信AI排行榜,不如信它們的遊戲排位分數_風聞
差评XPIN-差评官方账号-用知识和观点Debug the world!26分钟前
文章開頭問大家一個問題,如果想知道最近哪個 AI 牛,你會怎麼查?
直接上 AI 競技場,XX 排行榜?
沒錯,這些是有一定參考能力。
但看完最近大模型圈的電競比賽後,我覺得現在多一種更靠譜的辦法了,那就是看——
 AI****的遊戲排位天梯。
AI****的遊戲排位天梯。
前幾天,Google 旗下 Kaggle 舉辦了首屆 AI 國際象棋比賽,一共有 8 名選手參加,個個都是狠角色。
什麼 Gemini 2.5 Pro、Grok 4、DeepSeek R1。。
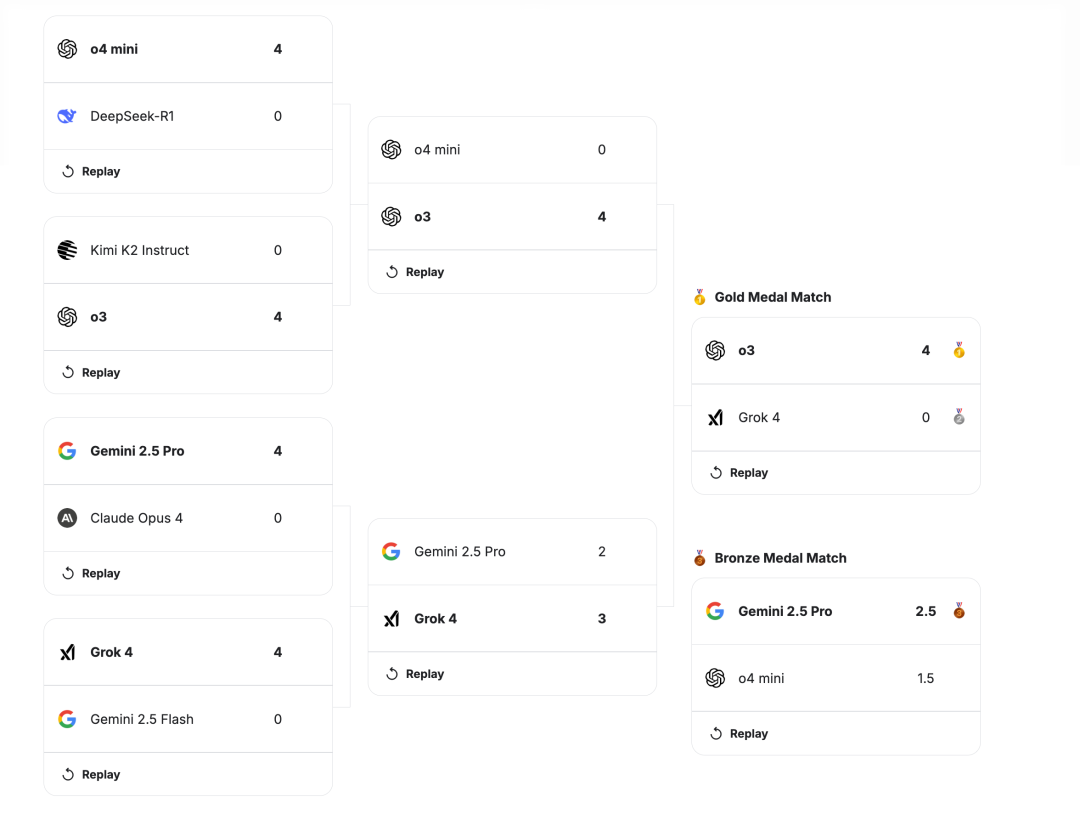
比賽規則很簡單。每場對決為“ 四局兩勝制 ”,誰先拿到2分(勝1分,平0.5分)誰晉級。如果打成 2-2 平,將加賽一場絕殺局。
比賽過程中,我們還能看到這些職業選手的思考過程,看看他們如何應對對方的進攻,看待自己的失誤。
結果説起來你可能不信,在眾多排行榜都保持第一的 Gemini,只拿下季軍。
 而 GPT-o3,則以一把沒輸的絕對統治力,奪得冠軍。
