VLSI 2025最詳細論文解讀,來了!_風聞
半导体产业纵横-半导体产业纵横官方账号-探索IC产业无限可能。25分钟前

本文由半導體產業縱橫(ID:ICVIEWS)編譯自semianalysis
芯片巨頭,各展神通。
近日,semianalysis以技術為重點,總結了今年 VLSI 大會上的精彩內容,包括頂級設計和集成技術。其中包括芯片製造領域的最新進展:晶圓廠數字孿生、先進邏輯晶體管和互連的未來、超越 1x 納米節點的 DRAM 架構等等。
半導體設計和製造正變得越來越複雜,這不僅增加了開發成本,還延長了設計週期。數字孿生技術能夠在加速的虛擬環境中進行設計探索和優化。藉助數字孿生技術,工程師可以在任何硅片進入晶圓廠之前確保設計能夠正常工作。
數字孿生:從原子到晶圓廠
數字孿生涵蓋了整個半導體設計範圍:
原子級:模擬晶體管接觸和柵極材料工程中原子之間的量子和牛頓相互作用。
晶圓級:優化虛擬硅片中的工具室和工藝配方,以提高產量和性能。
晶圓廠級別:通過協調整個設備的維護和管理,最大限度地提高晶圓廠的生產力。
來源:Synopsys
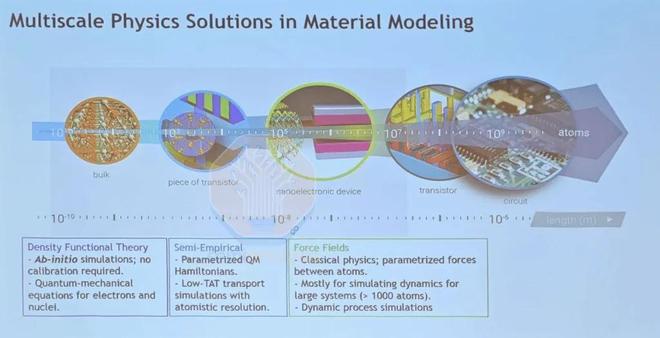
在原子模擬方面,新思科技概述了其QuantumATK套件,該套件用於材料工程中的晶體管觸點和柵極氧化物堆疊設計,這些設計對器件性能至關重要。傳統的密度泛函理論 (DFT) 建模原子間的量子效應最精確,但計算成本高昂;而傳統的牛頓原子相互作用的力場模擬速度快,但精度有限。GPU 加速的 DFT-NEGF(非平衡格林函數)僅使用 4 倍 A100 即可實現 9.3 倍加速(相對於 CPU);而使用矩張量勢的機器學習力場模擬則展現了接近 DFT 的精度,計算成本為 17 分鐘,而傳統 DFT 則需要 12 天。
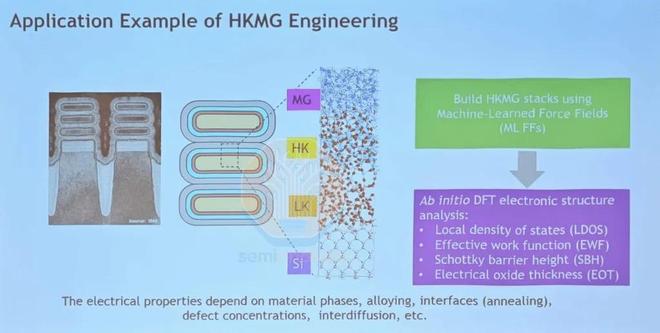
來源:Synopsys
這些原子模型對於理解不同材料層界面處發生的電相互作用至關重要。在接觸工程中,MLFF 用於生成晶體硅和非晶硅化物之間的接觸界面,模擬邊界發生硅化作用的相互擴散深度。然後使用 DFT-NEGF 計算界面上的接觸電阻和電流-電壓曲線。對於柵極氧化層設計,使用 MLFF 構建複雜的多層功函數金屬疊層,並進行模擬以檢查其結構和化學成分。然後可以引入偶極子摻雜物並使用 DFT 進行優化,DFT 還可以進行靜電分析以計算關鍵參數,例如有效功函數、肖特基勢壘高度和等效氧化層厚度。隨着我們逐步推進“全環繞柵極”設計方案,這些原子模擬在選擇合適的材料方面將變得更加重要。
