用大腦“説話”:這項技術讓失語者再次發聲_風聞
返朴-返朴官方账号-科普中国子品牌,倡导“溯源守拙,问学求新”。22分钟前
 一項新型腦機接口技術,藉助 AI 算法將神經信號映射為預期聲音,首次實現將腦活動即時轉化為語音,為神經疾病失語者恢復對話能力提供可能。
一項新型腦機接口技術,藉助 AI 算法將神經信號映射為預期聲音,首次實現將腦活動即時轉化為語音,為神經疾病失語者恢復對話能力提供可能。
撰文 | 常愷
“這就像我重新擁有了⾃⼰的聲⾳。”
一位漸凍症患者在通過腦語⾳接⼝系統説出第一句話時如此表達。
2025年6⽉12⽇,由加州⼤學戴維斯分校(UC Davis)聯合布朗⼤學、哈佛醫學院附屬⻢薩諸塞總醫院及美國退伍軍⼈事務部神經恢復中⼼組成的研究團隊,在Nature雜誌發表了一項引發全球關注的神經⼯程研究。他們⾸次實現了通過⼤腦信號直接⽣成⾃然語⾳的技術,讓一位因漸凍症(ALS)失去發聲能⼒的患者“重新開⼝”。
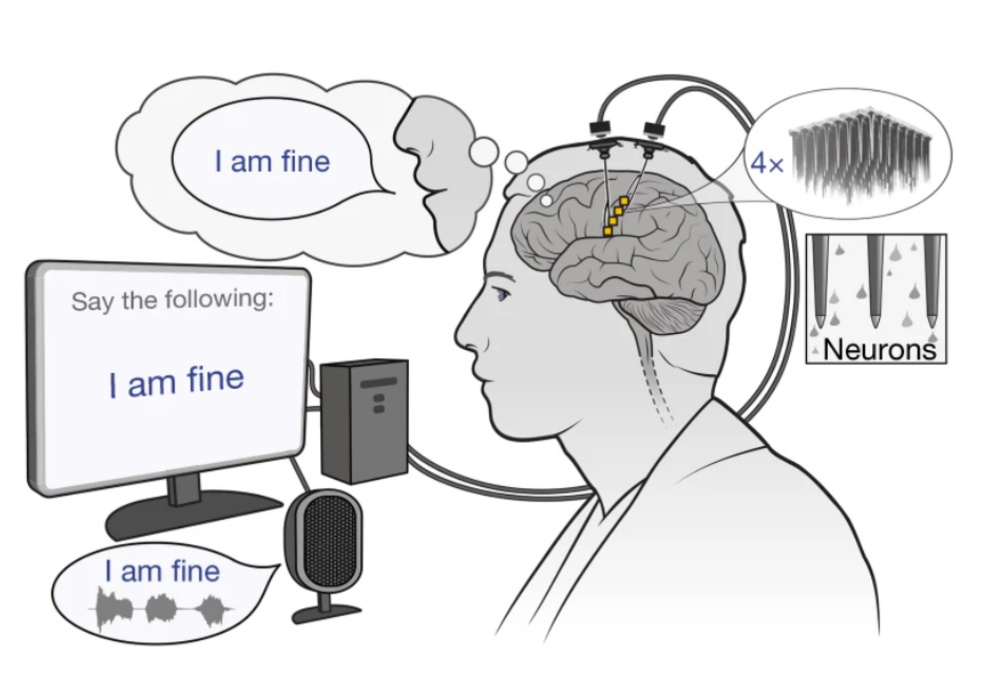 圖1:腦—語音接口系統的工作原理示意圖。
圖1:腦—語音接口系統的工作原理示意圖。
⽤⼤腦説話:⾸次實現⾃然語⾳的腦機接⼝
在神經⼯程和腦機接⼝領域,實現“⽤⼤腦直接説話”一直是一個意義⾮凡卻充滿挑戰的⽬標。過去的腦機接⼝⼤多依賴⽂字拼寫或按鈕輸⼊,即便能合成語⾳,往往也機械⽽單調,缺乏⾃然語⾔的韻律和情感。⽽對於那些⽆法發聲的⼈來説,語⾔從未在⼤腦中沉默,只是被困在了⽆聲的意圖之中。如今,科學家們終於找到了一種⽅式,讓這些“沉默的語⾔”被真實聽⻅。
此次發表在Nature上的研究,⾸次通過⼤腦運動⽪層的神經信號,即時⽣成帶有語調、節奏與個性化⾳⾊的⾃然語⾳。這不僅讓語⾔障礙患者能夠重新“説話”,更讓他們能⽤屬於⾃⼰的聲⾳、⾃⼰的⽅式進⾏交流。
對於參與試驗的ALS患者來説,這是一次技術測試,更是一次語⾔⾝份的重建。他成功説出“你好”“今天感覺很好”等簡單句⼦,並能靈活調控語調語⽓,甚⾄嘗試哼唱旋律。這些表達,不再只是功能性的輸出,⽽是具有⾃我⾊彩、情感温度和交流能⼒的完整語⾔。
從沉默到發聲:⼤腦如何直接驅動真實語⾳
要實現如此⾃然流暢的語⾳表達,背後依賴的是一個⾼度精密的腦—語⾳接⼝系統。研究團隊將整個流程設計為四個關鍵步驟:神經信號採集(neural recording)、神經解碼(neural decoding)、語⾳合成(speech synthesis)和即時播放(real-time audio feedback),構建出一個完整的閉環路徑,讓意圖真正轉化為可聽⻅、可互動的語⾔。