而 GPT-o3,則以一把沒輸的絕對統治力,奪得冠軍。
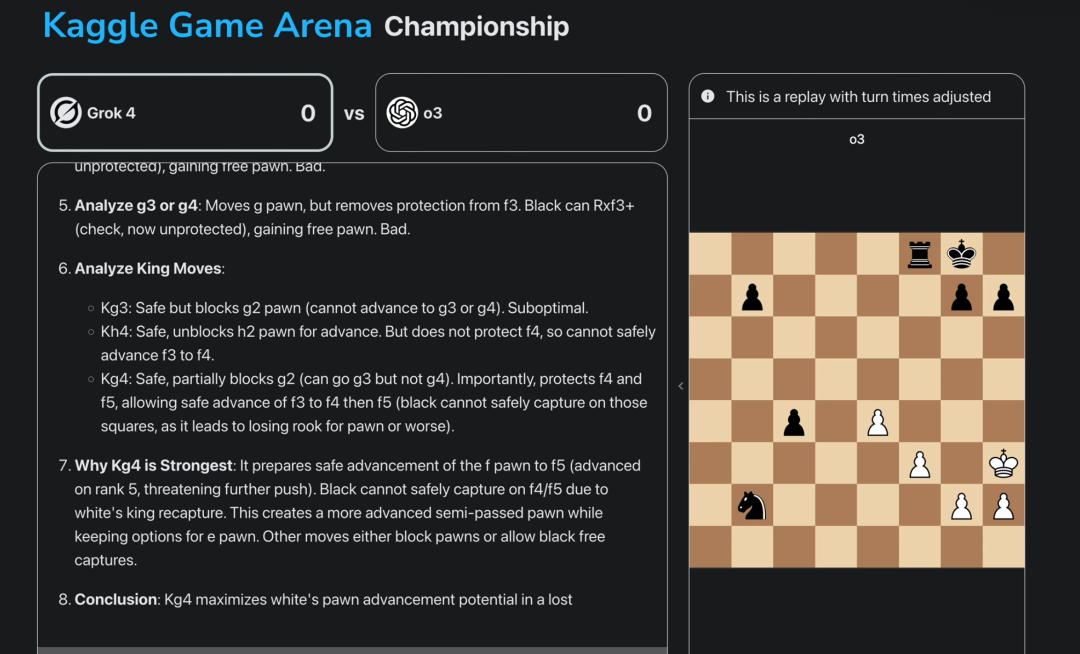
看到這,可能有差友好奇,為啥要讓這些大模型下棋啊,誰贏誰輸和咱有關係麼?
因為國際象棋,更能讓你看出 AI 的實力。
相比那些傳統排行榜,國際象棋考驗的是一套無法靠刷題速成的綜合能力,更能展示出一個大模型的思考、湧現能力。
 過去,我們要想知道哪個模型牛,主要看兩種榜。
過去,我們要想知道哪個模型牛,主要看兩種榜。
第一種就是 AI 競技場 LMArena,可以把它理解為大模型圈的《蒙面歌王》。
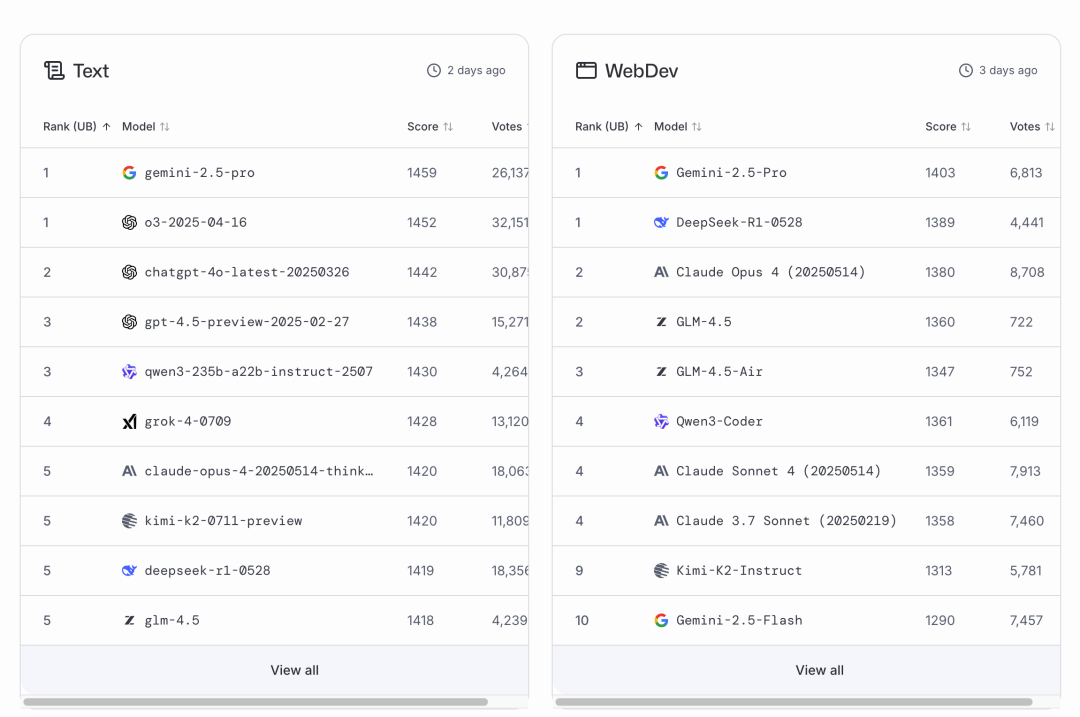
你隨便問個問題,它給你兩個匿名模型的回答,你覺得哪個好就投哪個。
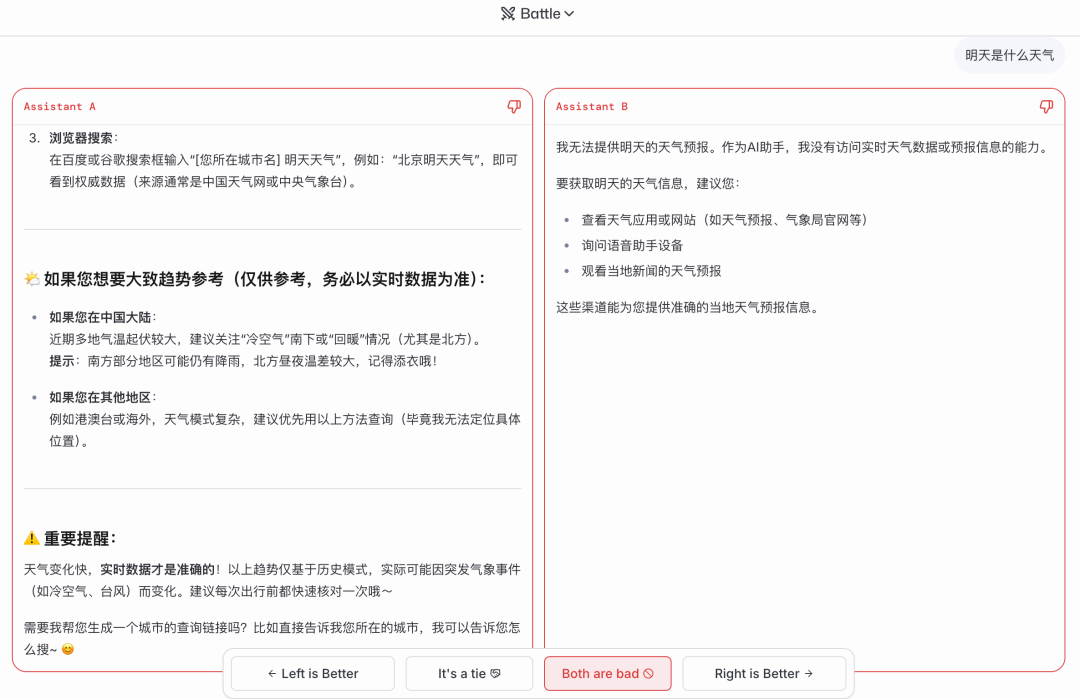
聽起來很公平是吧?但它也有不少缺點。
首先圈子太小了。
我不提,可能很多人都沒聽過這網站。天天泡在上面投票的,不是專業的技術人員,就是一些前沿科技發燒友。
這些人的問題和對答案的主觀判斷,跟咱們普通人可能並不一樣。
 這就導致 AI 競技場排名,更像是一種技術愛好者的口味榜,並非適合你我。
