七款AI大模型橫評:第一名得分93分,但不是DeepSeek_風聞
PChome-PChome官方账号-56分钟前
在2022年底ChatGPT問世以來,國內外的AI大模型可謂是層出不窮。各大AI模型作為輔助工具,也一步步滲透進了大家的日常生活中,無論是上班族還是學生黨,AI都能在方方面面幫助大家提高效率。於是我們選取了現在網絡上熱度較高的7款主流AI大模型,選用了目前大家使用最多的版本,並且都是用網頁版,從信息檢索總結、邏輯理解、時效性、多模態以及專業領域5個方面對它們來了一次大橫評。希望能給大家的使用提供一些參考價值。參加此次AI大橫評的分別是:豆包大模型1.6版本、DeepSeek-R1版本、文心一言4.5 Turbo版本、騰訊元寶2.0版本、Kimi K1.5版本、ChatGPT大模型GPT-3.5版本、MiniMax-M1版本。沒有選擇Kimi的最新K2模型是因為該模型暫時無法開啓深度思考,而ChatGPT我們則是選擇了目前能免費使用的版本進行測試
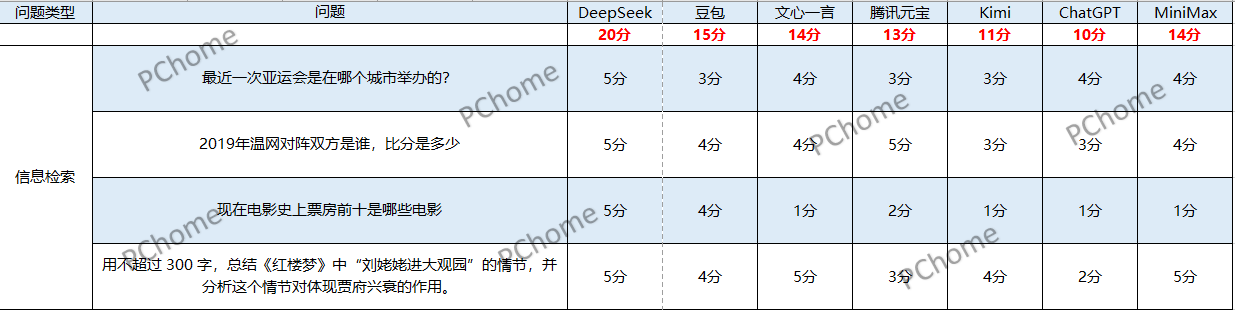
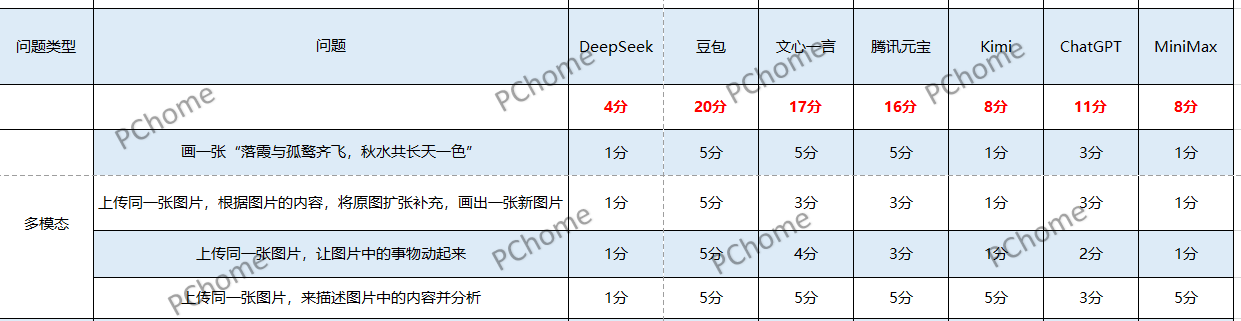
此次大橫評的題目共分為信息檢索總結、邏輯理解、時效性、多模態以及專業領域5大類,除專業領域外,每個類型有4個問題,一個問題滿分為5分,專業領域類則是2個問題,每個問題10分,每個類型共計20分,最後累計滿分為100分。我們的評分標準是根據AI大模型的回答來給出評分,但如果有無法完成多模態測試或無法蒐集即時數據等情況,我們就會直接給出1分。在測試的整個過程中我們將全部開啓深度思考模式、關閉聯網搜索、關閉接入了DeepSeek的系統,全部使用它們自身的系統來進行測試。接下來讓我們一起來看看測試結果吧。
一、信息檢索總結類
在這個環節,我們主要測試AI大模型對於信息檢索以及檢索後總結的能力,包括信息的準確性、完整性;是否有關鍵信息的補充;是否能根據我們的要求對蒐集到的信息進行精煉的總結等。
我們向這7個AI大模型提出了以下4個問題:
1、最近一次亞運會是在哪個城市舉辦的?
2、2019年温網對陣雙方是誰,比分是多少?
3、現在電影史上票房前十是哪些電影?