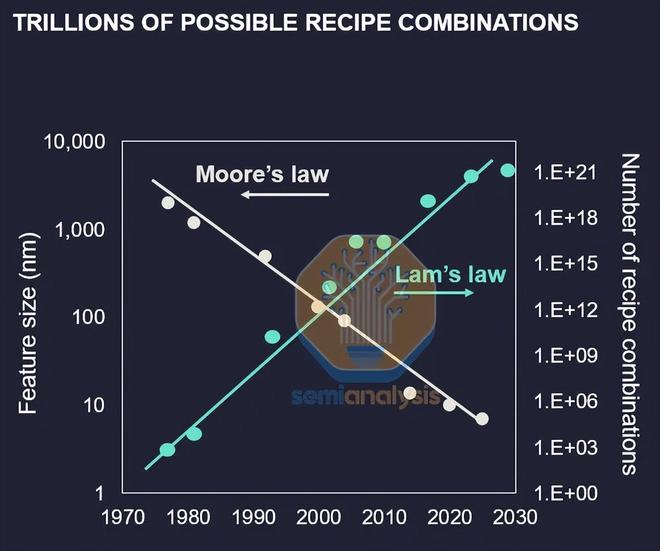
拉姆定律:隨着複雜度的增加,可能的配方組合數量呈指數級增長。來源:Lam Research
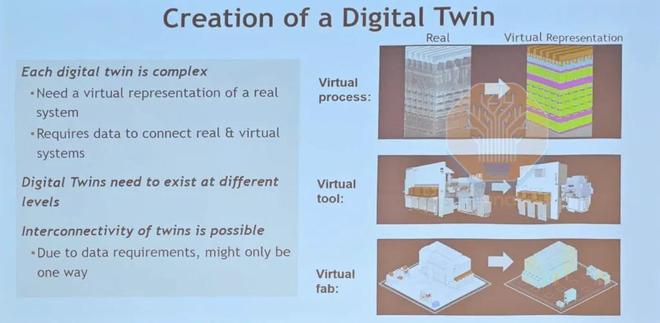

Lam 的數字孿生產品涵蓋從工藝到設備,乃至虛擬晶圓廠的廣泛領域。來源:Lam Research
關於利用虛擬硅片進行晶圓級優化,Lam Research 展示了其Coventor SEMulator3D軟件的研究成果。隨着晶體管幾何結構從平面到 FinFET 再到 GAA 的複雜性不斷提升,可能的工藝配方組合數量也呈指數級增長,他們將其稱之為“拉姆定律”。虛擬晶圓製造採用經過優化參數的訓練模型進行工藝仿真,使工程師能夠拓寬工藝窗口、提高良率,同時減少驗證變更所需的物理測試晶圓周期數。Lam Research 還將其沉積和蝕刻工具構建為數字孿生,利用等離子體流模擬構建虛擬腔室,以幫助預測配方,同時優化腔室設計以確保整個晶圓的均勻性。
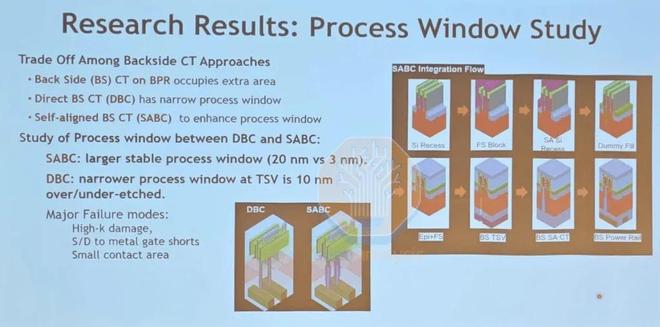
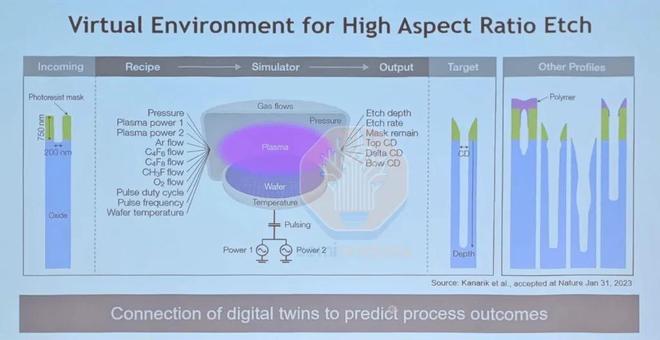
來源:Lam Research
這些模擬工具已用於工藝窗口研究,以選擇具有最寬工藝窗口的背面接觸方案,同時研究每種方案如何影響納米片晶體管的應力和應變。高深寬比刻蝕方案還使用虛擬環境來預測給定輸入掩模圖案的工具輸出刻蝕輪廓。將這些刻蝕輪廓與目標輸出輪廓進行比較,並給定一個距離,然後通過在數字孿生中進行進一步測試來最小化該距離。


來源:Lam Research
在晶圓廠層面,Lam 還介紹了實現“無人值守”晶圓廠所需的工作。“無人值守”晶圓廠無需人工干預,因此可以隨時關閉燈光。設備羣需要以近乎即時的速度在虛擬孿生中進行協調,以協調設備停機時間並最大限度地提高晶圓廠的生產力。設備本身需要具備預測性維護的“自我意識”,使用內置的計量工具來檢測設備在其整個生命週期內的校準和工藝漂移。對於“無人值守”晶圓廠,每台設備的目標應該是至少一年不間斷運行,無需人工干預,故障後自動恢復,並能夠自行請求維護。