⾸先,研究⼈員在患者⼤腦左側前中央回腹部(ventral premotor cortex)——這一控制⾯部和喉部運動的關鍵區域——植⼊了兩組共計256通道微電極陣列(microelectrode arrays)。即便患者已⽆法發聲,但在“試圖説話”時,⼤腦依然會產⽣可被記錄的電信號。隨後,這些神經信號被輸⼊⾄兩套並⾏的深度神經⽹絡模型中進⾏解碼:
•第一套模型⽤於預測語⾳內容(phoneme probabilities及acoustic features),即識別“説了什麼”;
•第⼆套模型則專⻔提取語調和情緒等副語⾔信息(paralinguistic features),如語句是否為疑問句、是否強調某一詞等。
這種“雙路徑解碼”機制,不僅能還原語義信息,還能呈現語言中的情感和個性表達,使系統輸出更接近真實人類語言。
由於患者無法清晰發聲,研究團隊面臨缺乏“真實語音”訓練數據的難題。為此,他們開發了一種創新算法:藉助屏幕提示語引導患者進行“嘗試説話”,並即時記錄其神經活動。系統隨後從這些神經信號中識別出音節邊界,再通過語音合成技術(text-to-speech)生成對應的目標語音。最後,研究人員將合成語音與神經信號在時間上對齊,從而構建出神經—語音配對數據,間接還原出患者的“預期發音”,為神經解碼模型的訓練提供了可靠基礎。
在此基礎上,團隊訓練了一套基於 Transformer 架構的深度學習模型,每10毫秒預測一次語音的頻譜與音高特徵。該模型實現了“因果解碼”能力,還對不同實驗時段之間神經信號的波動進行了結構優化,以確保不同使用時間下的穩定性和精確性。
最終的語音輸出由一套個性化聲碼器(personalized neural vocoder)完成。該系統通過模擬人類聲帶與發音機制,將神經解碼得到的語言參數轉化為清晰自然的語音,並通過揚聲器即時播放給患者。這種閉環式音頻反饋有助於重建大腦與語言表達之間的神經通路,也增強了交流的沉浸感。
為了最大限度保留個體特徵,聲碼器在訓練時還融⼊了患者早期的語⾳錄⾳,使得合成的語音在音色、語調上更貼近患者原有的嗓⾳特徵,具有⾼度個體化識別度。
整體而言,該系統在音素識別、語調判斷等方面均表現出色。實驗顯示,該系統對疑問語調的識別準確率約為 90.5%,詞語重讀的識別準確率約為 95.7%;在部分自由表達任務中,合成語音的音頻質量與提示語條件下生成結果相當(Pearson 相關係數約為 0.79±0.05)。整個過程在毫秒級時間窗⼝內完成閉環,從神經信號產⽣到聲⾳輸出延遲極低,⼏乎可實現即時對話。這一速度遠超以往的腦—機語⾳系統,真正做到了“⽤⼤腦即時説話”。