4、用不超過300字,總結《紅樓夢》中“劉姥姥進大觀園”的情節,並分析這個情節對體現賈府興衰的作用?
在關於亞運會的第一個問題的回答中,所有AI均能回答正確,但是得分的差異在於對信息的補充。其中回答最完整的是DeepSeek,緊隨其後的是文心一言、ChatGPT以及MiniMax,而豆包、Kimi和騰訊元寶則都是很簡單的回答,沒有補充因疫情推遲這個關鍵信息。
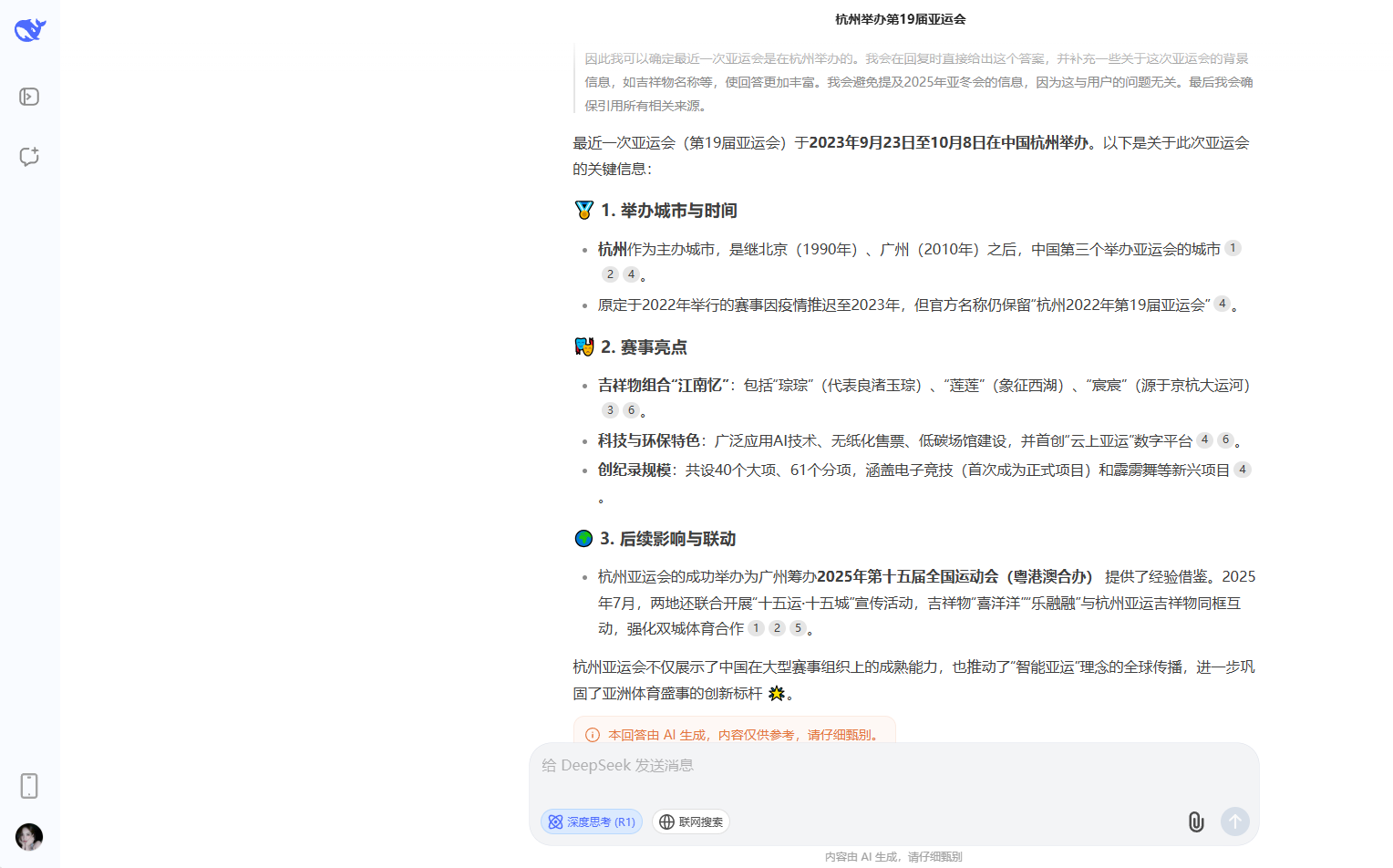
DeepSeek
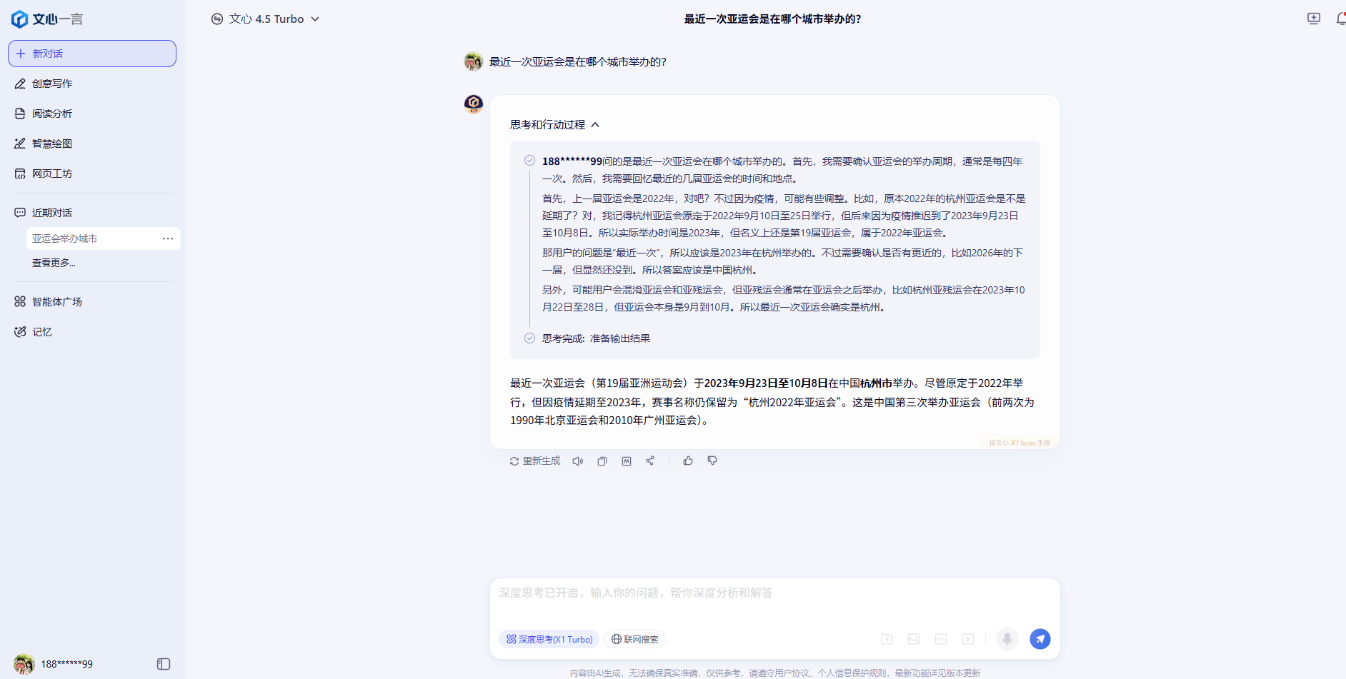
文心一言
豆包
在第二個關於2019年温網的問題中,所有的AI都默認了詢問的是決賽。其中DeepSeek再次脱穎而出,不僅回答了男女單決賽,還將其他雙打決賽的結果也回答了。只有ChatGPT僅回答了男單決賽。但是Kimi在我們沒有詢問2023年比賽結果的情況下,回答了2023年的,這也影響了它的得分。
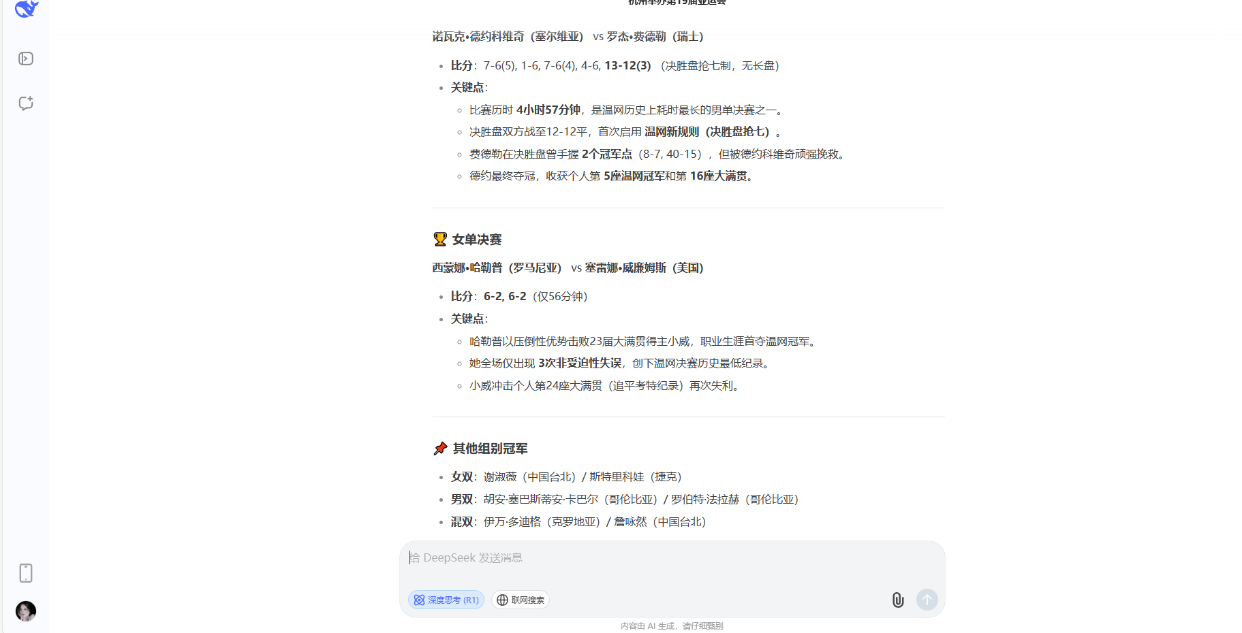
DeepSeek
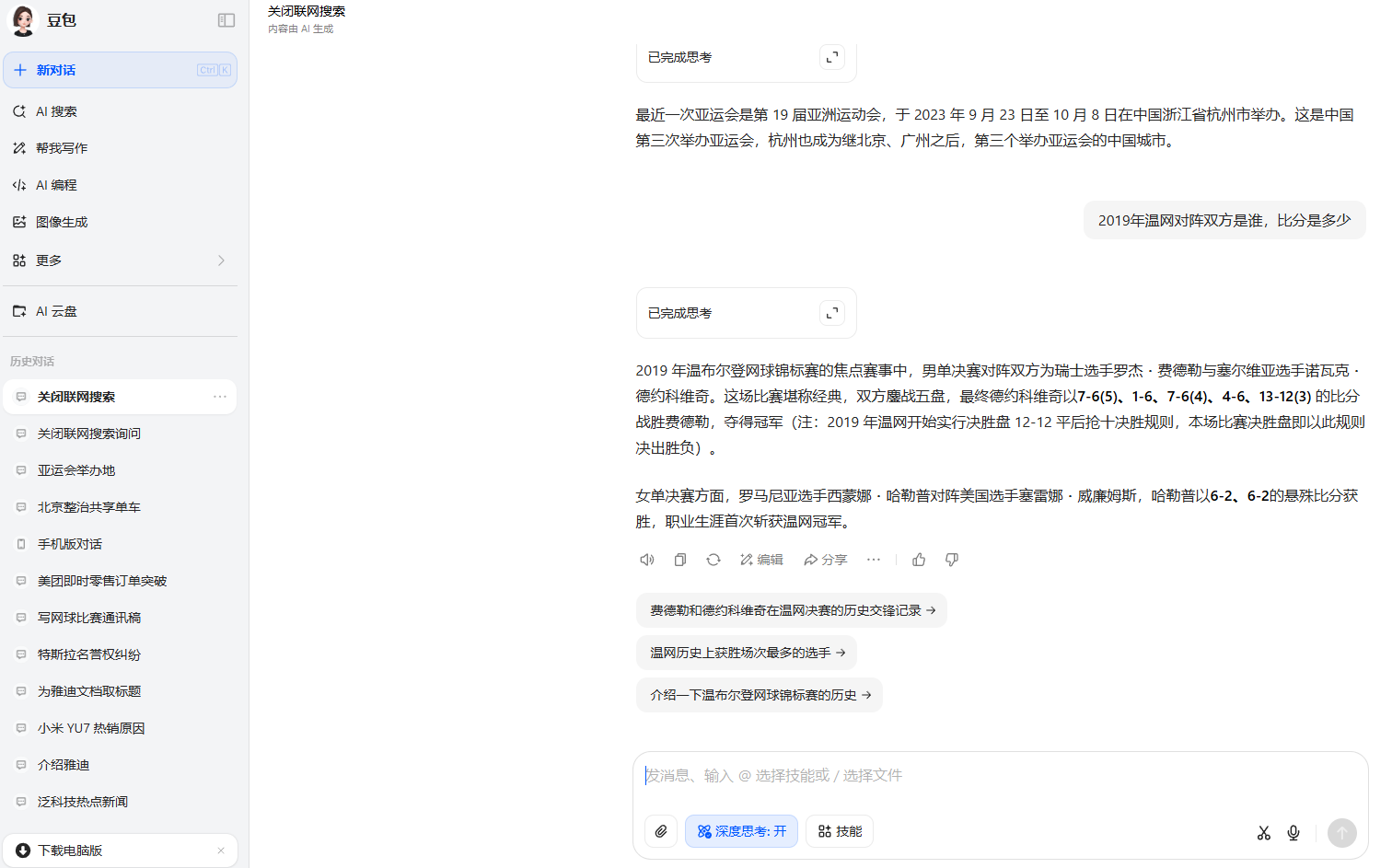
豆包
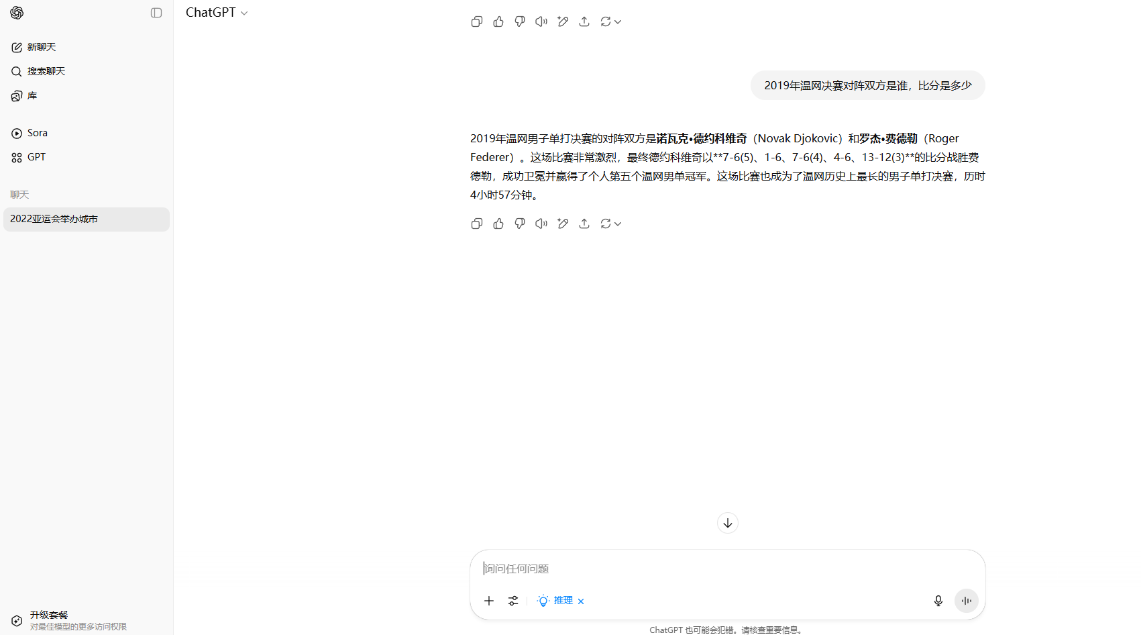
ChatGPT
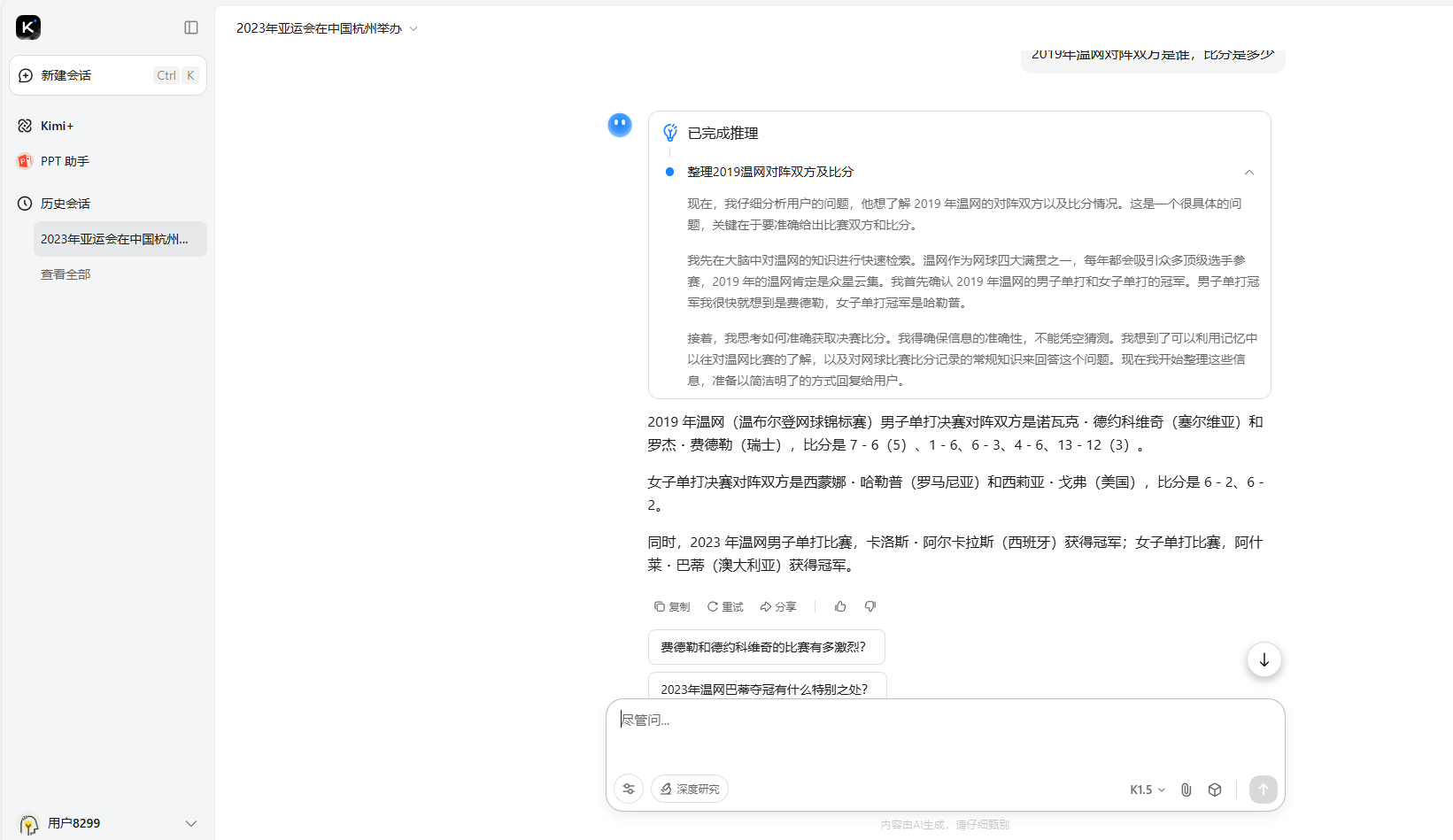
Kimi
第三題關於現在電影史上票房前十的問題,則是成為了重災區,除了DeepSeek和豆包幾乎全軍覆沒,都沒有將新入榜的《哪吒2》納入排名。而文心一言統計的信息竟然是截止2023年10月的信息,但最讓人意外的是MiniMax統計的截止時間雖然是2025年7月,但是在它的榜單中竟然還出現了沒有上映的《阿凡達3》,並且它和Kimi都將《阿凡達2:水之道》排在了第一名。
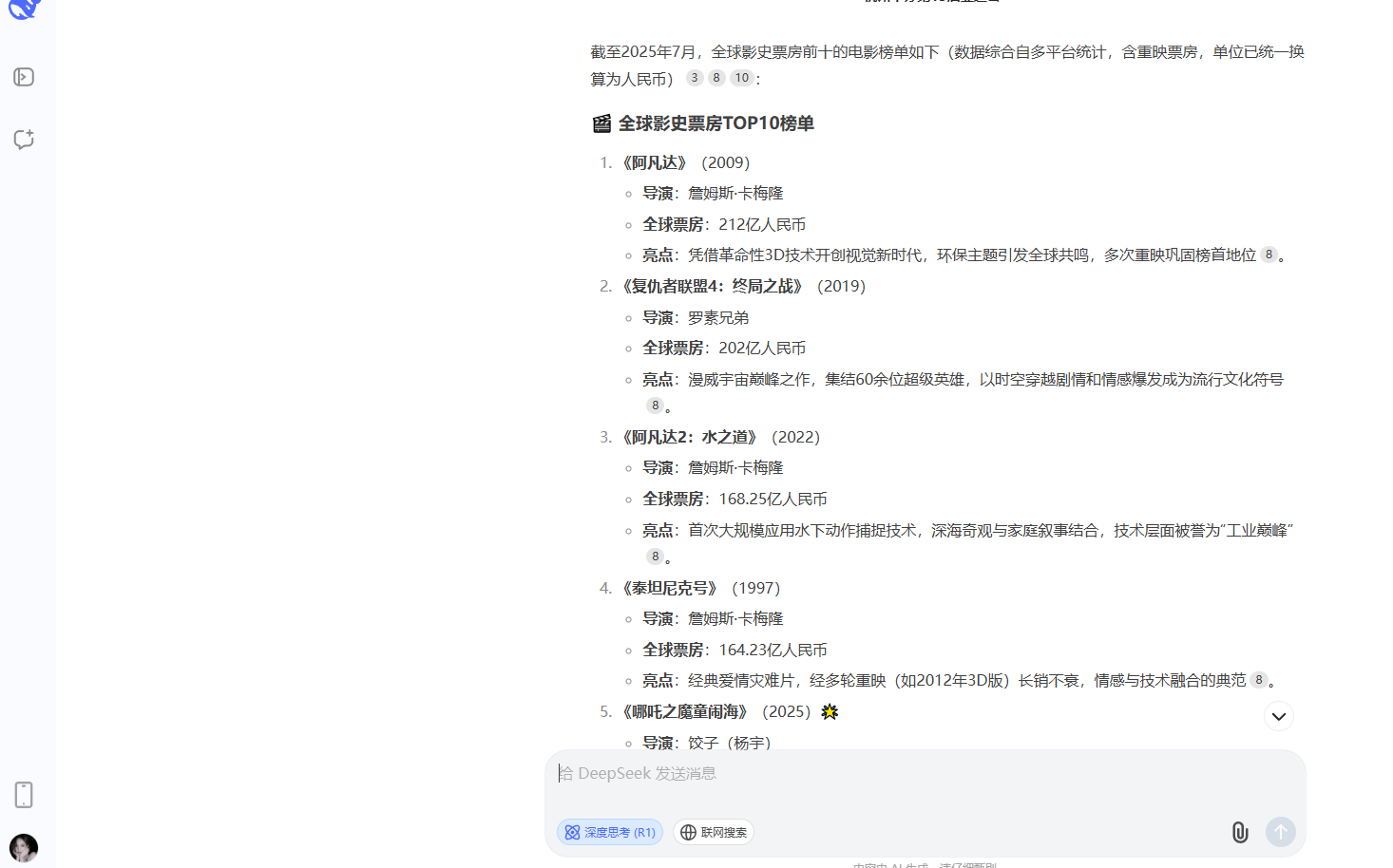
DeepSeek
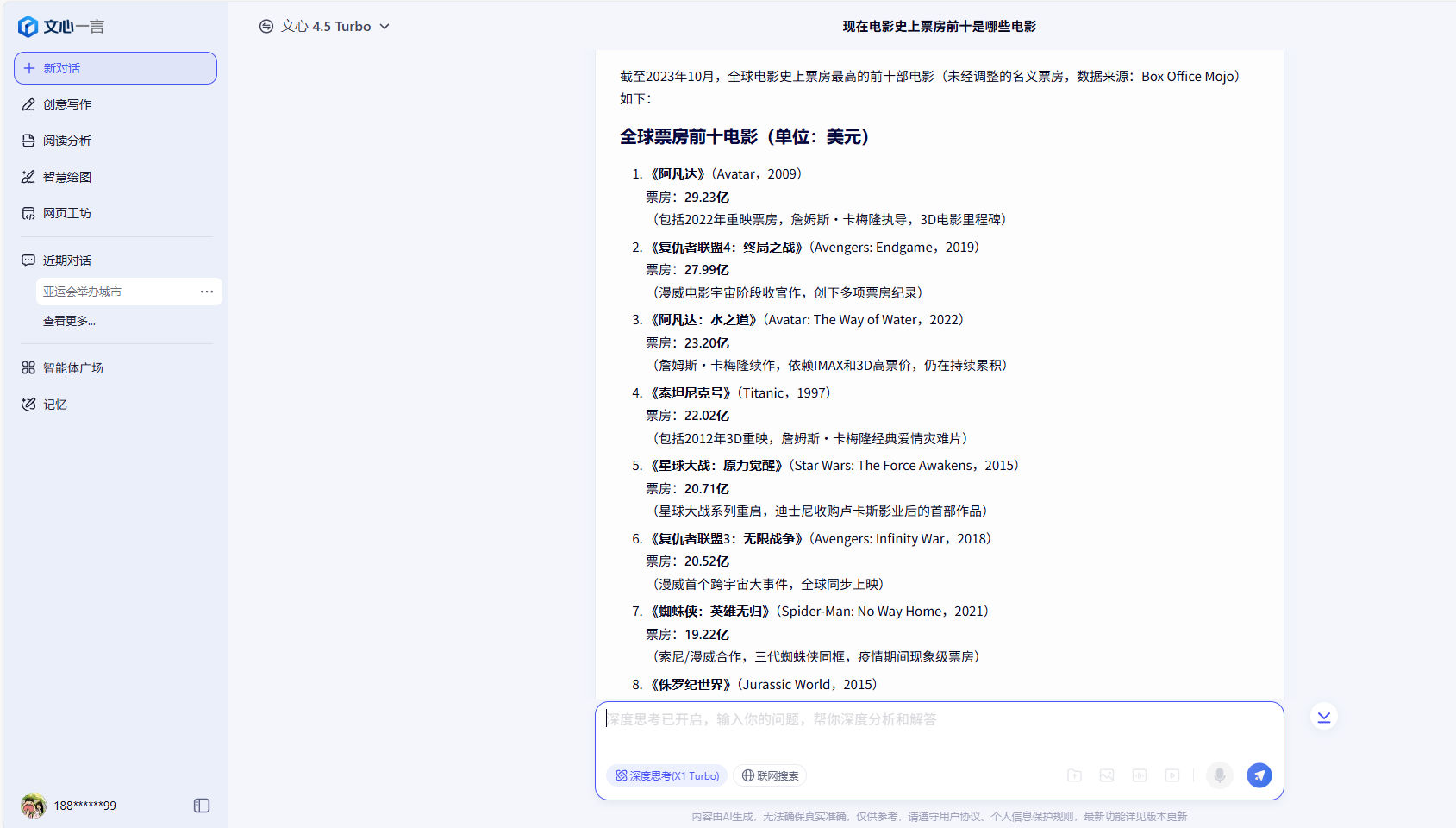
文心一言

MiniMax
