使這項新技術順利進入主流應用。
未來的研究應聚焦於解決上述挑戰,同時繼續探索與石墨烯和TMDCs互補的新型材料系統。二者結合,將推動由電子、光子和基於二維材料的組件構成的混合平台發展,為AI硬件和技術帶來顛覆性進步鋪平道路。
用於光子類腦計算芯片的自旋電子學
納米光子學作為一門新興的交叉學科,融合了納米技術和光子學原理,旨在探索和利用納米尺度結構對光波的調控能力。在光子學領域,主動器件與被動器件均扮演着重要角色,並具有廣闊的應用前景。類腦系統通過借鑑神經網絡的原理,試圖模擬人腦的計算與認知能力。本節將系統探討自旋電子器件與納米光子結構在類腦計算中的協同集成。
類腦計算的背景與挑戰
類腦計算的提出源於傳統馮·諾依曼架構的根本性限制。傳統計算系統受到“馮·諾依曼瓶頸”的困擾,即處理單元與存儲單元的物理分離導致在數據傳輸中產生過高的能耗與延遲。隨着處理器與存儲之間性能差距的擴大,這一瓶頸進一步加劇,被稱為“存儲牆”。現代計算機在模擬基礎腦功能時需消耗兆瓦級功率,而生物大腦僅使用20瓦功率卻能實現驚人的認知能力。
與此同時,半導體產業面臨晶體管微縮趨於極限、摩爾定律停滯等生存性挑戰。這場架構危機與晶體管縮放危機共同促使人們對類腦計算範式產生濃厚興趣。
類腦計算通過三項關鍵創新應對上述挑戰:1)計算與存儲的共址;2)信息的模擬編碼;3)大規模並行連接 。儘管神經網絡的理論框架可追溯至McCulloch與Pitts的二值神經元模型(1943年)以及之後的深度學習發展,但實際實現面臨嚴重的硬件限制。
基於CMOS的晶體管陣列實現缺乏非線性動力學、長期可塑性和隨機性等基本神經生物特性。新興的非易失性存儲器技術(尤其是憶阻器 )使更具生物逼真度的實現成為可能,但材料限制依然存在。阻變RAM(RRAM)、相變材料和鐵電器件在耐久性、速度和可控性之間存在權衡,限制其大規模部署能力。
三代神經網絡凸顯了硬件需求的不斷演進:1)以閾值操作為核心的第一代感知機;2)要求連續非線性激活函數的第二代深度神經網絡(DNN);3)依賴精確時間編碼和事件驅動處理的第三代脈衝神經網絡(SNN)。雖然DNN主導當前AI應用,SNN因稀疏、基於脈衝的通信方式而在生物逼真度與能效方面表現更優 。
然而,SNN的硬件實現尤為困難,需要器件能本徵地模擬生物神經元的“泄漏積分-發放”(LIF)動態,以及突觸的“基於脈衝時序的可塑性”(STDP)。當前採用CMOS電路或新型憶阻器的解決方案,或缺乏基本類腦特性,或在耐久性與隨機控制方面存在侷限性。這種硬件-算法之間的落差從根本上限制了類腦計算實現類腦效率與適應性的潛力。
神經形態計算中的核心優勢與
關鍵自旋電子技術
自旋電子器件具備獨特優勢,使其成為神經形態計算硬件的領先候選。其內在的非易失性、超快動態響應(>1 GHz)以及幾乎無限的耐久性(10^15 次循環)能夠實現高能效、符合生物邏輯的神經網絡實現方式。關鍵在於,自旋電子技術利用磁性和自旋相關現象,天然模擬神經-突觸功能,同時保持與傳統 CMOS 製造工藝的兼容性。其三大核心優勢包括:
(1)磁化翻轉和自旋進動中的隨機性可映射為神經元的概率性發放機制,從而實現事件驅動的脈衝神經網絡(SNNs),具備稀疏編碼效率 ;
(2)多態磁化動態(如磁疇壁運動、磁渦旋核化)展現模擬憶阻特性,是調控突觸權重的關鍵 ;
(3)非易失狀態保持特性可消除空閒期間的靜態功耗。
