顛覆通用CPU,全球最省電處理器,正式發佈_風聞
半导体行业观察-半导体行业观察官方账号-专注观察全球半导体最新资讯、技术前沿、发展趋势。24分钟前
幾十年來,我們一直用錯誤的方式構建通用CPU——這是Efficient Computer團隊的大膽宣言。為此,他們在今日正式發佈了其首款產品 E1 處理器,希望開創通用計算效率的新時代。
Efficient Computer表示。這是一款通用處理器,徹底顛覆了業界長期以來對馮·諾依曼架構的依賴。除了是 Efficient Computer 首款獨立硬件產品之外,這款芯片還值得關注的另一個點是該公司稱其為“全球最節能的通用處理器”。
 據介紹,與傳統的馮·諾依曼處理器在內存和計算核心之間傳輸數據時消耗過多能量不同,Electron E1 處理器基於 Efficient 的 Fabric 架構構建——這是一種執行通用代碼的空間數據流架構,無需進行成本高昂的分步計算。與傳統的低功耗 CPU 相比,這種方法可將能效提升高達 100 倍,使邊緣智能應用在電力和維護受限的環境中也能擁有長達數年的使用壽命。
據介紹,與傳統的馮·諾依曼處理器在內存和計算核心之間傳輸數據時消耗過多能量不同,Electron E1 處理器基於 Efficient 的 Fabric 架構構建——這是一種執行通用代碼的空間數據流架構,無需進行成本高昂的分步計算。與傳統的低功耗 CPU 相比,這種方法可將能效提升高達 100 倍,使邊緣智能應用在電力和維護受限的環境中也能擁有長達數年的使用壽命。
公司的初衷,對傳統CPU失望
Efficient Computer 直言,公司的工程師和開發者團隊對傳統馮·諾依曼處理器的侷限性深感失望,因為這些處理器在內存和計算核心之間傳輸數據時會消耗過多的能量。我們深知,要實現真正的效率,需要從根本上重新思考處理器的設計方式。
如他們所説,長期以來,我們的處理器一直受制於控制流模型,不斷地在緩存、內存和計算單元之間來回移動數據——我想大家都認同,這個過程每一步都會消耗大量的能源。事實上,目前,CPU 僅在移動數據上就消耗了過多的能源,有時甚至超過了處理數據所需的能源。傳統架構注重性能、功耗或單次操作的功耗,往往忽略了數據移動的開銷。這恰恰是功耗受限的嵌入式系統或使用小型定製電池或電池供電的系統的瓶頸所在。
據他們所説,現代計算系統面臨着一個根本性的權衡:實現極致的能效往往以犧牲通用可編程性為代價。之所以出現這樣的原因,是因為在現代架構中,數據移動(而非計算)才是能源、性能和可擴展性的主要瓶頸。因此,實現高效率意味着將大部分計算工作儘可能地放在訪問內存附近。
 如圖所示,當今的系統,包括 CPU、GPU 和其他可編程加速器,通過在處理單元 (PE) 之間使用分佈式數據存儲器來應對這一挑戰(參見 NUMA 圖)。其理念是預先確定哪些程序數據應該映射到哪個存儲器,以及如何將任務分配給每個相應存儲器附近的 PE。這種方法被廣泛稱為非均勻內存訪問 (NUMA),因為不同的存儲器對不同的處理器具有不同的(即非均勻的)訪問時間。