來源:Lam Research
設備維護將通過機器人零件配送以及耗材和易損件的安裝實現自動化,設備的設計也將圍繞機器人維護進行。雖然Lam提出了2035-2040年的概念性目標,但無人值守晶圓廠面臨的主要障礙在於不同供應商設備之間的數據和連接,以及維護流程的標準化。
台積電 DRAM BEOL
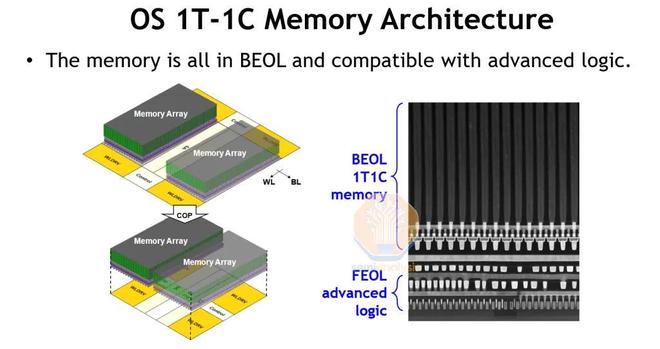
來源:台積電
由於SRAM位密度不再隨着新工藝節點的提升而提升,台積電研發部門試圖重振eDRAM,以提高芯片緩存密度。嵌入式DRAM上一次亮相是在IBM基於GlobalFoundries 14nm工藝的z15處理器中。其主要創新之處在於,台積電能夠在BEOL金屬層內製造整個存儲器陣列,並且DRAM晶體管和電容器的形成方案在BEOL工藝流程的400攝氏度極限範圍內。這釋放了前端晶體管和底層金屬層,用於功能邏輯塊。隨着現代處理器設計不斷提高SRAM與邏輯面積的比例,能夠在主動邏輯之上堆疊基於DRAM的最後一級緩存,將代表可擴展性和設計方面的突破。
然而,演示仍處於研發早期階段,下方可用的高級邏輯區域僅用於容納 DRAM 外圍邏輯(字線驅動器和感測放大器),以提高存儲密度。製造的 4Mbit 宏的位密度僅為 63.7 Mb/mm²,甚至不到現代高密度 6T SRAM 的兩倍。作為參考,美光最新的 1-gamma DRAM 的密度約為其 9 倍,但性能和可訪問性不足以用作片上緩存。
雖然台積電沒有透露何時可以投入產品化,但它確實展示了該技術未來幾代的巨大潛力,它將從根本上改變芯片的設計方式。
DRAM:4F2和3D
DRAM 在其五年發展路線圖上有兩個拐點:4F2和3D。目前已使用十多年的6F2只能擴展到 1D 節點。鑑於 1C 現已量產,1D 應該會在未來 1-2 年內問世。SK 海力士強調了超越 1D 節點的幾個關鍵挑戰:
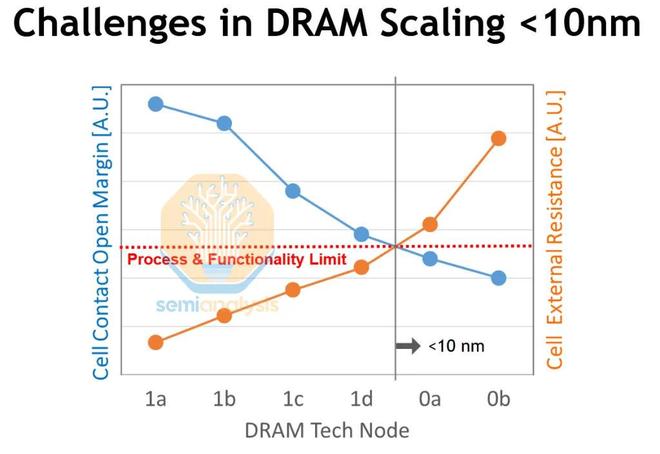
來源:SK海力士
