HBM,爆炸式增長_風聞
半导体产业纵横-半导体产业纵横官方账号-赋能中国半导体产业,我们一直在路上。38分钟前

本文由半導體產業縱橫(ID:ICVIEWS)編譯自medium
HBM,如何推動AI發展?
高帶寬內存(HBM) 是下一代 DRAM(動態隨機存取存儲器)技術,可實現超高速和寬數據傳輸。
HBM 的核心創新在於其獨特的 3D 堆疊結構,其中多個 DRAM 芯片(4 層、8 層甚至 12 層)使用先進的封裝技術垂直堆疊。3D 結構使 HBM 能夠以比 GDDR 等傳統內存解決方案高得多的帶寬(數據傳輸速率)運行。
可以這樣想:HBM 不是將所有內存芯片並排佈置在平板上,而是將它們像多層建築一樣堆疊起來。這種垂直集成與複雜的電氣連接相結合,為數據創造了一條高速公路,從而能夠更快、更高效地與處理器進行通信。

HBM 3D 結構(來源:Semiconductor Engineering)
為什麼高帶寬內存(HBM)對 AI 至關重要?
根據IDTechEx 的報告,全球HBM 市場將在未來十年內增長 15 倍。這種爆炸式增長的核心在於高帶寬內存 (HBM) 以超高帶寬和低延遲為圖形處理單元 (GPU) 提供海量數據流的獨特能力。
GPU 與中央處理器
CPU(中央處理器)託管少數針對順序、邏輯複雜的任務進行了優化的複雜內核,而GPU 則擁有數千個旨在並行處理數據的簡單內核。每個 CPU 核心都具有強大的單線程性能和複雜的控制邏輯。然而,現代 AI 訓練和推理涉及處理數 TB 的參數和中間激活,遠遠超出了幾個 CPU 內核可以有效處理的範圍。
GPU 專為圖形渲染和視頻編碼而設計,因此它們可以同時或並行處理大量相對簡單的計算。這種大規模並行架構使 GPU 成為 AI 訓練和推理的完美之選,這涉及以相對規則的計算模式(一次進行數百萬次乘加運算)處理大量數據集。這就是為什麼 GPU 成為 AI 加速器的核心芯片。

