從IMO「搶跑」到AI「幻覺」:技術狂歡下的認知陷阱_風聞
深眸财经-洞察商业逻辑,深研行业趋势。22分钟前

作者:高藤
原創:深眸財經(chutou0325)
28日晚,許多人都在關注的第 66 屆國際數學奧林匹克競賽(IMO)公佈了比賽結果。
中國隊不出所料地奪得頭籌,斬獲6 枚金牌。其中更是有兩位同學獲得滿分,以231分的團隊總成績碾壓全場。
對於這一已經預料到的結果,網上反應比較平淡,引發熱議的反倒是另一個賽道的OpenAI。
01 OpenAI“搶跑”背後的幻像
在用於評估AI大模型在數學競賽表現的MathArena.ai平台上,對當前最頂尖的AI公開大模型進行了測試。

OpenAI的o3與o4-mini、谷歌的Gemini 2.5、馬斯克家的Grok-4以及國產DeepSeek-R1等頂流AI模型全部出戰。
遺憾的是,AI大模型在這屆IMO上全軍覆沒。
在這場比拼中,得分最高的是谷歌Gemini 2.5拿到13分,也就是31%的分數,連銅牌都夠不上。
就在大家紛紛認為這就是目前AI的上限時。
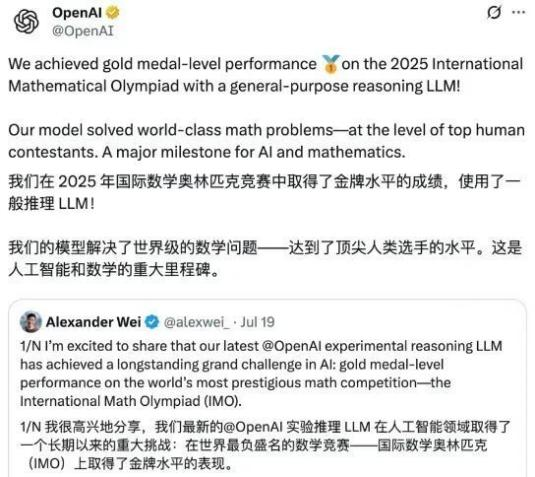
OpenAI團隊帶着最新開發的通用推理模型,拋出了一顆重磅炸彈:
在與人類完全相同的考試條件下作答,最終解出5道題,共獲得35分,達到IMO金牌分數線,成功拿到了金牌。
但事實真的是這樣嗎?
首先引發大家爭吵的就是消息發佈的時間。
按照IMO的規定,所有成績都應該在IMO閉幕的一週後再發布。
結果當地時間19日下午5點43分,閉幕式一結束,5點50分OpenAI的官方就發佈了“AI剛好壓過金牌線”的消息。
七分鐘之差,既讓OpenAI鑽了規定的空子,還先其他參賽選手一步,在網絡上掀起了軒然大波。
這一行為讓不少網友為其他真實競爭對手打抱不平,畢竟搶跑的行為,本身就是對競爭對手的不尊重。
其次就是,金牌是誰認證的?
雖然官方一直説的都是“OpenAI壓上了金牌及格線”,但不少媒體為了省事,直接寫成“AI奪得金牌”。
此外,OpenAI並未接收到任何參加IMO的邀請,更不用説究竟是誰給AI評出的35分好成績。
這就相當於自己在家裏做了一套高考真題,對照答案評分後,得出了一個我是高考狀元,能上清華的結果。
國外有OpenAI以“奪冠”炒作,國內也有AI寫高考作文吸睛。

