英偉達GB200 NVL72與H100,誰才是訓練之王?_風聞
半导体产业纵横-半导体产业纵横官方账号-探索IC产业无限可能。08-27 18:29

本文由半導體產業縱橫(ID:ICVIEWS)編譯自SemiAnalysis
迄今為止,H100 仍是平衡性能、成本和可靠性的最優選擇。
儘管GB200 NVL72在理論上具備顯著的性能潛力,但其當前可靠性缺陷與工具鏈不成熟導致實際每美元性能仍落後於H100。
前沿模型的訓練已將GPU和AI系統推至絕對極限,這使得成本、效率、功耗、單位總擁有成本(TCO)性能以及可靠性成為高效訓練討論的核心議題。Hopper與Blackwell架構的對比並非如英偉達所宣稱的那般簡單。
本報告將首先呈現基於超過2000塊H100 GPU的基準測試結果,分析模型浮點運算利用率(MFU)、總擁有成本(TCO)以及每訓練100萬token的成本數據。本文還將探討能耗問題,測算每個訓練token所消耗的實用焦耳能量,並將其與美國家庭年平均用電量進行對比,從而在社會化語境中重新審視能效意義。
可靠性不足導致的停機時間與工程時間損耗,是本文計算單位TCO性能時考量的核心因素。目前GB200 NVL72尚未完成大規模訓練任務,因其軟件尚待成熟且可靠性挑戰仍在攻關中。這意味着英偉達H100、H200以及谷歌TPU仍是當前能成功完成前沿規模訓練的唯一起作用方案。即便是最先進的前沿實驗室和雲服務提供商(CSP),目前仍無法在GB200 NVL72上實施超大規模訓練。
值得注意的是,任何新架構自然需要時間讓生態圈逐步完善軟件以充分發揮其效能。GB200 NVL72的適配進度雖略慢於前代產品,但差距有限。本文確信,在今年年底前,GB200 NVL72的軟件將得到顯著改善。加之前沿模型架構在設計之初就考慮了更大規模的擴展需求,本文預計到年底時,採用GB200 NVL72將帶來顯著的效率提升。
在可靠性方面,英偉達仍需與合作伙伴緊密協作以快速攻克重大挑戰,但本文相信整個生態圈將迅速整合資源應對這些可靠性難題。
基準測試與分析方法論
本文的基準測試與分析,採用英偉達DGXC基準測試團隊最新的DGX雲基準測試腳本,這些腳本在英偉達內部配備8×400 Gbit/s InfiniBand網絡的H100 EOS集羣上運行。測試結果將作為官方參考標準,新型雲服務商在與客户定義服務級別協議(SLA)時,可據此比對自身環境性能。
雲服務商也可向英偉達提交基準測試數據。若能達到EOS參考標準,即可獲得"英偉達典範雲"認證。本文即將推出的ClusterMAXv2評級體系將高度重視該認證——它標誌着服務商具備在大規模GPU部署中為多種工作負載提供參考級性能的能力。
當前基準測試基於NeMo Megatron-LM框架開展,但考慮到眾多GPU終端用户並不完全依賴該框架,DGXC基準測試團隊計劃擴展對原生Torch DTensor框架(如TorchTitan)的兼容支持。在此特別感謝英偉達DGXC基準測試團隊開發這套基準測試體系並提供參考數據,為提升GPU雲行業標準作出重要貢獻。
H100與GB200 NVL72資本支出、運營成本及總擁有成本分析
過去18個月內,H100服務器單價已有所下降,目前約為19萬美元/台。對典型超大規模供應商而言,包含存儲、網絡及其他組件的單服務器前期資本支出總計達25萬美元。