單元接觸面積,尤其是存儲電容器連接到下方控制晶體管的存儲節點接觸面積,會隨着單元臨界尺寸的平方而縮小。這些接觸面積必須足夠大/對準度足夠好,以便在晶體管和電容器之間提供良好的電連接,但又不能過大或錯位,以免與任何相鄰單元短路。這就是上圖中的“單元接觸開口裕度”,它會隨着每個節點的縮小而縮小。在1d時,工藝和工具已達到可行、高良率工藝的極限。
隨着器件和互連線尺寸的縮小,其電阻也會隨之增大。這就是上文提到的“單元外部電阻”。它是存儲單元和感測放大器之間所有電阻元件的總和。位線觸點和本地位線(金屬)線本身是兩個主要電阻因素。隨着尺寸的縮小,它們的電阻都會增大。這會減慢單元的運行速度並降低單元的讀取裕度,這兩者都是不可取的。操作速度受單元和位線之間電荷轉移的影響,隨着該路徑電阻的增加,電荷轉移的速度會減慢。電阻還會削弱感測放大器檢測到的電壓差。電阻太小,單元就無法可靠讀取——存儲器無法工作。
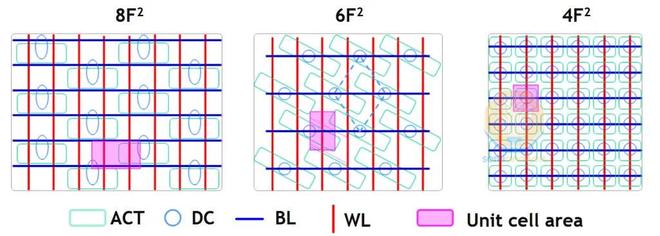
DRAM 單元佈局。ACT = 單元控制晶體管的有源區。DC = 直接接觸,位於位線和晶體管漏極之間。BL = 位線。WL = 字線。來源:三星
6F 2中的單元接觸挑戰來自位線和存儲節點接觸處於同一水平面的擁塞(下圖中,存儲節點接觸表示為埋入式接觸的 BC)。
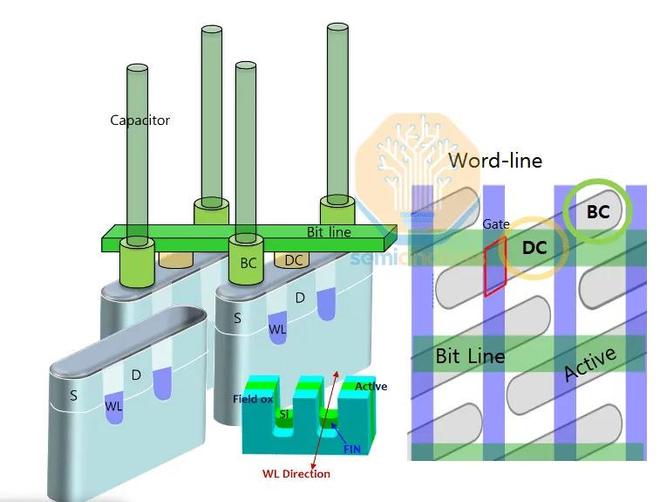
來源:三星
從側面看,很容易看出位線和觸點之間的間隙有多小:
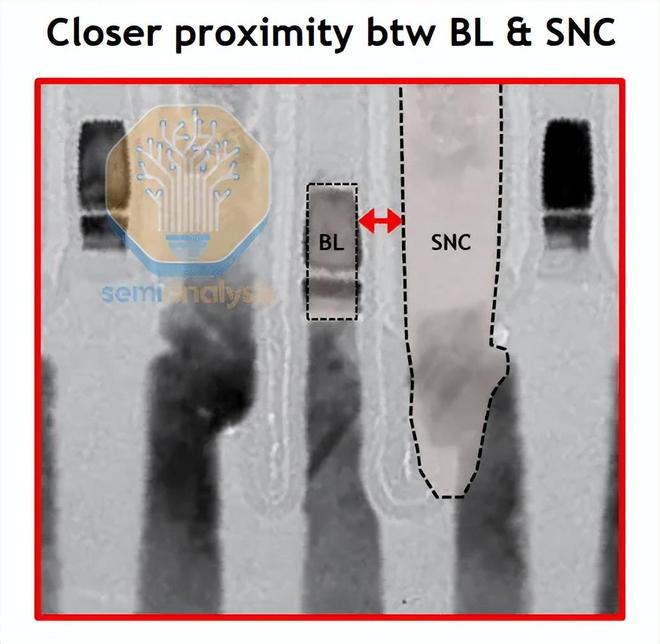
來源:SK海力士
與4F2佈局中的垂直溝道晶體管 (VCT) 相比,埋入式位線擁有獨立的空間,不會干擾任何其他元件。電流路徑也短得多,直接從電容器向下,穿過垂直溝道,直達位線。在 6F2 中,路徑向下穿過“U”形溝道的底部,然後再返回,路徑更長,因此電阻也更高。
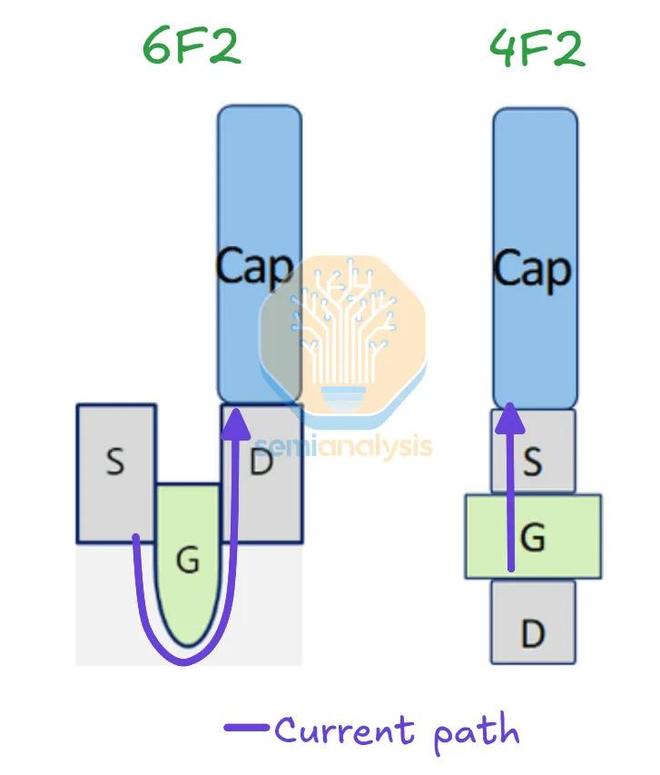
4F2中,電流通過控制晶體管和觸點的路徑更短,電阻更低,因此更多電子能夠進出電池。來源:三星,SemiAnalysis