CPU 與 GPU 的比較(來源:Layerstack)
內存帶寬決定 GPU 速度
內存帶寬是指內存子系統每單位時間(通常為每秒)可以傳輸的數據總量。它直接測量處理器(如CPU 或 GPU)從連接的內存 (DRAM) 讀取數據或將結果寫入其的速度。
例如,如果內存系統每秒可以可靠地傳輸100GB 的數據,則其帶寬為 100GB/s。您可以使用以下公式粗略估計帶寬:
內存帶寬(GB/s)= [總線寬度(位) × 有效傳輸速率 (GT/s) ] ÷ 8
Bus Width (bit)(總線寬度(位)):內存接口一次可以並行傳輸多少位數據。更寬的公交車就像在數據高速公路上擁有更多的車道。例如,HBM2E 的接口寬度可以達到 1024 位或更高,遠遠超過 GDDR6 的 32 位。有效傳輸速率(Hz / GT/s):每秒數據傳輸作數。現代高速內存(如 GDDR、HBM)通常使用雙倍數據速率 (DDR) 或四倍數據速率 (QDR) 技術,在時鐘信號的上升沿和下降沿傳輸數據。為了實現更高的內存帶寬,您需要高有效傳輸速率(數據“運行速度快”)和寬總線寬度(許多“數據通道”)。
為什麼 HBM 的 Ultra-Wide Bus 解決了內存瓶頸
在AI 應用程序中,模型的參數可能為數百 GB 甚至 TB。在計算過程中,GPU 經常與內存交換大量參數和中間結果(激活、梯度)。
傳統系統將內存分層到緩存(SRAM) →主內存 (DRAM) →存儲 (SSD/HDD) 中,但由於內存壁問題和處理器利用率不足,當今的 AI 和 HPC 工作負載暴露了這種層次結構的限制。為了防止強大的 GPU 受到數據供應的瓶頸(即避免“飢餓”的 GPU),該行業正在重新劃分內存堆棧:
封裝內HBM:共同封裝的 3D 堆疊 DRAM 距離 GPU 芯片僅幾英寸。CXL 池內存:跨加速器共享 DDR 池。基於NAND 的內存:SLC 優化存儲和 TLC/QLC,適用於較冷的數據層。
高帶寬內存(HBM) 具有更高的吞吐量,可以同時處理來自各個內核的多個內存請求。例如,HBM3E 通過結合高速接口技術,將其數據“高速公路”(總線寬度)大幅擴大到1,024 甚至 2,048 位,從而使每個堆棧的速度達到 1,225 GB/s。
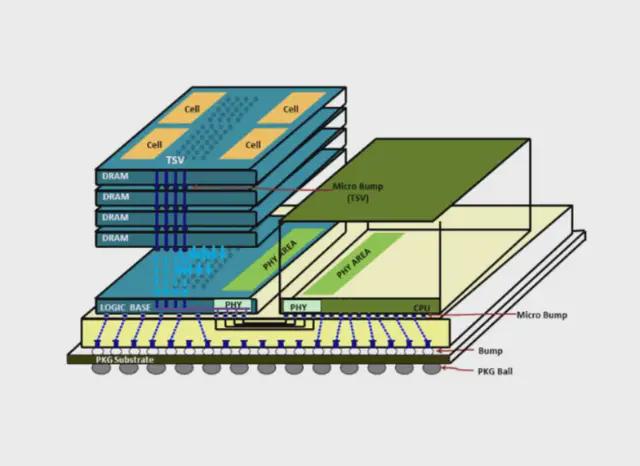
HBM 使用 3D 存儲芯片陣列,垂直堆疊並使用硅通孔 (TSV) 並聯連接。(來源: TOP500)
最新一代HBM3E 使用帶有微凸塊和底部填充的熱壓縮來堆疊 DRAM 芯片,然而,SK 海力士、三星和美光等製造商正在過渡到更先進的封裝技術,例如 HBM4 及更高版本的銅-銅混合鍵合,以增加輸入/輸出、降低功耗、改善散熱、減小電極尺寸等。
視頻隨機存取存儲器(VRAM) 的作用
專為GPU 設計的高速內存稱為 VRAM(視頻隨機存取存儲器)。在當今的高端 AI 和計算中,HBM 是占主導地位的 VRAM 解決方案。

