6個月估值暴漲5倍突破100億美元,三個“00後”逼急Scale AI_風聞
极客公园-极客公园官方账号-09-08 13:11

AI 數據行業,總有新人出頭。
作者|芯芯
編輯|靖宇
AI 浪潮裏,數據標註可能是不起眼,但卻最重要的一環。
比如數據標註巨頭 Scale AI 的創始人,被扎克伯格用上百億美元收編,輟學生搖身一變成了 Meta AI 團隊重要人物。
而與此同時,另一家公司借 Scale AI「不再中立」的機會,挖走了 Scale AI 原來的客户,甚至逼得 Scale AI 親自下場起訴。
這家公司叫 Mercor,2023 年成立,創始人都是 00 後。兩年間,他們把「數據標註」的苦差事,變成了一個平台生意,收入飛速增長。
今年 2 月,公司估值已經突破 20 億美元**,****半年後的當下,**居然還有人開出 100 億美元的投資邀約。
半年時間估值狂漲 5 倍,Mercor 做對了什麼?
01
AI「專家」撮合平台
通常,人們提起數據標註,想到的是印度、菲律賓、非洲外包公司,幾百萬匿名「眾包工人」在屏幕後苦撐,如同數據血汗工廠,平台管工、千人同做、質量靠抽檢。
但 Mercor 的邏輯有點不同,這家公司並不依賴低價勞動力,而是聚焦領域專家,比如律師、醫生、金融分析師、化學研究員,或者博士、 STEM 領域人才。複雜任務需要高質量數據,而高質量數據只能靠「懂行的人」產出,不能只是學生和眾包工人。
它搭建了個 AI 驅動的招聘平台,靠着最近 AI 模型大廠對「專家級人類數據」的需求激增,正好切中痛點,於是撮合了大量數據標註業務。客户可以發出需求,平台用模型篩簡歷、做測評、AI 自動面試與對接,最後連工資都代發,最後向甲方收取佣金或服務費。
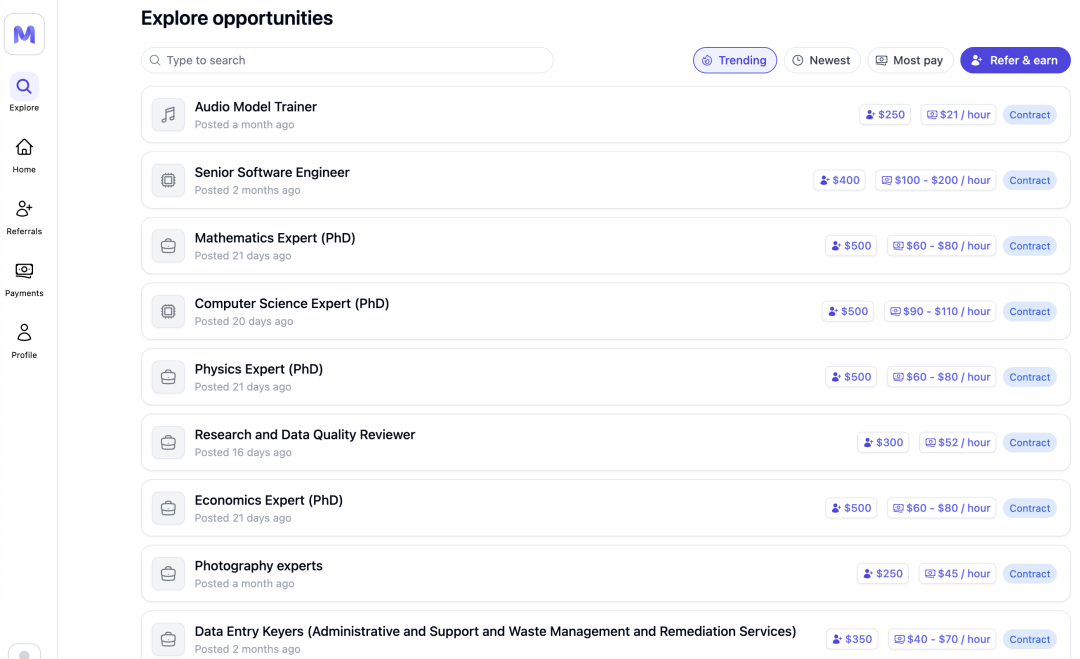
Mercor 平台上各種專家數據標註職位 |圖片來源:Mercor
「我們的爬蟲會自動從簡歷、GitHub、個人作品集網站等平台抓取信息,從而完整地展現每位申請人的形象。這使我們能夠瀏覽數百萬份個人資料,進行數千次面試,最終在全球找到一兩位最適合特定職位的人才。」Mercor 的首席執行官稱。
2025 年初,Mercor 的全球候選池據稱有 30 萬人,其平台用 AI 工具做准入篩查,每一次合作都會產生表現數據,反哺匹配算法。需求端和客户包括很多頂尖 AI 實驗室和科技公司,任務難、單價高。
簡言之,Mercor 現在做的不是簡單的數據標註外包,而是「AI 時代的按需專家外包」。
對於瘋狂訓練大模型的公司來説,這意味着可以不養冗餘人力,就能在項目週期內迅速拉起一支懂行的隊伍。而且,如果供應商沒被任何一家巨頭捆綁,能在競爭激烈的市場保持「中立」,那聽起來比任何炫技都可靠。
據 Mercor 聯合創始人兼 CEO 稱,該公司目前已與「七巨頭」中的 6 家合作,同時也覆蓋了全球前五大 AI 實驗室以及大多數頂級應用層公司。