而對於GB200 NVL72系統,僅機架級服務器本身的成本就達310萬美元。包含網絡、存儲及其他組件後,單機架總成本約為390萬美元。
從三類採購商(超大規模供應商、新型雲巨頭、新興雲服務商)的綜合數據來看,GB200 NVL72的單GPU總資本支出約為H100的1.6至1.7倍。
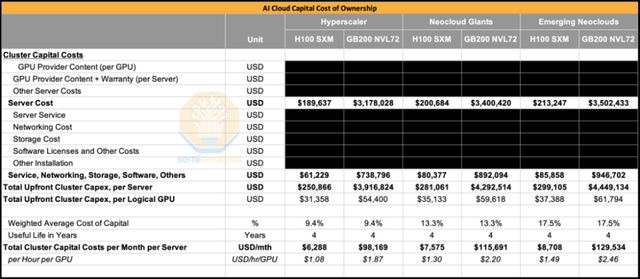
在對比兩個系統的總體擁有運營成本時,本文發現GB200 NVL72的單GPU運營成本(Opex)並未顯著高於H100。成本差異主要源於GB200 NVL72的單GPU整體功耗高於H100,這主要是因為GB200芯片的單芯片功耗為1200W,而H100僅為700W。
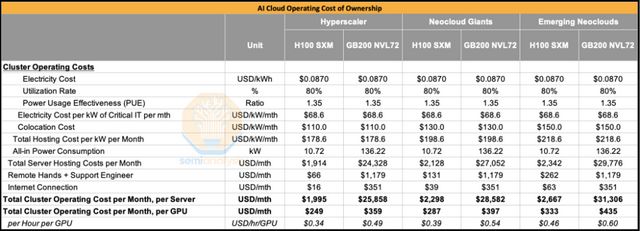
若將資本性支出(Capex)與運營成本(Opex)共同計入總擁有成本(TCO)進行計算,可得出GB200 NVL72的TCO約為H100的1.6倍。這意味着,若要使GB200 NVL72在單位TCO性能表現上優於H100,其運行速度至少需達到H100的1.6倍。

英偉達可優化面向機器學習社區的三大方向
在深入分析性能基準與測試結果前,本文謹向英偉達提出三項關鍵建議:
首先,本文建議英偉達進一步擴大基準測試範圍並提升數據透明度。為推動整個GPU雲行業持續進步,英偉達需對超大規模合作伙伴(Hyperscaler)及英偉達雲合作伙伴(NCP)進行全面基準測試,並將數據公開化。這將使機器學習社區在簽署價值數千萬乃至數億美元合同前,能充分參考基準測試數據優化決策。
例如,在本文首期ClusterMAX評級報告中曾指出:谷歌雲平台(GCP)舊款a3-mega H100集羣在訓練Llama 70B規模模型時,平均模型浮點利用率(MFU)低於行業均值10%;在訓練8x7B混合專家稀疏模型時MFU差距擴大至15-20%。這意味着終端用户需爭取比市場均價低10-20%的租賃費用,才能實現與行業平均水平持久的性價比。公開跨雲服務商的基準測試結果將顯著簡化合同價格談判流程,加速決策效率,並通過避免昂貴耗時的概念驗證(POC)測試為雙方節約大量資源。
第二項建議是拓展基準測試框架範圍,不應侷限於NeMo-MegatronLM。目前許多用户更傾向採用原生PyTorch(配合FSDP2與DTensor)而非NeMo-MegatronLM。雖然NeMo-MegatronLM能率先集成最新性能特性(這些功能往往暫未登陸原生PyTorch),但合理做法應是在最多一個月內將所有這些特性上游同步至原生PyTorch。為此,英偉達應將更多工程師資源配置到PyTorch核心開發而非NeMo功能疊加,同時將基準測試範圍擴展至基於PyTorch的訓練任務以形成戰略協同。
相較於優化NeMo,英偉達更應聚焦TorchTitan的研發。新版NeMo AutoModel庫支持原生PyTorch FSDP2後端(除Megatron-LM外)雖是正確方向,但明顯缺乏對原生PyTorch DTensor三維並行及完整預訓練功能的支持——現有功能仍主要偏向微調場景。
