任務驅動的納米AI,如何讓AI搜索進入3.0時代?_風聞
陆玖商业评论-真相只能揭露,无法接近。1小时前
從納米開始,搜索引擎不再是一個“無情的信息檢索工具”,而是一個會自主拆解問題,制定策略的“即時生產力平台”。AI搜索,至此進入了另一個發展階段。

對於大部分移動互聯網時代的用户來説,“信息孤島”是在信息檢索時,不得不跨越的第一座大山。
舉一個簡單的例子,如果你要策劃一場跨國學術會議,通常要在小紅書上搜索合適的會議場地、在OTA平台上安排對應的機票行程、再在學術數據庫上檢索合適的議題和素材,這還不包括比價驗證和信息核實環節。
如果放在兩年前,接入各大平台的AI搜索,已經能做到將碎片信息歸納整理,或者生成真假難辨的片段答案。
這固然是生成式AI時代初開的“基操”,但也顯而易見,信息鑑別和鏈接跳轉,對用户而言,仍然佔用了大量的時間與精力——甚至在某些時候,鑑別信息的成本超出了在平台間使用“跳島戰術”的成本。
而當互聯網的一隻腳邁入生成式AI時代,簡單的信息歸納和整合,已然不符合越來越挑剔的用户需求,無論是用户一側,還是廠商一側,都在呼喚更AGI化,能力更“全棧”的AI搜索應用。
有基於此,新發布的納米AI超級搜索智能體,某種意義上宣告了“跳島”時代的結束——從納米開始,搜索引擎不再是一個“無情的信息檢索工具”,而是一個會自主拆解問題,制定策略的“即時生產力平台”。AI搜索,至此進入了另一個發展階段。
01 “3.0”階段的AI搜索,應該是什麼樣子?
