AMD發佈3nm GPU,推理性能狂飆35倍_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。1小时前
過去幾年,AMD屢創新高。
從第一季度的財務數據看來,AMD季度營收74億美元,同比增長36%。這已是公司連續第四個季度營收加速。其中,數據中心和AI業務的蓬勃發展無疑是公司最強的底氣來源。數據顯示,AMD數據中心部門一季度營收為營收37億美元,同比增長57%,主要得益於AMD EPYC CPU和AMD Instinct GPU銷量的增長。
與此同時,公司第一季度客户收入創紀錄地達到23億美元,同比增長68%,主要得益於市場對最新“Zen 5”AMD Ryzen處理器的強勁需求以及更豐富的產品組合。
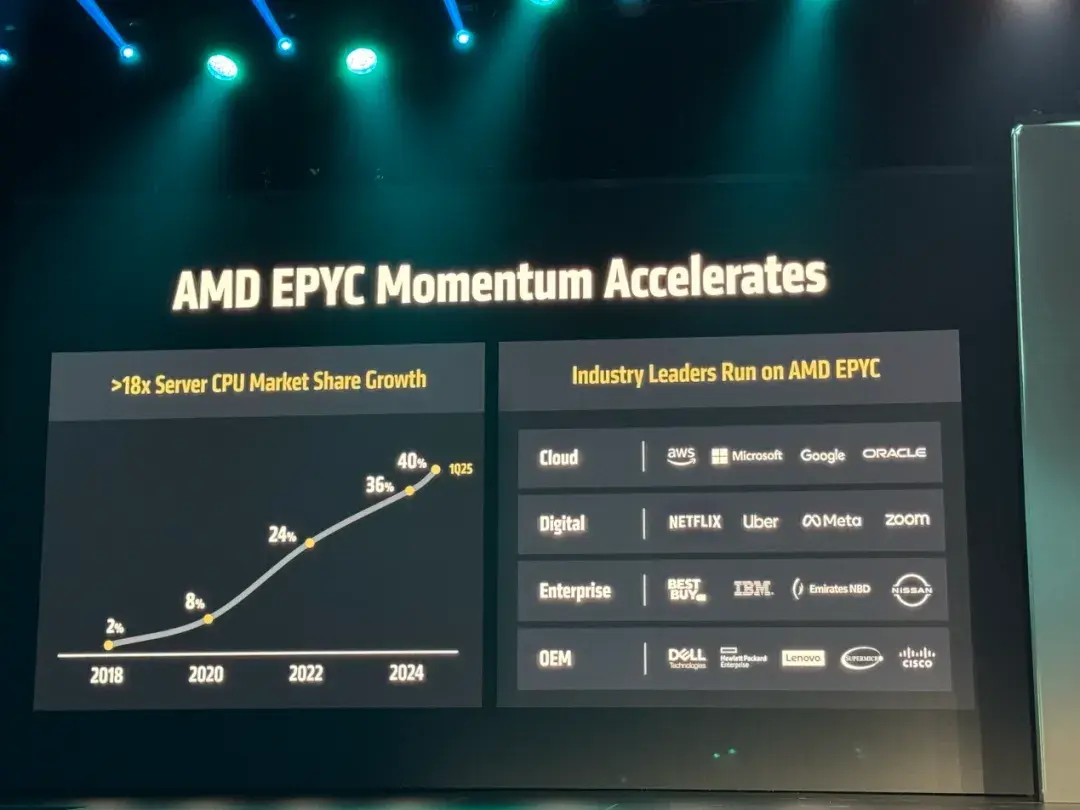
 在今天於舊金山舉辦的“Advancing AI 2025”活動中,AMD董事會主席及首席執行官蘇姿豐(Lisa Su)博士拋出了一個數據。如下圖所示,在2018年的時候,AMD在服務器CPU的市場份額僅為2%,但到了今年一季度,公司在這個市場的佔比已經高達40%,這足以公司看到公司在這個市場的號召力。
在今天於舊金山舉辦的“Advancing AI 2025”活動中,AMD董事會主席及首席執行官蘇姿豐(Lisa Su)博士拋出了一個數據。如下圖所示,在2018年的時候,AMD在服務器CPU的市場份額僅為2%,但到了今年一季度,公司在這個市場的佔比已經高達40%,這足以公司看到公司在這個市場的號召力。
當然,作為本屆大會的重頭戲,Lisa Su博士重申了對AI業務的看好。
她表示,在去年同期,它曾預測到2028年,整個數據中心AI加速器的市場規模會高達5000億美元。在拋出了這個觀點後,有些分析師對這個數據有所質疑。但她補充説:“根據我們現在的觀察,屆時這個數字可能大概率會超過5000億美元。尤其是用於推理的AI需求,增長速度更為驚人。”
 AMD也正在面向這個市場需求,做好全方位的準備。
AMD也正在面向這個市場需求,做好全方位的準備。
AI市場,AMD的全棧實力
能在AI市場突圍,除了本身在CPU和GPU積累領域的積累外,過去多年圍繞AI生態的收購,也是AMD能走到現在的關鍵之一。
相關統計顯示,自 2023 年以來,AMD進行了多次收購,首先是 2023 年收購軟件公司 Mipsology 和 Nod.ai,然後去年繼續收購 AI 實驗室 Silo AI 和數據中心基礎設施提供商 ZT Systems。此次收購熱潮一直持續到今年。
在過去十來天,該公司宣佈收購了硅光子初創公司 Enosemi、編譯器軟件初創公司 Brium 以及人工智能芯片初創公司Untether AI和生成式AI初創公司Lamini背後的團隊。這些收購都有助於改善和增強 AMD 的人工智能能力,尤其是在數據中心市場,該市場是收入增長和盈利潛力最大的市場。