VRAM 是 GPU 的專用內存緩衝區,用於存儲關鍵數據以便快速訪問。(來源: Ms.Code)
典型的顯卡(或AI 加速器)由一個 GPU 芯片與 VRAM 模塊(通常是多個 HBM 堆棧)緊密耦合組成。
以下是GPU 執行計算時的典型數據流:
數據加載:用於計算的初始數據通過PCIe 等接口從速度較慢、較大的 CPU 系統內存 (RAM) 傳輸到 GPU 的專用高速 VRAM (HBM)。並行計算:GPU 的眾多計算內核從高速 VRAM (HBM) 讀取必要的數據段並執行密集的並行計算(例如,矩陣乘法、卷積)。結果暫存:計算的中間或最終結果快速寫回VRAM (HBM) 進行臨時存儲。數據輸出/保存:處理後的數據最終從 VRAM (HBM) 傳輸回 CPU 系統內存 (RAM) 進行進一步處理或存儲,或者在某些情況下(如圖形輸出),直接從 VRAM 輸出到顯示接口。
在圖像識別、自然語言處理(NLP) 和大型語言模型 (LLM) 訓練/推理等 AI 任務中,模型涉及數十億甚至數萬億個參數。計算在很大程度上依賴於 GPU 內核和 VRAM 之間持續、高速的數據交換。
因此,VRAM 的性能,尤其是其高速讀寫海量數據的能力,直接決定了 GPU 整體計算效率的上限。如果 GPU 核心急需的數據(指令、參數、中間結果)由於內存帶寬不足或高延遲而無法按時交付,則計算單元將卡頓,浪費寶貴的計算能力並妨礙最佳性能(形成“內存牆”或內存瓶頸)。
這就是為什麼HBM 憑藉其出色的高帶寬(滿足數據吞吐量需求)和低延遲(減少內核等待時間)已成為 NVIDIA H100 和 AMD MI300X 等高性能 AI 專用 GPU 不可替代的內存解決方案。
近距離觀察HBM:3D結構
HBM 的核心創新在於其獨特的 “3D” 結構。HBM 不是傳統的平面存儲芯片,而是像摩天大樓一樣垂直堆疊多個標準 DRAM 芯片(稱為 DRAM 芯片)。然後,這些芯片通過密集的硅通孔 (TSV) 在垂直方向上電氣互連。
每個DRAM 芯片都使用極薄的粘合劑材料進行粘合,最初通過微凸塊在各層之間互連。
HBM 高性能的關鍵在於三個相互關聯的核心技術要素:
堆棧:垂直堆疊多層DRAM 芯片可實現單位面積存儲容量的指數級增長(例如,8 層堆棧提供的容量是單個芯片的 8 倍),節省空間並實現更大的容量。TSV(硅通孔):在堆疊的 DRAM 芯片內蝕刻小孔,並填充導電材料以形成垂直通道(直徑僅為 5-10 微米)。這種高密度、短距離的垂直佈線直接連接上下層的信號、電源和接地線,實現了傳統平面佈線無法實現的極寬總線寬度(超過 1024 位)。中介層:一種精密的硅或有機襯底,可同時承載GPU 芯片和 HBM 堆棧。它使用其表面和內部高密度佈線(走線寬度/間距低至微米級)在極短的距離內將 HBM 堆棧的超寬接口與 GPU 芯片的高速 I/O 端口互連。
下圖説明了GDDR 和 HBM 之間的基本結構差異。