第三,本文建議英偉達加速完善GB200 NVL72背板的診斷與調試工具。目前即使經過嚴格老化測試,NVLink銅質背板的可靠性仍顯不足。GB200 NVL72運維人員同時指出,落後的背板故障診斷工具加劇了這一問題。英偉達還應通過對ODM/OEM合作伙伴實施更嚴格的驗收測試(再向客户交付GB200 NVL72機架)來改善現狀。
下表展示了本文在128塊H100組成的集羣上,於不同時間點訓練GPT-3 175B模型的基準測試結果。本文選取了從2024年1月至2024年12月多個不同版本的NeMo-Megatron LM框架運行數據,這段時間距離H100開始大規模部署分別約為一到兩年。
基準測試採用128塊H100 GPU,配置4個數據副本。每個數據副本由32塊GPU通過並行化策略組成:每層的張量並行(TP=4)在4塊GPU之間通過NVLink域執行,隨後進行流水並行。儘管有人認為TP=8(匹配H100的NVLink全域8GPU規模)更為理想,但對於GPT-3 175B模型,TP=4能夠實現更高的算術強度,因此是更優選擇。
具體而言,GPT-3 175B的隱藏層維度為12,288。若採用TP=8,會導致Key維度的縮減尺寸過小(僅為1,536);而採用TP=4時,隱藏層的縮減維度可達3,072,顯著提高了計算效率。
基準測試的序列長度遵循原版GPT-3論文設置,採用2,048的序列長度和256的全局批量大小。這意味着模型在每次優化器更新前會處理50萬token(全局批量大小 × 序列長度)。
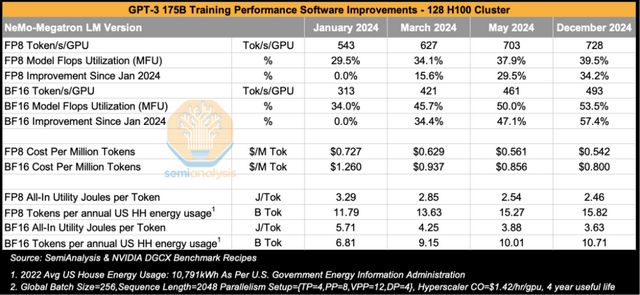
從BF16的模型浮點運算利用率(MFU)來看,在12個月內從34%顯著提升至54%,訓練吞吐量單憑CUDA軟件棧的改進就實現了57%的提升。這一進步得益於NVIDIA CuDNN/CuBLAS工程師編寫了更優化的融合wgmma內核,以及NCCL工程師開發出使用更少流多處理器(SM)完成通信的集體操作算法等多項優化。歸根結底,軟件全棧優化才是關鍵所在。
FP8的MFU也呈現相同趨勢,同期從29.5%提升至39.5,僅通過軟件優化就實現了34%的吞吐量增長。從成本角度分析,在假設單GPU成本為1.42美元/小時(不含租賃利潤)的情況下,GPT-3 175B的FP8訓練成本從2024年1月每百萬token花費72美分,降至2024年12月的54.2美分。這意味着基於3000億token的原訓練數據量,總訓練成本從2024年1月的21.8萬美元下降至2024年12月的16.2萬美元。
最後本文考察訓練GPT-3的能耗情況。通過估算128塊H100集羣(含GPU、CPU、網絡、存儲等組件)的總功耗,並乘以典型託管數據中心的電能使用效率(PUE),本文得出每token消耗的總電能焦耳值。需要説明的是,焦耳是能量單位——1焦耳相當於用1牛頓的力使物體在力的方向上移動1米所做的功。點亮一盞60W白熾燈1秒消耗60焦耳(瓦特是每秒能耗單位),每小時耗能216千焦。另一種能量表述方式是千瓦時,即設備功率與運行時間的乘積。2022年美國家庭年均耗電10,791千瓦時(約38,847,600,000焦耳),按全年8,760小時計算,相當於平均持續功率1,232瓦——略高於單塊GB200 GPU的1,200W功耗!