當然,AMD的AI戰略及其與英偉達競爭的能力也受益於其最新一輪收購之前的收購。這包括該公司在2022年收購可編程芯片設計公司賽靈思(Xilinx)和網絡芯片設計公司Pensando,這兩筆收購都為AMD拓展新產品和新市場提供了機會。
 Lisa Su博士在今天的演講中表示,如上圖所示,AMD已經為AI市場積累了多樣化的算力底座。 與此同時,公司也打造了包括開源硬件、開源軟件和開源生態在內的開源開發生態,推動價值和創新。
Lisa Su博士在今天的演講中表示,如上圖所示,AMD已經為AI市場積累了多樣化的算力底座。 與此同時,公司也打造了包括開源硬件、開源軟件和開源生態在內的開源開發生態,推動價值和創新。
AMD數據中心GPU產品營銷總監Mahesh Balasubramanian此前在接受媒體採訪時曾表示,世界上沒有哪家公司能夠解決所有問題,而用人工智能解決世界問題的最佳途徑是建立統一戰線,而統一戰線意味着擁有一個開放的軟件棧,供所有人協作。這也正是AMD願景的關鍵部分。
據介紹,AMD 的開源軟件堆棧 ROCm 已被 OpenAI、微軟、Meta、甲骨文等行業領導者廣泛採用。Meta在 AMD Instinct GPU 上運行其最大、最複雜的模型。ROCm 標配對最大的 AI 框架 PyTorch 的支持,並擁有來自 Hugging Face 高級模型庫的超過一百萬個模型,使客户能夠在 ROCm 軟件和 Instinct GPU 上享受無縫的開箱即用體驗。
此外,圍繞着硬件服務,通過近期收購的 ZT Systems,AMD獲得了重要的服務器和集羣設計專業知識,再疊加上述談到的其他各種收購,AMD打造了能夠加速客户AI部署的全棧AI實力。
正如Balasubramanian 所説:“我們廣泛的產品組合旨在適配各種規模的 AI 解決方案,使其能夠為各種客户設置提供最佳性能,並支持各種規模的 AI 戰略。無論組織處於 AI 之旅的哪個階段,無論他們是在構建模型還是將模型用於最終用例,我們都希望他們能夠與我們交流,瞭解我們如何幫助他們解決最大的問題。”
在今天的“Advancing AI”活動中,AMD也帶來公司芯片和軟件的更新。
MI350系列亮相,MI400同步披露
如大家所見,過去幾年,GPU成為了AI市場的風口浪尖,這也正是AMD Instinct 系列一展所長的地方。如圖所示,繼去年推出MI325X之後,AMD在今年的AI大會上帶來了基於CDNA 4架構的MI350X 和 MI355X AI GPU。