如圖所示,當今的系統,包括 CPU、GPU 和其他可編程加速器,通過在處理單元 (PE) 之間使用分佈式數據存儲器來應對這一挑戰(參見 NUMA 圖)。其理念是預先確定哪些程序數據應該映射到哪個存儲器,以及如何將任務分配給每個相應存儲器附近的 PE。這種方法被廣泛稱為非均勻內存訪問 (NUMA),因為不同的存儲器對不同的處理器具有不同的(即非均勻的)訪問時間。
NUMA 本身無法平衡效率和通用性。除了最簡單的程序之外,確定如何協同調度數據和任務幾乎是編譯器和系統無法解決的問題。具有不規則計算模式(例如稀疏機器學習模型)的工作負載難以分析,即使擁有完善的信息,也可能無法通過映射數據來顯著減少數據移動。另一種常見的方法是使用領域特定語言或低級 API 將這一負擔轉移給程序員。然而,這會犧牲通用性並限制可用性。
眾所周知,傳統處理器通過分支預測執行順序操作,並且在每個操作之間,處理器需要參考與處理管道相鄰的內存並執行配置更改,在Efficient Computer 的首席執行官兼聯合創始人看來:“在每個週期中,你每秒都要執行數十億次這樣的操作;這是非常浪費的。”
正因如此,他們在 Electron E1 處理器上採取了與眾不同的思路。那就是基於卡內基梅隆大學十年的研究成果,我們從零開始構建了 Fabric 架構,旨在為通用計算應用帶來顯著的能效提升。
E1 構建於名為 Fabric 的專有空間數據流架構之上,該架構消除了與指令提取、解碼和寄存器文件移動相關的開銷。據 Efficient 公司稱,這種設計在保留完整軟件可編程性和通用實用性的芯片中實現了前所未有的能效,每秒每瓦可執行高達 1 萬億次 8 位整數運算(1 TOPS/W)。
“如果你讓計算機執行 X 加 Y 的操作,那麼 95% 到 99% 的能耗都花在了指令提供、解碼、流水線重構和操作數提供上。只有 1% 到 5% 的能耗真正用於執行加法運算。”該公司創始人Lucia 説道。
數據流架構,突破的本質
Electron E1 處理器正是基於這種空間數據流架構構建的,它能夠執行通用代碼,同時無需進行成本高昂的分步計算。Efficient的目標是通過靜態調度和數據流控制來解決這個問題——不是緩衝,而是運行。它沒有緩存,沒有亂序設計,但它也不是VLIW或DSP設計。它是一款通用處理器。
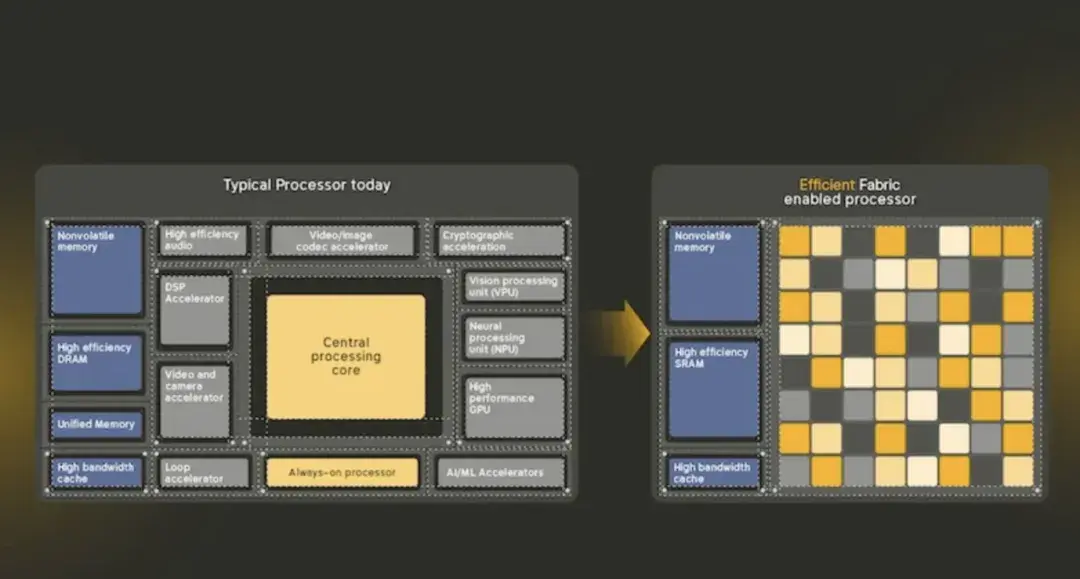 大多數人聽到“低功耗芯片”或“嵌入式CPU”時,都會想到一個按序執行的ARM Cortex-M或略高於此級別的處理器,架構上有一些亂序執行的指令,並配備足夠的片上內存或一些片外DRAM。其模型很簡單:一個小型處理器逐步獲取、解碼、排序、調度、執行,然後退出流水線指令,並根據需要將數據移入和移出內存。
大多數人聽到“低功耗芯片”或“嵌入式CPU”時,都會想到一個按序執行的ARM Cortex-M或略高於此級別的處理器,架構上有一些亂序執行的指令,並配備足夠的片上內存或一些片外DRAM。其模型很簡單:一個小型處理器逐步獲取、解碼、排序、調度、執行,然後退出流水線指令,並根據需要將數據移入和移出內存。
