太業餘?有科技公司CEO怒懟王興興,建議他別聊AI了,你們怎麼看?_風聞
哲就-32分钟前
8月9日,宇樹科技創始人兼CEO王興興在北京舉行的世界機器人大會上,談及當前智能機器人暫時還沒得到大規模應用的技術障礙時表示,最大的挑戰是模型。“現在對具身智能和機器人來説,AI模型完全不夠用,這也是限制當前人形機器人大規模應用最大的卡點。”此外,王興興對目前機器人公司選擇的常用技術路線VLA模型架構持懷疑態度。
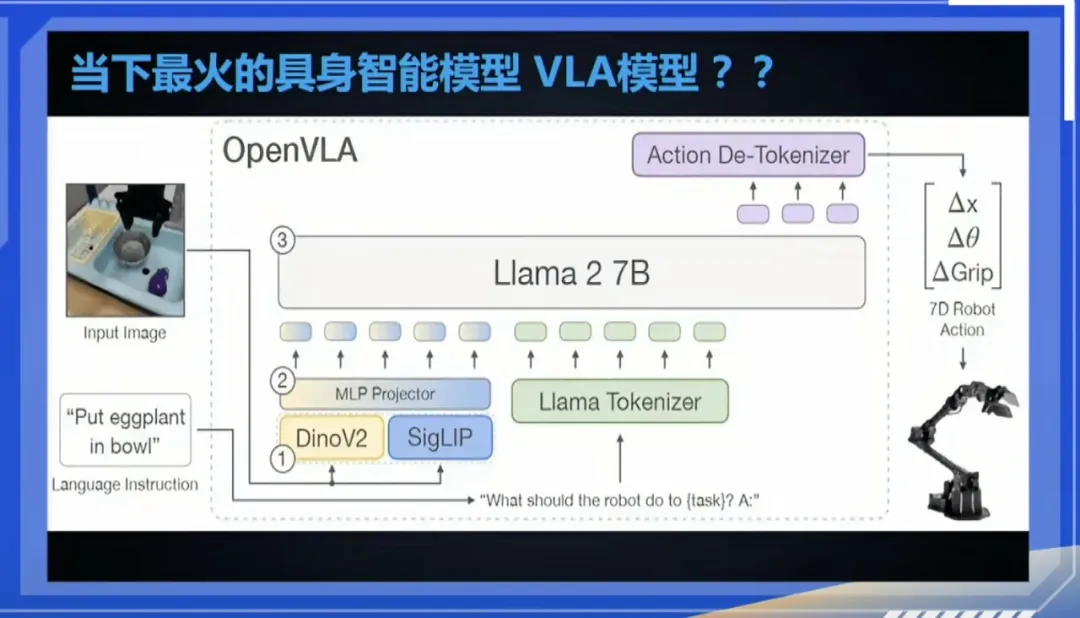
VLA模型指的是Vision-Language-Action Model(視覺-語言-動作模型),可以把它理解為——讓機器“看得懂、聽得懂,並且能動起來”的一種AI模型,強調像人一樣,從感知環境到自主決策並採取一定的行動。
王興興認為,對於VLA模型,目前在真實世界交互中,數據採集的質量和數量都不足,即便在VLA模型基礎上加入Reinforcement Learning(強化學習訓練),仍不夠用,模型本身還需要進一步升級和優化。
“目前機器人大模型類似於處在ChatGPT出來前的一到三年。”王興興稱。