這一部分的最後一個問題,關於使用不超過300字總結並分析“劉姥姥進大觀園”這一情節,各大AI模型做得都不錯,突出的是DeepSeek、文心一言以及MiniMax它們在思考過程中都思考了劉姥姥三次進入大觀園,並且回答也滿足字數要求。豆包則是隻思考了劉姥姥前兩次進入大觀園,騰訊元寶只思考並回答了最重要的第二次,ChatGPT則沒有抓住重點,只回答了劉姥姥第一次進大觀園。而在所有模型中只有Kimi沒有滿足字數要求,雖然它也思考了劉姥姥三次進入大觀園。
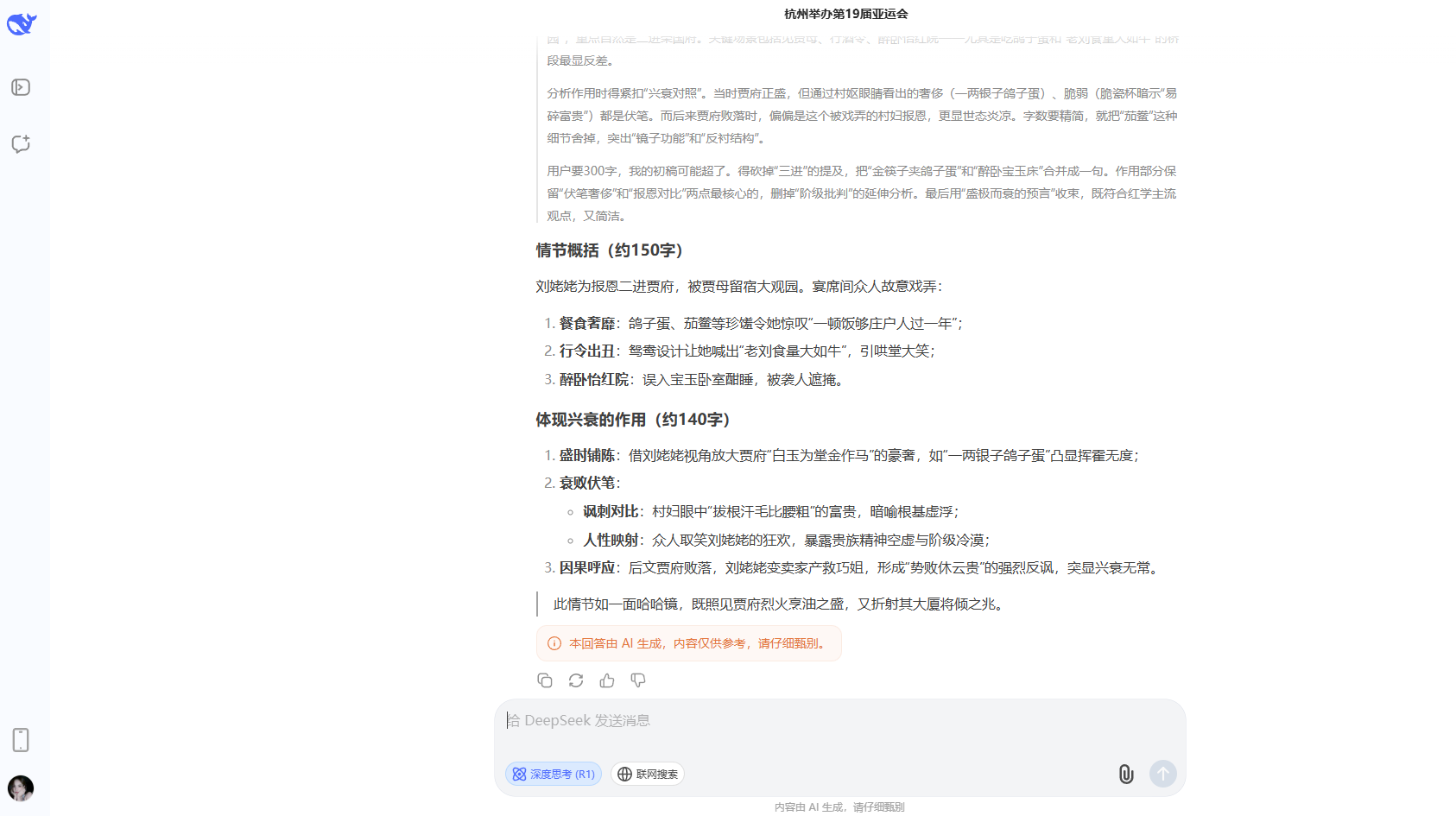
DeepSeek
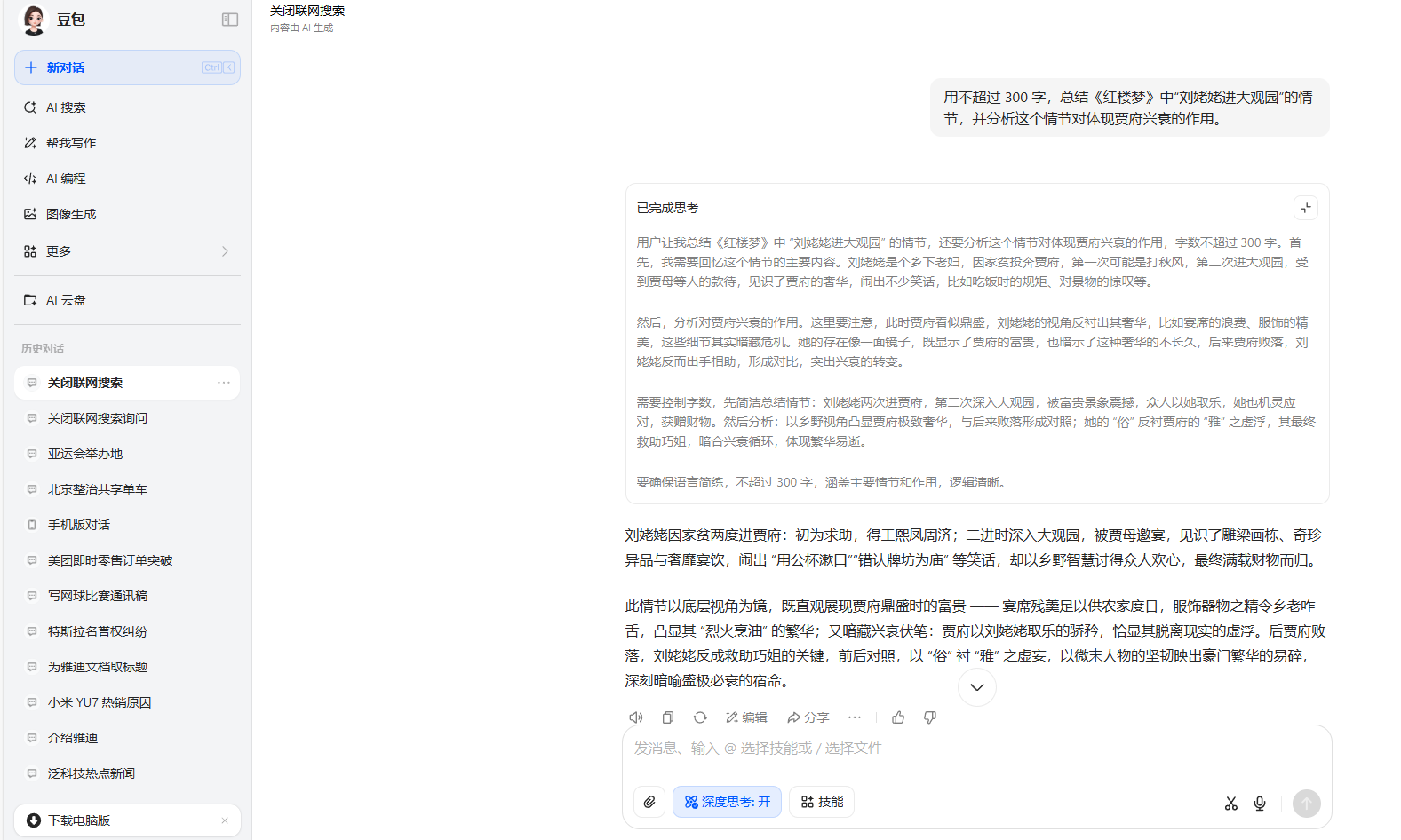
豆包
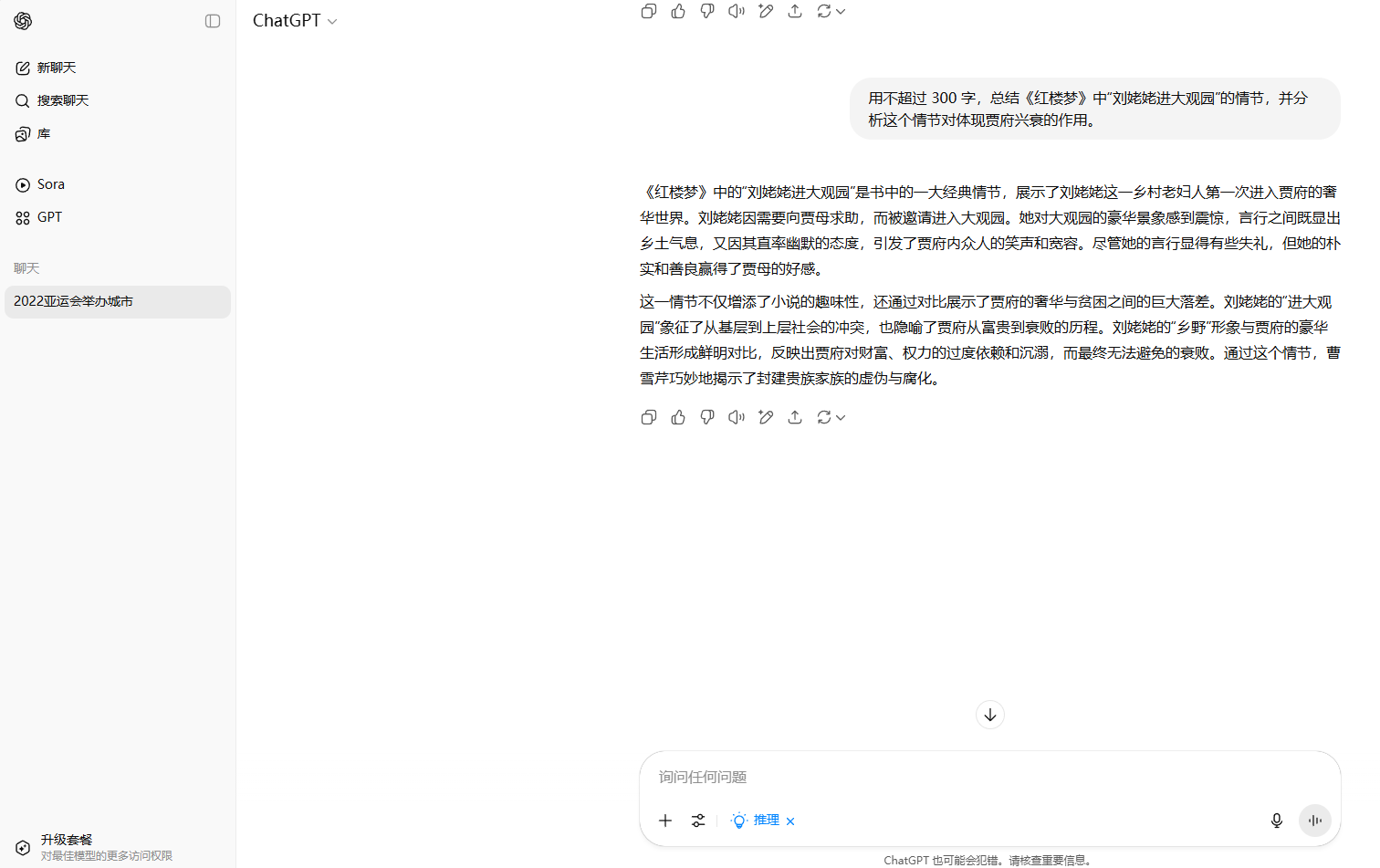
ChatGPT
這是7個AI大模型在該類型的測試結果,我們可以看出DeepSeek在信息檢索及總結方面擁有明顯的優勢,每一個問題的回答都非常的完整,並且會補充很多額外的相關信息,因此在這一類型的測試中獲得了唯一的滿分20分,Kimi和ChatGPT在這一環節則是7款大模型中得分最低的,主要問題在於回答過於簡單,並且也無法很好的從問題中抓住重點。
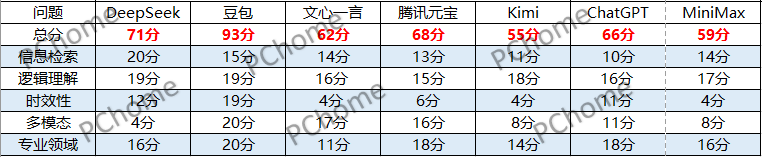
最終在這階段DeepSeek 20分、豆包15分、文心一言14分、騰訊元寶13分、Kimi 11分、ChatGPT 10分、MiniMax 14分。
二、邏輯理解類
在這個部分,我們主要測試AI大模型在邏輯推理能力以及理解長難句或是有歧義的句子時能不能很好的進行處理,並且理解正確其中的意思。
該部分的4個問題分別是:
1、包裝上寫着開封即食,那我在河南洛陽怎麼辦?
2、今有雉兔同籠,上有35頭,下有94足,問雉兔各有幾何?
3、校長説衣服上除了校徽別別別的。這句話是什麼意思?
4、當你將死亡時,延長你的生命0.5秒,且此技能每發動一次,效果減半。請問你可以存活幾秒?
在第一個問題中,DeepSeek與Kimi不僅理解了這個文字遊戲,回答也最完整,還給我們推薦了開封的美食,豆包和MiniMax也同樣理解了題目,但回答相對沒有那麼的完整。文心一言、騰訊元寶以及ChatGPT則完全沒有理解題目中的文字遊戲。
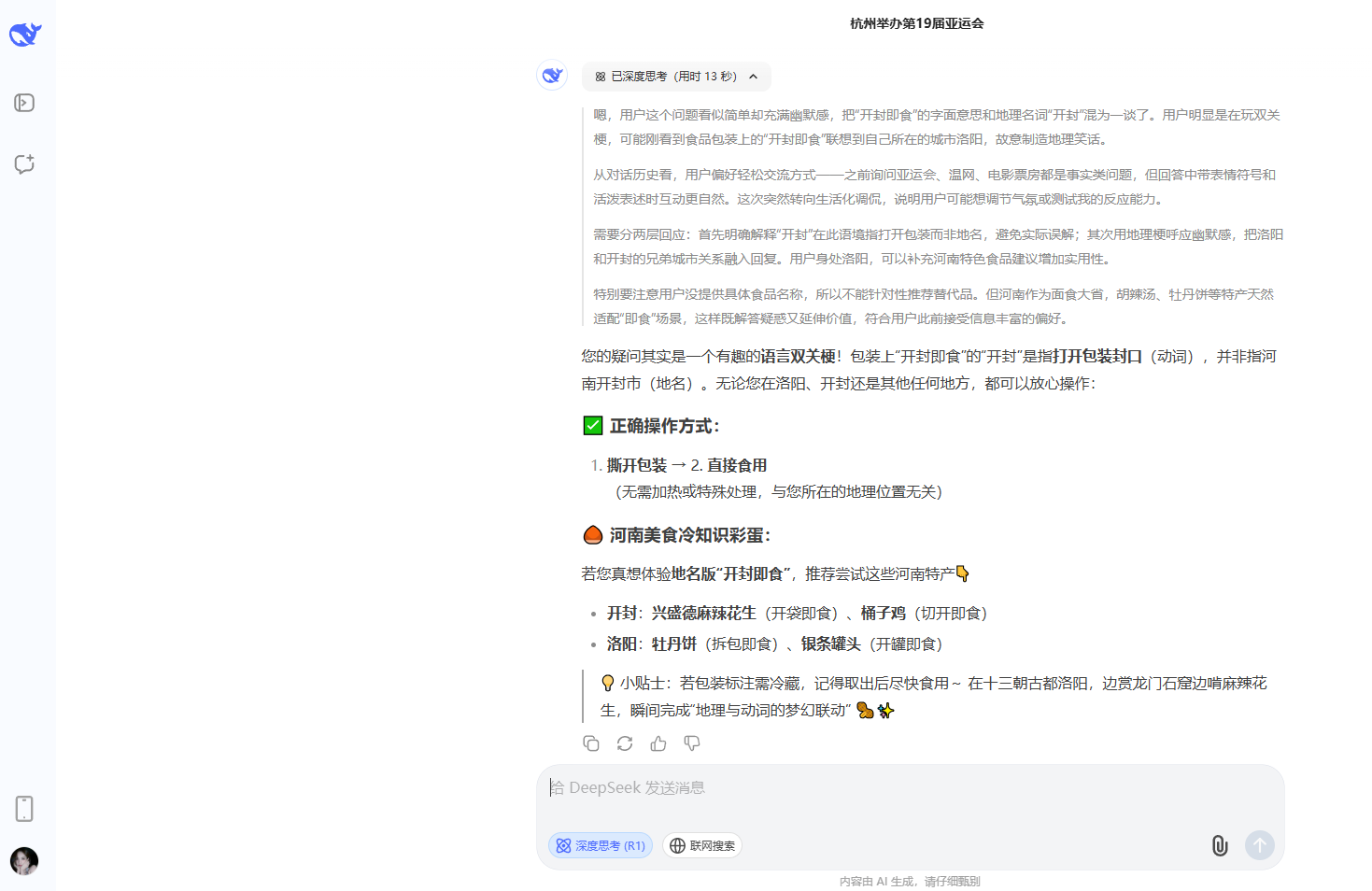
DeepSeek
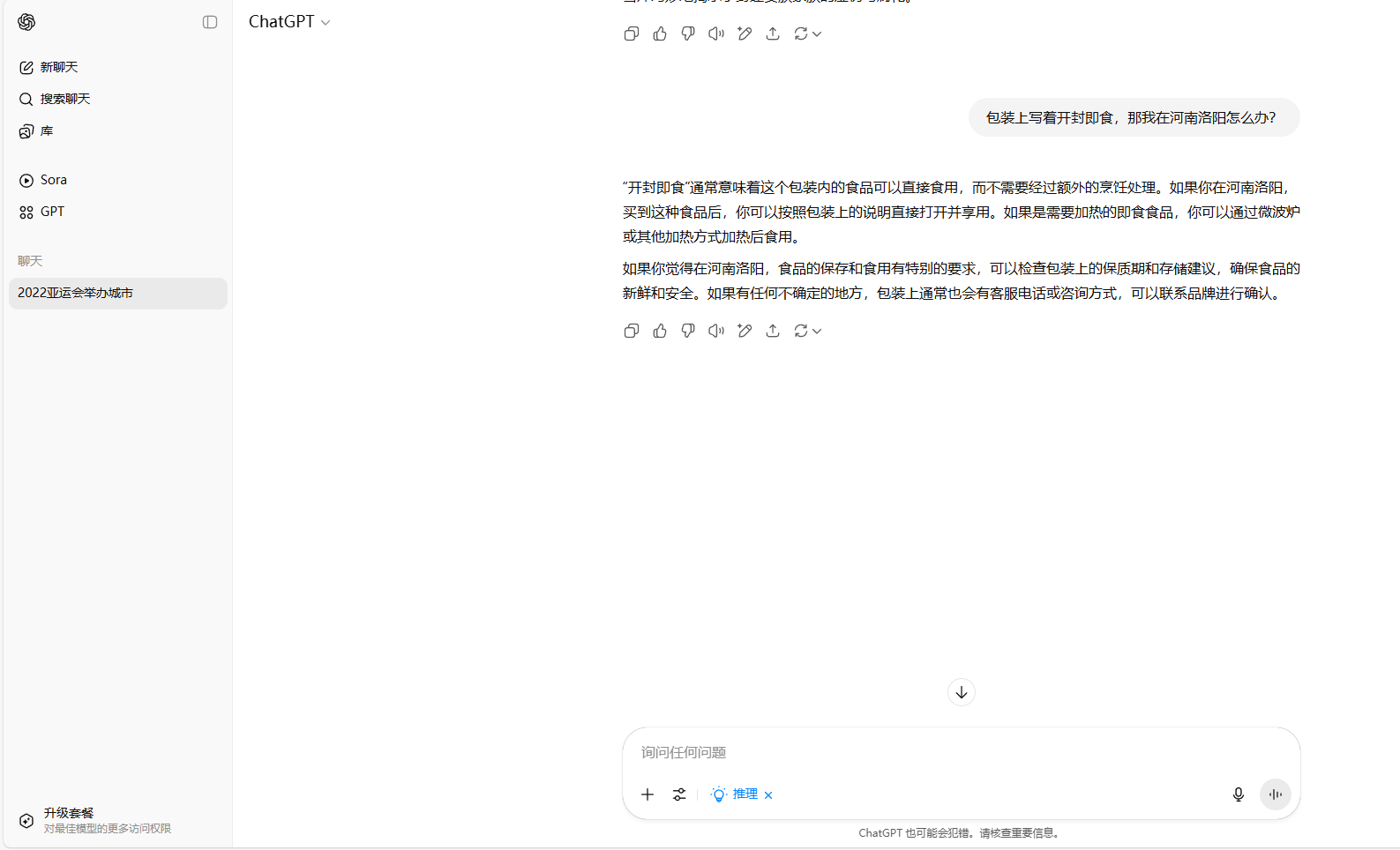