Efficient 的架構簡稱為“Fabric”,基於空間數據流模型。E1 的指令並非通過集中式流水線,而是將指令綁定到稱為“tile”的特定計算節點,然後讓數據在它們之間流動。當某個節點(例如乘法器)的所有操作數寄存器都填滿時,該節點才會處理其操作數。結果隨後會被傳送到下一個需要它的“tile”。它沒有程序計數器,也沒有全局調度程序。據稱,這種原生數據流執行模型可以大幅降低傳統 CPU 在數據移動過程中所浪費的能源開銷。
Electron E1 本質上是一個由小型計算塊組成的網格,每個塊都能夠執行數學、邏輯和內存訪問等基本運算。編譯器會靜態地調度每個標題,使其符合其所需,並路由數據。Efficient 編譯器會將 C++ 或 Rust 代碼轉換為數據流圖——這是這裏的關鍵點。由於能夠運行常規的 C++ 或 Rust,Efficient 稱其為通用 CPU。
當然,這本身也帶來了挑戰。如果你的程序圖對於芯片來説太大了,會發生什麼?Efficient 通過流水線重新配置解決了這個問題——編譯器將程序圖拆分成多個塊(chunks),芯片會在執行過程中動態加載新的配置。每個塊甚至都包含一個小型的近期配置緩存,因此循環和重複模式不會每次都強制完全重新加載。
Tile 之間的互連也是靜態路由且無緩衝的,在編譯時決定。由於沒有流量控制或重試邏輯,如果兩條數據路徑通常會發生衝突,編譯器必須在編譯時解決。這使得 Fabric 保持極高的能效,但也將許多責任推給了工具鏈。依賴“完美”的編譯器一直是傳統計算領域的一個問題,因此,看看這種方案將如何發揮作用將會非常有趣。
Electron E1 首款候選發佈芯片的一個意義非凡的里程碑是它支持 32 位浮點運算。許多低功耗架構僅支持整數運算,並以定點數學格式運行。首席執行官 Brandon Lucia 教授強調,32 位對於該架構的擴展能力至關重要。
至關重要的是,這不是軟件模擬的數據流;硬件被設計為數據流引擎。這是否足夠靈活以適應現實世界的嵌入式軟件,或者是否會造成太多邊緣情況,還有待觀察。從架構上講,它與傳統的 CPU 設計相去甚遠,同時仍然聲稱是“通用的”。據説,這正是其功耗優勢所在。
從物理層面,Electron E1 採用標準 BGA 封裝,並集成片上存儲器和外設接口,以最大限度地減少外部依賴。它包含 4 MB MRAM(用於非易失性代碼和數據存儲),以及 3 MB SRAM 和 128 KB 緩存。該芯片支持 QSPI、UART、SPI 從接口和 I2C 主接口各六個實例,以及 72 條 GPIO 線和一個即時時鐘。
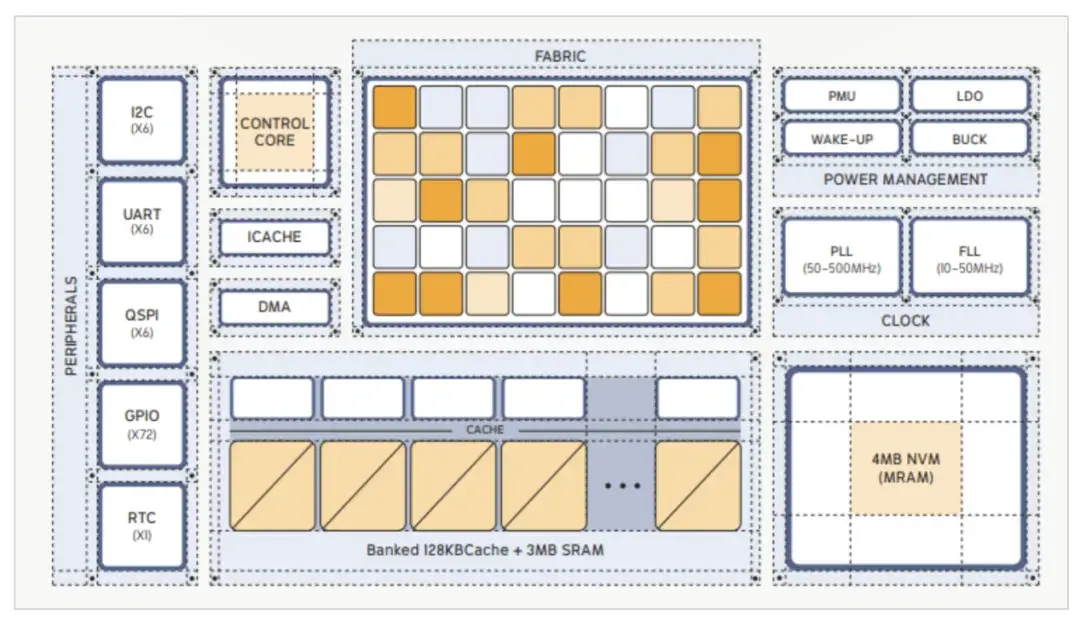 性能方面,E1 提供兩種可選工作模式:低壓模式,在 25 MHz Fabric 時鐘下可實現 6 GOPS;高壓模式,在 100 MHz 時鐘下可實現高達 24 GOPS。可編程喚醒控制器以及集成降壓和 LDO 穩壓器支持動態功耗模式,包括睡眠和深度睡眠。