按照他們所説,AMD新一代GPU除了領先於英偉達的同類產品以外,與上一代 AMD MI300X 相比,還能將稱性能提升高達 4 倍,推理速度更將提高 35 倍。這主要得益於向 CDNA 4 架構過渡,並採用了更小、更先進的計算芯片工藝節點。
據介紹,MI350X 和 MI355X 採用相同的底層設計,使用3nm工藝(XCD的製造工藝),集成了1850億晶體管。在HBM方面,均配備高達 288GB 的 HBM3E 內存、高達 8 TB/s 的內存帶寬,並新增了對 FP4 和 FP6 數據類型的支持。其中,AMD MI355X 配備的 HBM3E 顯存容量更是競爭對手 Nvidia GB200 和 B200 GPU 的 1.6 倍,但內存帶寬同樣為 8TB/s。
 和我們在 Nvidia 方案上看到的那樣,AMD GPU更強大的性能也帶來了功耗的增加。不過,MI350X 還能適用於總板級功耗 (TBP) 較低的風冷解決方案,但 MI355X 則將功耗進一步提升,滿足最高性能的液冷系統需求。
和我們在 Nvidia 方案上看到的那樣,AMD GPU更強大的性能也帶來了功耗的增加。不過,MI350X 還能適用於總板級功耗 (TBP) 較低的風冷解決方案,但 MI355X 則將功耗進一步提升,滿足最高性能的液冷系統需求。
如上圖所示,液冷高性能 MI355X 型號的總板載功耗 (TBP) 最高可達 1400W。這比 MI300X 的 750W 和 MI325X 的 1000W 散熱能力有了顯著提升。不過,AMD強調,性能密度的提高使其客户能夠在單個機架中塞入更多性能,從而降低至關重要的每 TCO(總體擁有成本)性能指標。
 得益於這些配置,AMD 聲稱,MI355X 其峯值 FP64/FP32 性能比 Nvidia 芯片高出 2 倍。無論是在訓練還是推理方面,AMD新的GPU也能獲得不小的提升。據介紹,與B200相比,使用MI355X ,能在相同成本的前提下,獲得高達40%的tokens增加。換而言之,AMD這個方案進一步降低了推理成本。
得益於這些配置,AMD 聲稱,MI355X 其峯值 FP64/FP32 性能比 Nvidia 芯片高出 2 倍。無論是在訓練還是推理方面,AMD新的GPU也能獲得不小的提升。據介紹,與B200相比,使用MI355X ,能在相同成本的前提下,獲得高達40%的tokens增加。換而言之,AMD這個方案進一步降低了推理成本。
在發佈會現場,AMD還展示了公司基於MI250系列打造的Rack-Scale解決方案。其中,DLC 機架配備 128 個 MI355X GPU 和 36TB HBM3E,這得益於液冷子系統提供的更高密度,從而支持使用更小的節點尺寸。AC 解決方案則最高可配備 64 個 GPU 和 18TB HBM3E,利用更大的節點通過風冷散熱。