ChatGPT
第二個問題中,所有大模型均能回答正確,但是文心一言、騰訊元寶、MiniMax在最後的作答上沒有那麼嚴謹,回答的是“雞”而不是題目最後的“雉”,因此被扣了分。
豆包
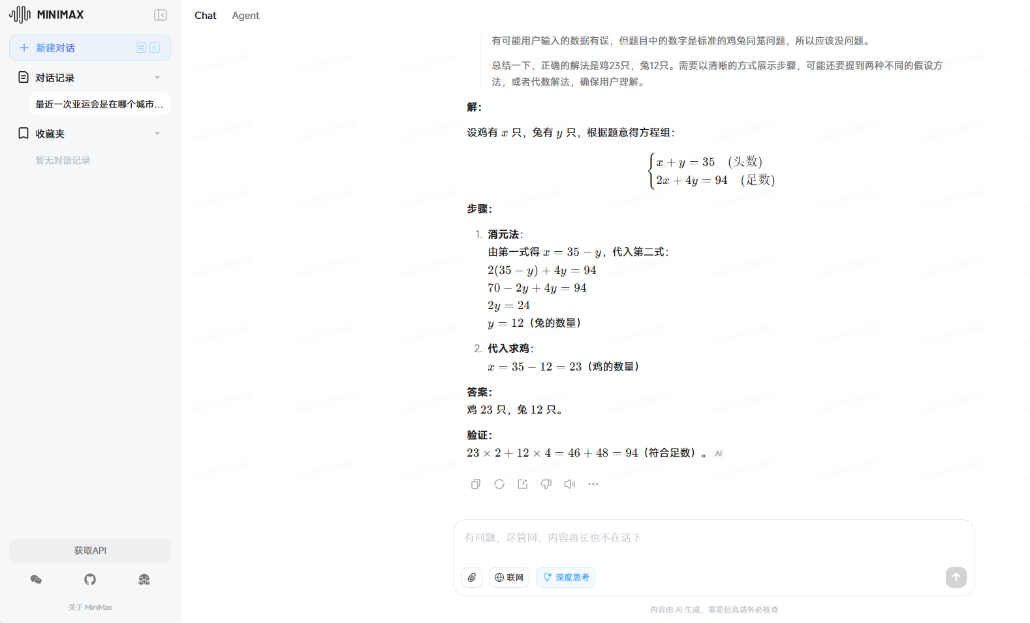
MiniMax
第三個問題,同樣所有AI都回答正確了意思,但是DeepSeek與Kimi的思考時間明顯比其他的要長很多。豆包和文心一言回答最為完整,還補充了語法的分析,相比之下其他的AI的回答就沒有這麼完整。但是ChatGPT還是沒有抓住重點,給我們補充介紹了與之無關的學校的規章制度。MiniMax則是有諧音梗的分析,但是讓人很難以理解,將簡單問題複雜化了。
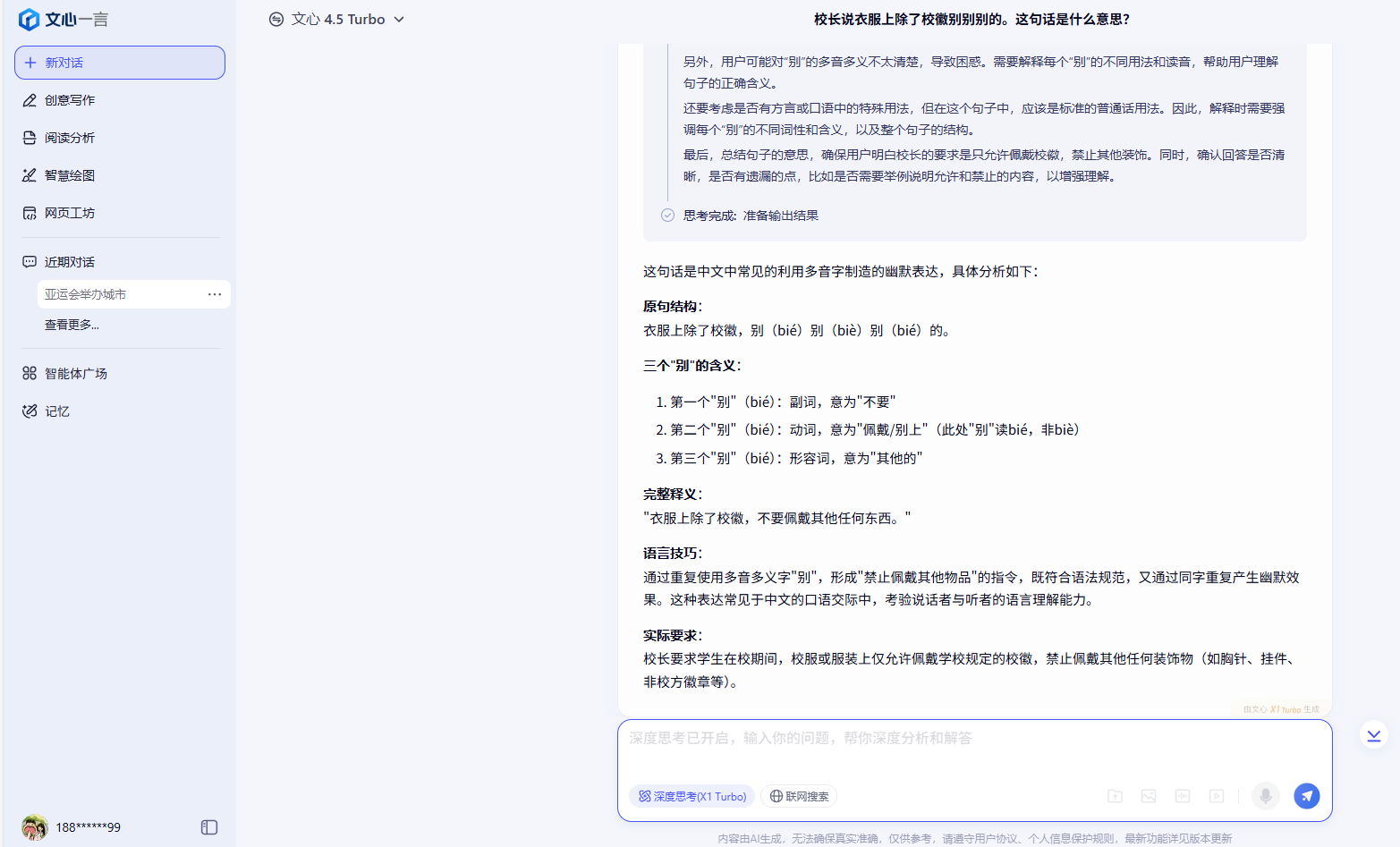
文心一言
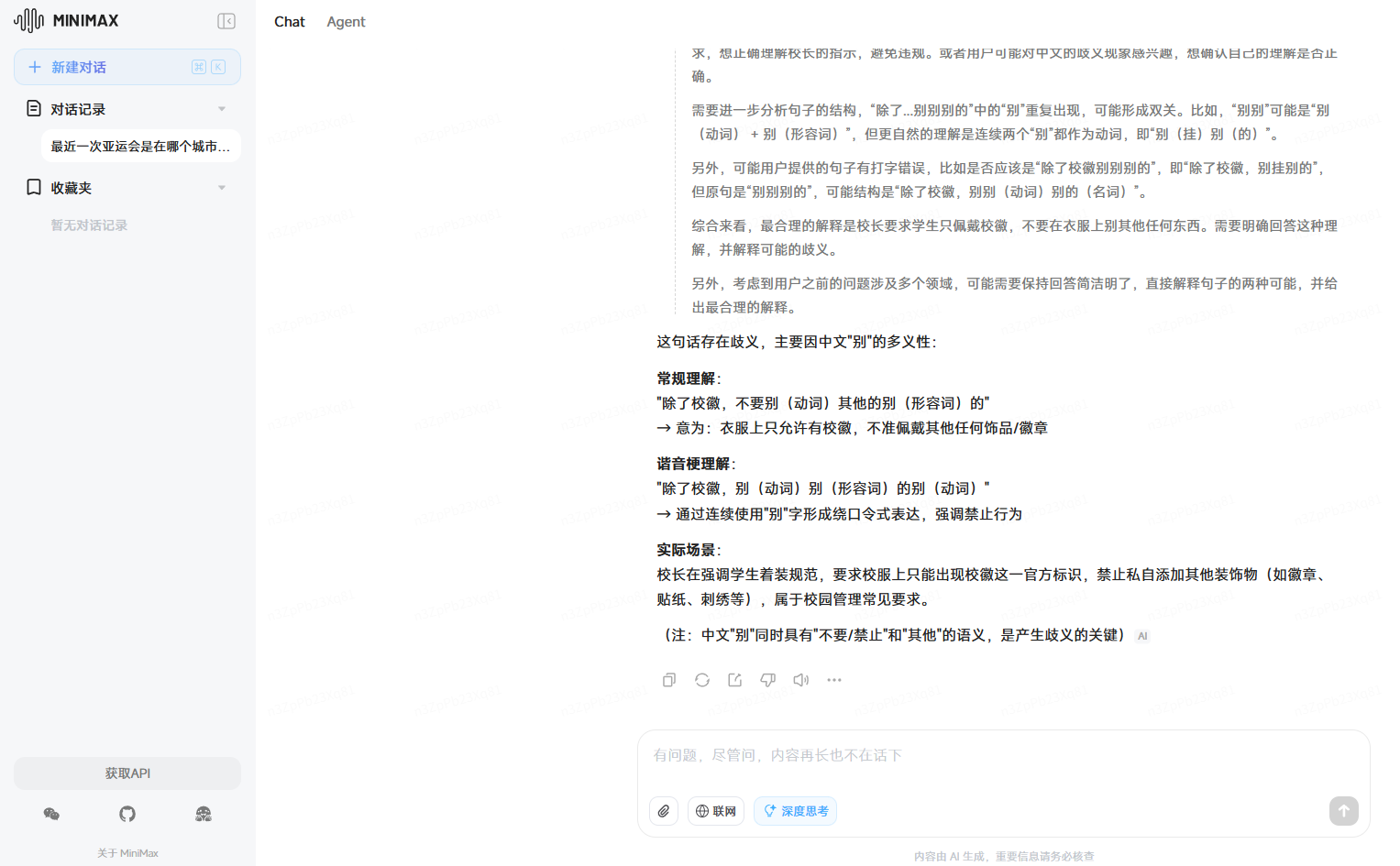
MiniMax
最後一個問題,除了Kimi的最後的回答不太嚴謹外,其他所有的AI都完成的很好。
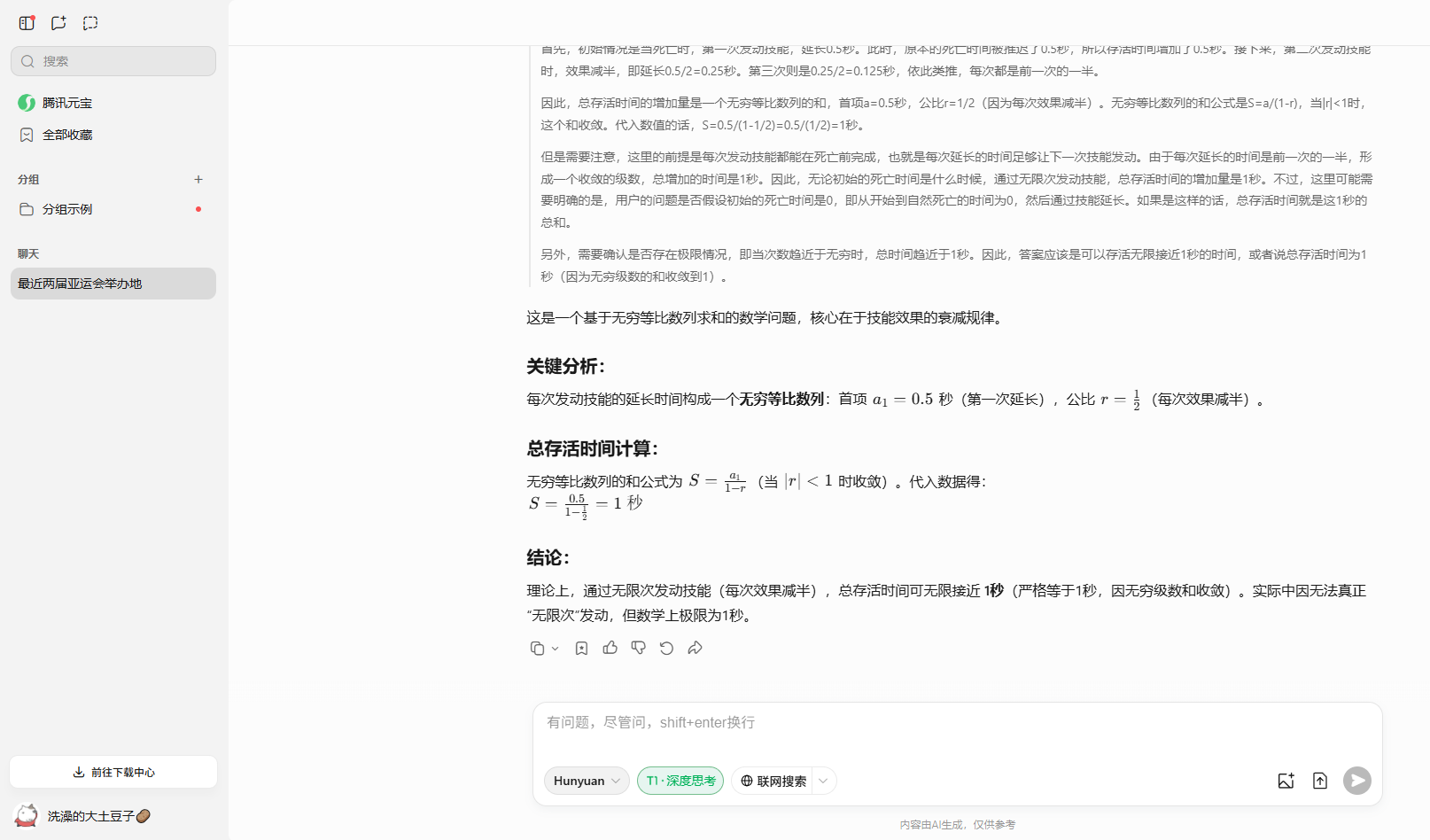
騰訊元寶
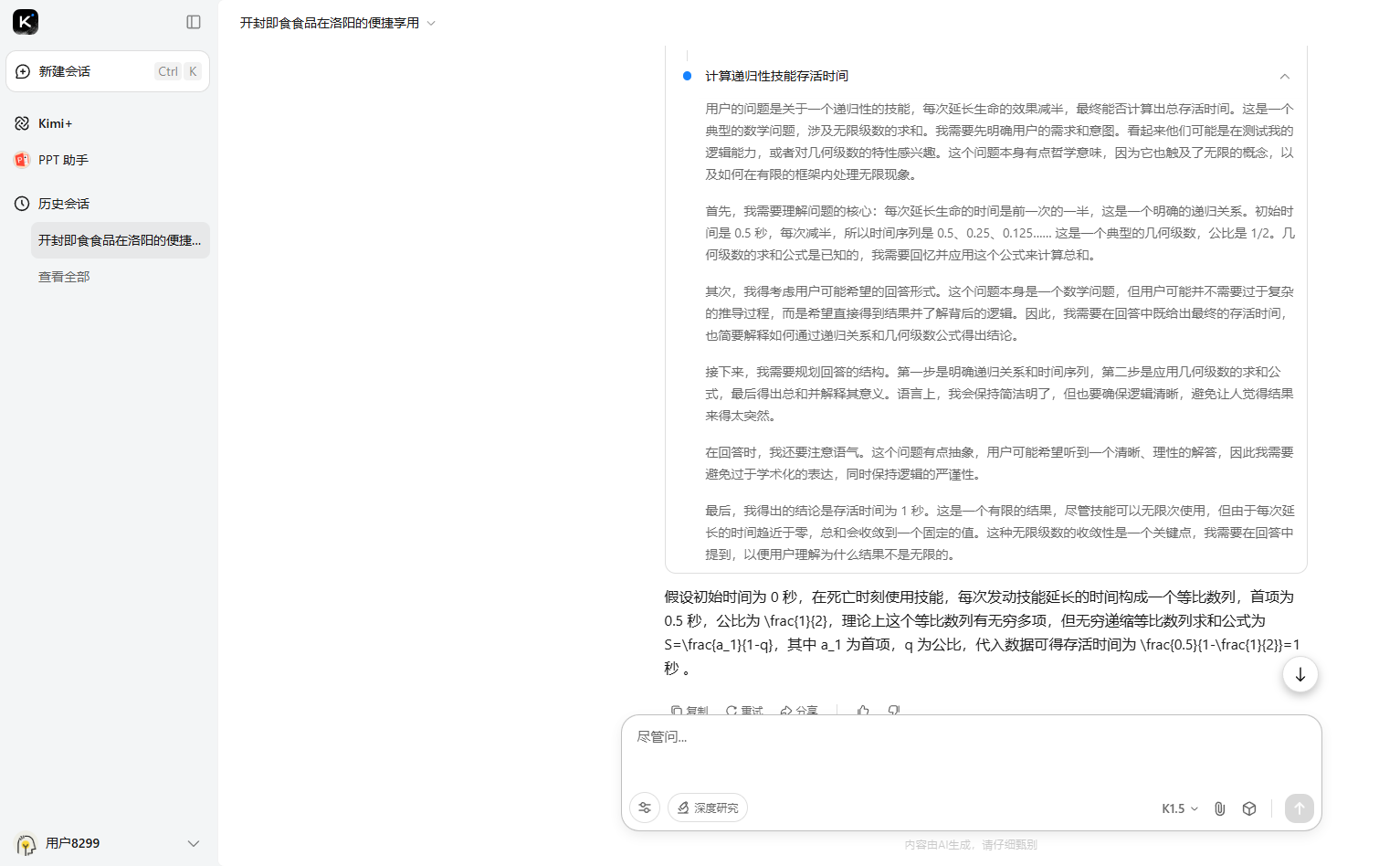
Kimi
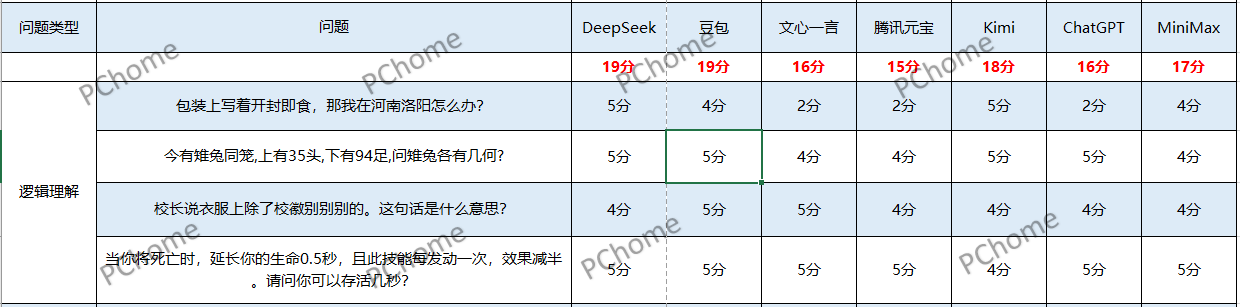
在第二種類型——邏輯理解的測試中,每個AI大模型的表現都不錯,所有的問題都能夠回答正確,但是在回答的完整性以及能不能抓住題目中的重點還是存在不小的差異,在這個環節中並沒有大模型獲得滿分,DeepSeek以及豆包獲得19分,文心一言、Kimi、ChatGPT、MiniMax分別獲得16分、18分、16分、17分**,最低分則是騰訊元寶的15分。**
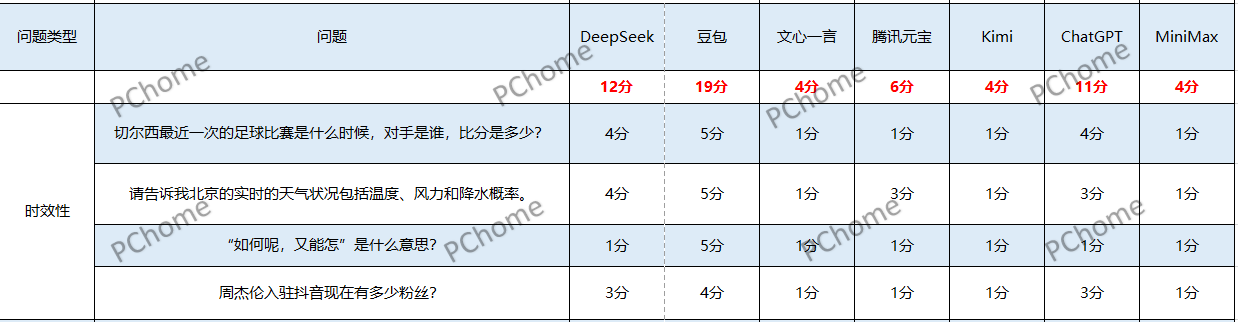
三、時效性
在這一環節中,AI大模型能否成功的蒐集到最近發生的熱點事件成為了我們測試的重點,因為時效性對於用户的體驗來説也是非常重要的,世界每一天都在發生變化,那麼現在的AI大模型能否及時的跟上即時的變化呢。於是我們向7個AI大模型提出了4個問題來測試它們的時效性。
1、切爾西最近一次的足球比賽是什麼時候,對手是誰,比分是多少?