什麼時候才能達到機器人GPT時刻?
王興興認為,如果有一天,我們帶一台機器人到一個它此前從未去過的環境,隨便給它一個指令,譬如“把這瓶水遞給某位觀眾”或“幫忙整理一下這個房間”,它就能順暢、自主地完成任務。那時就接近機器人的“GPT時刻”了。
今年5月,谷歌在I/O開發者大會上正式發佈了新的世界模型Veo 3,這是其首款能夠同步生成音效(包括環境音與對話)的AI視頻生成模型。
王興興認為,谷歌這條視頻生成路線技術的收斂速度和成功概率可能會比VLA模型更高,但仍然面臨還有很多挑戰。其中一個主要問題是,視頻生成模型過於關注畫質,導致GPU消耗非常大。
另外,王興興指出,目前還面臨的一個大問題是,如果要進一步提升機器人模仿學習的能力,必須解決Scaling
law,而這一點目前行業做得並不好。“最簡單的例子是,當我訓練機器人執行一個新動作,比如學一支新舞或完成一項新任務時,往往需要從零開始訓練,這非常低效。理想情況下,新的訓練應該基於已有訓練成果,讓訓練速度越來越快,學習新技能的效果越來越好。”
王興興指出,這是一個非常值得深入研究的方向,Scaling law在語言模型上的成功已經得到驗證,但在機器的運動控制上,大家做的還只是剛剛開始,他建議可以關注這方面的研究。
王興興表示,在未來兩到五年,除了更低成本、更高壽命的硬件之外,機器人的技術核心仍將是端到端的具身智能AI模型。
除了發表演講,王興興在現場還接受了包括央視財經在內的多家媒體採訪。
問:在機器人研發層面,還有哪些技術有待突破?
**王興興:**今天我還看到一種説法,馬斯克認為未來基本上每個人都不用寫代碼,AI會幫助生成代碼。確實,目前AI在寫代碼這個領域的技術進步非常快,這也是各家公司非常關注的。簡單的程序或簡單代碼,AI的成功率確實非常高,但如果代碼非常複雜,那成功率肯定是會下降不少的,這個成功率指的是一遍就成的成功率。
所以我覺得,最大的技術點還是要把具身智能AI模型做得更好。對行業來説,目前機器人的AI能力還不夠用。如果哪一天,在這個場館裏,每台人形機器人都能隨意地走來走去,人能隨便跟它説點什麼,能讓它幫忙乾點事的時候,才算達到了一個比較好的臨界點。這是我們的目標,也是當下社會期待機器人能實現的點。
機器人領域,模型能力優先於數據能力問:目前機器人落地應用的技術難點有哪些?如何解決機器人通用泛化性以及自主決策能力不足問題?
**王興興:**目前機器人的硬件能力是夠用的,當然不足夠好,想要更大規模、更低成本、更高可靠性,硬件肯定要繼續完善。最大的難點還是目前整個具身智能AI模型在本質上還沒有達到一個階段性突破的臨界點。舉個例子,ChatGPT時刻在具身智能領域還沒有發生,AI很多情況下是階梯式的進步。今天可能大家感覺不到,但突然有個階段性的進步,這是非常容易發生的。
另外,語言模型領域是純數據驅動的,有足夠多、足夠好的數據,語言模型的性能就會上升得非常快,但是在機器人領域,這個點反而是很大的一個問題。無論用哪種方法採集的數據,真正放到機器人上,跟實物機器人的偏差還是非常大。
某種意義上,哪怕採集了大量數據,把機器人的數據訓練出來部署到實物機器人上,會發現沒辦法很好地對齊。所以在機器人領域,尤其對AI模型本身能力的要求是需要定位到更高級別。簡單説,我們希望達到什麼效果呢?就是隻要很少的數據就能把機器人訓練出來,成功率很高而且泛化能力很好。我們希望有這樣的模型出來,然後再用數據去訓練。而不是現在可能模型都沒有,又搞一大堆數據去訓練,這個效果其實不是特別理想。
---------------------
目前,國內多傢俱身智能和機器人公司都在佈局VLA模型、AI數據採集等技術方向。
對於王興興的言論,很多行業人士並不完全同意。其中,AI世界模型技術公司極佳科技創始人、CEO黃冠發朋友圈表示:“哭笑不得,關於數據、VLA、世界模型的觀點也太業餘了,建議王興興還是好好做下肢硬件和運控,不要談AI了!”
鏈接閲讀:
王興興「炸裂」發言:對VLA持懷疑態度,數據並非最關鍵問題
今日(2025年8月9日),宇樹科技創始人兼CEO王興興在「2025世界機器人大會」的論壇上,發表了最新演講。以下是RoboX整理出的部分關鍵演講內容:

王興興表示,今年上半年,整個機器人行業非常火爆,再加上政策的支持,相關整機廠商及零部件廠商,平均每家企業至少有將近50%-100%的增長,這意味着需求端拉動了整個行業的發展。
在海外,特斯拉今年大概他們會發布他們第三代的特斯拉的人體機器人,同時包括英偉達、蘋果,META等頭部企業都在持續推動機器人領域的發展。
在此背景下,王興興分享了幾個個人觀點:
1、關於本體的誤區
之所以機器人還沒有大規模應用,並非因為硬件不夠好或者成本比較高。他認為其實從技術層面或者AI角度來説,目前硬件是完全夠用的,這也包括人形機器人和靈巧手。
關鍵問題在於量產,相關的工程問題非常多。

2**、具身AI完全不夠用**
與硬件相比,更大的挑戰,還是具身智能的AI完全不夠用,這也是限制機器人尤其人形進行大規模應用的最大問題。
王興興認為,目前的智能體AI應用,感覺類似於ChatGPT出來前的1-3年左右。目前業界已經發現了類似的方向以及技術路線,但是還沒人把它做出來。
而機器人的臨界點應當達到什麼程度?他表示,如果哪一天我們帶一個人形機器人來到完全陌生的會場,和它説,幫忙把這瓶水帶給某個觀眾,它可以流暢地完成;或者説「把這個房間整理一下」,它也能自己完成,那就差不多達到了臨界點。
“如果快的話,未來的1-3年內還是很有可能實現的。最慢的話估計3-5年也可以實現,但是現在確實還沒有達到這個效果。”