採用2024年12月版NVIDIA軟件時,每訓練一個token消耗2.46焦耳(FP8)和3.63焦耳(BF16)。若以美國家庭年均能耗為基準,可訓練158億FP8 token。進一步計算表明:訓練3000億token的GPT-3 175B模型,FP8精度需消耗19個家庭年用電量,BF16精度則需28個家庭年用電量。
雖然GPT-3的16.2萬美元訓練成本和19個家庭年能耗看似不多,但現實中大量實驗與失敗訓練任務的累積,正是導致美國當前AI訓練能耗急劇膨脹的根本原因。
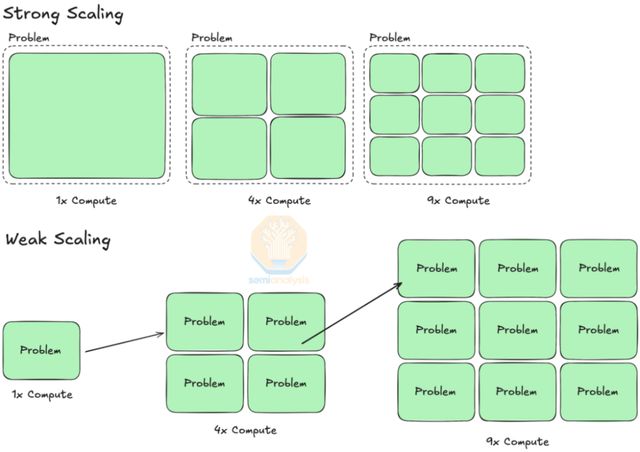
弱擴展與強擴展
弱擴展(Weak Scaling)和強擴展(Strong Scaling)用於描述在不同問題設置(如不同批量大小)下擴展計算資源所帶來的性能提升方式。
強擴展是指在保持模型規模和全局批量大小不變的前提下,通過增加計算資源來提升訓練效率。此類擴展的性能提升可用阿姆達爾定律(Amdahl’s Law)進行量化,該定律描述了通過並行化計算步驟所能實現的理論加速比。
而弱擴展則是指在固定時間內通過擴展計算資源以求解更大規模的問題。人工智能訓練本質上更依賴弱擴展,因為在實際訓練中,可以通過增加GPU數量來擴展模型規模和全局批量大小(在收斂性允許的前提下),從而在相近的時間內處理更復雜的任務或更大規模的數據。
Llama3 405B 訓練擴展分析:單GPU Token處理速度、每百萬Token成本及單Token能耗與GPU數量的關係(弱擴展模式)
本次基準測試旨在探究Llama3 405B模型在擴展H100 GPU集羣規模時的訓練性能變化——這是弱擴展(Weak Scaling)的典型應用。
如下表所示,當GPU集羣從576塊H100擴展至2,304塊H100時,FP8和BF16精度下的模型浮點運算利用率(MFU)分別穩定維持在43%和54%左右。在《Llama 3 模型集羣論文》發佈的訓練任務中,研究者使用16,000塊H100訓練Llama 3 405B模型,採用類似的並行策略,在預訓練階段實現了41%的BF16 MFU。需要説明的是,上述預訓練任務使用的序列長度為8,192,而在訓練中期的上下文擴展階段,每個樣本的序列長度延長至131,072(而非8,192)。更長的序列需要跨16個節點進行上下文並行,由於環形注意力(ring attention)機制引入的額外通信開銷,MFU降至38%。
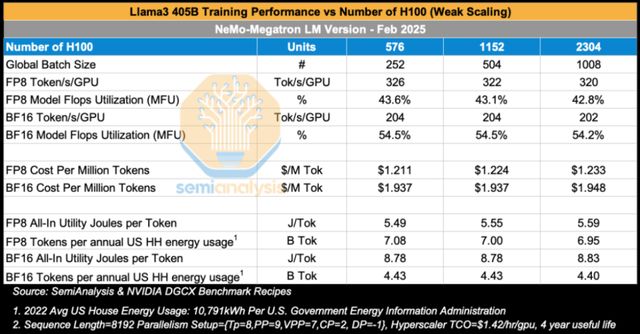
從訓練總成本的角度來看,若使用2,304塊H100集羣以BF16精度對Llama 3 405B進行預訓練(訓練量達15萬億token),每百萬token的成本為1.95美元。僅預訓練階段的總成本就高達2,910萬美元,顯著高於混合專家模型(如DeepSeek每次訓練僅耗資500萬美元)。