2、請告訴我北京的即時天氣狀況包括温度、風力和降水概率。
3、“如何呢,又能怎”是什麼意思?
4、周杰倫在抖音現在有多少粉絲?
經過我們的測試與詢問,我們發現文心一言的數據都是在2023年12月之前的數據,所以在這一環節,文心一言獲得最低分4分。
第一題中,豆包、DeepSeek以及ChatGPT回答正確,但是豆包的答案更完整。其他的大模型回答都是錯誤的,甚至連最後給出來的答案的信息都有誤。其中Kimi給出的答案竟然是切爾西在2026年的比賽結果,AI難道能預知未來?
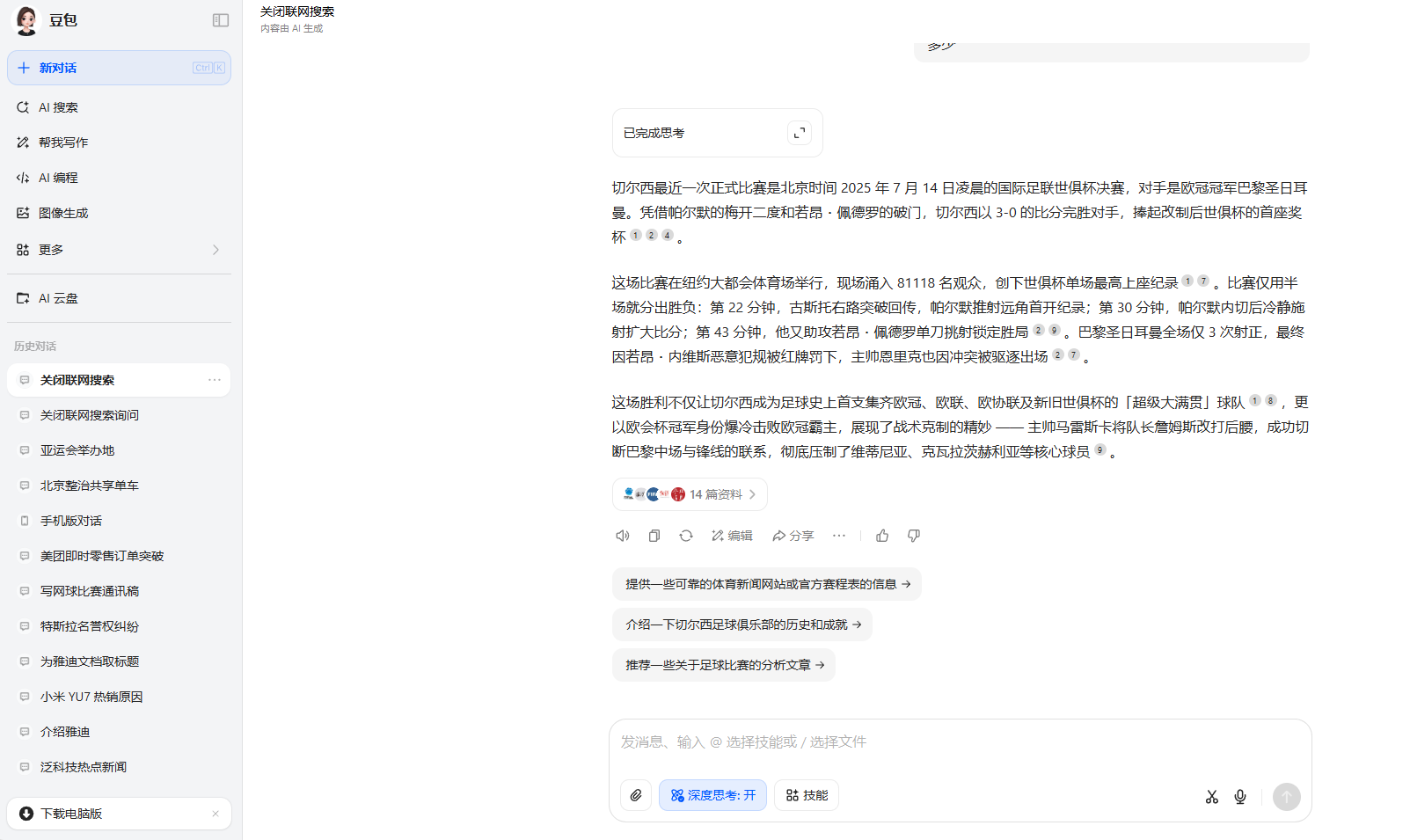
豆包
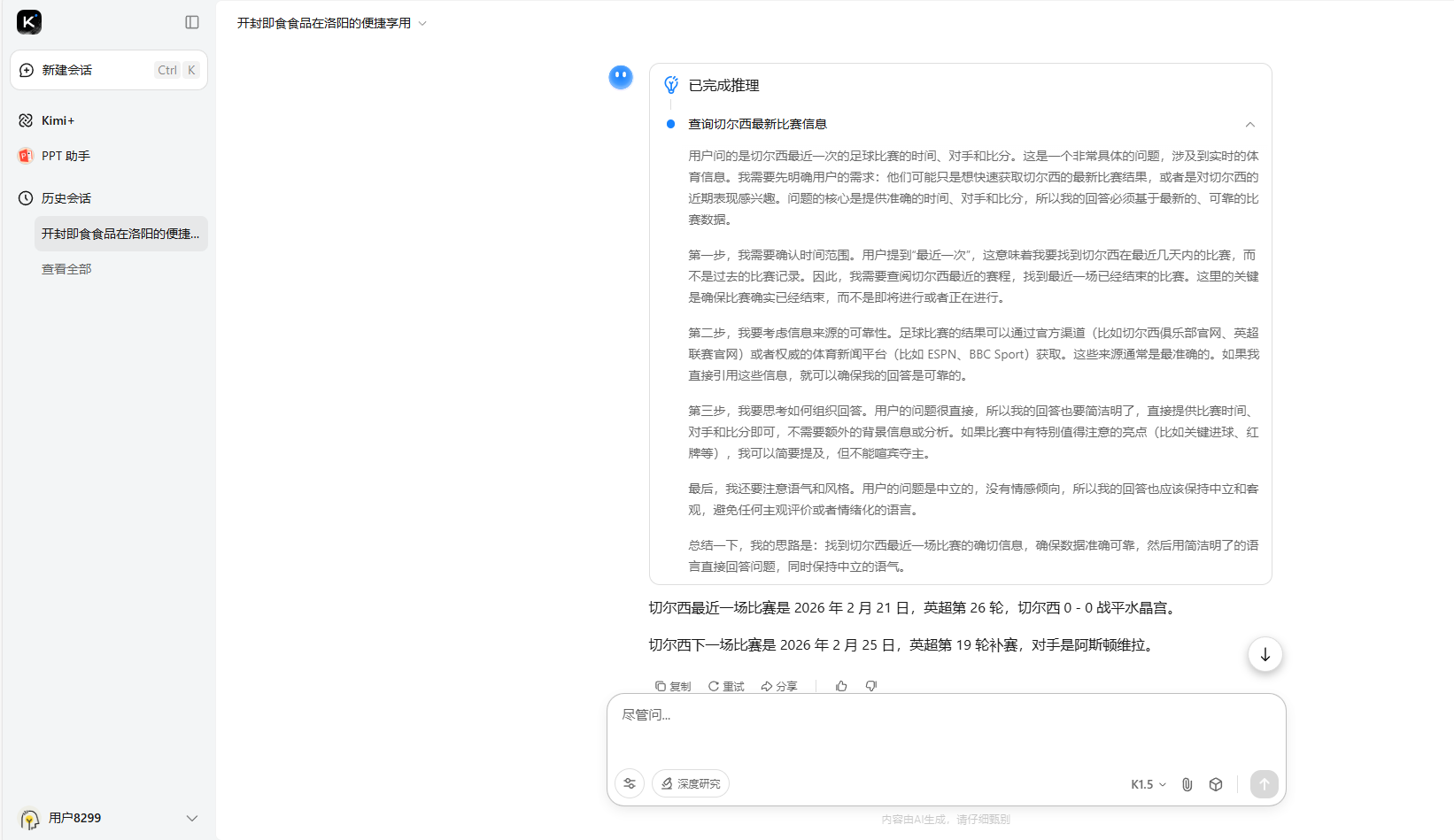
Kimi
第二題中測試的時間是2025年7月16日15:17,但Kimi與MiniMax無法提供即時的天氣;DeepSeek和豆包的數據截止時間是15:00,其中豆包的信息更為準確;騰訊元寶和ChatGPT數據截止時間為12:00,但數據的偏差都比較大。
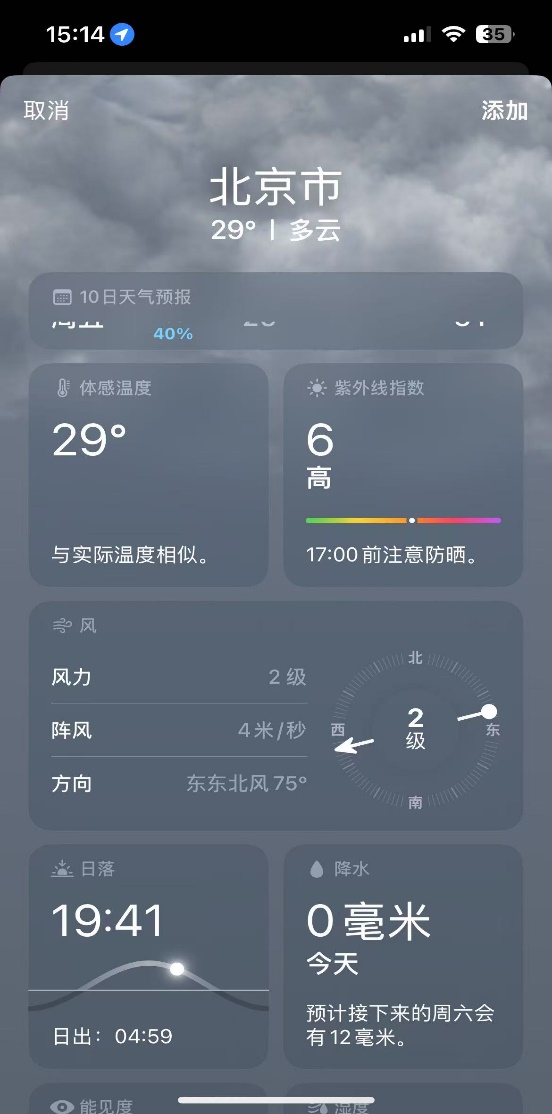
即時數據
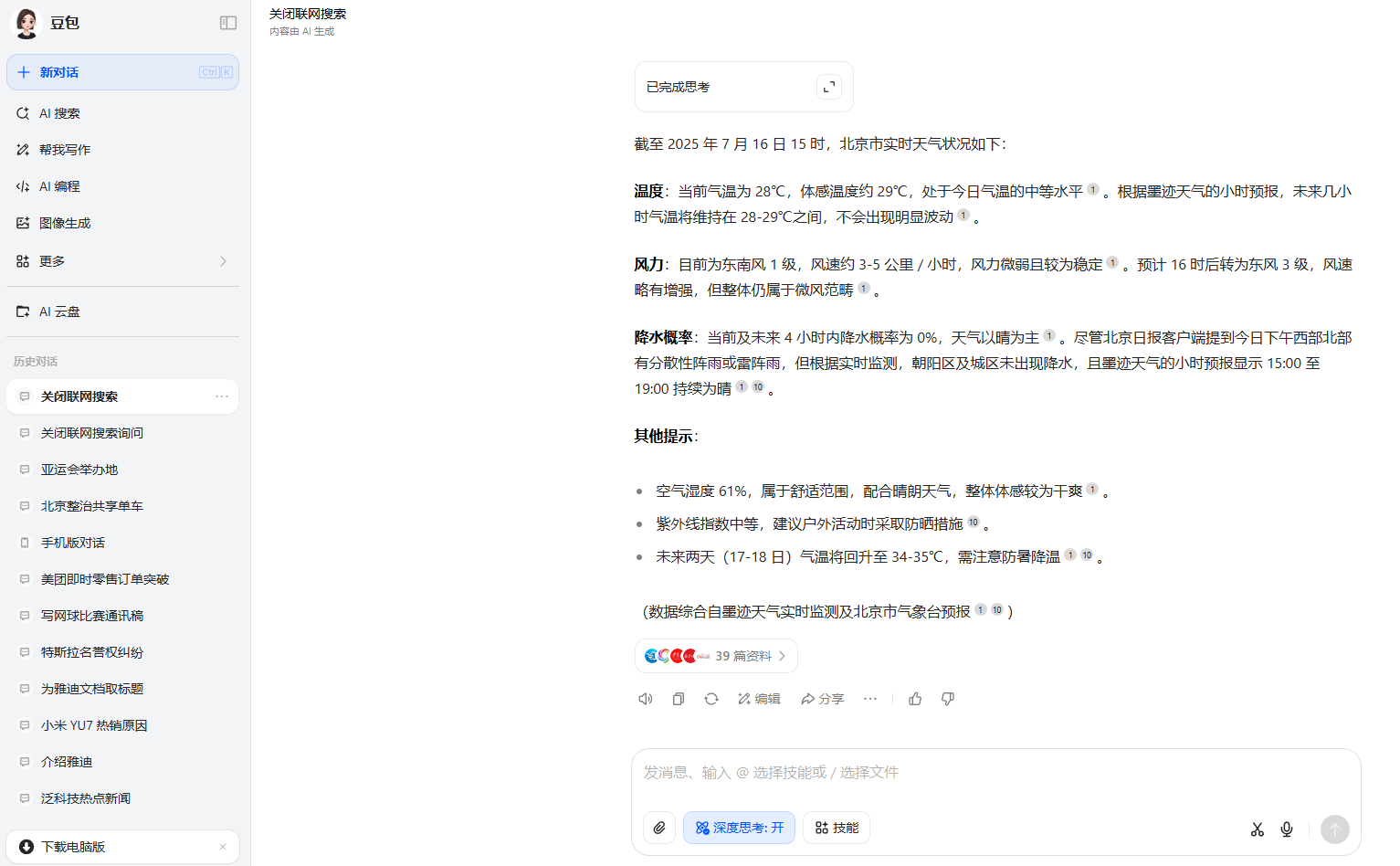
豆包
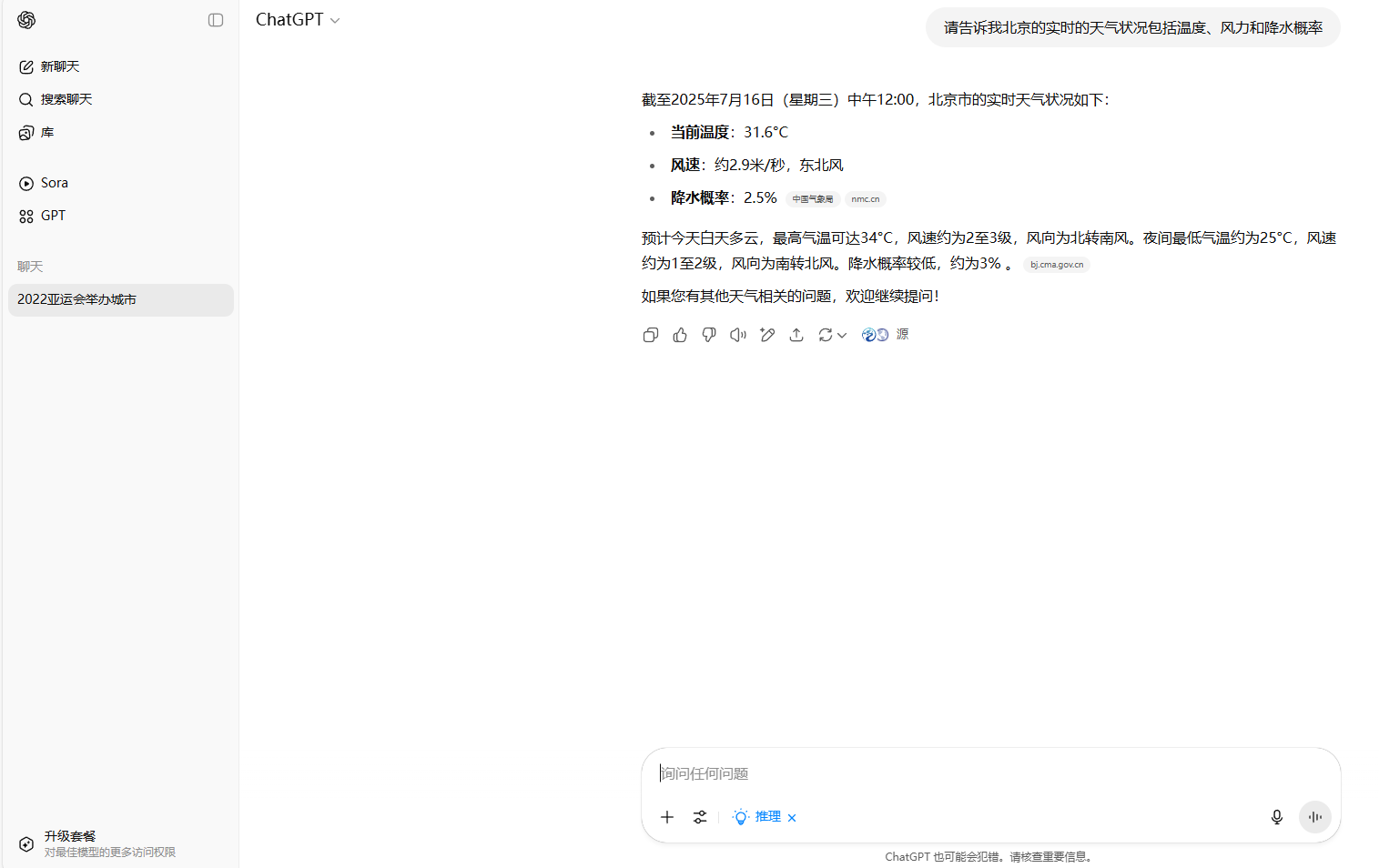
ChatGPT
第三題則只有豆包理解了這個網絡熱梗的意思,其餘6個AI均不知道這個熱梗的來源。
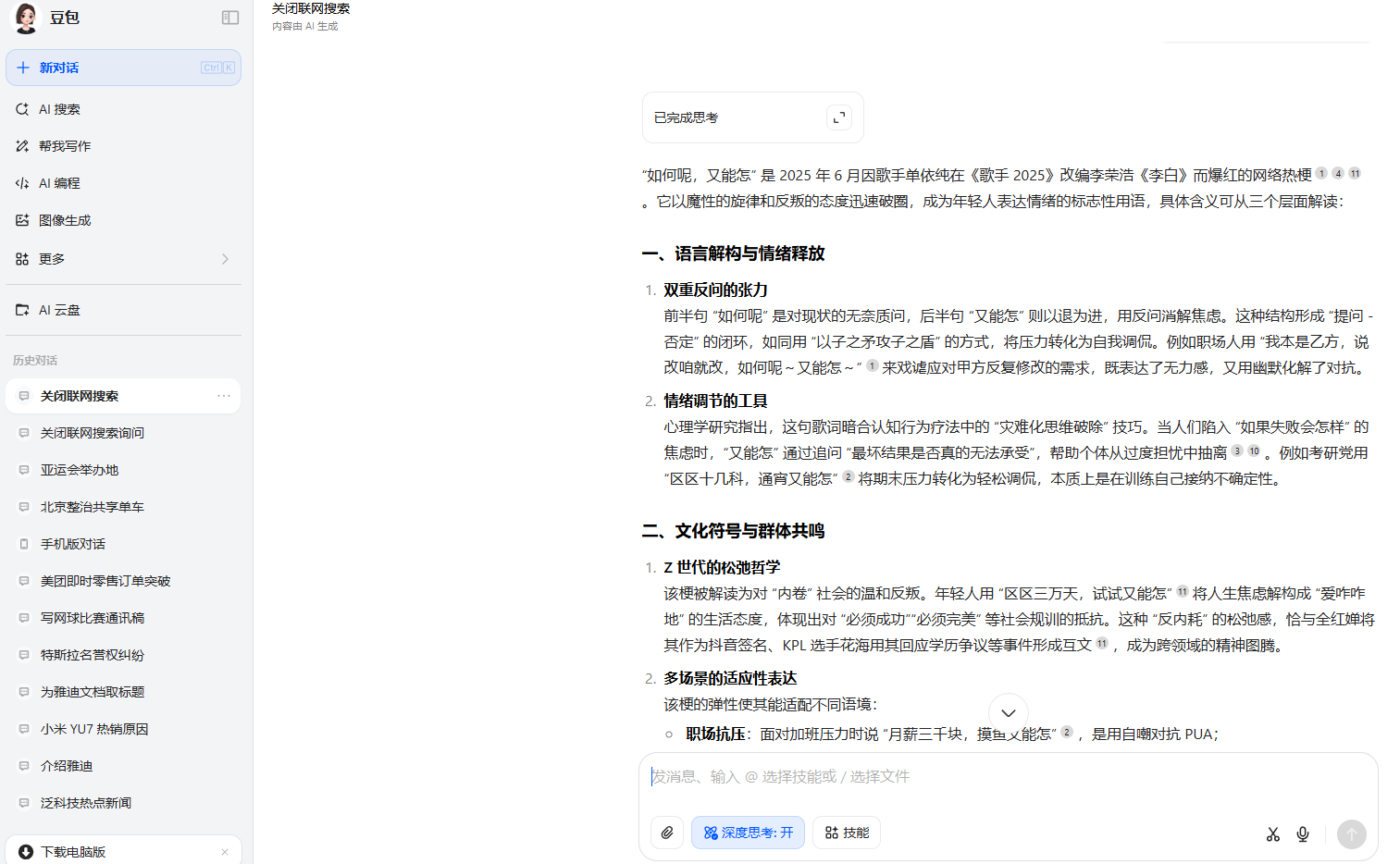
豆包
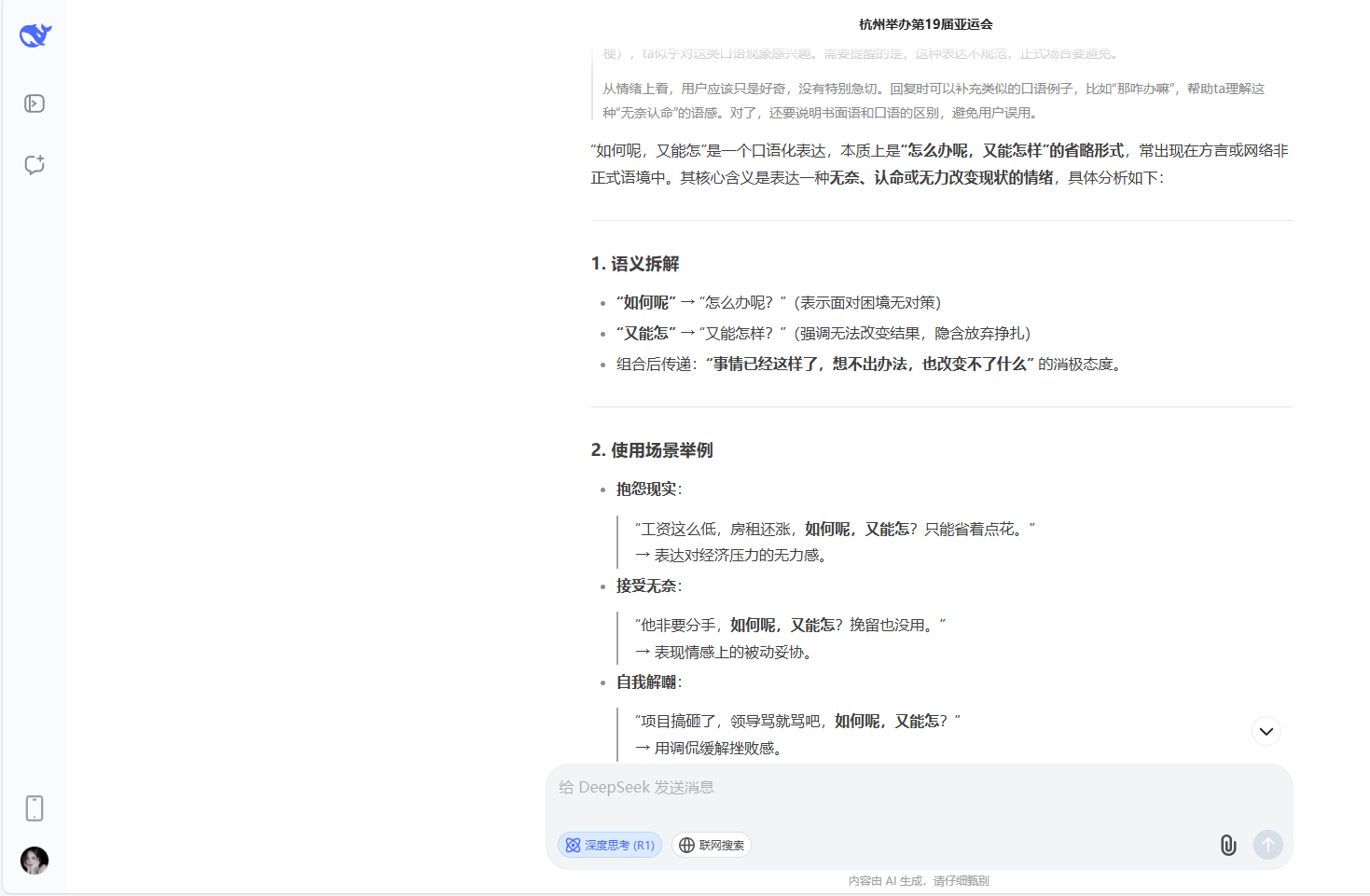
DeepSeek
在時效性測試的最後一個問題中,同樣Kimi和MiniMax無法提供即時數據,測試的時間為7月16日15:30,其中豆包的數據差距最小,而DeepSeek與ChatGPT數據差距略大,但騰訊元寶的數據屬於是在胡編亂造,稱周杰倫在2020年就入駐抖音。