今年高考語文考試一結束,各大AI公司迫不及待地讓自己的AI助手開始考試。
豆包、騰訊元寶、天工……一共16款產品,都在網上發佈了自己寫的作文。
面對AI寫出來的作文,不少人站出來説“我覺得AI比我強”。
每每在這種測評的關鍵時刻,AI都會以出色表現“出圈”。
但到了生活中,AI假大空的想法、胡亂編造的數據、古今中外虛實大亂燉的文章模板,甚至連AI造假的事也層出不窮。
就算這樣,AI的使用率仍在不斷增長。
從學生用AI代寫論文,到上班白領依賴AI生成報告,再到媒體行業機器人撰稿佔比突破40%,人類正經歷一場前所未有的“思考能力危機”。
02 思維惰性引發認知陷阱
AI寫高考作文、壓線奪冠,每一次“出圈”都像是精心策劃。
拋開網絡上營銷號對AI的呼聲,值得讓我們思考的並不是AI會不會代替人類,而是我們總是習慣把思考的機會全部甩給AI,自己坐享其成。
以Cision發佈的《2025全球媒體調查報告》為例,通過對19個國家3,126名記者的調研發現,53%的記者已在工作中使用生成式AI工具。
在其他使用AI進行輔助的領域中,教育行業首當其衝:
國內的某高校調查顯示,使用AI輔助學習的學生中,僅28%能獨立完成複雜邏輯推導,較五年前下降45%。
神經可塑性研究表明,長期依賴AI會導致大腦神經網絡重構,前額葉的決策區域活躍度下降20%,視覺皮層的信息處理區域卻變得異常活躍。
換句話説,使用AI大量處理認知工作,會讓工作者參與創新所需的深層分析的過程大幅減少,思維出現"斷片"現象,產生認知依賴症。
還會縮小人腦思考和機器思考之間的差距,弱化原創觀點和創造性方法所帶來的價值。
除此之外,過度相信AI的建議,可能會失去辨別能力,導致錯誤信息風險增加。
AI之所以能夠高效產出內容,就是因為它直接搬運或者套用海量數據庫中的表面規律,但卻不會主動核實事實。
2023 年,紐約市協助政府服務的AI 聊天機器人,建議企業主扣除員工消費來獲利,但真實的法律卻明確規定了老闆不能扣取員工的小費。
再比如,政策明確規定企業必須接受現金,不得歧視沒有銀行賬户的客户。但是AI 卻説“餐廳可以不提供現金付款選擇”。
在面對具有信息變量的情況下,尤其是在涉及多變量分析時,AI就可能生成看似專業但邏輯不自洽的內容。
如果不仔細甄別,這種“幻覺”現象不僅會誤導用户,增加錯誤信息的風險,還可能引發信任危機。
所以説,AI使用率的不斷提高已成必然,但我們該做的不僅是改進算法,讓人工智能更好的服務人類,而是如何才能在享受便利和堅守認知之間找到平衡。
03 以AI治理AI
首先,利用AI自身的算法能力,來監管、優化和安全應用AI技術。
我們常見的AI主要分為,基於模板的自動化生成,和基於深度學習技術的自動化生成,這兩種類型。
而訓練AI的原材料就是數據。
以Open AI的第一個大模型GPT1為例,它有1.17億個參數,到了GPT2,有15億個,而GPT3則增長到了1750億個,GPT4的參數更是達到令人震驚的1.8萬億個。
巨大的參數數量決定了AI模型如何對輸入數據做出反應,從而決定模型的行為。
將AI的行為舉止具象化,可以增進用户對AI技術的理解,識別其潛在的偏差,有助於平衡用户對AI的信任度和依賴度。
其次,還可以利用AI技術研究用户的心理機制,成果可以作為改進AI模式的參考,避免引發引發過度依賴。
AI技術通過自然語言處理和情感計算,能夠即時分析用户的語言、語音和行為模式,識別潛在的心理健康風險。
例如養老院使用機器人,通過聲波震顫識別老人的孤獨指數,輔助早期篩查抑鬱傾向。
在過度依賴AI的防控上,同樣可以運用它的算法,通過分析用户的使用頻次、情感表現、面部表情等,來提供特定的“AI戒斷”方法,降低用户的依賴程度。
結語:AI的發展已成必然,頻頻“出圈”的背後不再只是算法的精進,還有認知主導權的易主。如何在技術狂歡與認知危機交織的時代始終保持警惕,避免淪為算法的附庸,才是人類駕馭科技的關鍵。