性能方面,E1 提供兩種可選工作模式:低壓模式,在 25 MHz Fabric 時鐘下可實現 6 GOPS;高壓模式,在 100 MHz 時鐘下可實現高達 24 GOPS。可編程喚醒控制器以及集成降壓和 LDO 穩壓器支持動態功耗模式,包括睡眠和深度睡眠。
該芯片的活動標量 RISC-V 核心可以進入斷電狀態,而 Fabric 則繼續執行。
E1 採用 1.8 V 電源供電,內部邏輯電壓範圍為 0.55 V 至 0.8V,額定工業温度範圍為 -40°C 至 125°C。
Electron E1 還支持全棧可編程性,將常規代碼編譯成數據流圖,並放置在整個 Fabric 架構中。在此過程中,系統保持確定性和靜態調度,編譯後的程序可持久運行長達 1 億次。
軟件棧,背後的另一個核心
除了 E1 之外,Efficient 還發布了其編譯器工具鏈 effcc 的首個公開版本,該工具鏈將獨特的硬件抽象化,並採用標準開發接口。該編譯器基於 LLVM 和 MLIR 構建,可接受標準 C 代碼,並只需極少的改動即可集成到現有的開發者工作流程中。開發者只需指向新的編譯器二進制文件,即可使用 Make 和 CMake 等常用構建工具以及 Visual Studio Code 等編輯器。
這樣可以保持與工程師們已經熟悉的調試工具和工作流程的兼容性。正如 Lucia 所説:“你只需使用 effcc,它就能像 Clang 一樣在前端運行……如果你使用 VS Code、Make 或 CMake,你只需讓它知道我們的編譯器在哪裏,然後一切就都正常了。”
編譯器的前端使用 Clang,而在中端,Efficient 將輸入轉換為針對 Fabric 定製的中間表示。高級優化例程(包括基於 AI 的調度框架,即模塊化優化框架 (MOF))會分析代碼結構並將其高效地映射到空間網格上。這包括將指令輸出自動路由到下游區塊,以及優化數據流路徑,以最大限度地降低延遲和功耗。
藉助這些工具,開發人員可以在基於 Web 的 Playground 上模擬執行,其中包括指令在 Fabric 中傳播的交互式可視化效果。該公司強調“兩分鐘即可體驗 Hello World”的開發體驗,幾乎消除了新平台帶來的學習曲線。
由此可以看到。Electron E1 使用標準工具;編譯器前端基於 Clang,並支持前面提到的 C++ 和 Rust。他們還表示支持 PyTorch、TensorFlow 和 JAX 等機器學習框架,儘管啓用這些框架所需的手動干預程度尚不清楚。
此前,他們的工具鏈effcc之前只是一個沙盒編譯器遊樂場。隨着 E1 的發佈,它現在可以完全下載,這意味着開發人員可以將其直接集成到他們的工作流程中,並瞄準真正的芯片。EFCC 採用常規代碼,並將其降低到 Fabric 的空間數據流模型中,處理圖形分解、操作映射到圖塊、配置生成和流水線管理。在傳統的編譯器中,這些決策是在運行時動態進行的;而在這裏,它們在編譯時靜態解析。這種編譯時解析是效率的來源,但這也意味着編譯器必須非常智能。