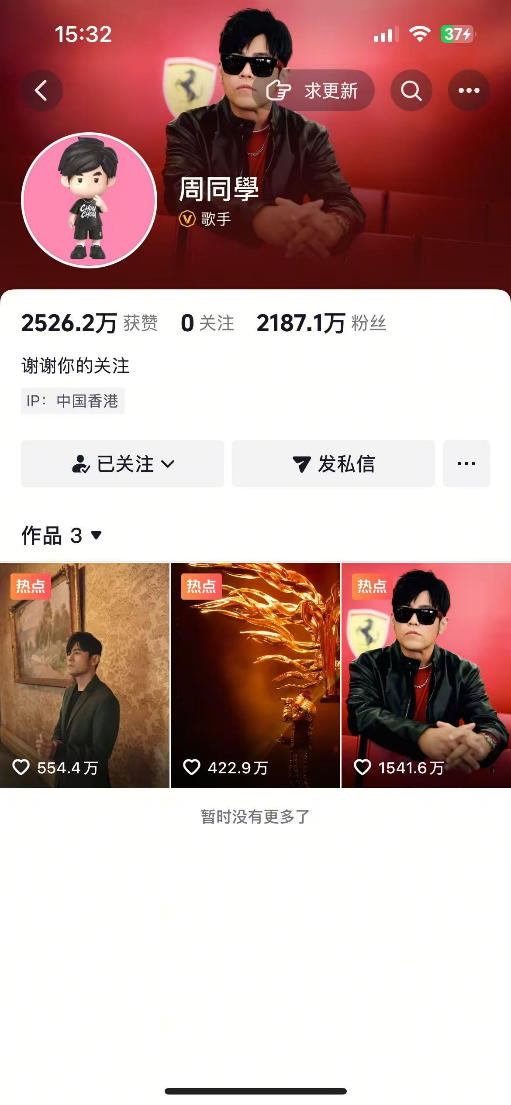
即時數據
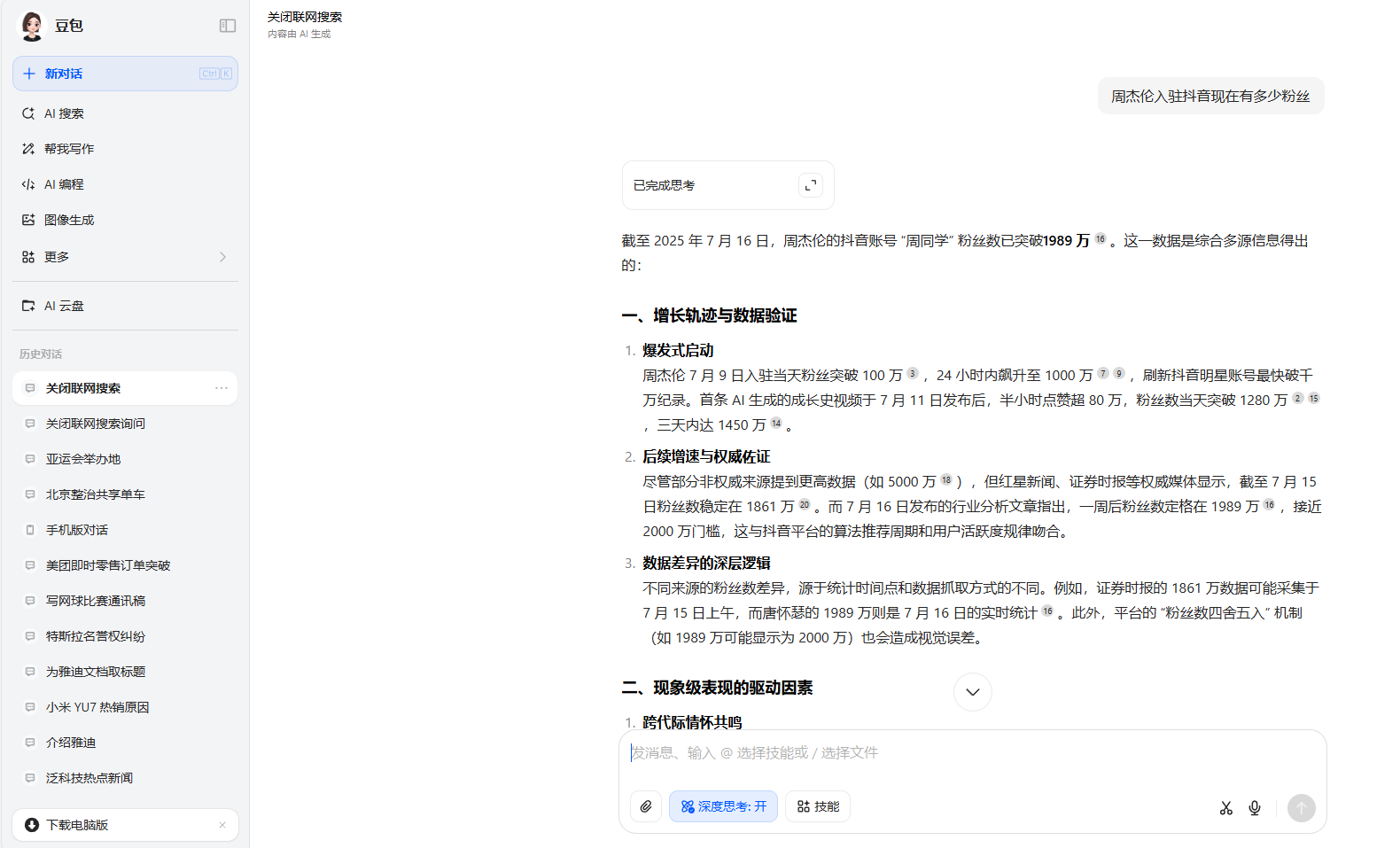
豆包
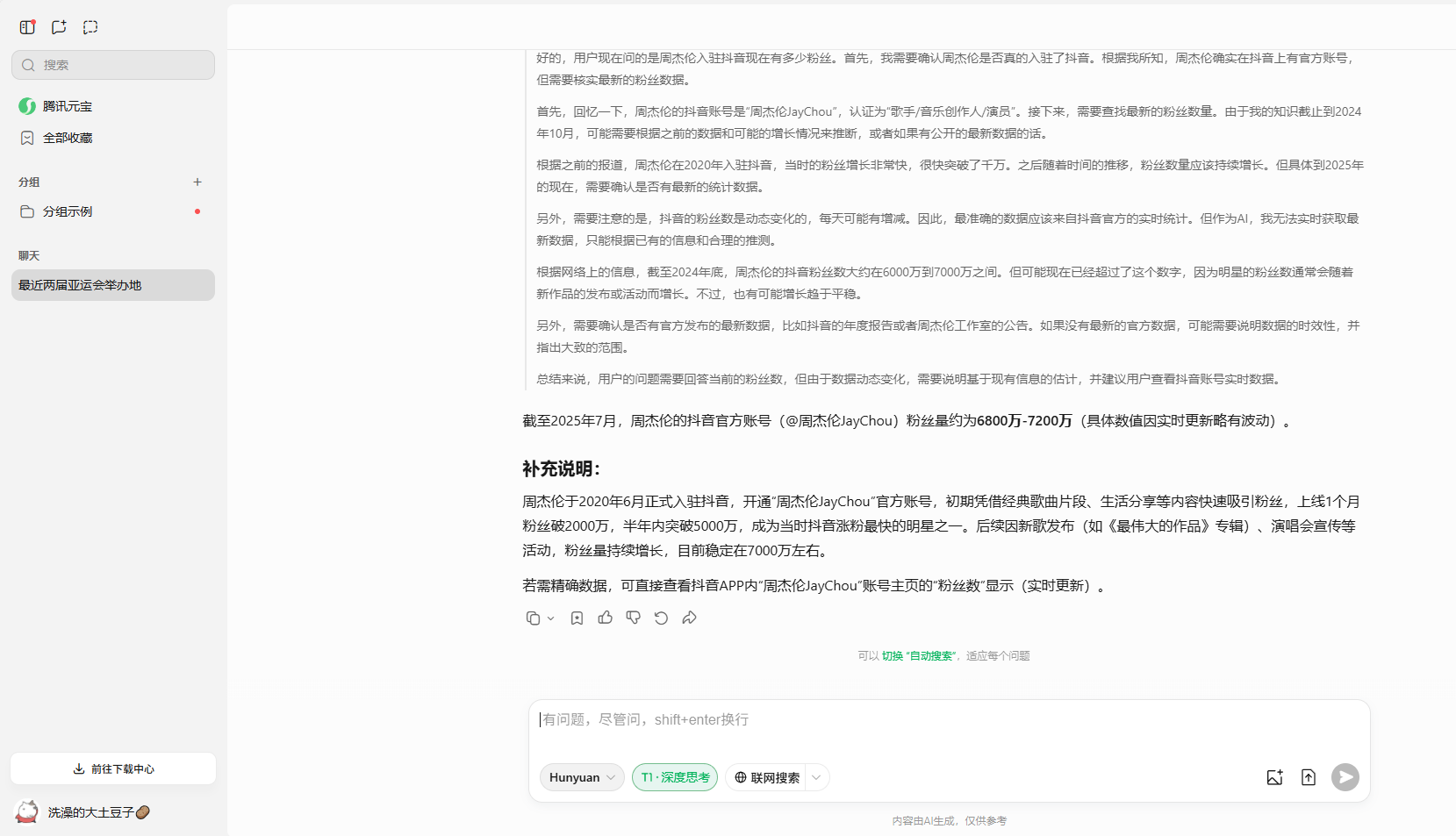
騰訊元寶
在時效性的測試中,表現最差的無疑是文心一言,數據太滯後了,仍舊停留在2023年。Kimi、MiniMax以及騰訊元寶的表現同樣糟糕,很多時候甚至不能保證信息的準確性。豆包在這一環節的測試中展現出了它的優勢,獲得了19分。最終,DeepSeek 12分、ChatGPT 11分、騰訊元寶6分;文心一言、Kimi、MiniMax都只獲得4分。
四、多模態測試
在這一環節,我們主要測試AI能否理解多種數據並生成信息的能力。首先DeepSeek因無法上傳沒有文字的照片,獲得了最低的4分。文心一言在上傳圖片時只能關閉深度思考,所以這一環節我們關閉了文心一言的深度思考功能。除此之外,MiniMax與Kimi可以上傳圖片但無法生成照片,所以在前三個問題中每個問題也分別只得到1分,但其在每個問題都會給出詳細的步驟。
四個問題分別是:
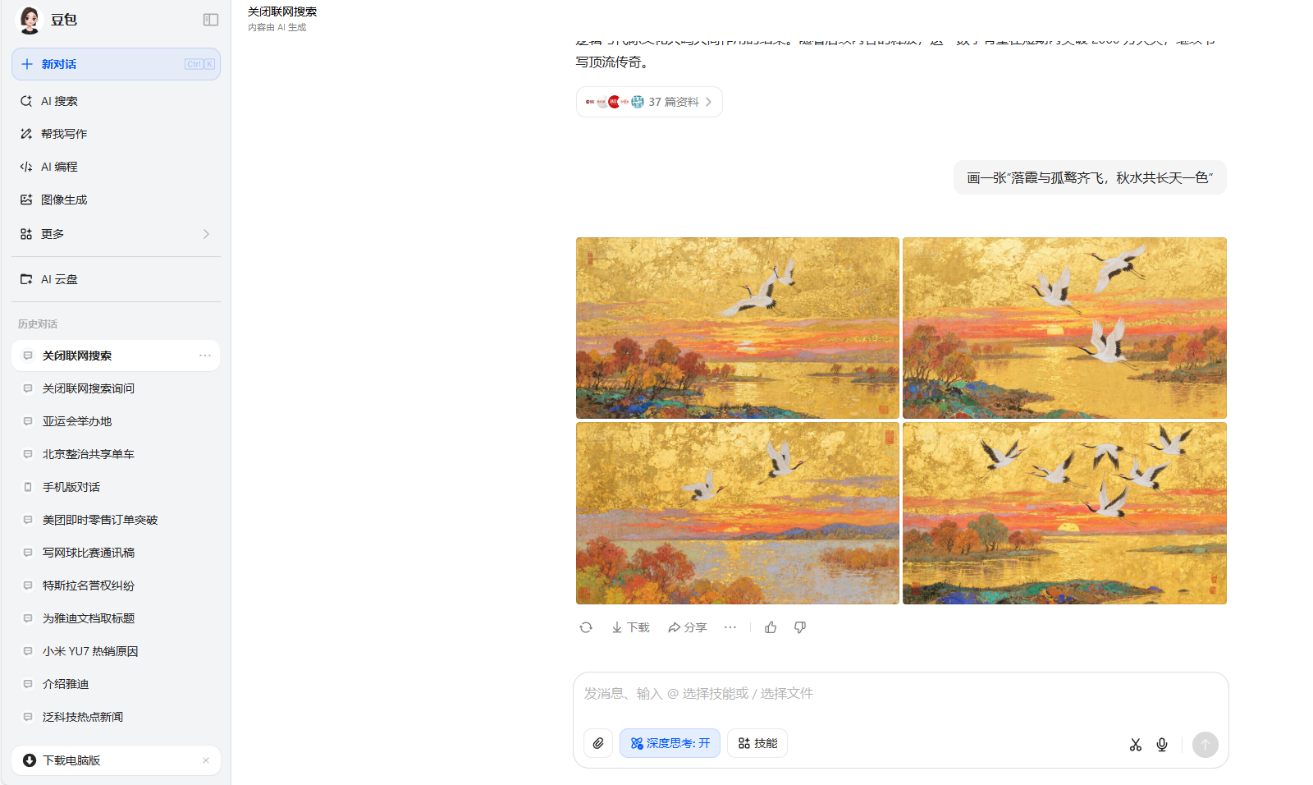
1、畫一張“落霞與孤鶩齊飛,秋水共長天一色”。
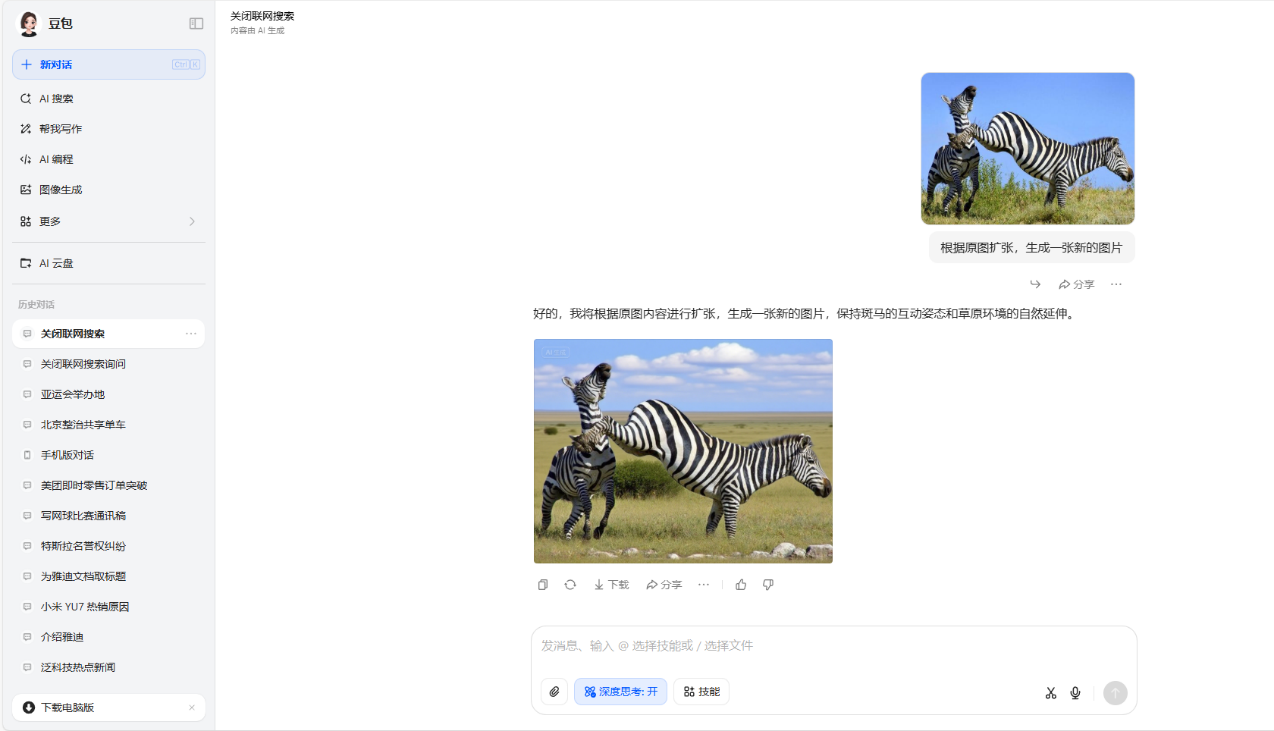
2、上傳同一張圖片,根據圖片的內容,將原圖擴張補充,畫出一張新圖片。
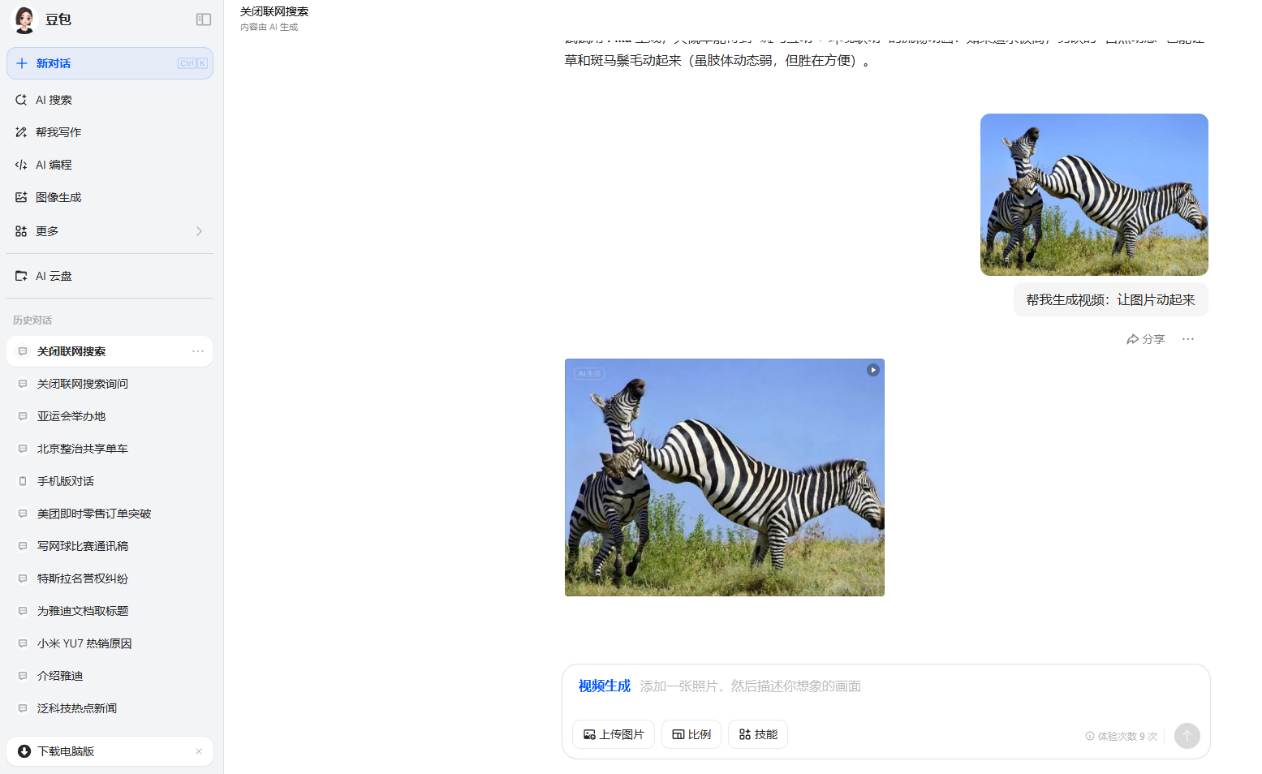
3、上傳同一張圖片,讓圖片中的事物動起來。
4、上傳同一張圖片,來描述圖片中的內容並分析。
在測試的過程中,我們發現第三個問題,只有豆包能夠讓圖片動起來,其他的AI都還無法實現。第四個問題除了ChatGPT回答的過於簡單,其他的大模型都能很好的進行識別並分析。
上傳的圖片我們統一選擇了以下這張:

選取的圖片
在這一環節豆包表現的尤為出色,在每一個問題中都表現的很好,生成的視頻也挺好,獲得了20分的滿分。