 在介紹MI350系列的時候,AMD強調,新的GPU延續了公司在封裝和Chiplet方面的優勢。其中,應用在XCD 在 IOD 之上的 3D 混合鍵合堆疊意味着垂直連接芯片的帶寬比使用 2.5D 中介層技術所能實現的帶寬要大得多,這使得整個 GPU 封裝比其他方式小得多。而I/O 芯片和 HBM 堆棧使用台積電的 CoWoS-S 封裝以 2.5D 方式連接,這是目前將芯片連接在一起的一種成熟方法。
在介紹MI350系列的時候,AMD強調,新的GPU延續了公司在封裝和Chiplet方面的優勢。其中,應用在XCD 在 IOD 之上的 3D 混合鍵合堆疊意味着垂直連接芯片的帶寬比使用 2.5D 中介層技術所能實現的帶寬要大得多,這使得整個 GPU 封裝比其他方式小得多。而I/O 芯片和 HBM 堆棧使用台積電的 CoWoS-S 封裝以 2.5D 方式連接,這是目前將芯片連接在一起的一種成熟方法。
 具體而言,該芯片共包含八個 XCD Chiplet,每個chiplet啓用 32 個計算單元 (CU),總計 256 個 CU。其中,XCD 芯片從上一代的 5nm 工藝過渡到採用台積電 N3P 工藝節點生產的 MI350 系列芯片,使得整個芯片集成的晶體管數量比上一代的 1530 億個晶體管預算增加了 21%。
具體而言,該芯片共包含八個 XCD Chiplet,每個chiplet啓用 32 個計算單元 (CU),總計 256 個 CU。其中,XCD 芯片從上一代的 5nm 工藝過渡到採用台積電 N3P 工藝節點生產的 MI350 系列芯片,使得整個芯片集成的晶體管數量比上一代的 1530 億個晶體管預算增加了 21%。
 來到I/O Die (IOD) ,雖然仍然使用 N6 工藝,但 AMD 已將 IOD 從四個 Tile 減少到兩個。通過這個設計,AMD 可以在兩個 I/O 芯片之間以更寬的總線運行 Infinity Fabric 高級封裝互連使 AMD 能夠將 Infinity Fabric 總線寬度翻倍,將對分帶寬提升至高達 5.5 TB/s,同時通過降低總線頻率和電壓來降低功耗。這降低了非核心功耗,從而將更多功耗用於計算。
來到I/O Die (IOD) ,雖然仍然使用 N6 工藝,但 AMD 已將 IOD 從四個 Tile 減少到兩個。通過這個設計,AMD 可以在兩個 I/O 芯片之間以更寬的總線運行 Infinity Fabric 高級封裝互連使 AMD 能夠將 Infinity Fabric 總線寬度翻倍,將對分帶寬提升至高達 5.5 TB/s,同時通過降低總線頻率和電壓來降低功耗。這降低了非核心功耗,從而將更多功耗用於計算。