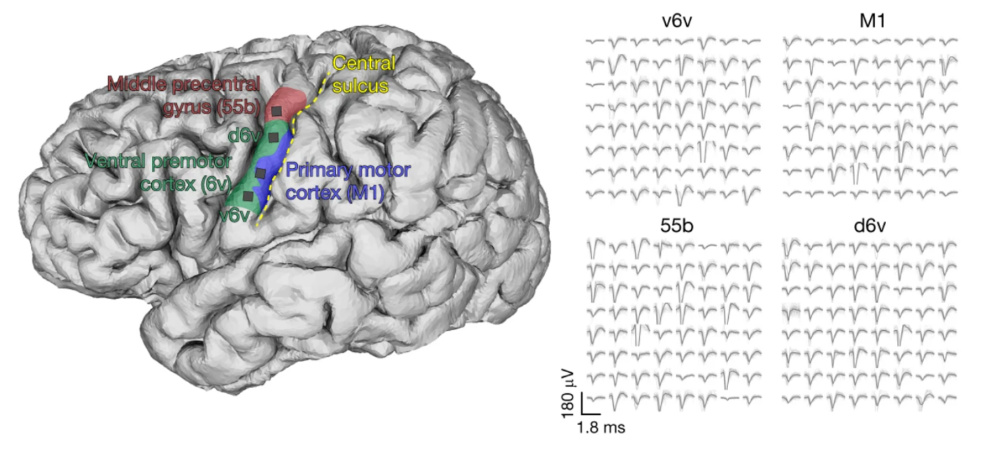 圖2:語言相關腦區的神經信號採集與放電波形圖。左側圖顯示了研究中電極陣列的植入區域,包括中前中央回(Middleprecentral gyrus,55b)、腹側前運動皮層(ventral premotorcortex,6v)、初級運動皮層(primary motorcortex,M1)以及相關子區(d6v、v6v)。黃色虛線標示中央溝(central sulcus)作為解剖參照。右側圖為從每個腦區採集到的神經放電波形(spike waveforms),展示了不同皮層區域中神經元的典型放電模式。這些信號構成了接口系統語音解碼的神經基礎。
圖2:語言相關腦區的神經信號採集與放電波形圖。左側圖顯示了研究中電極陣列的植入區域,包括中前中央回(Middleprecentral gyrus,55b)、腹側前運動皮層(ventral premotorcortex,6v)、初級運動皮層(primary motorcortex,M1)以及相關子區(d6v、v6v)。黃色虛線標示中央溝(central sulcus)作為解剖參照。右側圖為從每個腦區採集到的神經放電波形(spike waveforms),展示了不同皮層區域中神經元的典型放電模式。這些信號構成了接口系統語音解碼的神經基礎。
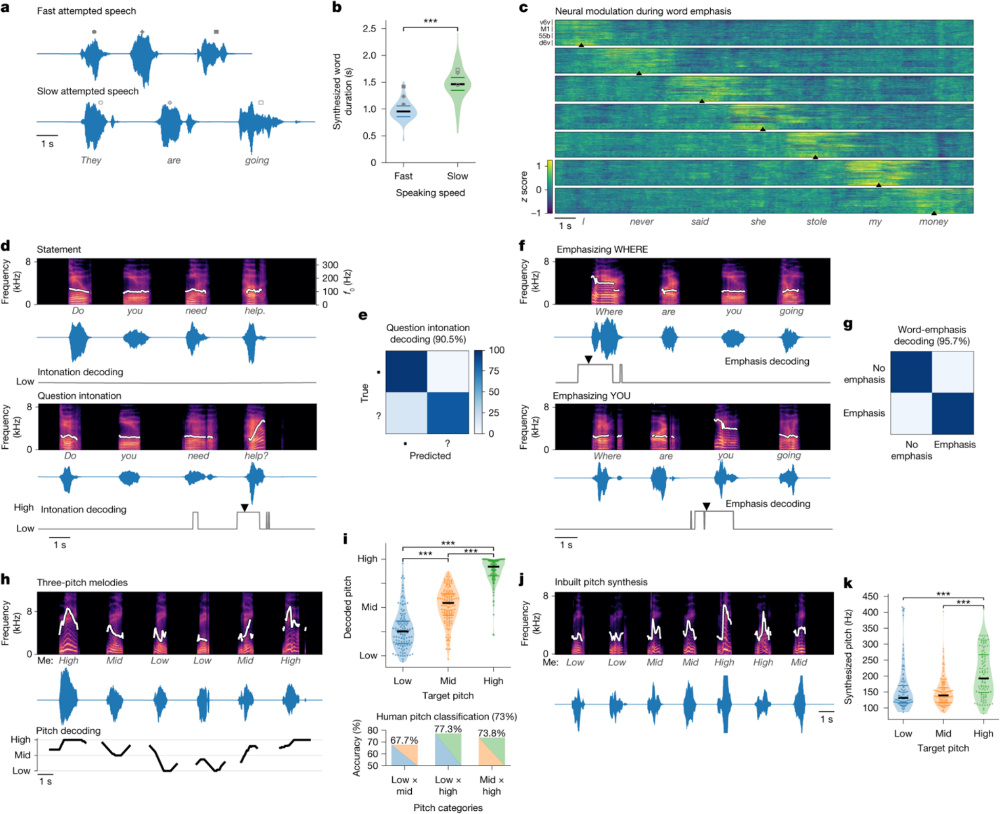 圖3:腦—語⾳接⼝系統的表達⼒與語調控制能⼒。本圖展示系統在語速調控(a–b)、詞語重讀(c)、語調識別(d–e)、強調重建(f–g)和⾳⾼合成(h–k)⽅⾯的多維解碼能⼒。a–b:系統可區分快速與緩慢語速的神經意圖,併合成相應節奏語⾳;c:在不同⽪層(M1、v6v、d6v、55b)中檢測到與詞語強調相關的神經調製;d–e:區分疑問句與陳述句語調,並實現⾼準確率的語調解碼(90.5%);f–g:成功識別並再現句中不同詞語的強調位置(如“Where” vs “You”);h–k:合成不同⾳⾼(Low,Mid,High)的旋律語⾳,並達到了與⽬標語調一致的頻率分佈(合成精度>73%)。
圖3:腦—語⾳接⼝系統的表達⼒與語調控制能⼒。本圖展示系統在語速調控(a–b)、詞語重讀(c)、語調識別(d–e)、強調重建(f–g)和⾳⾼合成(h–k)⽅⾯的多維解碼能⼒。a–b:系統可區分快速與緩慢語速的神經意圖,併合成相應節奏語⾳;c:在不同⽪層(M1、v6v、d6v、55b)中檢測到與詞語強調相關的神經調製;d–e:區分疑問句與陳述句語調,並實現⾼準確率的語調解碼(90.5%);f–g:成功識別並再現句中不同詞語的強調位置(如“Where” vs “You”);h–k:合成不同⾳⾼(Low,Mid,High)的旋律語⾳,並達到了與⽬標語調一致的頻率分佈(合成精度>73%)。
語⾔的未來:不僅是技術,更是權利的歸還
這項研究的意義,不僅在技術層面實現了用“大腦説話”的突破,更在於它為失語者在重建語言、身份與人際連結提供了全新可能。在傳統溝通手段失效的情況下,這一腦語音接口技術讓沉默的大腦重新被聽見,讓表達不再依賴聲音或動作,而直通思維本身。