這些特性有效緩解馮·諾依曼架構瓶頸,並在速度與可靠性方面優於其他憶阻技術 。
磁隧道結(MTJ)是基礎的自旋電子構件,能夠在兩種運行模式下展現多樣神經形態功能。在超順磁模式下,MTJ 在平行與反平行狀態間的隨機翻轉可生成泊松分佈脈衝,應用於概率計算 ,在 CoFeB/MgO 結構中實現高達 604% 的隧道磁阻比(TMR)。當作為自旋轉矩納米振盪器(STNO)使用時,MTJ 可產生 GHz 級的電壓振盪,並與外部刺激同步,用於構建耦合振盪器網絡以實現模式識別 。自旋軌道轉矩(SOT)器件通過重金屬/鐵磁體雙層結構實現無場磁化翻轉,擴展了這些能力。SOT 驅動的自旋霍爾納米振盪器(SHNOs)在二維陣列中可實現互同步,三端結構的 MTJ 則通過讀寫路徑分離增強突觸精度 [Fukami2016]。磁納米線中的磁疇壁運動提供連續的電阻調製,適用於模擬突觸,實現每次突觸更新能耗為 32 meV。
新興的拓撲自旋結構如磁渦旋(skyrmion)具備類粒子動態,可用於生物啓發計算模型。在手性磁體中,直徑小於 100 nm 的渦旋的生成與湮滅模擬神經遞質釋放的概率機制,閾值電流為 10 μA 。反鐵磁(AFM)自旋電子學提供 THz 級動態響應和無雜散磁場特性,通過補償磁矩實現高密度交叉陣列。基於 AFM 的突觸展現 100 ps 的翻轉速度和高達 200°C 的熱穩定性]。
這些技術的融合使得構建“全自旋神經網絡”成為可能:結合基於 STNO 的神經元 [Romera2018]、磁疇壁憶阻突觸與渦旋概率互連,該硬件生態系統在物理層面協調設計,解決了存儲-計算分離難題。
自旋電子技術在系統層級的應用探索
自旋電子神經形態系統通過基於物理機制的架構創新,在認知計算模式中展現變革潛力。一項前沿實現中,四個同步運行的自旋轉矩納米振盪器(STNOs)處於耦合的微波發射狀態,用於即時元音識別任務,準確率達到 96%,比等效的深度學習網絡高出 17%,且每次分類僅消耗 3 mW 功耗 。該事件驅動架構利用 2.4 GHz STNO 陣列的固有頻率複用特性,將時間語音信號直接映射到振盪器的同步狀態,從而省去了模數轉換的開銷。
對於大規模實現,32×32 元素的自旋霍爾納米振盪器(SHNO)交叉陣列通過傳播的自旋波在 100 µm 距離上實現互相鎖相,從而通過集體動態而非離散突觸權重完成模式補全任務。
磁渦旋網絡通過拓撲保護的粒子相互作用引入概率計算能力。在手性磁體中,50–100 nm 尺寸的渦旋網絡通過核化密度編碼概率分佈,構建貝葉斯推理引擎,實現氣象預測模型中的 92% 準確率,在 10^5 個隨機狀態下進行存內採樣。該方案相較於 GPU 實現的蒙特卡洛仿真,能耗減少了 10 倍,通過模擬電流控制的狀態重組方式實現。
反鐵磁(AFM)自旋電子器件具備抗雜散場和 1 THz 動態性能,可實現超高密度結構。在 IrMn 基交叉陣列中,每次突觸更新的實驗能耗為 4 fJ,權重漂移在 10^12 次循環內保持在 0.1% 以下。
在儲備計算(Reservoir Computing)實現中,系統利用非線性磁化動態進行時間信號處理。單個旋渦型 STNO 通過時間複用進動狀態等效於 400 個神經元,解決 Mackey-Glass 混沌時間序列預測任務時,歸一化均方誤差僅為 0.012 。基於渦旋的儲備結構利用無序磁結構中的新興相互作用處理 10 MHz EEG 信號,功耗為 20 μW,成功實現即時癲癇發作檢測,依賴自旋結構動態中的分叉檢測機制。
