WEWA、VLA、世界模型,輔助駕駛進入GPT時代_風聞
HiEV大蒜粒车研所-HiEV大蒜粒车研所官方账号-09-02 09:45
作者 | 德新
編輯 | 王博

車企決勝「大」模型
2025年的車市即將邁入「金九銀十」,各家頭部車企在關鍵的輔助駕駛競爭上也摩拳擦掌,醖釀各自年度的大版本更新。
華為ADS4即將推送,並升級到WEWA架構;小鵬、理想、元戎選擇了VLA,已經或者馬上在新車推出新版大模型;地平線、Momenta則更強調強化學習,前者HSD新車馬上要量產了,後者正準備R6大模型上車。

華為ADS4 WEWA架構, 圖片來源:HiEV拍攝
如果用一句話來總結輔助駕駛在今年的趨勢,那就是全面進入了「GPT時代」。這一代的輔助駕駛系統,普遍在車端的模型參數規模上已經超過了十億參數門檻(1B),雲端模型參數規模更是接近千億級(100B)。
當然,與大語言模型相比,今天輔助駕駛「大模型」還在非常早期的階段。但針對模型訓練所需的數據規模,以及算力投入已經在顯著地增長。頭部的車企,包括吉利、理想、奇瑞等在內,雲端算力儲備已經超過10EFlops,各大車企加碼雲端算力以EFlops計算;頭部公司今年增加的輔助駕駛里程,將以10億公里計算。
在輔助駕駛的研發上,大模型主導的技術路線已經非常明確,車企的挑戰從路線的摸索,轉向對新範式下研發組織的變革以及效率打磨。

輔助駕駛進入GPT時代
在整個大AI領域,Scaling Law模型參數規模帶來的算法性能收益仍在持續,輔助駕駛也追隨這一定律。
OpenAI剛剛在8月初發布了GPT-5,其早前歷代的大版本——GPT-2是15億參數,GPT-3躍升至1750億,而GPT-4達到了1.8萬億。歷代模型隨着參數加大,每代模型的能力都令人刮目相看,模型的訓練成本也是直線飆升。
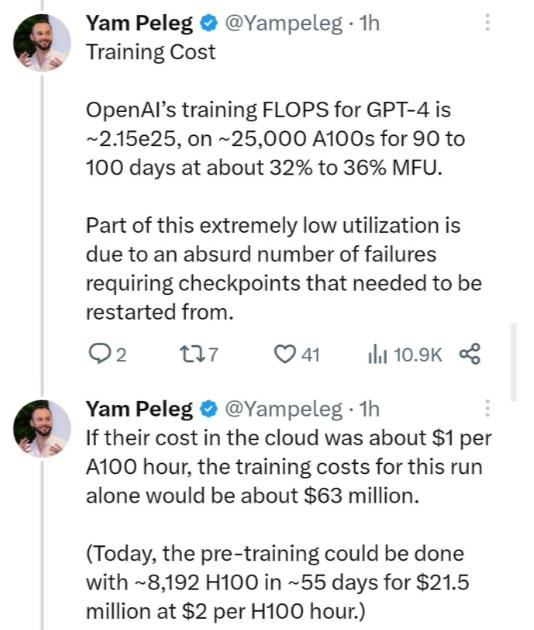
我們沒有最新的GPT-5的數據,但是據此前Deep Trading創始人Yam Peleg爆料:GPT-4大約在2.5萬張A100上訓練了90 - 100天,利用率在32%到36%之間。業界估算訓練算力成本將近8000萬美元,耗電超過2億度。
目前,就輔助駕駛的模型參數規模,進到端到端大模型後有顯著的提升,車端參數規模在10億級(幾B),雲端參數規模已經達到百億級(幾十B)。頭部公司小鵬公佈其在訓練的雲端輔助駕駛基座模型參數規模為72B,理想VLA的VL基座模型達到32B。
純從參數規模角度,輔助駕駛雲端大模型現在的發展階段,介於GPT-2和GPT-3之間。
圖片來源:X
模型參數規模的增長,在車企的研發上是全鏈路的挑戰。
車端視角下,過去BEV + Transformer的範式,需要的車端算力規模大概在100 Tops,現在需要數百甚至1000 Tops級的車端算力;典型的11V 800萬像素攝像頭,每天採集到的數據是數個TB。
雲端投入也在高速增長期。吉利的星睿智算目前算力規模超過23 EFlops,理想最近公佈雲端算力超13 EFlops,奇瑞的天穹智算算力也超過了13 EFlops。光這3家加起來就接近50 EFlops,之前有行業預測稱2028年國內車企總算力規模達到100 EFlops,如今看已經太保守。
除了資源上的壓力,頭部公司也在面臨新的問題,比如MPI的增速放緩,又比如在超過10億級里程積累後挖到有價值數據的難度越來越大,模型訓練的週期也在被拉長。
總之,輔助駕駛在從70、80分,向100分挺進的路上,車企開始踏上最難的一段坡。