需要強調的是,這一成本僅反映最終成功完成一次訓練所需的直接計算開銷,並未包含前期大量實驗嘗試、研究人員人力成本及其他間接投入。
就能耗而言,由於Llama 3 405B的參數規模約為GPT-3 175B的2.3倍,其單token訓練能耗也同比增加:Llama 3 405B每token消耗8.8焦耳,而GPT-3 175B為3.6焦耳。這意味着,以一個美國家庭年均能耗為基準,Meta僅能用於訓練44億個Llama 3 405B(BF16精度)的token。若要完成15萬億token的收斂訓練,所需能源相當於3,400個美國家庭一年的總用電量。
接下來,本文分析不同集羣規模下Llama3 70B模型的訓練性能表現。當集羣規模從64塊H100擴展到2,048塊H100時,FP8精度下的模型浮點運算利用率(MFU)下降了10%,從64塊GPU時的38.1%降至2,048塊GPU時的35.5。這一下降幅度(以百分比計——考慮到MFU基數本身較低,百分比變化更具實際意義)頗為值得關注,因為儘管規模擴大,每個數據副本的批量大小並未改變,並行策略也保持一致。所有實驗均採用TP=4、PP=2和上下文並行=2的配置,唯一的變動僅是增加了數據副本數量。
值得注意的是,BF16精度下的MFU下降幅度遠小於FP8,僅降低了1-2%,從64塊H100時的54.5%小幅下降至2,408塊GPU時的53.7%。
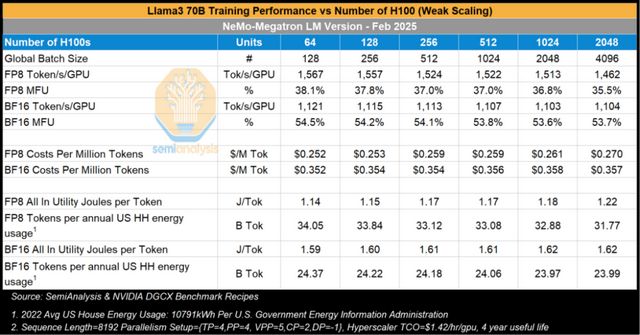
Llama3 405B的參數量是Llama3 70B的5.7倍。對於這類稠密模型,所需浮點運算量(FLOPs)與參數量呈線性關係,因此理論上訓練Llama3 405B的成本應為Llama3 70B的5.7倍。實際在約2000塊H100的集羣規模下,基於BF16精度訓練時,Llama3 405B的每百萬token成本約為Llama3 70B的5.4倍。
就能耗而言,FP8精度下,在2,408塊H100上訓練每個token的能耗比64塊H100集羣高出10%。若以64塊H100訓練Llama3 70B至15萬億token(FP8精度),所需能耗相當於440個美國家庭的年用電量;而將規模擴大至2,048塊H100時,這一數字將增至472個家庭年用電量。
Llama3 8B訓練性能隨時間變化分析
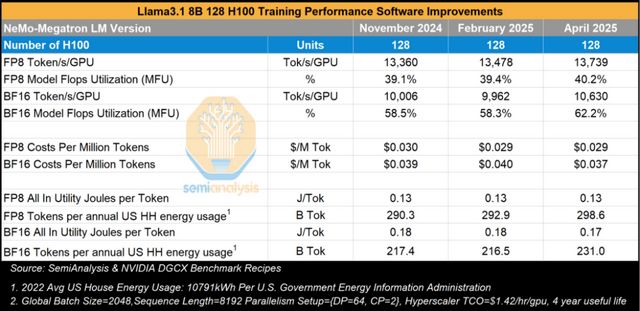
與需同時採用塊量並行、流水並行和數據並行的Llama3 405B/70B等大模型不同,Llama3 8B的訓練僅需在NVLink域內每對GPU間針對8,192序列長度進行上下文並行,並在更多GPU對間採用數據並行擴展計算。本文還分析了其隨時間變化的訓練性能,以評估全棧軟件優化帶來的影響。從2024年11月至2025年4月(即Hopper架構大規模部署滿23個月後),性能僅略有提升。
*聲明:本文系原作者創作。文章內容系其個人觀點,我方轉載僅為分享與討論,不代表我方贊成或認同,如有異議,請聯繫後台。