作為與互聯網相伴而生的“基建型”產品,進入AI時代的搜索引擎,在不到4年的時間裏,已經經歷了三個不斷迭代的發展階段。
哪怕是在大模型時代初期的“1.0”階段,用户在浩如煙海的互聯網,信息檢索仍然逃不開“手動檢索”——輸入合適的關鍵詞,篩選有效信息,並在人工處理後,形成為能直接使用的結果。
2023年以後,信息聚合的步驟被大模型所取代,在此過程中,瀏覽器和搜索引擎只負責根據關鍵詞呈現搜索結果,用户需要通過不同關鍵詞的排列組合精準定位搜索目標,這對於檢索能力的要求自然較高。
根據《Nature》的研究,大多數用户的單次有效信息檢索平均耗時12分鐘,其中60%時間消耗於鏈接跳轉與信息真偽驗證。
360集團副總裁、納米AI負責人梁志輝也曾在AGI Playground大會上分享過傳統搜索的侷限性——在此過程中,超過40%的用户需求僅為網址或資源定位,而60%的問題求解需求被壓縮進關鍵詞匹配的框架中,複雜意圖無法表達。

在Kimi、Perplexity等高性能大模型推出之後,接入互聯網的AI搜索隨之進入2.0時代。
這個階段的顯著特徵是,大模型解析問題直接生成大部分可用的摘要答案,信息整合效率顯著提升。SimilarWeb數據顯示,全球AI問答產品月活用户已經超過5億,也印證了AI搜索市場規模的不斷增長。
但在這個階段,AI搜索的網頁結果進入了“隱藏狀態”,用户需要自行進入鏈接,檢查引用網頁的真實性。即便如此,用户仍然需要掌握Prompt工程技能才能精準提問,就模糊意圖的解析能力而言,這個階段的AI搜索引擎,仍然較為薄弱。