GDDR 和 HBM 的區別(來源: PC Perspective)
GDDR 的工作原理是什麼?
多個獨立的DRAM 芯片(單個組件)在 BGA 封裝中平面排列,並安裝在 PCB 基板上的 GPU 芯片周圍。
每個DRAM 組件都需要獨立、相對較長的 PCB 走線才能連接到 GPU。這不僅會佔用寶貴的 PCB 面積,增加電路板尺寸和成本,而且長走線會帶來顯著的信號傳輸延遲、信號完整性 (SI) 挑戰(如反射和串擾)和更高的驅動功耗。總線寬度受物理可路由通道數的限制(通常最大為 256 位或 384 位)。
HBM 是如何工作的?
預先垂直堆疊的HBM 模塊(包含多個 DRAM 芯片)與 GPU 芯片並排放置在相同的高密度中介層襯底上。
堆疊結構本身大大節省了平面空間(利用Z 軸)。因此,靠近 GPU(在同一中介層上)導致極短的互連佈線長度(毫米級甚至更短)和其他優勢,包括:
超高空間利用率海量存儲容量超寬總線寬度(通過TSV 和轉接板實現)超低信號延遲出色的信號完整性顯著降低通信功耗
綜上所述,HBM 通過 3D 堆疊 DRAM 封裝並與 GPU 在 2.5D 中介層上緊密集成,完美克服了傳統 GDDR 的物理限制,從而在帶寬和革命性的能效方面實現了數量級的提升。
硅通孔(TSV) 技術在高帶寬存儲器 (HBM) 中的重要性
在高帶寬存儲器(HBM) 的堆疊結構中,硅通孔 (TSV) 技術在實現 DRAM 芯片之間的垂直互連方面發揮着至關重要的作用。
TSV 是蝕刻在硅芯片中的微孔(通常直徑為 5-50 微米),並填充有銅等導電材料,形成垂直電通道。這些互連具有幾個關鍵優勢:
超短互連:TSV 允許信號、電源和接地線直接垂直穿透硅芯片,在相鄰 DRAM 層之間提供儘可能短的電氣連接路徑(約 50-100 微米)。這繞過了傳統上使用的較長的引線鍵合或倒裝芯片互連方法,這些方法需要圍繞芯片邊緣進行佈線。高密度互連:芯片內密集封裝了數千到數十萬個TSV,與平面封裝方法相比,HBM 實現了更高的互連密度和並行通道數。這支持超寬總線寬度,例如 1024 位或 2048 位,這對於高帶寬至關重要。高速、低功耗運行:較短的垂直連接路徑可顯著降低信號傳輸延遲,最大限度地減少信號衰減和失真,並降低驅動互連所需的功率。與具有較長封裝引線或PCB 走線的傳統 DRAM 芯片佈置相比,基於 TSV 的垂直互連可提供更快、更高效和低功耗的信號傳輸。
這種先進的垂直互連結構是HBM 能夠同時提供高存儲密度、超高帶寬和低功耗的基礎。
中介層在高帶寬存儲器(HBM) 中的作用
HBM 堆棧和 GPU 芯片不直接焊接到普通 PCB 上。相反,它們被共同集成到稱為中介層的精確中間襯底上。中介層本質上是具有超精細布線能力(走線寬度/間距低至 1 微米或更小)的無源硅襯底或高級有機襯底。
中介層在HBM 系統中起着至關重要的作用:
Bearing Platform: 它為 GPU 芯片和 HBM 堆棧芯片提供了一個物理安裝平台。超高密度互連:其核心價值在於能夠在其表面和內部製造大量(數千到數萬個)非常窄間距(微米級)的金屬跡線(再分佈層- RDL)。這些痕跡就像高架公路或密集的高速道路網絡。連接橋:它使用這些超密集走線在非常短的距離(幾毫米到幾十毫米)內以低損耗精確連接HBM 堆棧的超寬接口(球柵陣列,通常包含數千個觸點)與 GPU 芯片的巨大高速 I/O 端口(微凸塊陣列)。
同樣,HBM 實現超高帶寬的關鍵不僅僅是提高數據傳輸的“單通道速度”(時鐘頻率),而是通過使用 TSV 和中介層共同創建數量驚人的“並行數據通道”(即超寬總線寬度),從而能夠一次傳輸大量數據。
HBM 設計面臨的主要挑戰是什麼?
自第一代HBM 以來,該技術已經發展了六代,包括 HBM2、HBM2E、HBM3、HBM3E 和計劃中中的 HBM4。隨着 2025 年 HBM3E 量產競爭的白熱化,下一代 HBM4 的競爭已經開始。
在這種持續的技術升級中,封裝技術越來越成為競爭的焦點,尤其是在散熱瓶頸變得更加明顯的情況下。如果堆疊芯片的積熱不能得到有效控制,將直接導致性能下降、壽命縮短和功能異常。這使得熱管理以及容量和帶寬成為高級內存開發的三個核心指標之一。
作為HBM 高速技術的基石,TSV (Through-Silicon Via) 技術通過在 DRAM 芯片上蝕刻數千個微孔來構建垂直電極通道,就像 “HBM 摩天大樓” 中連接樓層的 “高速電梯” 一樣。
然而,隨着HBM3E 中的堆疊層躍升至 12 層,散熱壓力和翹曲問題帶來了雙重挑戰。為了保持總厚度,DRAM 芯片需要比 8 層 HBM3 薄 40%,而減薄過程引入了與結構變形相關的新技術障礙。
要突破堆疊超過12 層的物理限制,混合鍵合技術可能成為必然選擇。雖然該解決方案可以實現微米級 3D 互連,但預計包裝成本會增加 30% 以上。
從HBM4 到 HBM8 的長期路線圖
未來HBM 的 I/O 數量將增加三倍,HBM5、HBM7 和 HBM8 將增加三倍,同時堆棧層、單層容量和引腳速率也將得到改進。此外,鍵合技術將從目前的微凸塊過渡到銅對銅直接鍵合方法(混合鍵合)。然而,隨着這種代際演變的發生,HBM 堆棧產生的熱量將逐漸增加,需要增強的熱管理。