當然,實現 4F2 也面臨挑戰,否則它早就被採用了。埋入式位線和垂直溝道晶體管都具有高縱橫比,這對於蝕刻和沉積設備來説非常困難。直到幾年前,沉積設備還無法用位線所需的金屬(可能是釕或鈷)填充深溝槽。雖然 6F2 的單元佈局減少了一些對準挑戰,但密度仍然更高,因此需要 EUV 圖案化。最後,當 6F2 仍然可擴展時,根本沒有理由冒險改變架構。
4F2 的開發中仍存在一些不確定因素,這些因素可能決定哪家晶圓廠能夠實現最低的單位成本和良好的良率,以及哪些設備供應商可能從中受益。對於存儲單元性能至關重要的柵極結構可能是雙柵極,甚至是全柵極。SK 海力士和其他公司仍在權衡。
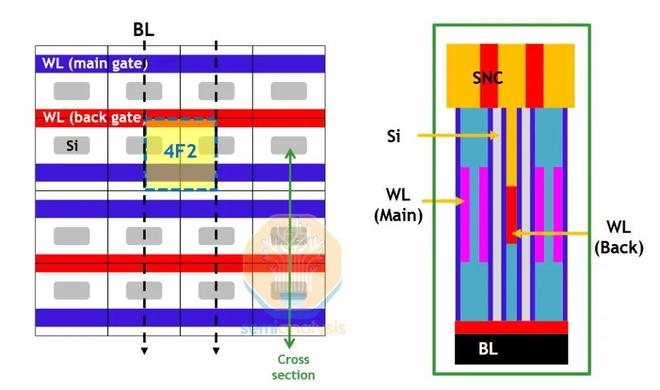
來源:SK海力士
還可以選擇“peri-under-cell”和“peri-on-cell”。傳統上,外圍電路會與晶圓正面的存儲單元相鄰,但為了提高整體密度,它會被移到單元陣列下方。“peri-under-cell”類似於背面邏輯電源,需要熔接第二片晶圓。控制晶體管在正面以陣列形式構建,然後鍵合支撐晶圓,翻轉晶圓,並構建外圍電路。之後,再次翻轉所有部分,添加存儲節點觸點和電容器本身。能夠獲得增量收益的工具供應商類似於BSPDN供應鏈——CMP、熔接、TSV蝕刻。
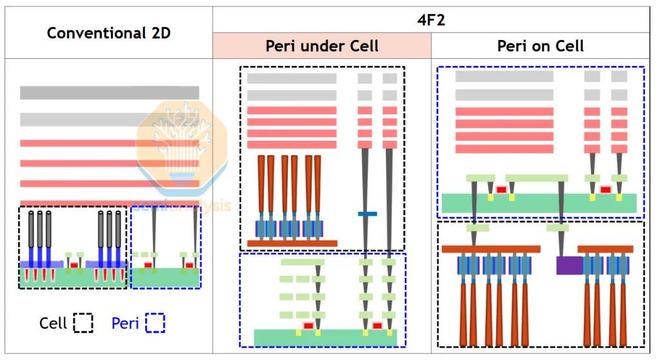
來源:SK海力士
Peri-on-cell 只是將已完成的存儲節點陣列與外圍晶圓進行混合鍵合。雖然這提供了一定的工藝靈活性——製造外圍晶圓時無需擔心損壞陣列,反之亦然——但它需要遠低於 50nm 間距的混合鍵合。這比目前的領先技術低了一個數量級。儘管如此,海力士至少在研發中正在考慮這個問題,而且無論如何,其他應用都將推動混合鍵合機的發展。
最後,3D DRAM 正在同步開發中。目前的進展表明,在 3D 技術成熟之前, 4F2的幾個節點可能已經成熟。中國芯片製造商是這一領域的一個潛在競爭者,因為他們有強烈的動力去開發 3D 技術,因為 3D 技術不依賴於先進的光刻技術。
非易失性動態隨機存取存儲器
美光公司的 NVDRAM(NV 代表非易失性)在2023 年 IEDM上首次亮相 18 個月後再次浮出水面。這是他們採用 4F2 架構、釕字線和 CMOS 底層陣列的鐵電 (HZO) DRAM 。如果你想用所有最新技術來製造一塊昂貴的內存,這可能是你最想嘗試的方法。