Efficient 承諾開發人員無需學習新的思維模型即可上手——只需編寫 C++ 代碼,編譯器就會處理映射。我最大的疑問是,如果某些代碼無法清晰地映射,或者編譯器遇到特殊情況,會發生什麼?開發人員能否洞察到問題所在?或者,我的想法更像高性能芯片程序員,他們擁有性能工具。像 E1 這樣的新範式能否被採用,很可能取決於開發人員開始在實際環境中進行壓力測試時,該工具的穩定性。
一些思考
Efficient 表示,E1 最適合嵌入式和邊緣 AI 工作負載,這些工作負載通常受到當前 CPU 和窄帶加速器的限制。Efficient 提供加速器級的能效和 CPU 級的可編程性,將 E1 定位於通用計算和 AI 推理專用芯片之間。
獨立加速器隔離了機器學習管道的密集矩陣乘法核心,而 E1 可以在同一芯片上處理上游信號處理、傳感器融合和下游分析或控制邏輯。
Efficient 已開始向早期試用客户提供 E1 樣品,並正在與工業和航空航天垂直領域的合作伙伴合作。即將推出的 Photon P1 是 E1 的高端繼任者,它將擴展該架構的適用性,使其能夠應用於更大規模的邊緣計算場景,甚至可能擴展到低端數據中心層。正如 Lucia 所説:“我們的架構兼具可擴展性和高效性,這才是真正的根本。”
“我對公司的願景是,我們現在從 E1 的嵌入式領域開始,然後一路擴展到邊緣、雲端,最終擴展到數據中心。” Lucia強調。
然而,密歇根大學計算機科學與工程教授託德·奧斯汀 (Todd Austin)表示,E1 等芯片是高效架構的一個很好的例子,因為它們最大限度地減少了硅片中用於非純計算的部分,例如獲取指令、臨時存儲數據以及檢查網絡路由是否正在使用。
伊利諾伊大學香檳分校計算機架構師拉凱什·庫馬爾(Rakesh Kumar)也表示, Lucia 的團隊“正在開展大量巧妙的研究,以便為通用計算提供極低的功耗”。他預測,這家初創公司面臨的挑戰將是經濟效益。“超低功耗公司一直舉步維艱,因為低功耗、價格低廉的微控制器市場競爭激烈。關鍵挑戰在於發現新的功能”,並讓客户為此買單。
讓我們回到性能,特別是能效方面。Efficient 聲稱 Electron E1 的能效比市場領先的嵌入式 ARM CPU(具體指的是 Cortex M33、M85 和 A5 級內核)高出 10 到 100 倍。Efficient 的核心指標是“每焦耳操作次數”,如果你的設計目標是電池續航,那麼這個指標就很合理。問題就在於:每單位能量能做多少有用的功?
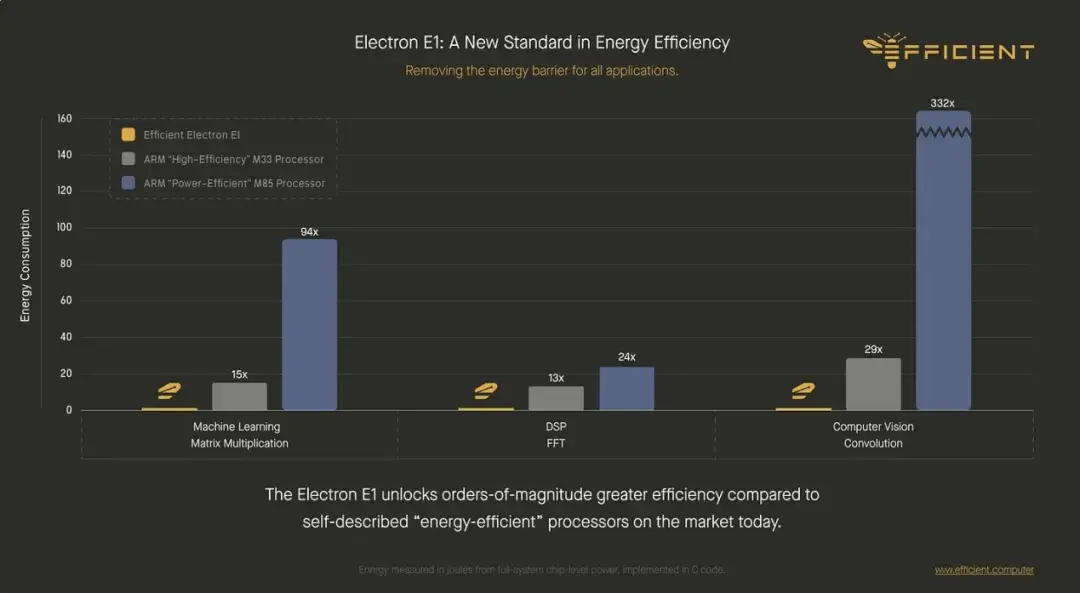 然而,這位首席執行官也強調“每瓦 TOPS”是他們的關鍵指標。坦白説,每瓦 TOPS 讓我有點擔心。每瓦 TOPS 通常是一個 AI 加速器指標,而不是通用 CPU 的指標。它也依賴於精度,雖然 E1 支持 FP32,但將通用 CPU 的 TOPS 進行比較,開始落入我們通常在機器學習芯片而非嵌入式芯片中看到的那種性能營銷的陷阱。此外,傳統 CPU 可能擁有大型矢量引擎,這掩蓋了真正的串行性能。我想補充一點,大多數嵌入式基準測試都非常傳統,例如 DMIPS 或 Coremark,許多嵌入式處理器甚至沒有列出 TOPS。我非常期待看到 SPEC2006 在這裏運行,因為我知道很多 Arm 的嵌入式客户仍然依賴他們的評估工具包中的這些數據。