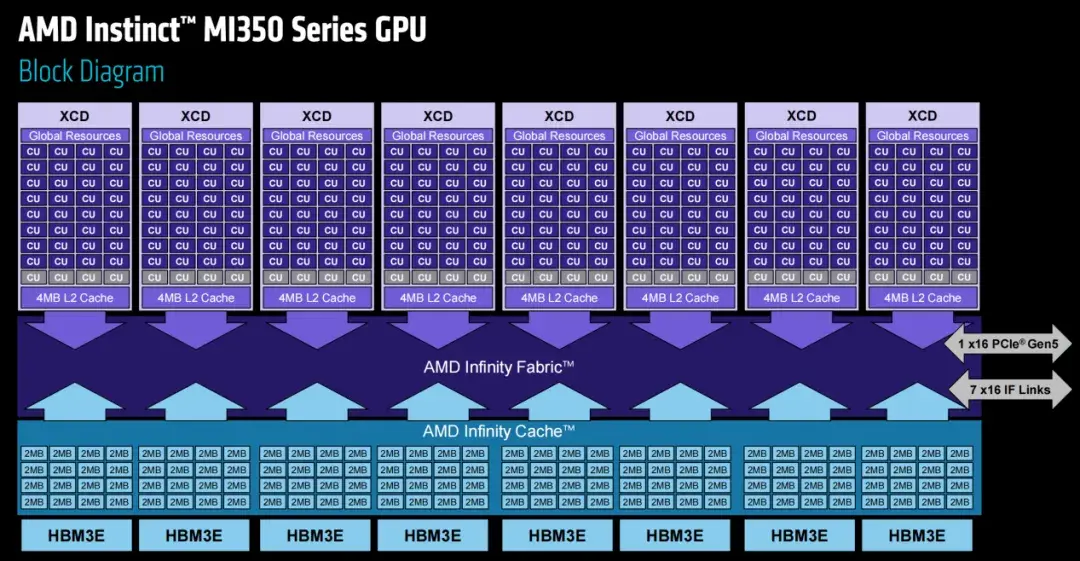 如上圖所示,每個 XCD 總共包含 32 個計算單元和 128 個矩陣單元,其中 8 個 XCD 組合起來可組成 256 個計算單元和 1024 個矩陣核心。每個 GPU 芯片都有一個 HBM3E 堆棧,其中包含 12 個垂直堆疊的 DDR5 DRAM,每個堆棧互連 36 GB,並以 8 Gb/秒的速率運行。MI350 系列擁有 8 個堆棧和 288 GB 的容量,可在 128 個通道上驅動 8 TB/秒的總內存帶寬。HBM3E 內存和 Infinity Fabric 互連之間有一層 Infinity Cache 內存,用於將內存連接到 XCD。
如上圖所示,每個 XCD 總共包含 32 個計算單元和 128 個矩陣單元,其中 8 個 XCD 組合起來可組成 256 個計算單元和 1024 個矩陣核心。每個 GPU 芯片都有一個 HBM3E 堆棧,其中包含 12 個垂直堆疊的 DDR5 DRAM,每個堆棧互連 36 GB,並以 8 Gb/秒的速率運行。MI350 系列擁有 8 個堆棧和 288 GB 的容量,可在 128 個通道上驅動 8 TB/秒的總內存帶寬。HBM3E 內存和 Infinity Fabric 互連之間有一層 Infinity Cache 內存,用於將內存連接到 XCD。
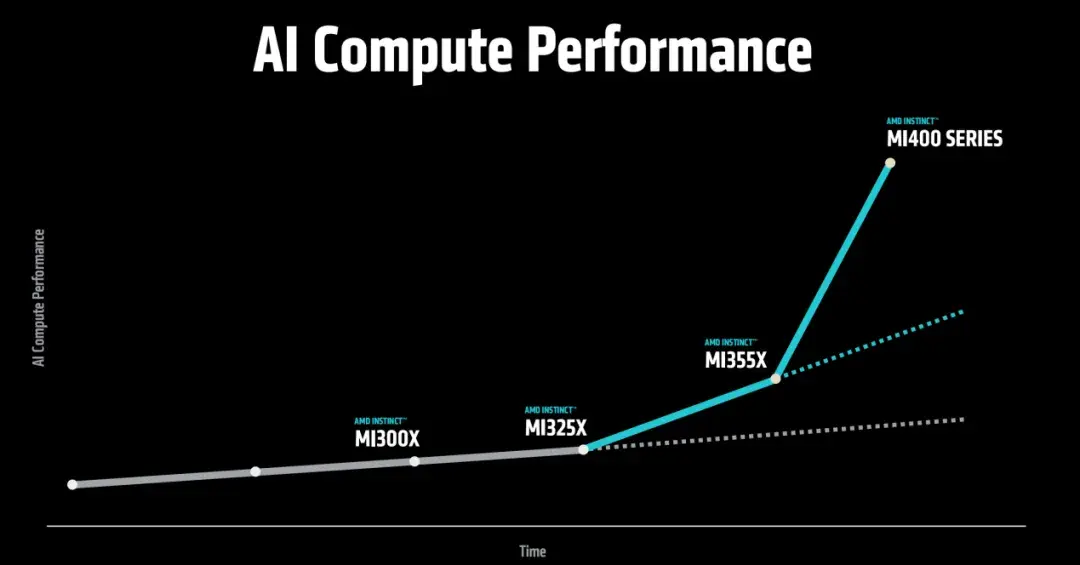
 在介紹了MI350系列以後,AMD又披露了公司的下一代的MI400系列產品。據介紹,AMD MI400 GPU 系列將於 2026 年推出,能夠執行40 petaflops(FP4)和20 petaflops(FP8),的運算,是今年推出的旗艦產品 MI355X 的兩倍。
在介紹了MI350系列以後,AMD又披露了公司的下一代的MI400系列產品。據介紹,AMD MI400 GPU 系列將於 2026 年推出,能夠執行40 petaflops(FP4)和20 petaflops(FP8),的運算,是今年推出的旗艦產品 MI355X 的兩倍。
與 MI350 系列相比,MI400 系列基於 HBM4 標準,將內存容量提升至 432 GB,內存帶寬將達到 19.6 TBps,同樣是上一代產品的兩倍多。MI400 系列還將支持每 GPU 300 GBps 的橫向擴展帶寬容量。
 屆時,AMD 還計劃將 MI400 系列與其下一代 EPYC“Venice”CPU 和 Pensando“Vulcano”NIC 配對,為一個叫做 Helios AI 的機架提供動力。
屆時,AMD 還計劃將 MI400 系列與其下一代 EPYC“Venice”CPU 和 Pensando“Vulcano”NIC 配對,為一個叫做 Helios AI 的機架提供動力。