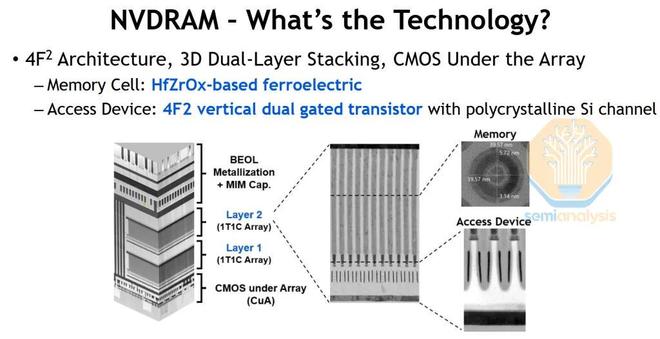
來源:美光科技
與上一篇論文相比,位單元尺寸顯著縮小了 27%,達到 41 納米,且性能絲毫未減。這使得密度達到近 0.6 Gb/mm² ,遠高於目前任何商用大容量 DRAM。
理論上,NVDRAM 比傳統 DRAM 略有優勢,因為它無需耗費電力和時間執行刷新週期。遺憾的是,每年節省的電費大約只有 1 美元。考慮到單個 DIMM 的價格在 300 美元以上,其終身節能效果遠不足以證明這款奇特產品的高昂價格是合理的。至少,在 Ru 字線、4F2、垂直通道晶體管和 CMOS 陣列方面的工作都適用於即將到來的 DRAM 節點。
二維材料
取代硅的門檻很高。任何替代材料不僅要生產出性能更好、密度更高的晶體管,還必須實用。硅晶圓是一種商品,可以很容易地在特定區域摻雜以形成晶體管溝道。二維材料目前還不具備工業規模應用的實用性。研究人員曾多次指出 ,晶圓上生長是其關鍵障礙。我們看到的關於其他創新的論文——英特爾改進了接觸形成,三星構建了具有二維溝道的CFET——令人印象深刻,但如果材料一開始就無法以經濟的方式生長,最終就會失敗。
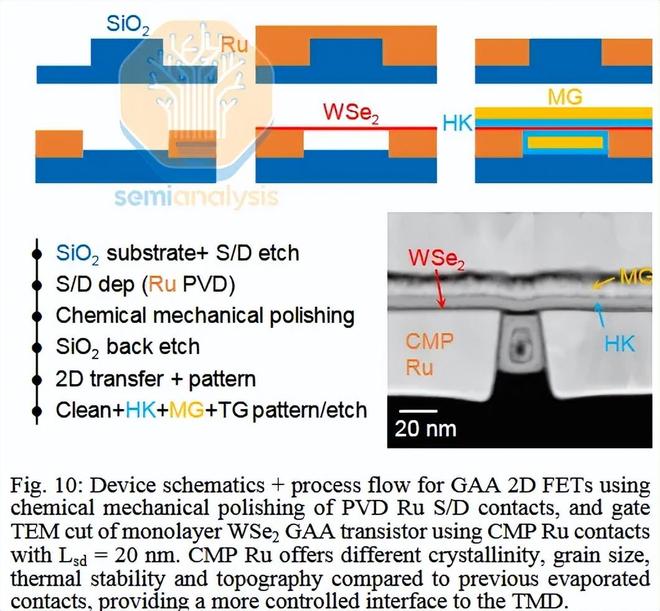
英特爾演示了使用經 CMP 拋光的釕改進的二維晶體管源漏接觸。遺憾的是,該工藝仍然依賴於轉移而非二維材料的生長。來源:英特爾
下一代架構的標杆
環柵技術已不再是邏輯領域的“下一個大趨勢”,而是正在向大規模量產邁進。Forksheet 和 CFET 已成為激動人心的下一代架構的標杆。Forksheet 是 GAA 的演進,通過在 CMOS 的 N 和 P 部分之間添加一層介電壁,使其更加緊密地連接在一起。
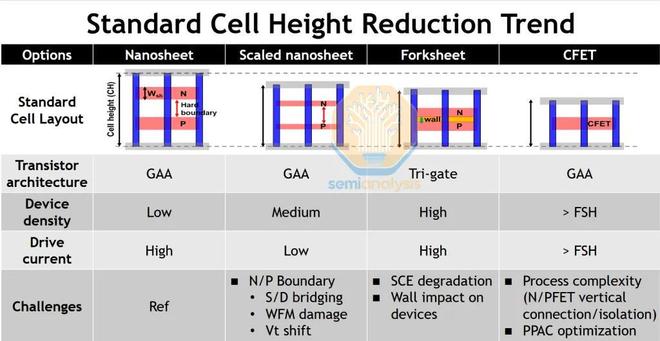
來源:台積電
在傳統架構中,NMOS 和 PMOS 器件之間的間距受到寄生電容和閂鎖效應的限制。寄生電容的增加意味着芯片運行速度變慢,功耗增加。閂鎖效應是指晶體管的徹底失效,導致輸入電壓 Vdd 形成一條不受控制的直接接地路徑。目前已有一些技術可以減輕這些影響,其中最重要的是淺溝槽隔離。