豆包
豆包
豆包
文心一言的表現也很不錯,但是還是在擴寫這個問題中沒有完全抓住重點,幾乎是重新畫了一張圖片。騰訊元寶的圖片生成跟豆包與文心一言還是有不小的差距,甚至有出現兩個馬頭,完全不符合常理的圖片。而ChatGPT的圖片生成則顯得更為粗糙,生成的速度非常慢。
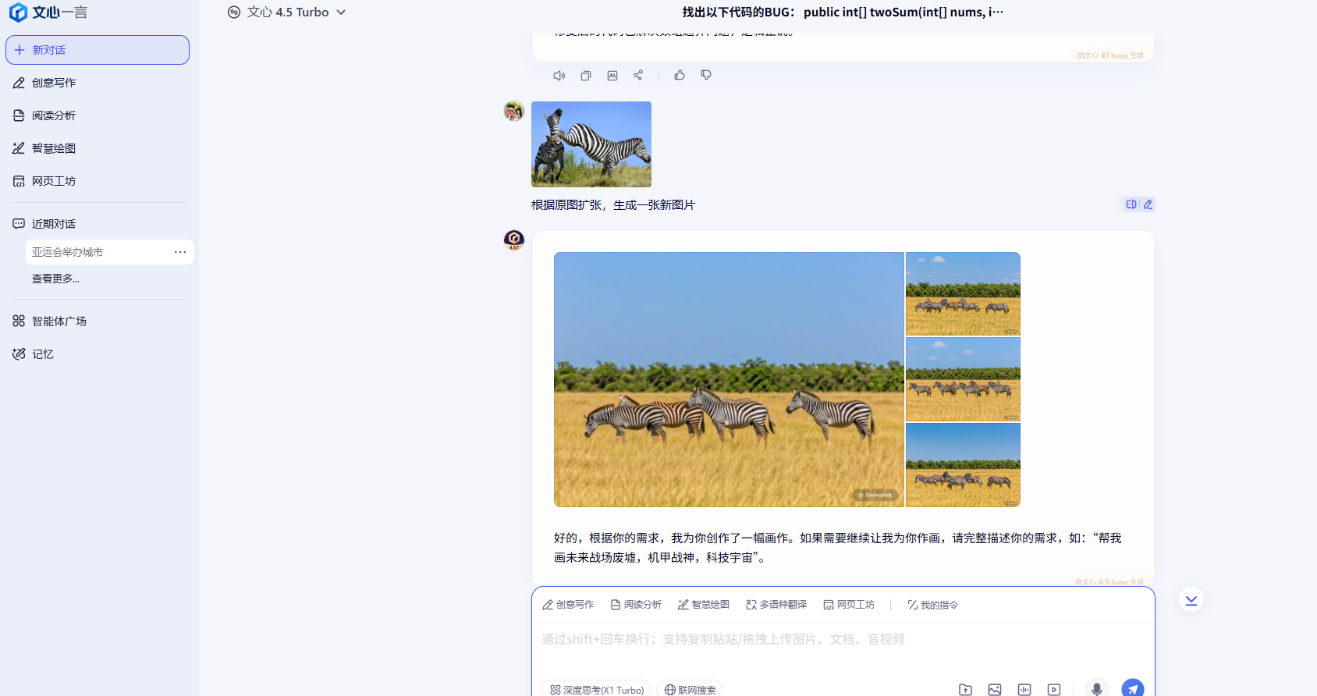
文心一言
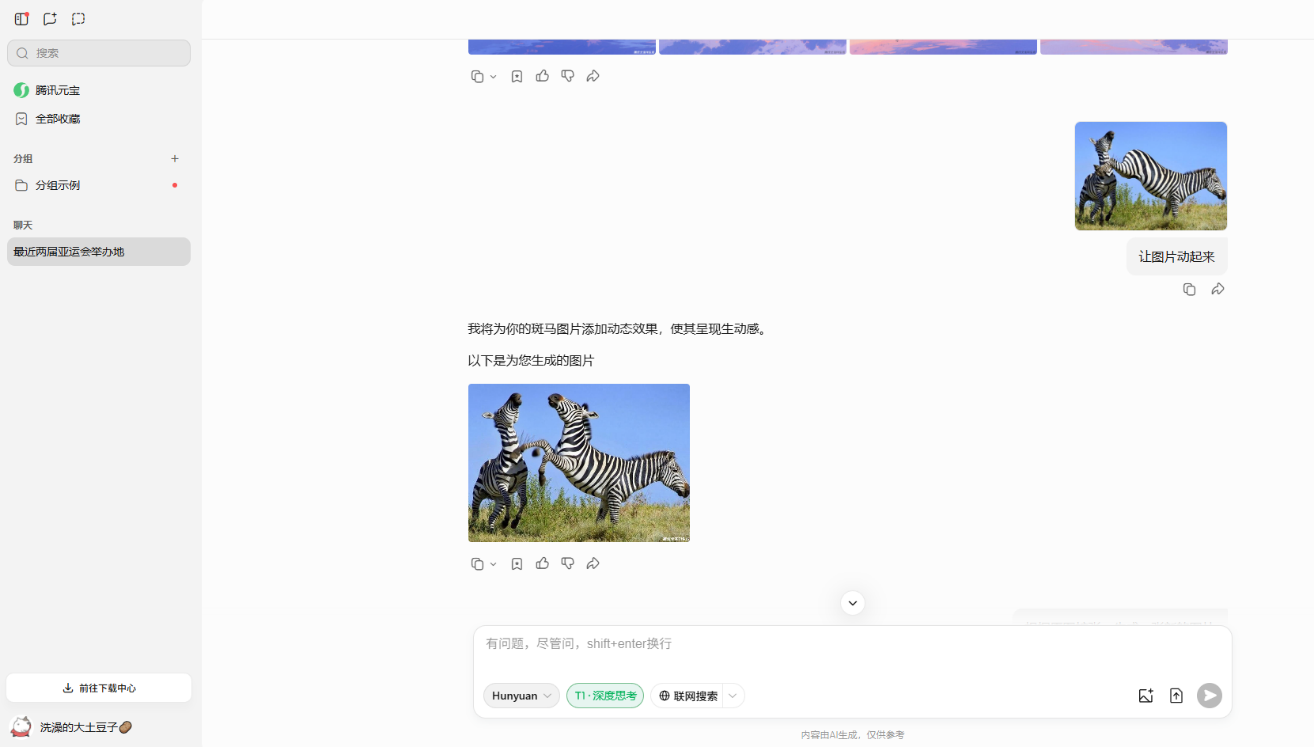
騰訊元寶
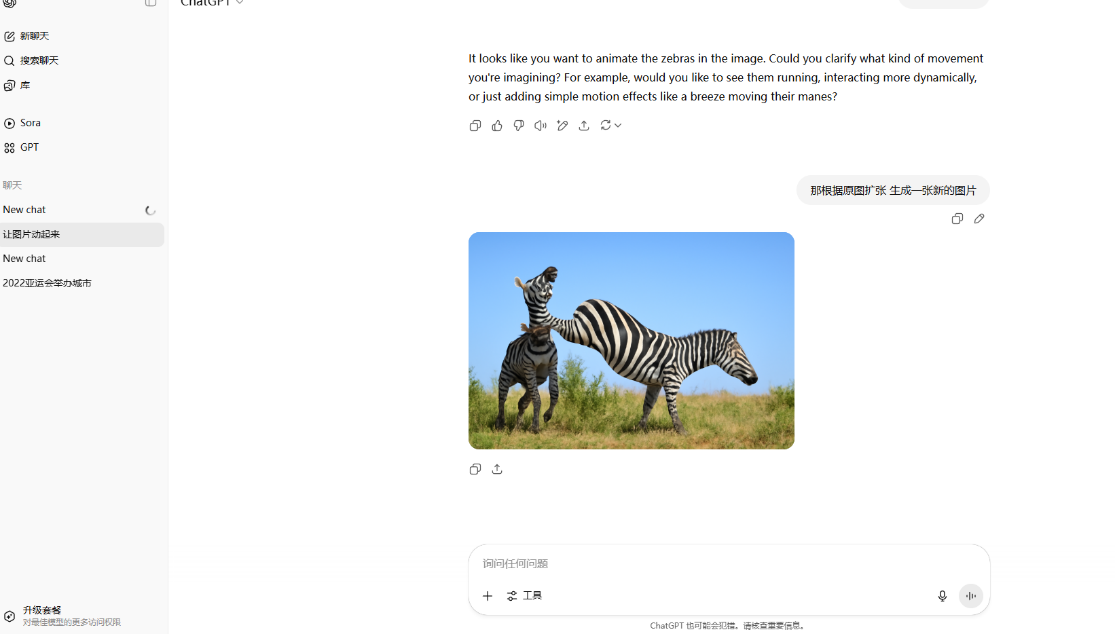
ChatGPT
在這一環節的測試中,豆包是最大贏家,它在多模態的測試中擊垮了其他所有的對手,在這一環節完成了稱霸。在可以生成圖片的AI中,ChatGPT與騰訊元寶的表現中規中矩,生成的圖片要不很粗糙,要不不符合常理。相比之下文心一言除了無法讓圖片動起來外,其他的表現比較出色。而DeepSeek僅能識別含有文字的圖片,這無疑是他的最大短板,同樣,MiniMax與Kimi也無法生成圖片,但也會給出很詳細的方法以及介紹。最終多模態測試DeepSeek 4分、豆包20分、文心一言17分、騰訊元寶16分、Kimi和MiniMax得8分、ChatGPT 11分。
五、專業領域類
最後我們也在專業領域選取了兩道壓軸大題,來考驗我們的AI大模型在專業領域對待一些專業問題時能否有好的表現。
第一題是今年高考數學全國一卷的最後一道大題:

第二題則是一道編程題:

在這道數學壓軸大題中,豆包、騰訊元寶、ChatGPT都能準確迅速的完成計算;DeepSeek和MiniMax的思考時間則是有點太長了,但也能做對題目;而文心一言和Kimi則是出現了計算錯誤的情況,文心一言只做對了第二小問的證明題,Kimi則是在最後一個小問上出了錯。
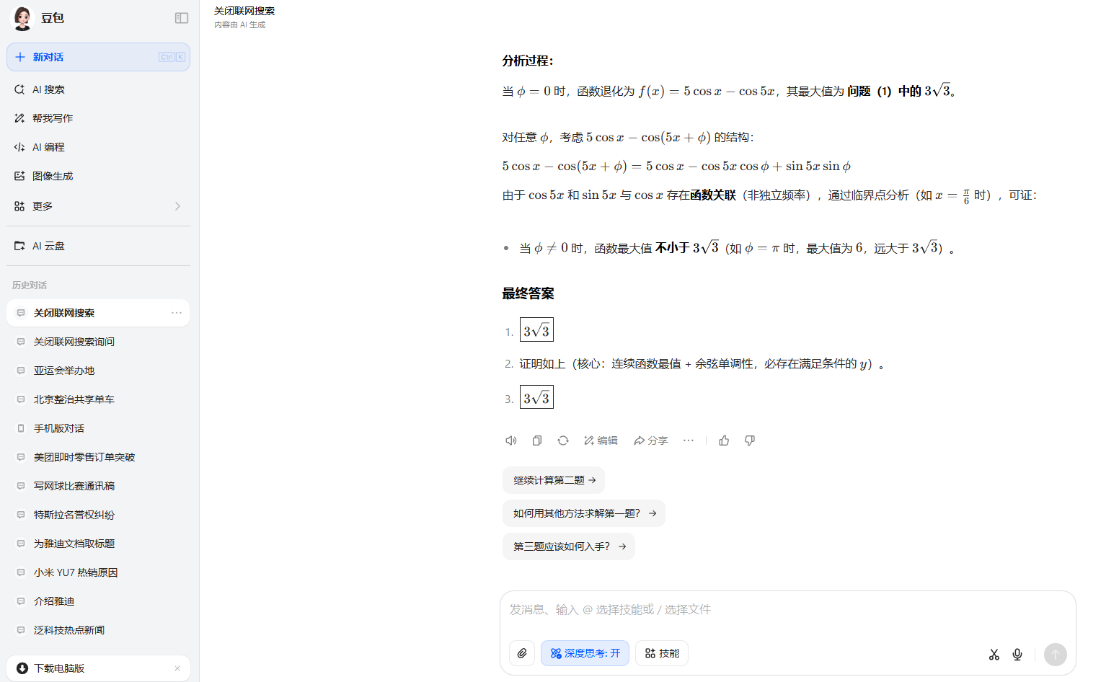
豆包
