以色列初創芯片公司,瞄準AI CPU_風聞
半导体产业纵横-半导体产业纵横官方账号-探索IC产业无限可能。29分钟前

本文由半導體產業縱橫(ID:ICVIEWS)編譯自nextplantform
AI CPU市場將會非常火爆。
僅僅因為GenAI 計算和其他類型的機器學習和數據分析的重心已經從 CPU 轉移到 XPU 加速器,並不意味着託管這些 XPU 的系統的 CPU 選擇並不重要。
事實上,系統中CPU 的選擇至關重要。CPU 的設計、主內存容量(用作 XPU 的 L4 緩存,用於存儲模型權重和嵌入)、連接 XPU 和外部世界的互連,以及用於加速某些系統功能的板載加速器,都可能決定着是最大限度地利用 XPU 的價值,還是在數據中心的冷卻塔上浪費鉅額資金。如今,世界上最糟糕的事情莫過於花費四五萬美元卻無法充分利用緩存的 GPU。
AMD 和英特爾一直在銷售他們的高端 Epyc 和 Xeon CPU,以此來提高 GPU 主機的吞吐量。具體來説,今年早些時候,AMD 展示瞭如何將其Turin Epyc 9575F 處理器與其自己的Antares MI300X 或 Nvidia 的Hopper H100 GPU 加速器一起使用,可以比高端 Xeon 5 處理器提高近 10% 的 AI 推理性能。
英特爾也一直在為其高端Granite Rapids Xeon 6 6900P 處理器成為 XPU 主機服務器的首選 CPU 而努力。Nvidia 設計了自己的Grace CG100 Arm 服務器處理器,明確地與其數據中心 GPU 配對,用於 HPC 和 AI 工作負載,當然,美國和中國的每個超大規模計算企業和主要雲構建者以及歐洲和印度的 HPC 中心都在出於類似目的推動自己的 Arm 服務器芯片設計。
NeuReality 是一家總部位於以色列的芯片初創公司,一直專注於推理,現在它正在迎接挑戰,與 Arm 合作推出一款新的 Arm 服務器芯片,該芯片專注於作為 AI 推理和 AI 訓練工作負載的主機處理器。
到目前為止,NeuReality 一直專注於 AI 推理,首先從運行 AI 推理算法的 FPGA 開始,然後構建一個名為 NR1 的定製八核 Arm 主機處理器,該處理器於 2023 年 11 月推出,它具有用於 AI 工作負載的板載加速器,可以完成其他 CPU 無法很好地完成且可以從 GPU 上卸載的繁重工作。
NeuReality 由首席執行官 Moshe Tanach、芯片設計副總裁 Yossi Kasus 和運營副總裁 Tzvika Shmueli 於 2018 年 9 月共同創立,其 80 人團隊擁有來自 Marvell、英特爾、Mellanox Technologies(現已成為 Nvidia 的一部分)和 Habana Labs(也曾是英特爾的一部分)的專業知識。
Tanach 曾擔任 Marvell 片上系統設計架構總監。Kasus 曾是 EZChip 的 VLSI 項目經理,EZChip 開發了基於 Arm 的 DPU 引擎,該引擎最終於 2016 年被 Mellanox 收購,併成為 NvidiaBlueFieldDPU 的基礎。Shmueli 曾擔任 Habana Labs 的工程副總裁,在此之前,他在 Mellanox 的芯片部門工作了十五年多。
據我們所知,NeuReality 已籌集約 7000 萬美元的種子資金和隨後的四輪融資,其中包括來自 SK Hynix 和三星等眾多私募股權公司的資金。
如今,PC 製造商紛紛打造有別於普通 PC 的AI PC,而 NeuReality 則在數據中心打造有別於其他 CPU 的AI CPU。其創立原則是,AI 主機的需求與數據中心內執行其他工作的主機的需求不同。2022 年底之前的 AI 推理對主機 CPU 的要求並不高。但 GenAI 的出現使 AI 推理的工作負載大大增加,現在,擁有強大CPU 及其配套 XPU 的主機可能適合運行 AI 訓練,也可能適合在較少的主機數量下進行 AI 推理。這種情況的發生相當方便,但數百家提供專用AI 推理設備的公司以及超大規模計算企業和雲構建者為推理而開發的自主產品可能已經受到了威脅。
但即使你這樣做,也不同於專門為AI推理和訓練設計的主機CPU,它不僅僅是為任何高性能工作負載而設計的CPU。NR1是一個有趣的初步嘗試,它展示了性能更強大的NR2芯片的架構,後者將於2026年推出,並於2027年開始批量出貨。