這就導致 AI 競技場排名,更像是一種技術愛好者的口味榜,並非適合你我。

其次,嘴甜的大模型在這種模式裏,很容易佔便宜。
很多時候,大夥兒不會去做事實核查。
 如果有一個模型説錯了所有答案,但它回答地頭頭是道,答案很清晰,邏輯也很自洽,那它很有可能騙走一堆不該有的票數。
如果有一個模型説錯了所有答案,但它回答地頭頭是道,答案很清晰,邏輯也很自洽,那它很有可能騙走一堆不該有的票數。

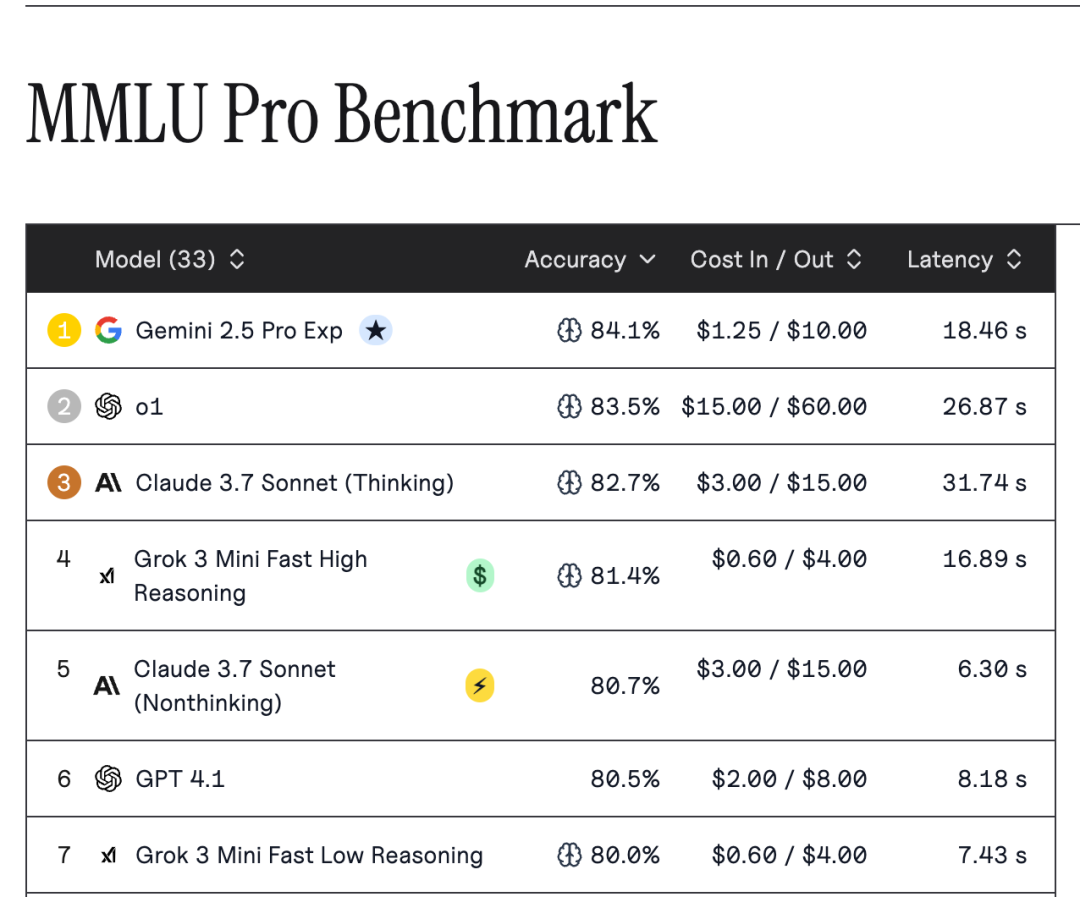
除了 AI 競技場這種主觀排行榜,大模型還有 MMLU Pro和 AIME 這類客觀基準測試。
MMLU 全稱是大規模多任務語言理解,它包含了從初中水平數理化到研究生水平的歷史、科學、法律等 57 個科目,MMLU Pro 則在此基礎上進一步加大難度,總之它可以迅速衡量一個模型知識面的寬度。
AIME 也類似,這是美國高中生數學競賽體系中的一環,可以測試出大模型們的邏輯推理深度。
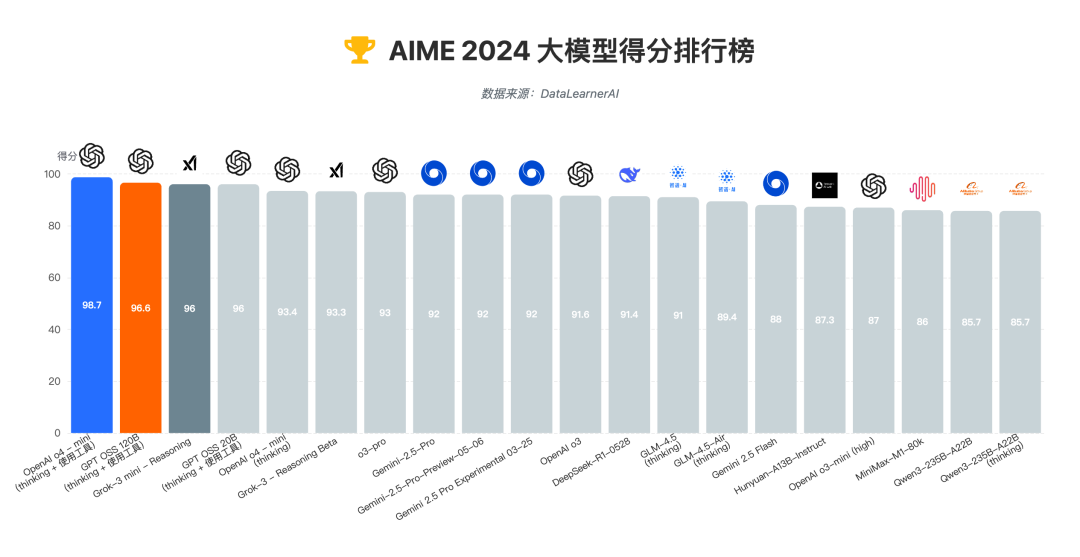
這兩類考試的優點,都是極度客觀。
 但缺點也很致命。
但缺點也很致命。