以“策劃親子登山活動”的任務目標為例,這個階段的AI搜索在識別到用户意圖之後,大多數情形下,已經能做到提供景點列表和出行方式推薦,但仍然無法將其拆分為裝備清單、路線規劃、保險購買等子任務。一些特定領域的內容,仍需跳轉到對應的內容平台自行檢索
至於答案本身的準確程度,仍然大量依賴於用户自行驗證。但大量不具備Prompt或者驗證習慣的用户,並沒有識別答案幻覺成分的能力。
斯坦福大學2024年發佈的《AI可信度研究報告》顯示,63%的職場新人首次使用AI時,因未識別幻覺導致工作失誤,且錯誤內容的平均傳播率比人工失誤高40%。換言之,起碼在AI搜索領域,仍然需要通過產品迭代解決答案幻覺和子任務層面的問題。
但當AI搜索進入2025年,以納米AI為代表的搜索智能體,推動AI搜索進入了3.0時代。相較此前“教你做事”的AI+搜索引擎,超級搜索智能體已經可以做到從意圖輸入、自動執行到結果交付的閉環,“幫你做事”已經大部分變成了可能。
具體而言,3.0時代的智能體搜索,已經從標準上與傳統意義的搜索引擎“涇渭分明”:
其一,智能體已經能做到內置任務規劃,用户不必再手動拆解任務單個搜索,做到“搜索即執行”。
其二,在底層大模型層面,打破了不同模型的“次元壁”,通過產品層接入不同模型的長板能力優勢互補,顯著提高輸出內容的專業度和準確度。
其三,通過自研的MCP工具,實現多模態、跨網站數據的深度抓取,以往的“信息孤島”被逐步瓦解,在信息維度層面的認知再度提高。同時也能做到多模態輸出。
其四,結合用户此前的搜索習慣和記憶數據,讓AI不再“失憶”,實現更具深度的個性化搜索體驗。