HBM 路線圖 (來源: KAIST Teralab)
HBM4:集成 LPDDR 控制器
在傳統的HBM 堆棧中,通常具有定製的 DRAM 芯片。

HBM4(來源:KAIST Teralab)
然而,在HBM4 中,HBM 基礎芯片有望集成一個 LPDDR 控制器,為 HBM 存儲系統增加一個額外的層,並有效利用傳統配置中未使用的容量和帶寬資源。
HBM5:面向 AI 工作負載的 NMC 簡介
遷移到HBM5 後,內存堆棧預計將包含 NMC (Near-Memory Computing) 模塊。這種集成將降低 HBM 和 AI xPU 之間的帶寬要求,改善計算定位,並提高整體系統性能和能效。

HBM5(來源:KAIST Teralab)
HBM6: 雙塔結構和 NMC 集成
目前,每個HBM 堆棧都由一個 Base Die 和一個單塔結構的 DRAM 堆棧組成。
然而,對於HBM6,預計一個大型 Base Die 將支持兩個 DRAM 堆棧,形成雙塔物理設計。

HBM6(來源:KAIST Teralab)
此外,NMC 單元將位於堆棧下方。這一代還將看到從當前的硅中介層/Silicon Bridge 連接過渡到硅玻璃複合中介層,以促進多個 GPU 模塊的集成。
HBM7: 多層存儲系統和嵌入式冷卻
對於HBM7,預計有兩大發展:引入由 HBM 和 HBF(高帶寬閃存)組成的多級存儲系統,以及在 DRAM 堆棧中集成多功能橋接,以提高信號質量並增加更多功能。
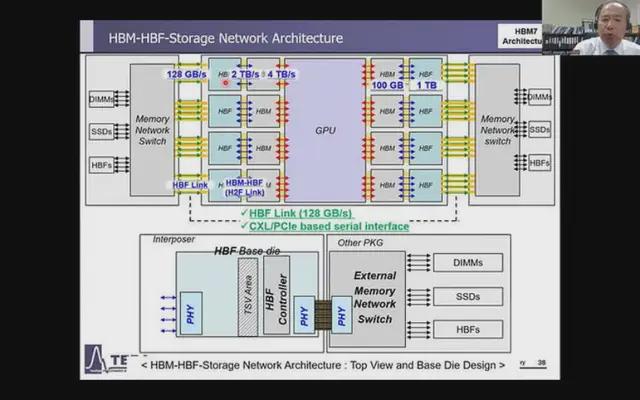
HBM7(來源:KAIST Teralab)
此外,還將引入嵌入式冷卻系統,以解決這些系統的高性能功能產生的熱量。
HBM8: 增強型芯片複合材料和集成冷卻
HBM8 增加了一種複雜的芯片複合材料,它不僅利用了HBM 內存封裝的正面,而且還在背面集成了存儲擴展。此外,熱管理將緊密集成到結構中,以應對日益增長的熱量挑戰。
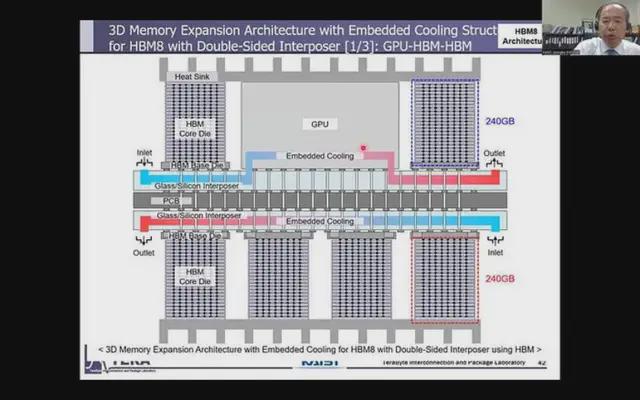
HBM8(來源:KAIST Teralab)
展望未來:HBM 在 AI 計算中的未來
儘管高帶寬內存(HBM) 在 AI 計算中發揮着不可替代的作用,但高成本仍然是廣泛採用的重大障礙。
為了克服這一挑戰,該行業可能會尋求兩條可能的途徑:
“HBM-Lite” 的開發: 此版本旨在通過簡化當前的 HBM 架構來優化成本,而不會為要求較低的應用犧牲關鍵性能。混合存儲架構:一種分層方法,在系統級別將HBM 與傳統內存類型(如 DDR5 和 GDDR7)相結合。在這種設置中,HBM 將管理“熱數據”——需要快速處理的高優先級信息——而 DDR5/GDDR7 將處理“冷數據”,即不常訪問的信息。這種混合策略可以提供靈活的解決方案,從而有效滿足特定需求。對於高端 AI 訓練,完整的 HBM 架構將確保所需的吞吐量。對於邊緣推理,混合解決方案將優化總擁有成本 (TCO),平衡性能與經濟性。
KAIST 的長期路線圖強調了 HBM 令人興奮的未來,在內存架構、AI 工作負載和散熱解決方案方面不斷進步。隨着這些創新的展開,HBM 將不斷發展以滿足高帶寬、低延遲應用不斷增長的需求,確保其在下一代計算的前沿地位。
*聲明:本文系原作者創作。文章內容系其個人觀點,我方轉載僅為分享與討論,不代表我方贊成或認同,如有異議,請聯繫後台。