一個大模型的 MMLU 分數高,只能説明它讀過很多書,或者提前訓練了題庫,並不能反饋出模型的理解能力。
它可能知道“火鍋瞎掉一隻眼是哪一年”,但不一定能分析出火鍋瞎眼對狗圈顏值會帶來多大損失。
而且啊,從去年開始,幾個頭部大模型們正確率就已超過了 80%,正不斷接近於人類專家水平(89.8%),我們也很難看出這些模型之間的實力差距。
同樣,AIME 只能測試一種非常線性的、基於數學公理的邏輯。
但真實世界的問題,哪有像數學題這樣邏輯清晰、條件充分的。
 一個在 AIME 裏爆殺的大模型,或許並不擅長幫你解讀電影,幫你怎麼理解領導的話中話。
一個在 AIME 裏爆殺的大模型,或許並不擅長幫你解讀電影,幫你怎麼理解領導的話中話。
到這,你應該能明白 Kaggle 搞這場象棋比賽的邏輯了——
別再讓 AI 考試和選秀了,到底有沒有實力,直接線下真實一波就知道了。
畢竟大眾普遍需要的,是一個能在複雜、多變的環境中,即時解決未知問題的大模型。

而遊戲,就是一個很不錯的修羅場。
因為你想在遊戲裏贏,光會背書沒用,每一次對局都是完全不一樣的。
 在遊戲中,你也得有大局觀,不能只盯着眼前這一步,最關鍵的是,還得有應變能力,對手一出招,局面又會發生變化,你要會調整戰術,甚至思考要不要壯士扼腕。
在遊戲中,你也得有大局觀,不能只盯着眼前這一步,最關鍵的是,還得有應變能力,對手一出招,局面又會發生變化,你要會調整戰術,甚至思考要不要壯士扼腕。
這些能力,在靜態的考卷上是絕對測不出來的。
雖然這次比賽直播採用錦標賽形式,但最終的排行榜是由全對全系統決定,這些大模型還要幕後進行上百場比賽,最終才會出現一個動態排行榜,給大家查看排名。
國際象棋的比賽結束後,Kaggle 還會繼續舉辦其他遊戲比賽,比如撲克牌,甚至是狼人殺。
該説不説,以後的 AI 排行榜,可能會越來越刺激了。
圖片、資料來源:
Kaggle Game Arena Chess Exhibition Tournament 2025
2025 Kaggle Game Arena Chess Exhibition Tournament: Official Discussion Thread
Chess NewsKaggle AI Chess Exhibition Tournament LIVE
Chess Text Input Leaderboard | Kaggle
Google Kaggle 舉辦 AI 國際象棋錦標賽,評估領先模型的推理能力