車企破局「大模型」開發
在2025年轟轟烈烈的「全民輔助駕駛」運動裏,保守估計國內市場至少50%以上的新車會搭載L2輔助駕駛系統,也就是****一年1000萬台級的增量。
尤其對傳統廠商來説,今年會壓力陡增,一個是車企的用户基數大,另一個是因為今年他們的輔助駕駛配置率拉得很快。比如長安汽車現在大概有2000多萬的車主,奇瑞有超過1600萬,長安預期今年會有數百萬台的增量,而奇瑞則談到今年輔助駕駛里程增加在20億公里以上。
除了堆更高的車端算力,大模型帶來的挑戰大部分聚焦在雲端的工作,比如訓練算力、數據挖掘、模擬仿真等等。
以長安汽車為例,長安今年選了華為雲CloudMatrix384超節點來做輔助駕駛的雲端模型訓練;前不久的智能汽車大會2025上,搭載華為雲 CloudMatrix384超節點的長安天樞智駕重磅發佈。
華為雲CloudMatrix384超節點首創將384顆昇騰NPU和192顆鯤鵬CPU,通過全新高速網絡MatrixLink全對等互聯,形成一台「超級 AI服務器」,單卡推理吞吐量躍升到2300 Tokens/s。針對今年汽車行業大模型的趨勢,華為雲專門跟主流車企做了專項深度的優化,尤其是針對端到端和VLA的大模型。
前面我們提到過GPT-4在訓練時,2.5萬張A100利用率是32 - 36%,什麼意思呢?這實際上是説,此時GPU的算力是夠的,但因為一些原因沒有「餵飽」浪費掉了,可能的瓶頸包括顯存帶寬、通信帶寬等等。
而華為雲CloudMatrix384超節點將算子從CPU向NPU下發,使用的不是傳統的PCIe,而是華為自建的UB(Unified Bus),可以大幅加快算子的下發速度;而在顯存帶寬上,CM384是GB200 NVL72的2.1倍。
顯存高就是在模型的訓練過程中,可以喂得更快、算得更快,模型的參數規模也可以更大;對車企來説,就是同樣電費,迭代更快,訓得的模型更大。
在模型訓練,除了計算之外,還有一大瓶頸是存儲。
華為雲在CloudMatrix384超節點的機櫃中部署了AI-Native智算存儲節點,是專為AI 全生命週期設計的存儲解決方案,也是輔助輔助駕駛開發的加速器。
通過向量檢索,其每次檢索能返回的條數高達10萬條;AI-Native智算存儲還提供大模型訓練所需的高緩存容量和帶寬,到年底,其高性能緩存容量將增長到128PB,高性能緩存帶寬將提升到12TB/s。
所謂「向量檢索」,比如高速場景中會蒐集海量數據,想找到「 前車車尾伸出了一根長長的鋼管」,要從海量的場景中找到對應的數據堪稱「大海撈“幀”」;使用傳統的檢索方法每次只能反饋一千條的結果,而華為雲通過AI存儲和向量檢索結合,一次可以返回十萬條的結果,大幅提高數據挖掘的效率。
目前,長安與華為雲開展深度合作,基於華為雲CloudMatrix384超節點及華為雲高帶寬、大容量的存儲集羣,成功實現了長安汽車自動駕駛模型的高效訓練。雙方已進行了VLA、端到端等多種自動駕駛模型的適配。
華為雲通過AI上飽和式的投入,以及CouldMatrix384超節點、AI-Native存儲等核心技術的創新,正在成為車企佈局大模型的首選夥伴。

輔助駕駛,如何駛向更安全的未來?
伴隨着開年的「全民輔助駕駛」運動,今年對輔助駕駛安全的關注也是空前的。
前不久在貴陽,華為雲發佈了全國首個具備大規模超節點的汽車專區 —— 華為雲貴安汽車專區。

華為雲貴安汽車專區發佈,圖片來源:企業官方
華為雲貴安汽車專區是專為汽車行業打造的雲基礎設施,依託分佈式接入架構與全國高可用佈局,實現低時延就近接入,保障用户在自駕遊等跨區域出行場景中,都能享受到一致的智能輔助駕駛體驗。
同時,多專區多活架構讓系統可靠性大幅提升,實行車雲時延降低60%,可用性達99.999%,讓智能輔助駕駛體驗更流暢、更可靠。
此前,華為雲已建成業內首個 「 三可用區(3AZ)」烏蘭察布專區,此次貴安專區上線標誌着其第二大汽車專區落地。後續蕪湖汽車專區上線後,華為雲即將完成業內首個三專區上線。
未來,三大專區協同聯動,將為智能輔助駕駛技術研發提供安全合規、低時延、高可用的基礎設施保障,支持分佈式全國就近接入,顯著提升用户體驗。
據瞭解,中國最大的智能駕駛輔助企業引望跑在昇騰雲上,引望使用雲上算力已支持100萬輛車智能飛馳。
華為雲在輔助駕駛的體驗上還有一個重要的創新思路是,以雲助車。
「 以雲助車」方案為複雜的智能輔助駕駛場景提供澎湃動力,已幫助車企落地泊車與低速巡航場景:一方面將難例泊車成功率提升15%,另一方面藉助雲端大模型輔助優化端到端泊車效率,讓準備出行的用户享受更輕鬆的駕駛過程。
真正「大模型」時代對車企的挑戰是日新月異的,用華為雲中國區Marketing與解決方案銷售部部長劉飛的話「華為雲幫助車企造更智能的車」。目前,已有5000萬輛智能網聯汽車由華為雲提供服務。