NR1 擁有八個 Arm Neoverse N1 核心、十六個通用 DSP 核心、十六個音頻 DSP 核心和四個視頻引擎。這些額外的加速器專門用於執行部分主機處理,用於處理 AI 模型使用的視覺、音頻和文本數據。NR1 擁有 20 個 LPDDR5 內存通道(也用於 Nvidia Grace 芯片),可提供 160 GB 的容量和 256 GB/秒的內存帶寬。(誠然,這個容量有點小,但五年前 NR1 規劃時,推理任務的帶寬也一樣小。)該芯片配備兩個 100 Gb/秒的 RoCE v2 以太網端口,用於與機箱內的其他 CPU 以及外界通信。
NeuReality CPU 設計中的特殊之處是它所稱的 AI-Hypervisor,它是一組基於硬件的固件,用於管理主機GPU 內部以及它們管理的 XPU 加速器的數據移動,同時提供服務質量保證和分層編程模型的掛鈎,使得使用 NeuReality 開發的內核庫(或您自己創建的庫)更容易在此主機上運行。
隨着GenAI 助力 AI 推理能力的增強,NeuReality 深知需要將更強大的主機 CPU 投入到該領域,因此正在與 Arm 合作,利用其計算子系統 (CSS) 模塊來加速開發,並於明年推出 NR2 芯片。Arm 已於 2024 年 2 月推出下一代 CSS 模塊。
具體來説,NR2 將基於 Arm 的Poseidon V3 內核——該內核包含大量 SVE2 矢量單元,很可能也會用於明年推出的 Nvidia 的Vera Arm CPU。NeuReality 已從 Arm 獲得Voyager CSS V3 軟件包的授權,該軟件包包含大量圍繞內核的技術,隨時可用。
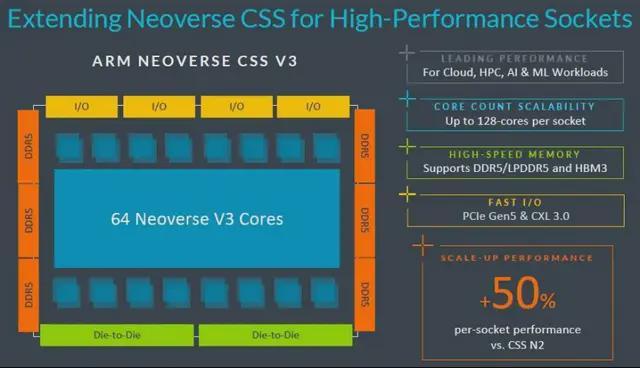
Tanach 並未具體説明將使用 CSS V3 封裝的哪些組件,也未説明集成到 NR2 封裝中的加速器數量,但他表示,將提供雙芯片組選項,將 NR2 插槽的核心數提升至 128 個,同時還將提升封裝的網絡功能——這可能意味着端口速度更快,但也可能意味着端口數量會更多。考慮到設計人員的傳統,NR2 將集成一個經過 AI 調優的集成網卡,具有即時模型協調、基於微服務的分解、令牌流、鍵值緩存優化和內聯編排功能。網絡堆棧還將包含一個結構引擎,用於簡化 AI 客户端和服務器之間的數據流,以及在使用 NR2 處理器和各種 XPU 構建的集羣上運行的 AI 流水線內的數據流。
NR1 芯片展示了 NeuReality 為相對較輕的推理工作負載帶來的差異化,並表明了該公司希望通過 NR2 後續產品產生的影響。
Tanach 表示,藉助NR1,我們構建了一個由運行 Linux 和 Kubernetes 的 ARM 內核管理的異構 CPU,但我們確保數據路徑大部分負載都轉移到了 GPU 或其他處理器上。與Arm 的合作,我們展示了 LLM 中 AI 運算成本的提升,提升了 2 到 3 倍;在運行 LLM 前端的計算機視覺提取管道和多模態管道時,成本甚至提升了 10 倍。
我們期待看到NR2 處理器的供給和速度,以及它如何與 AMD 和英特爾的 X86 CPU 以及超大規模和雲構建者為自己的工作負載設計的基於 Arm 的 CPU 區分開來,並通過高於 X86 的性價比銷售宣傳來吸引客户使用他們的雲。
Arm 基礎設施業務總經理 Mohamed Awad 告訴我們:NeuReality 圍繞 NR2 所做的特別有趣的事情在於,它把加速器置於系統的核心,這很重要,但同時也沒有忽視 CPU 對 AI 計算基礎設施至關重要的事實。我們這裏説的可不是‘弱小的 CPU’——NeuReality 正在這款芯片中全力投入 CSS V3,他們説的是 64 核和 128 核。我認為關鍵在於:這個市場才剛剛開始騰飛。未來將會湧現出許多不同的架構。
AI CPU市場將會非常火爆。Tanach 表示,英特爾和 AMD 向數據中心銷售 X86 CPU 所賺取的 320 億美元中,只有 20% 的收入來自 AI 系統。從長遠來看,AI 平台將推動 CPU 銷售額的大幅增長。NeuReality 認為,一款專為 AI 訓練和 AI 推理而設計、高度調校的 Arm 定製處理器能夠搶佔一大塊市場份額。
超大規模計算和雲構建商顯然相信這一點,因為他們正在製造自己的Arm 服務器芯片。Nvidia 也相信這一點,否則它就不會費心研發 Grace 和 Vera 了。但 Grace 在內存容量和核心數量方面有其侷限性,只有 72 個核心。而 Vera 也只有 88 個核心。因此,某些公司可以推出一系列 AI CPU,核心數量從 32 核到 128 核不等的 SKU,而 OEM 和 ODM 可以圍繞這些 SKU 構建系統並增加價值,而 Nvidia 的 Grace 和 Vera 芯片很難做到這一點,因為它們是完整 Nvidia 產品線的一部分。
*聲明:本文系原作者創作。文章內容系其個人觀點,我方轉載僅為分享與討論,不代表我方贊成或認同,如有異議,請聯繫後台。