截至目前,谷歌新發布的AI Mode,已經大部分實現了上述能力,而在國內,自納米AI超級搜索推出以後,超級搜索智能體的產品空白,至此也被填補完成。
02 從問答到交付的“AI搜索範式革命”
在此前舉行的產品發佈會上,360集團創始人周鴻禕指出,之所以選擇用智能體重塑和改造搜索,是因為智能體已成為AI“下半場”的主角——“雖然目前大模型的能力越來越強,但僅有大模型還不夠。大模型相當於大腦,能思考、能生成,但是沒有手和腳,不會用工具,不能直接幹活,落地執行遇到障礙。”

而在目前主流的“工作流”智能體層面,也仍然逃不掉人工編排和設計任務流程。對於一些專業程度較高的任務來説,使用智能體完成工作,仍然有不小的難度。
這就是納米AI迭代至“超級智能體”所要解決的問題。
跟一般的大模型或者智能體不同,納米AI更強調“搜商”,即搜索思維。譬如傳統搜索引擎的終點是信息呈現,而納米AI的起點是用户目標的終極達成。無論是為初創團隊設計股權激勵方案,還是策劃一場跨國學術會議,它都能將開放式需求轉化為可落地的解決方案。
這種能力源於其Multi-Agent架構的深度應用:每個子任務如同被分配給專業團隊的獨立工單,法律條款查詢、模板生成、税務計算等環節在分佈式計算中同步推進,系統即時監控進度並動態糾偏。
更關鍵的是,納米AI通過接入即時API實現了結果的動態進化——當航班價格波動、學術數據庫更新或政策法規調整時,交付文檔會自動觸發二次驗證與修正,確保用户始終掌握最新數據。