Forksheet 是一種新的、理論上更先進的技術,遵循了同樣的思路。雖然 NMOS 和 PMOS 之間的材料一直是某種絕緣電介質,但 Forksheet 需要一層精細的超低 k 材料來實現更緊密的間距。這給製造工藝帶來了新的集成挑戰和額外的成本。
開發一種既能沉積納米級厚度的高質量薄膜,又能承受後續晶體管其餘部分形成過程中的工藝處理的材料並非易事。蝕刻或沉積過程中等離子體引起的損傷是一個特別值得關注的問題。大多數論文並未在此詳細介紹其材料解決方案,但可以肯定的是,傳統上在超低k電介質領域處於領先地位的AMAT公司正在發揮重要作用。
名義上,Forksheet 的柵極控制也比環繞柵極更差。這是因為柵極僅環繞晶體管溝道的三條邊,第四條邊緊貼 Forksheet 的壁。它本質上是一個側向的 finFET。與 GAA 相比,密度的提升和更差的靜電控制並非良策。
有一些解決方法:
1.稍微蝕刻 Forksheet 的壁,留出空間讓柵極材料包裹溝道的第四條邊,但會犧牲一些微縮優勢;
2.添加額外的納米片以改善靜電控制,但這會增加成本和集成複雜性。
台積電、IBM 和 IMEC 都廣泛討論了 forksheet。對於 IBM 和 IMEC 來説,這在商業上意義有限。對於台積電來説,願意進行詳細討論甚至可能預示着真正採用 forksheet。目前,在 14 個埃系列中,尚未有任何公開宣佈的節點使用 forksheet。
CFET 時間線
即便如此,forksheet 的潛在繼任者也已在討論中。CFET 已經流行了幾年:
目前的工作正朝着工業化方向發展。單個器件的實驗室演示效果很好,幻燈片也看起來很棒,但成本高昂,良率低。儘管CFET在會議上很受歡迎,但筆者認為真正大規模應用CFET仍需十年時間。英特爾的一位演講者在一次關於“超越RibbonFET”的演講中直言不諱地説:“我們可能在未來十年內能看到柵極技術。” 與銅互連和finFET一樣,邏輯核心技術往往會比預期延伸1-2個節點。
中國的FlipFET設計
中國在半導體研發方面並未放緩腳步。在所有提交的學術論文中,北京大學的FlipFET設計最受關注,該設計展示了一種新穎的圖案化方案,可以實現與CFET類似的PPA,而無需單片或順序集成的難題。
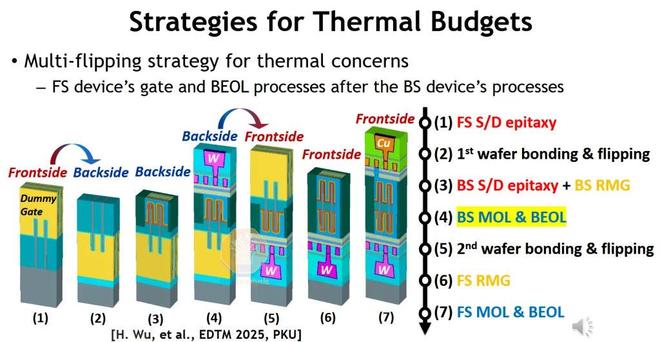