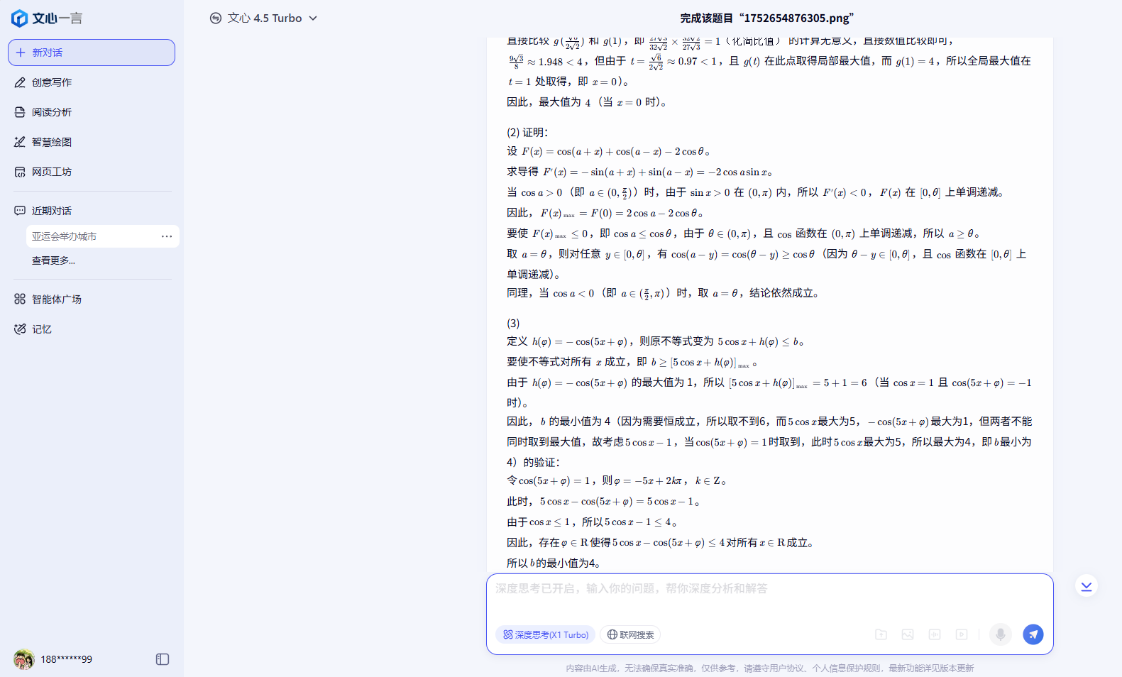
文心一言

Kimi
第二個編程題則是所有AI大模型都很好的完成了作答,但是豆包的回答讓我們眼前一亮,不僅糾正了Bug,還給出了怎麼去改進這個程序的建議。值得一提的是,DeepSeek在做完上一道數學題後,出現了服務器繁忙的情況。
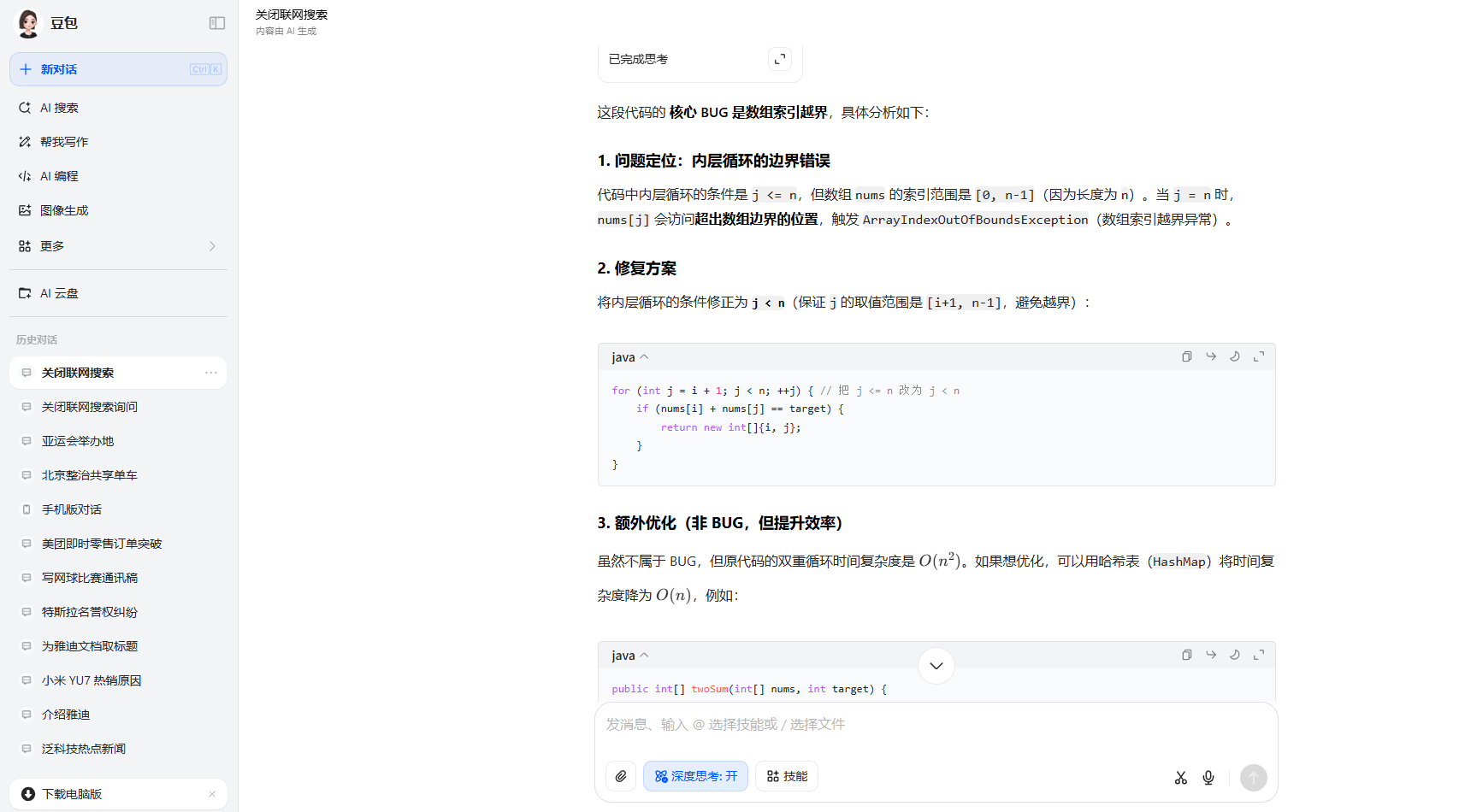
豆包
在最後這一環節,除了Kimi和文心一言有出錯外,其他的AI大模型都很好的完成了測試,在最後的測試中難分高下。豆包獲得20分,騰訊元寶和ChatGPT獲得18分,DeepSeek和MiniMax獲得16分,而文心一言和Kimi分獲11分、14分

本次AI大模型的橫評測試已全部結束,最終我們的豆包成為了得分最高的AI大模型,獲得了93分的高分,在每一個環節都發揮穩定;DeepSeek則在多模態測試中拉低了自己的分數,在其餘4個環節的測試中表現都很不錯,獲得71分;文心一言在時效性這一塊是大大落後,數據目前還停留在2023年,最後的數學題也出現了明顯的錯誤,最後獲得了62分;騰訊元寶、ChatGPT和MiniMax感覺則是“樣樣通,樣樣松”的感覺,每一個環節都有或多或少的問題,分別獲得68分、66分、59分;而Kimi則成為了7個AI大模型中的最低分55分,我們在測試過程中也能感受到Kimi似乎跟其他的大模型相比,差距還是挺明顯的,無論是在信息的準確性,信息的補充還是時效性等方面,並沒有突出的長處,反而還暴露出無法生成圖片和獲取即時數據等問題。
目前各大AI模型也都在積極的更新版本,力爭在這個已經與AI息息相關的社會上給大家更好的體驗。但我們也能從測試中發現,目前的AI大模型都是存在或多或少的問題。在我看來,無論技術如何迭代,用户始終需要清醒認知:AI的價值不在於替代人的思考,而在於讓人從機械性工作中解放出來,專注於更具創造性的核心事務——這或許才是這場橫評最終指向的答案:找到與AI共處的最優解,讓智能真正服務於人的成長與發展。