然而,這位首席執行官也強調“每瓦 TOPS”是他們的關鍵指標。坦白説,每瓦 TOPS 讓我有點擔心。每瓦 TOPS 通常是一個 AI 加速器指標,而不是通用 CPU 的指標。它也依賴於精度,雖然 E1 支持 FP32,但將通用 CPU 的 TOPS 進行比較,開始落入我們通常在機器學習芯片而非嵌入式芯片中看到的那種性能營銷的陷阱。此外,傳統 CPU 可能擁有大型矢量引擎,這掩蓋了真正的串行性能。我想補充一點,大多數嵌入式基準測試都非常傳統,例如 DMIPS 或 Coremark,許多嵌入式處理器甚至沒有列出 TOPS。我非常期待看到 SPEC2006 在這裏運行,因為我知道很多 Arm 的嵌入式客户仍然依賴他們的評估工具包中的這些數據。
儘管如此,考慮到傳統 CPU 在數據傳輸過程中的功耗,10 到 100 倍的能效提升並非不可能。值得稱讚的是,Efficient 已經在各種活動中展示了芯片,向客户展示了內部基準測試,並且正準備向市場推出開發套件。但在我們看到完整的工作負載和獨立驗證之前,很難知道這種優勢在各種用例中能持續多久。嵌入式開發人員也關心內存佔用、中斷延遲、重新配置時間、I/O 爭用和軟件兼容性。這些因素可能與 Efficient 的效率聲明同樣重要。
展望未來,Electron E1 只是 Efficient 路線圖的第一步。他們正在規劃一個完整的產品系列,包括第二代 E2 和更強大的 Photon P1。該計劃旨在提升架構性能,擴展工作負載支持,並提供獨立的 SOC 和可授權 IP——這是初創公司慣用的策略。Efficient 目前的重點是能源比峯值吞吐量更重要的系統:航空航天、國防、工業傳感、可穿戴設備,甚至可能是太空系統。任何計算都需要在有限的功耗下長時間運行,並且維護成本極低。
另外一個值得注意的點,他們現在已經從研究跨入了產品階段。現在 E1 已經面世,至少可以回答一些更棘手的問題,比如世界是否準備好採用這種新的執行模式,尤其是在嵌入式市場,可靠性和可預測性比新穎性更重要。
編譯器的成熟度、調試工具、供應鏈承諾以及產量提升——所有這些對於 Efficient 來説都還有待解決。嵌入式領域對零部件供應的持續需求已超過十年,這對於初創公司來説是一個殘酷的市場。我們都聽説過,現代飛機依賴於 80 年代和 90 年代的處理器,而這些處理器現在已經停產,迫使它們依賴於庫存,因為這些硬件已經停產。
但如果它真的有效,並且能夠擴展,Efficient 或許已經實現了我們很久沒見過的奇蹟:打造了一款並非僅僅從上一代 CPU 演化而來的通用 CPU。這無疑是一個有趣的想法,我希望我們能盡更深入地瞭解這個處理器。