來源:北京大學
本質上,FlipFET 概念始於為頂部和底部晶體管形成鰭片或納米片,但僅在頂部晶體管進行高温源極/漏極外延,然後翻轉晶圓並暴露背面進行處理。在晶圓再次翻轉之前,對觸點和 BEOL 金屬層進行圖案化,以完成兩側的低温工藝。這種方法可以生成自對準晶體管堆疊,無需單片 CFET 必須克服的高縱橫比工藝。從兩側形成柵極還可以更輕鬆地調整頂部和底部器件之間的閾值電壓差異。
然而,FlipFET 的主要缺點是成本,它犧牲了有源晶體管的集成便利性,卻需要多個背面工藝流程,而且更容易受到晶圓翹曲和套刻誤差的影響,從而降低良率。到目前為止,該實驗室僅在不同的晶圓上製造了正面和背面晶體管,因此人們懷疑製造另一個晶體管是否會影響第一個晶體管的器件性能。晶圓翻轉後,細間距觸點和金屬的對準也是一個問題,但應該不會比其他 CFET 方案更具挑戰性。
雖然中國實驗室已經在硅片上演示了FlipFET,但他們並未止步於此。他們展示並模擬了FlipFET設計的進一步創新,例如具有自對準柵極的FlipFET、使用叉片(forksheet)並在隔離牆內嵌入電源軌的FlipFET,甚至將FlipFET概念應用於具有高縱橫比過孔的單片CFET,以實現4堆疊晶體管設計。
18A 流程詳情
最精彩的論文是英特爾的18A演示。這是首次詳細公開展示真正意義上的大批量背面電源工藝。

來源:英特爾
英特爾聲稱,相對於英特爾3代基線,18A工藝的SRAM尺寸縮小了30%。從FinFET到GAA的轉換,預計會帶來類似的一次性巨大優勢。單元圖清晰地展示了用單層寬帶取代兩層鰭片後實現的尺寸縮小:
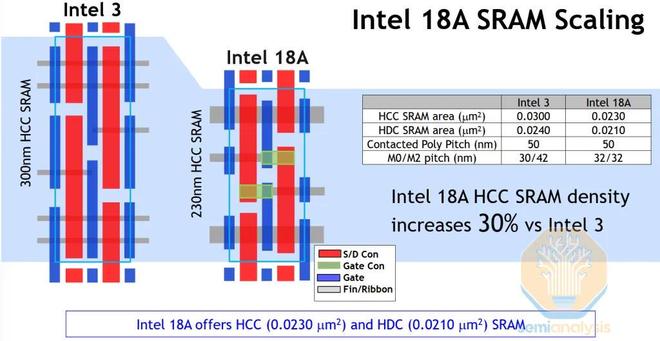
來源:英特爾
比較高密度 (HD) 單元面積,18A 與台積電 N5 和 N3E 相當,均為 0.0210 µm²。N2也應該會從 finFET 到 GAA 的轉換中獲得至少一些好處,但其聲稱的 22% SRAM 微縮(相對於 N3E)的大部分可能來自外圍,而非位單元本身。總體而言,18A 的密度可能略低於 N3P,比 N2 低近 30%。
*聲明:本文系原作者創作。文章內容系其個人觀點,我方轉載僅為分享與討論,不代表我方贊成或認同,如有異議,請聯繫後台。