劍指HBM,華為AI新技術UCM來了!_風聞
半导体产业纵横-半导体产业纵横官方账号-探索IC产业无限可能。1小时前

本文由半導體產業縱橫(ID:ICVIEWS)綜合
UCM不僅着眼當下解決當前推理加速問題,還面向未來設計。
今日,華為在“2025金融AI推理應用落地與發展論壇”上發佈其AI推理創新技術UCM(推理記憶數據管理器),通過創新架構設計降低對高帶寬內存(HBM)的依賴,提升國產大模型推理性能,推動AI產業自主化進程。
華為公司副總裁、數據存儲產品線總裁周躍峯表示,該技術以KV Cache為中心,融合了多類型緩存加速算法工具,對推理過程中產生的KV Cache記憶數據進行分級管理,旨在擴大推理上下文窗口,實現高吞吐、低時延的推理體驗,同時降低每Token的推理成本。
據介紹,推理體驗直接關係到用户與AI交互時的感受,包括回答問題的時延、答案的準確度以及複雜上下文的推理能力等方面。當前,隨着AI產業已從“追求模型能力的極限”轉向“追求推理體驗的最優化”,推理體驗直接關聯用户滿意度、商業可行性等,成為衡量模型價值的黃金標尺。
但在 AI 行業化落地的過程中,推理環節主要面臨:推不動、推得慢、推得貴三大挑戰。比如,將一篇較長的文章放入推理系統時,系統可能看了前面忘了後面,看了後面又忘了前面,這是因為推理窗口相對較小,難以處理長文本。同時,由於基礎設施投資的差距,目前中國互聯網大模型的首 Token 時延普遍慢於美國互聯網頭部企業,而且在每秒或一定時間內,中國頭部互聯網提供的推理 Token 數也遠少於美國頭部互聯網。因此,改進推理系統的效率和體驗成了重要課題。
UCM 作為華為與銀聯聯合創新推出的解決方案,相對於過去試圖通過增加 HBM 和內存來提升 AI 推理效率和性能的方式,是一次有效的突破。就像人類的思考能力與記憶能力密切相關,既需要記得多,也需要記得快,AI 推理系統的記憶同樣關鍵。
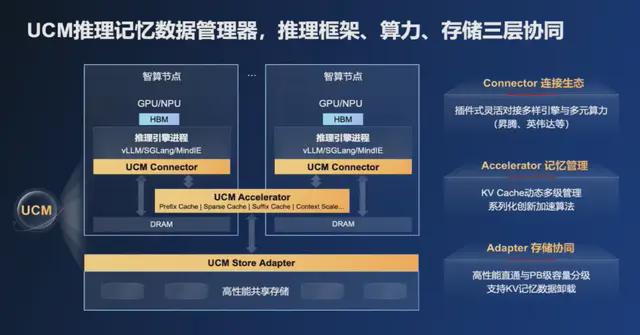
AI 推理系統的記憶主要分為三部分:高性能緩存 HBM、內存 DRAM,這兩部分基本都在計算服務器中;還有一部分是過去未被充分利用的專業共享存儲。UCM 推理記憶數據管理器通過一系列算法,將推理過程中不同延時要求的數據放在不同的記憶體中。即時記憶數據放在 HBM 中,短期記憶數據放在 DRAM 中,長期記憶數據與外部知識放在SSD中,以此極大提升整個系統的效率和 AI 推理性能。
作為軟件系統,UCM 主要由三部分構成。頂層是與業界流行推理框架對接的連接器,能連接華為的 Mind IE等推理框架,實現良好協同。中間部分是運行在計算服務器中的加速程序,負責對緩存記憶數據進行分級緩存管理,是核心部分。最後一部分是與專業共享存儲相結合的協同器,它能提升專業存儲的直通效率並降低時延,讓三級存儲協同工作。
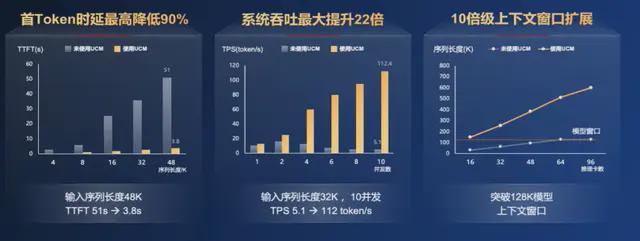
經大量測試和銀聯實際案例印證,該算法能使首 Token 時延最高降低 90%,系統吞吐率最大提升 22 倍,同時上下文推理窗口可擴展 10 倍及以上,極大提升了推理系統的效能。
華為計劃於2025年9月正式開源UCM,屆時將在魔擎社區首發,後續逐步貢獻給業界主流推理引擎社區,並共享給業內所有Share Everything (共享架構)存儲廠商和生態夥伴。
*聲明:本文系原作者創作。文章內容系其個人觀點,我方轉載僅為分享與討論,不代表我方贊成或認同,如有異議,請聯繫後台。