3**、關鍵問題:數據還是模型?**
之所以智能機器人還沒達到應有水平,到底是模型的問題,還是數據的問題?王興興給出了獨特答案:
“目前全球範圍內,大家對於機器人數據問題的關注度,都有點太高了。現在最大的問題其實反而是模型。”
他認為,目前具身智能和機器人的模型架構不夠好,也不夠統一。
“在大語言模型領域,當有了足夠多的好數據時,就能把模型訓練得越來越好。但是在具身智能領域,會發現在很多情況下,數據採了卻用不起來。大家對模型的關注目前是相對有點少,反而對數據關注有點太高了。”
4、對VLA模型持懷疑態度
“VLA是一個相對傻瓜式的架構,我個人對它還是抱一個比較懷疑的態度。”
王興興表示,VLA模型對於真實世界的交互,數據質量是不太夠用的。有個簡單的想法,是在VLA模型上加RL訓練,但綜合宇樹長期的嘗試來看,VLA+RL還是不夠的,模型架構還得再升級和優化。
5**、宇樹的做法**
去年,OpenAI發佈了視頻生成模型以後,行業內產生了一個想法——如果生成一個「整理房間」的視頻,是不是能讓視頻生成模型直接去驅動一個機器人去執行?
去年,宇樹就做了這個事情——**利用預訓練的機器人動作視頻,去控制機器人仿照執行。**他指出,目前谷歌的全新一代的視頻生成模型,也是一個視頻驅動的世界模型,同樣想實現這樣的效果。
“我覺得這個路線的方向,可能比VLA模型的收斂概率還大。但是我沒有驗證不敢打包票,目前該方法的問題就是,視頻生成模型太考驗視頻生成質量了,導致對GPU的消耗有點大。但是對機器人來説,如果遇到並不需要很高精度的視頻生成質量,還是可行的。”

6、機器人的Scaling law才剛開始
王興興指出,目前宇樹等品牌的機器人,在跳舞、格鬥等動作上,實現的效果還不錯。但是要想進一步整體提升能力,還面臨着一個很大的問題。
“目前,機器人領域的Scaling law,大家做得非常不好。舉個最簡單例子,如果我有一個新的舞蹈要去訓練,那麼每次加入新的動作,都要重新訓練,而是從頭開始訓練,這是非常不好的。我們是希望我每做一個新訓練的時候,是可以在之前的訓練基礎上去做AI訓練的。”
他認為,做AI訓練的時候,理論上應該訓練速度越來越快,學習新技能的效果越來越好。但是全行業內目前還沒人能做出來,這是非常值得做的一個方向。
因為這在語言模型上已得到過充分驗證,但是在機器人的運動控制上面,大家才剛剛開始。
“在未來2-5年,最重要的還是端到端的具身智能AI模型,模型本身是非常最重要的。”
7**、硬件工程優化**
更低成本、更高壽命的硬件,哪怕對於已經發展100多年的汽車行業來説,如果要做一輛很好的汽車出來,工程量還是非常大的。
“對機器人行業來説,未來可能每年要生產幾百萬、幾千萬甚至幾億台的人形機器人。如果要大批量生產製造出來,它的工程量的挑戰還是非常嚇人的一件事情。”
8**、算力部署的侷限性**
目前,在人形機器人上,或者在移動機器人本體上,沒辦法直接部署很大規模的算力。這是因為它的尺寸和電池都有限,它部署的算力功耗也是有限制的。
王興興稱,在人形機上,最多隻能部署峯值功耗約為100瓦的算力,且平時工作時算力只有幾個手機的水平。但是,未來的機器人對於大規模算力的需求肯定是毋庸置疑的,而且可能會是分佈式的算力。
因為,大家都希望機器人工作的通信延遲比較低。此時如果數據中心或者算力中心在異地,延遲實在是太大了。所以他認為,未來如果一座工廠裏有100個機器人,也可以配備集羣的分佈式服務器,這樣其安全性和通訊延時是可以接受的。
再比如,如果一個小區中每家每户都有機器人的時候,該小區也可以有分佈式的集羣。並且如果有一個新客户想買一台人形機器人的時候,他不需要給這部分算力的建設花錢,成本也會更低很多。
“我覺得分佈式集羣是未來在機器人領域非常重要的構成。”王興興説道。

9、全球共創的重要性
他認為,機器人領域是一個全球共創的過程,包括中國、美國的很多的大企業,大家在過去的很多年和當下,都做了很多貢獻,也希望共同推動行業進步。
“在AI領域,沒有一家大公司能保證只要有足夠的人、有足夠的資源,就能永遠保持在AI領域領先。OpenAI和DeepSeek已經證明了AI的創新,永遠伴隨着一些隨機性。所以很多情況下,需要每家公司或者每家高校都做出很多貢獻,進行全球共創。”