這種糾偏帶來的實際體驗提升,在實際場景中尤為顯著。譬如在618期間,美妝商家想要重新設計商品主圖,以此提振點擊率和銷量。在納米AI超級搜索裏,只需輸入這樣一句話,無需多餘提示詞,納米AI即可完成從搜索到結果呈現的一系列工作。
在前期規劃層面,納米AI即會按照搜索結果的有用程度進行重新排序,並進行對應的結果分析,並生成總結和對應分析報告。
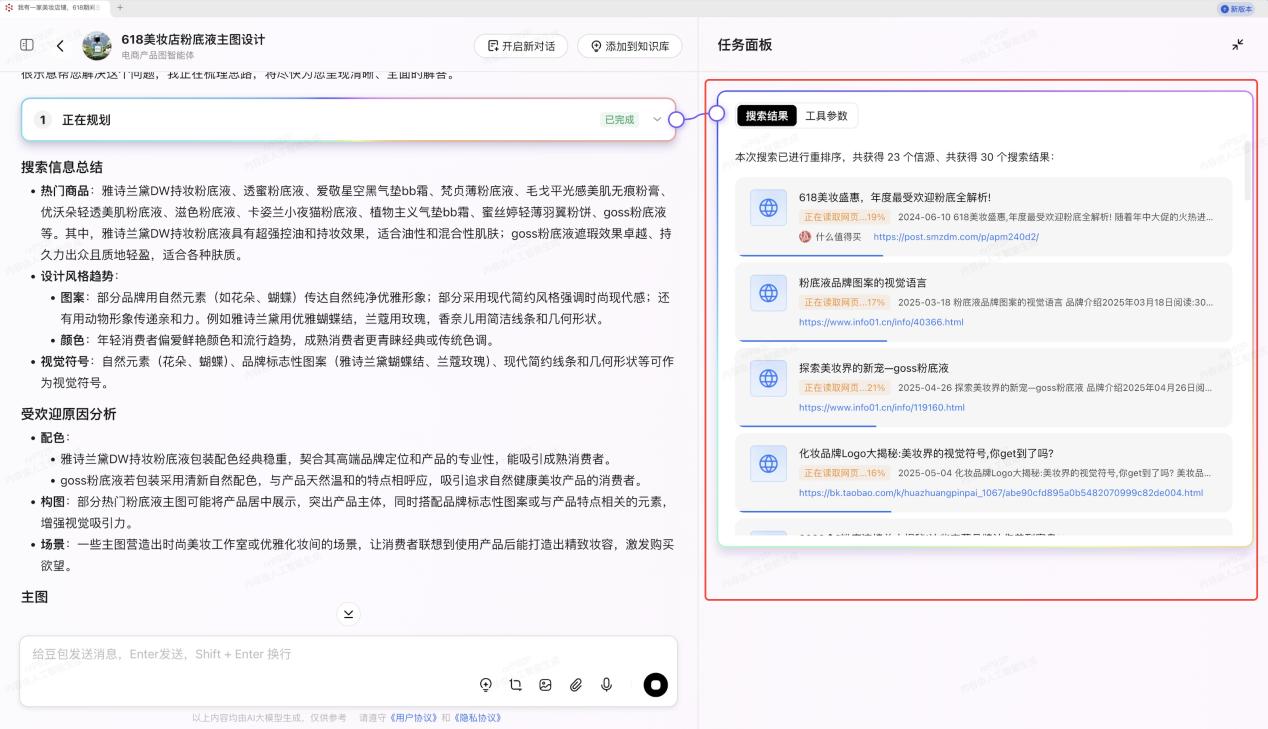
但這也只是第一步,智能體在層層拆解複雜任務的同時,通過深度搜索能力,打破平台間的“信息圍牆”,實現跨平台搜索,方便用户決策。
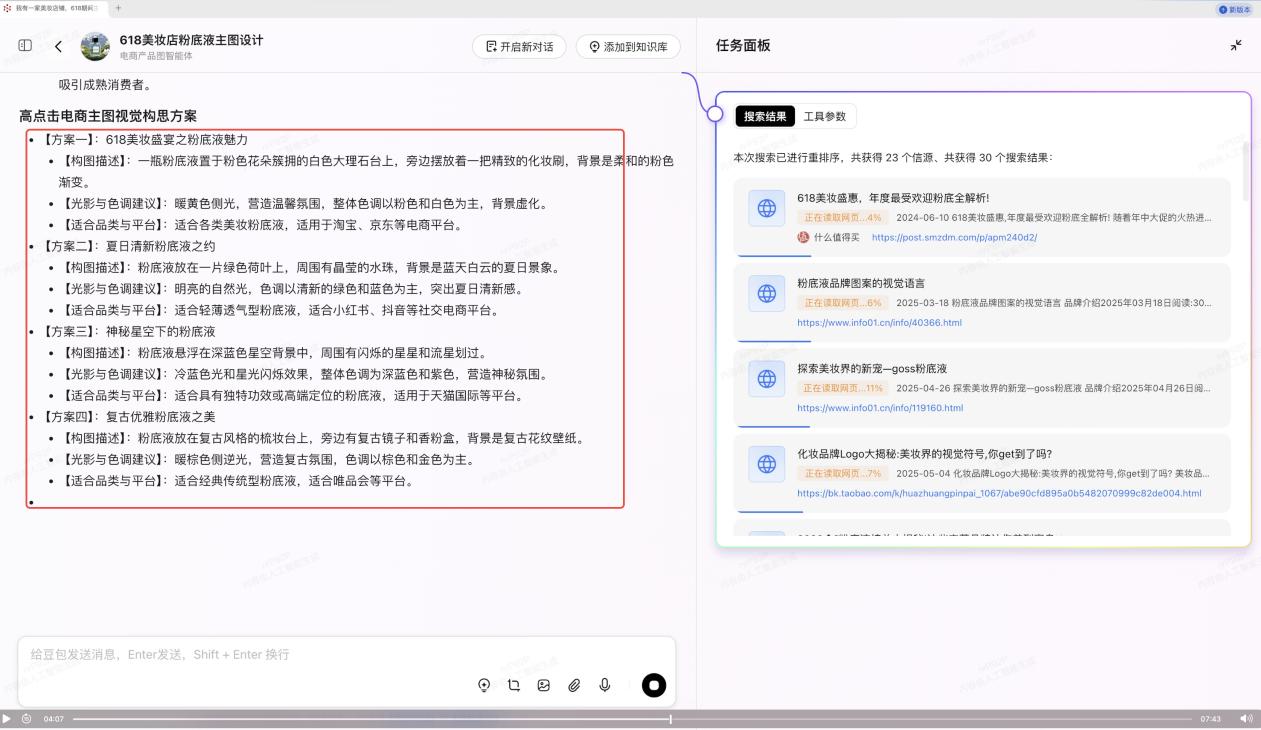
同時在輸出結果層面,用户可以自主選擇生成圖片或者文字方案。在最終的輸出結果上,也按照對應的方案各生成了效果圖,基本達到了可直接商用的狀態。
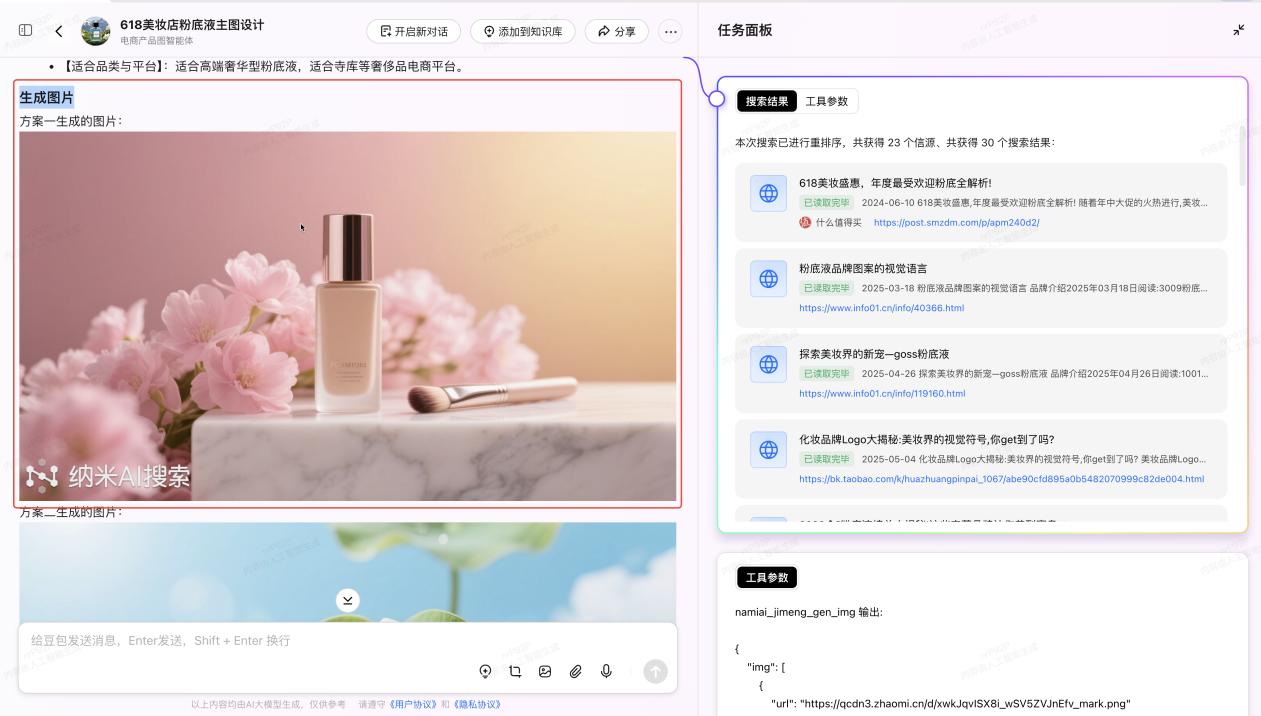
由此可見,搭載超級智能體的納米AI搜索,已經很大程度上脱離了傳統意義上的“工具屬性”——藉助內置的80餘個大模型構成“能力矩陣”,無論是金融模型計算股權激勵的期權定價,還是法律模型審核條款合規性,多模態模型則將枯燥數據轉化為可視化圖表。
這種交付內容的“維度進化”,也標誌着搜索的核心價值正從信息羅列走向智能交付,從被動應答用户輸入的關鍵詞,躍遷為主動理解並終結用户的原始目標。它不再只是一個信息的索引庫,而是整合認知、決策與執行的解決方案引擎。
03 中國智能體的“國際突圍”