據介紹,Helios 機架將由 72 個 MI400 GPU 組成,使其擁有 31 TB 的 HBM4 顯存容量、1.4 PBps 的顯存帶寬和 260 TBps 的擴展帶寬。這將使其能夠實現每秒 2.9 exaflops 的 FP4 計算能力和每秒 1.4 exaflops 的 FP8 計算能力。該機架的擴展帶寬也將達到 43 TBps。AMD透露,與定於明年推出的 Nvidia Vera Rubin 平台相比,Helios 機架將配備相同數量的 GPU 和擴展帶寬,以及大致相同的 FP4 和 FP8 性能。
AMD同時表示,Helio 是一款雙寬機架,這主要是因為AMD 及其主要合作伙伴認為,這是“複雜性和可靠性之間的正確設計點”。
 寫在最後
寫在最後
在上文中,我們提到了AMD下一代 EPYC處理器——基於ZEN 6架構的 “Venice”。
據介紹,該CPU使用台積電2納米工藝,配備多達 256 個核心,比當前一代 EPYC “Turin” 處理器的核心數量增加了 33%。與現有的第五代 EPYC“Turin”9005 系列處理器相比,新產品的性能將提高高達 70%。此外,新款 EPYC “Venice” 處理器的單路內存帶寬將提升一倍以上,達到 1.6 TB/s(高於公司現有 CPU 的 614 GB/s),以確保高性能 Zen 6 核心始終保持數據暢通。
“Venice 進一步拓展了AMD在數據中心各個重要領域的領導地位。”Lisa Su博士在演講中強調。
 除了上述產品以外,AMD在本屆峯會上的另一個硬件亮點則是在網絡方面。眾所周知,為了更好的增加系統的擴展能力,他們多年前收購了Pensando,以增強公司在網絡拓展方面的能力。如他們所説,模型大小每三年增加1000倍,訓練數據集每八個月增加2倍。但晶體管密度每兩年增加兩倍。
除了上述產品以外,AMD在本屆峯會上的另一個硬件亮點則是在網絡方面。眾所周知,為了更好的增加系統的擴展能力,他們多年前收購了Pensando,以增強公司在網絡拓展方面的能力。如他們所説,模型大小每三年增加1000倍,訓練數據集每八個月增加2倍。但晶體管密度每兩年增加兩倍。
為此,AMD認為,開放系統和以太網是未來分佈式系統的基礎,公司目前也正在出貨Pollara 400 AI 網卡——一款集成了 UltraEthernet 的 400G 設備。據介紹,該產品搭載 AMD P4 可編程引擎,支持最新的 RDMA 軟件,並提供多項新功能,以優化和增強高速網絡的可靠性和可擴展性。
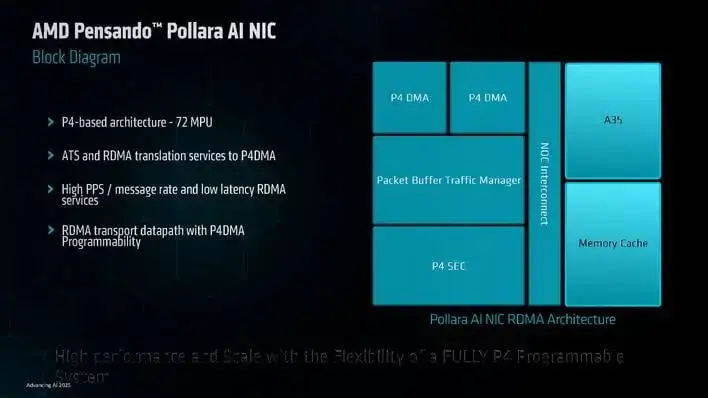 AMD 指出,當使用 AMD 版本的 NVIDIA NCCL(稱為 RCCL,用於橫向擴展集體通信)時,它的速度更快,比 NVIDIA ConnectX-7 快約 10%,比 Broadcom Thor2 快約 20%。這意義重大,因為如果通信效率低下,可能會導致 GPU 空閒,從而降低整體工作負載的運行速度。