為加速這一方向的發展,研究團隊已將完整的數據與代碼在GitHub(Neuroprosthetics-Lab/brain-to-voice-2025)開源,並邀請全球研究者共同優化算法、拓展功能。未來,它有望推廣至中⻛、腦癱、喉癌術後等多類失語人羣;與此同時,研究人員也在探索其與⾮侵⼊式腦電技術(如EEG)的結合,以進一步降低使用⻔檻;它還可能與AI語義理解系統融合,構建新—代⾃然語⾔交互平台。
儘管該研究已實現了神經信號到自然語音的即時轉化,但目前仍處於早期探索階段。在實驗中,患者需要根據屏幕提示語進行“默唸”或“嘗試説話”,系統才能識別相應意圖併合成語音。換句話説,當前的表達仍依賴於“外部引導”,尚未達到完全由大腦自主驅動的自由交流。
不過,研究團隊也嘗試在更開放的場景中進行測試。例如,在部分無提示的問答任務中,系統依然能夠生成清晰、自然的語音輸出。這一結果提示:腦語音接口正朝着“無提示、自主表達”的方向邁進,為未來實現意圖直接驅動語言奠定了技術基礎。
當然,這項技術目前僅在一位ALS患者中完成驗證,樣本數量有限,仍不足以評估其在不同個體、不同病理狀態下的通用性與穩定性。同時,從公開演示視頻來看,系統生成的語音雖然具備個性化音色,但在語調靈活性、節奏自然度與情感表現方面,仍與真實人類對話存在一定差距。
要實現真正的日常實用化,該技術仍面臨諸多挑戰:如何從“提示語驅動”邁向“自由表達”?如何減少設備的侵入性、提升長期使用的穩定性與適配性?這些問題將決定腦語音接口能否從實驗室走進真實生活的深度與廣度。
但毋庸置疑,我們正在邁入一個新的語言紀元。未來的語⾔,不再依賴聲帶、⽂字或⼿勢,⽽將直接來源於我們的思維本⾝。語⾔,原本就是我們存在的延伸。⽽今天的這項研究,讓我們看到:即使在沉默之中,⼤腦依然有話可説。科技,正在幫助那些失去語⾔的⼈再次被世界聽⻅。
參考文獻
[1]Wairagkar, M., Card, N.S., Singer-Clark, T. et al. An instantaneous voice-synthesis neuroprosthesis. Nature (2025). https://doi.org/10.1038/s41586-025-09127-3
注:本文封面圖片來自版權圖庫,轉載使用可能引發版權糾紛。
 特 別 提 示
特 別 提 示
1. 進入『返樸』微信公眾號底部菜單“精品專欄“,可查閲不同主題系列科普文章。
2. 『返樸』提供按月檢索文章功能。關注公眾號,回覆四位數組成的年份+月份,如“1903”,可獲取2019年3月的文章索引,以此類推。
版權説明:歡迎個人轉發,任何形式的媒體或機構未經授權,不得轉載和摘編。轉載授權請在「返樸」微信公眾號內聯繫後台。