截至目前,國際AI行業的競爭已經聚焦於智能體賽道,OpenAI的GPT-5 Agent、Google的Project Astra等巨頭動作頻頻。
在“互聯網女皇”Mary Meeker 發佈的《趨勢——人工智能》專題報告中,也着重提到了三個關鍵詞:競爭白熱化、開源浪潮、中國勢力崛起。
在月度用户活躍量這一核心指標中,中國有兩家公司進入全球市場前5。在中國市場,字節豆包、DeepSeek分列前二之外,Kimi、納米AI緊跟其後,騰訊元寶和百度文心一言則位於第五、第六的位置。
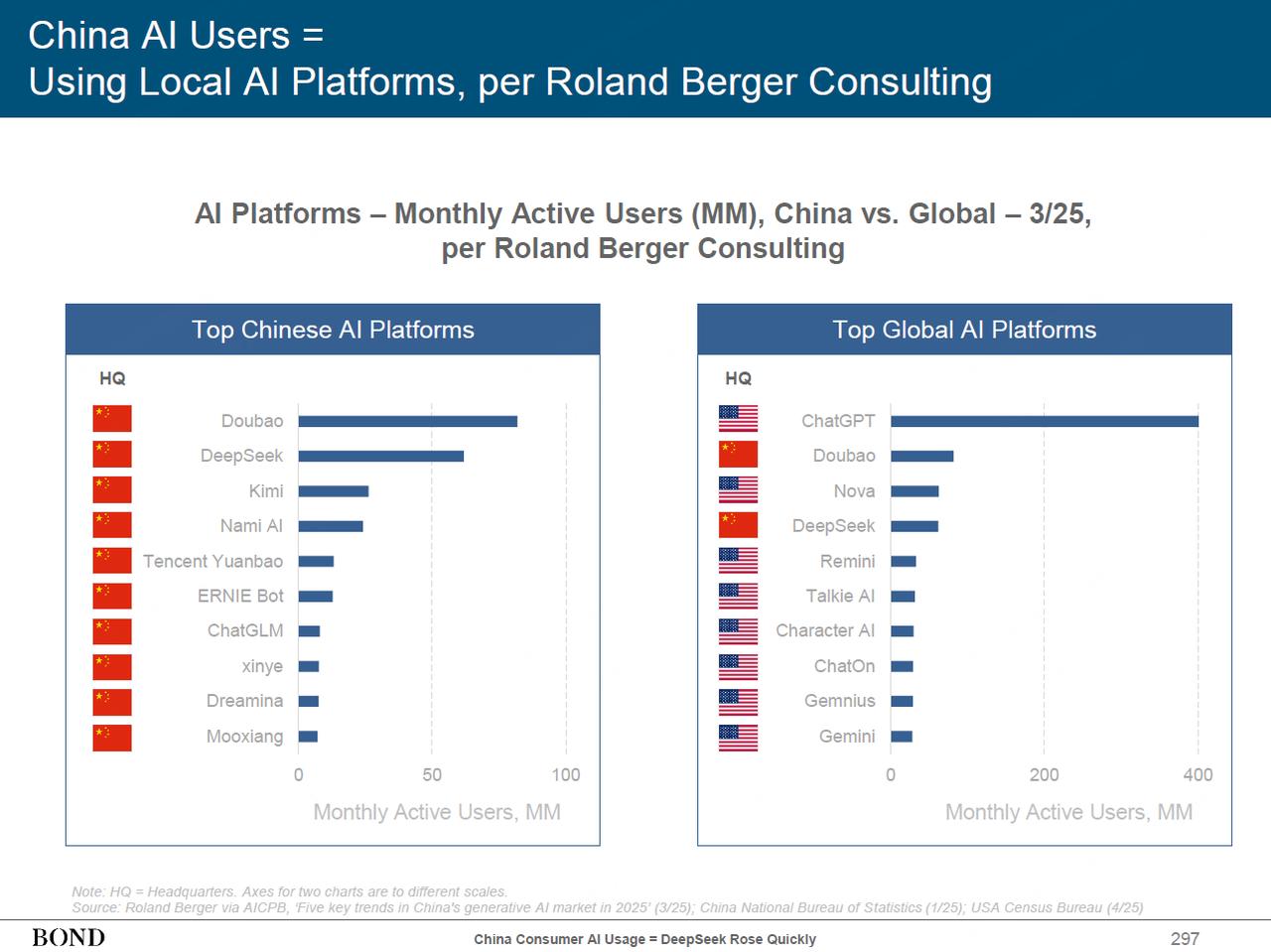
而納米AI,則是中國首個對標國際頂尖水平的AI Agent產品。
這一變化絕非偶然。它不僅驗證了中國頂尖團隊的研發實力已達國際一線,更從實際落地的維度宣告,在代表AGI認知與執行前沿的智能體技術代際上,中國已擺脱單一的跟隨模式,在核心能力構建上實現了與全球頂尖同頻共振,長期以來的“技術鴻溝”正被技術代際的同步所打破。
納米AI將“搜商”貫穿任務執行始終的Agent範式,並不完全是技術性能的追趕,而是一種面向未來產業需求的差異化競爭力。其遠期市場潛力與創新空間上限,正隨着產業AI化的深入而不斷抬升,並最終成為AI行業的“AGI”敍事中,一個重要的“中國支點”——
它不僅能為國內千行百業的智能化升級提供核心引擎,更在國際舞台積極參與,並逐漸爭奪AGI技術範式的定義權,與規則制定進程。最終推動着中國智能體,從局部趕超走向全方位的“國際突圍”。