AMD 指出,當使用 AMD 版本的 NVIDIA NCCL(稱為 RCCL,用於橫向擴展集體通信)時,它的速度更快,比 NVIDIA ConnectX-7 快約 10%,比 Broadcom Thor2 快約 20%。這意義重大,因為如果通信效率低下,可能會導致 GPU 空閒,從而降低整體工作負載的運行速度。
 同時,隨着下一代 AMD“Helios”機架規模架構的出現,AMD還計劃使用 UALink 1.0 來處理其擴展。作為NVIDIA NVLink 5.0 的開放替代方案,AMD 表示其擴展能力幾乎是英偉達的兩倍,而且還能集成來自多家供應商的組件。AMD 還計劃到2026年推出一款名為 Vulcano的800G NIC,一款適用於下一代 PCIe Gen6 集羣以及 UALink 和 UltraEthernet 的產品。
同時,隨着下一代 AMD“Helios”機架規模架構的出現,AMD還計劃使用 UALink 1.0 來處理其擴展。作為NVIDIA NVLink 5.0 的開放替代方案,AMD 表示其擴展能力幾乎是英偉達的兩倍,而且還能集成來自多家供應商的組件。AMD 還計劃到2026年推出一款名為 Vulcano的800G NIC,一款適用於下一代 PCIe Gen6 集羣以及 UALink 和 UltraEthernet 的產品。
 此外,AMD還帶來了全新的AMD ROCm 7 和 AMD 開發者雲.
此外,AMD還帶來了全新的AMD ROCm 7 和 AMD 開發者雲.
首先看ROCm 7,據AMD介紹,推理是 ROCm 7 最大的重點領域,在 AI 工作負載中性能提升高達 3.5 倍。細分性能提升。與 ROCm 6 相比,新一代ROCm 的Llama 3.1 70B 性能提升高達 3.2 倍,Qwen2-72B 性能提升高達 3.4 倍,Deep Seek R1 性能提升高達 3.8 倍。至於訓練性能,ROCm 7 仍然比 ROCm 6 有顯著提升,比 Llama 2 70B、Llama 3.1 8B 和 Quen 1.5 7B 提升了 3 倍。
全新 ROCm 軟件堆棧還將擴展到企業 AI,提供完整的端到端解決方案、安全的數據集成和便捷的部署。該軟件堆棧將與 GPU、CPU 和 DPU 協同工作,並支持各種工作負載,重點關注 GenAI 工作負載。
“與 ROCm 7 相輔相成的是 AMD 開發者雲,現已面向全球開發者和開源社區開放。這個完全託管的環境可即時訪問 AMD Instinct MI300X GPU,無需任何硬件投資或本地設置。”AMD強調。
在這些軟硬件的支持下,AMD和AI的未來,更可期。