展望大規模部署,結合 STNO 神經元、磁疇突觸與 AFM 互連的“全自旋神經網絡”有望實現 >100 TOPS 的認知計算性能,系統功耗低於 10 mW,通過在物理層面聯合設計神經-突觸功能結構達成。
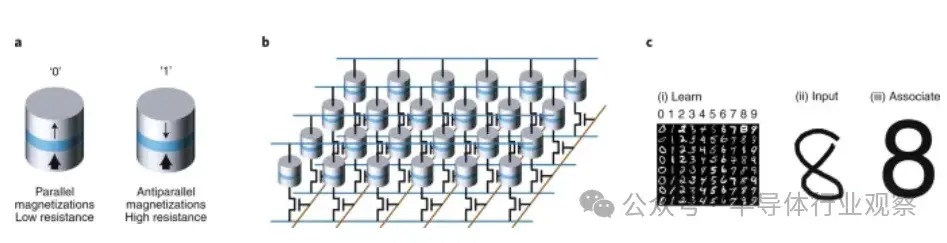 圖13:用於存儲應用的磁隧道結。
圖13:用於存儲應用的磁隧道結。
a、一種磁隧道結由兩個鐵磁層(灰色)夾着一層絕緣層(藍色)組成,其中一層的磁化方向固定,另一層的磁化方向可與其平行(低電阻)或反平行(高電阻)。標籤“1”和“0”分別表示這兩種狀態。
b、高密度存儲用的磁隧道結交叉陣列(磁性隨機存儲器)。通過激活相應的字線(紅色),允許底部位線與頂部感應線(均為藍色)導通,從而測量某個特定隧道結的電阻。通過施加足夠的電流可以切換磁化方向。
c、聯想記憶:(i) 來自MNIST數據集的手寫數字用於訓練聯想記憶;(ii) 訓練後輸入的測試樣本;(iii) 測試輸入產生的訓練網絡輸出,顯示成功的聯想。[<引用缺失>]
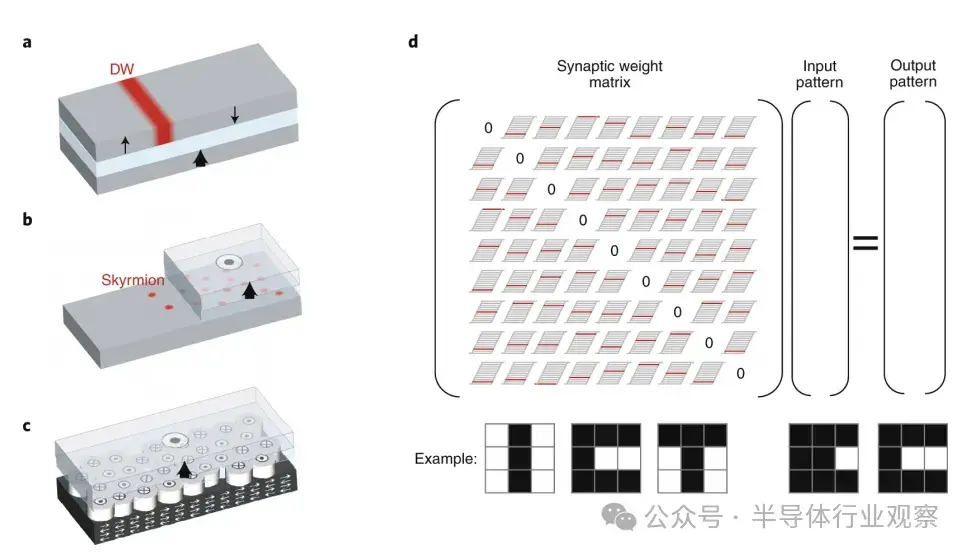 圖14:基於自旋電子學的憶阻器。
圖14:基於自旋電子學的憶阻器。
a、疇壁憶阻器:磁隧道結的電阻取決於疇壁位置,從而改變高電阻反平行態與低電阻平行態的相對面積。
b、基於Skyrmion的憶阻器:設備的電阻取決於固定層下方的Skyrmion數量。
c、細磁疇隧道憶阻器:在與多晶反鐵磁體耦合的隧道結中,由於各個磁疇的切換特性不同,使得磁疇可以在不同條件下獨立翻轉。設備的電阻由與固定層磁化方向一致的磁疇所佔比例決定。
d、自旋電子聯想記憶:每個非對角矩陣元素的值通過憶阻器的配置存儲,用不同的電平表示。這些電平經過訓練,使得在矩陣與輸入相乘後,結果最接近訓練集中的某一元素。乘法運算通過施加對應輸入的電壓並測量相關憶阻器的輸出電流完成。d圖下方的前三個圖像為網絡訓練識別的圖像,第四個為其中一個圖像的“噪聲”版本,第五個為重構後的正確圖像。
當前挑戰與未來方向
長上下文窗口與長序列下的內存問題
內存與上下文窗口: 光子加速器通常缺乏足夠的片上內存來緩存長序列的tokens。現代LLM推理可能涉及上萬個tokens,需要存儲激活值、鍵/值對以及整個上下文中的中間狀態。由於片上通常缺少大容量SRAM或NVM,光子系統只能將數據流進流出,這重新引入了馮·諾依曼瓶頸。正如Ning等人所指出,“數據移動經常成為整個系統的瓶頸”,這一問題不僅存在於傳統電子處理器,也同樣適用於光處理器。實踐中,有限的片上內存迫使光子LLM實現從外部DRAM或硬盤中獲取上下文,從而帶來延遲並破壞全光計算流水線。
諸如“檢索增強生成”(retrieval-augmented generation)等新興用例進一步加劇了這一問題:對多TB文本語料庫進行近即時搜索與分詞,又引入一輪高開銷的內存訪問。簡而言之,光子芯片的有限存儲能力限制了LLM的上下文長度與吞吐量,使得長序列推理成為一個主要挑戰。
光子計算系統中大規模數據集的存儲問題
存儲與I/O瓶頸: 大語言模型及其訓練數據或知識庫涉及PB級甚至更大的數據集。光子加速器仍依賴於高速外部存儲與內存來提供這些數據。所需的I/O帶寬常常超出現有接口的處理能力:即使光核本身運行極快,但如果無法快速供數,也會造成資源浪費。分析人士警告LLM面臨越來越嚴重的“內存牆”,數據移動成為主導限制因素。
現實工作負載使情況更為嚴峻:例如檢索增強型LLM需反覆提取和處理大量文本塊,對I/O系統造成極大壓力。有些提議(如將權重存儲與計算單元共置的非易失性存儲)可減少I/O開銷(一項研究報告使用片上Flash存儲權重可減少1000倍I/O),但考慮到數據集體量,多TB語料庫的緩存、調度與總線帶寬仍將是光子LLM系統中的關鍵瓶頸。
精度與轉換開銷問題
光子計算本質上是模擬的,因此很難表示LLM推理所需的高精度張量。當前最先進的光子Transformer設計依賴高分辨率ADC/DAC來保持精度,而這些轉換器消耗了大部分芯片面積與功耗。例如,在某個光子Transformer加速器中,ADC/DAC電路佔據了超過50%的芯片面積,併成為性能瓶頸。
如何在不大幅增加轉換開銷的前提下減少量化誤差是持續的挑戰:低比特轉換器或共享ADC架構可優化面積與能耗,但可能影響模型精度。因此,找到最優的模擬量化方案或混合信號架構(例如使用數字校正少量值)對下一代光子LLM芯片至關重要。
缺乏原生非線性函數
光子硬件擅長執行線性運算(如通過干涉儀實現的矩陣-向量乘法),但在實現激活函數和非線性層方面歷來缺乏高效手段。早期集成光子神經網絡雖可進行快速矩陣乘法,但激活函數仍依賴電子電路。實踐中,許多光子LLM加速器仍需轉換至CMOS以實現softmax、GELU等點操作函數。
集成高效的片上非線性元件(如光學可飽和吸收器、電光調製器或納米光子非線性元件),或開發最小化轉換差距的混合光電計算流水線,是實現全光LLM推理的重要工程挑戰。
光子注意力架構
目前的主要研究方向之一是將Transformer中的自注意力機制直接實現於光域中。這要求設計可調光學權重元件與可重構干涉儀網絡,以光學方式計算Q×K及V加權和。例如,光子張量核(photonic tensor cores)正在開發中,利用馬赫-曾德爾干涉儀(MZI)網格或其他交叉陣列實現大規模矩陣並行運算。可調權重可以通過相位調製器、微環調製器,甚至磁光存儲單元來實現:有研究提出使用Ce:YIG諧振器存儲多比特權重,從而實現片上非易失性光學權重存儲。
此外,來自儲備計算(Reservoir Computing)的基於延遲方案可提供時間上下文:長光延遲線或串聯微環已展示出極高的序列記憶能力。未來構想是:實現一個全光Transformer模塊,其中動態權重矩陣被編程進光學網格,過往token狀態保存在延遲路徑中,使自注意力機制得以光速運行。
最新設計如Lightening-Transformer(動態運行的光子張量核)與HyAtten驗證了這一思路:它們實現了高度並行、全範圍矩陣運算,同時最大限度減少了片外轉換。持續推進集成光學緩存、高帶寬調製器以及光學softmax逼近將推動該方向的發展。
類腦與脈衝光子LLM
另一條前沿路徑是將LLM推理重構為類腦、事件驅動範式。SNN以稀疏的異步事件形式處理數據,天然契合光子的優勢。事實上,已有基於相變神經元和激光脈衝的全光脈衝神經網絡在芯片上實現。
人們設想可以將token流編碼為光學脈衝,通過具有突觸權重的光子SNN實現序列處理。混合光子-自旋電子設計在此可發揮作用:自旋電子器件(如磁隧道結、相變突觸)可提供緊湊的非易失性權重存儲,並可與光神經元接口。
近期關於磁光存儲的光子片上權重研究、利用極端稀疏性的光子類腦加速器研究表明,在光子芯片中嵌入非線性、事件驅動組件是可行的。這類架構可利用數據稀疏性(大多數token僅弱激活網絡),僅在事件發生時更新權重,從而顯著降低能耗。
在光子類腦硬件上探索脈衝注意力模型或稀疏Transformer變種,是未來低功耗LLM推理的令人興奮的發展方向。
系統集成與協同設計
最後,在光子平台上擴展LLM需跨層次的協同設計。這包括將光子處理器與先進的光學I/O和存儲層次結構整合,以及從算法層面匹配硬件特性。例如,近期在商用代工廠製造的全集成光子DNN芯片展示了在芯片內全光完成神經網絡計算的可能性。
將此類集成擴展到Transformer級別模型將需要密集的波分複用(WDM)、片上傳輸的光學網絡架構(NoC)、以及新型封裝(如共同封裝光學)來提升吞吐量。同時,軟件工具鏈(如量化、並行性、佈局)也需適配光子硬件。
關於光電協同封裝與存內計算架構的努力提供了路線圖:通過將光子張量核與共置的內存和控制邏輯緊密耦合,可緩解馮·諾依曼架構帶來的數據瓶頸。
從長遠來看,成功可能來自“全球協同設計”——即將Transformer算法的稀疏性、低精度、模型分區等特性與非馮·諾依曼的光子芯片能力精確匹配。這些軟硬件的協同創新將釋放光計算在下一代LLM負載中的巨大並行潛能。
結論
光子學的進步正在推動計算技術的變革,其中光電器件與光子平台的集成處於前沿。這一集成催生了光子集成電路(PICs),它們作為超高速人工神經網絡的構建模塊,是新一代計算設備創建的關鍵。這些設備旨在應對機器學習和人工智能應用在醫療診斷、複雜語言處理、電信、高性能計算和沉浸式虛擬環境等多個領域中所帶來的高強度計算需求。
儘管已有諸多進展,傳統電子系統在速度、信號干擾和能效方面仍存在侷限。神經形態光子技術以其超低延遲的特性,作為一種突破性解決方案出現,為人工智能和光神經網絡(ONNs)的發展開闢了新的路徑。本綜述從光子工程和材料科學的角度出發,聚焦神經形態光子系統的最新發展,批判性地分析當前和預期面臨的挑戰,並描繪出克服這些障礙所需的科學與技術創新圖譜。
文章重點介紹多種神經形態光子人工智能加速器,涵蓋從經典光學到複雜的PIC設計的廣泛技術領域。通過詳細的對比分析,特別強調其在每瓦操作次數(operations per watt)方面的運行效率。討論轉向諸如垂直腔面發射激光器(VCSEL)/光子晶體面發射激光器(PCSEL)和基於頻率微梳的加速器等專用技術,突出了在光子調製和波分複用方面的最新創新,以實現神經網絡的高效訓練與推理。
鑑於當前在實現每瓦千萬億次操作(PetaOPs/Watt)計算效率方面存在的技術瓶頸,本文探討了提升這些關鍵性能指標的潛在策略,包括拓撲絕緣體與PCSELs等新興技術,以及提升製造工藝、系統可擴展性與可靠性的手段。本文不僅描繪了當前的技術圖景,也預測了神經形態光子技術在推動人工智能能力邊界方面的未來發展路徑。
總的來説,隨着摩爾定律的終結以及光子版“摩爾定律”的起飛,我們預計將在PIC的成本、可擴展性、可集成性以及總體計算能力方面看到顯著提升。PIC最終將取代IC,成為未來計算系統的核心支柱。
致謝本文作者:
Renjie Li、Wenjie Wei、Qi Xin、Xiaoli Liu、Sixuan Mao、Erik Ma 、Zijian Chen 、Malu Zhang、Haizhou Li、Zhaoyu Zhang