Mercor B 輪融資 1 億美元 |圖片來源:Mercor
Mercor 的創立時間很短,但融資路徑算是教科書級的。2023 年,它拿下 General Catalyst 領投的 360 萬美元種子輪,奠定平台雛形。
一年後,Benchmark 在 2024 年 10 月領頭投 3000 多萬美元,公司估值躍升至 2.5 億美元。那一輪的投資人名單有不少硅谷名流,比如 Peter Thiel、Twitter 聯合創始人 Jack Dorsey、Quora 聯合創始人 Adam D’Angelo,甚至還有前美國財政部長進行了個人投資。
接着是 2025 年 2 月的 B 輪融資,由 Felicis 領投,General Catalyst、DST Global、Benchmark 和 Menlo Ventures 跟投,一共 1 億美元,直接把 Mercor 的估值推到 20 億美元。這筆交易僅用兩週完成,甚至由公司主導條款。
當時,Mercor 披露的數據有一定誘惑力:年化營收約 7500 萬美元,月環比增長 50%,並已實現月度盈利。市場因此願意按 27 倍 ARR 的溢價買單。
半年後,Mercor 並未主動尋求新一輪融資,卻接連收到「不請自來」的要約,投資邀約最高甚至喊到 100 億美元。就這樣一家兩歲的初創公司,被市場追着投。

Mercor 的三名創始人 |圖片來源:Mercor
硅谷的資本為何那麼積極?
邏輯並不複雜。在市場上,模型本身的差異正在收斂,競爭的關鍵逐漸前移到數據與人類反饋;Mercor 的商業模式又很輕,平台抽成配合靈活外包,不需要龐大的固定成本,就能放大現金效率;更關鍵的是,頭部對手陷入信任危機,中立成為稀缺品。
所有 AI 實驗室都擔心:
自己辛苦獲得的數據**,**最終流向競爭對手。
另外比較吸睛的,是創始團隊的年齡與履歷。硅谷向來痴迷年輕創業者,三名創始人均為 00 後,都從大學輟學,拿過 Peter Thiel 設立的獎學金。團隊還從 OpenAI 挖來人力數據運營主管、從 Scale AI 挖來增長負責人,給了資本「既快又穩」的敍事。
02
Scale AI 成前浪?
無論 Mercor 的估值是否合理,該公司最近的突然躍升,不得不提 Meta 和 Scale AI 的推波助瀾。
2025 年中旬,Meta 的扎克伯格出手,花重金買下 Scale AI 49% 的股份,把它的估值抬到 290 億美元,刷新了 AI 數據服務領域的紀錄,也順手把 Scale AI 的「中立性」摧毀殆盡。
過去十年,Scale AI 是數據標註的代表性供應商,它靠自研工具和管理大規模標註隊伍,為客户交付端到端數據。
但當你的客户裏同時有谷歌、微軟、OpenAI、馬斯克的 xAI,而你又被 Meta 部分「收編」,其他人會怎麼想?
答案來得很快:合同縮減、遷移、觀望、複審,Scale AI 自身的團隊也陷入動盪。Scale AI 依舊龐大,但外部已經質疑它會變成 Meta 的「內部基建」。

扎克伯格與 Scale AI 的創始人 Alexandr Wang|圖片來源:X
空出來的訂單與信任,可以流向誰?當然是,其他數據標註公司。
Mercor 現在可以標榜自己是獨立第三方,保證不會把數據餵給競爭對手,還能在短期內組織懂行的專家隊伍,尤其擅長複雜、高價值的垂直數據標註任務。
更諷刺的是,即便 Meta 控了 Scale AI 的半壁江山,Meta 內部的一些團隊在訓練新模型時,據傳依然繼續採購 Mercor 的數據服務。
相比 Mercor 的專家定製標註,Scale AI 更偏向大規模數據標註,適合通用任務,而模型前沿實驗室有時需要定製化的數據。
另外還有數據質量和內部團隊矛盾的原因。
部分 Meta 研究員對外爆料稱 Scale AI 的數據「質量不夠高」。而且,Scale AI 前高管加入 Meta 不到兩個月就離職,也引發外界對雙方整合效果的質疑。一些 Meta 老員工也對空降成領導的 Scale AI 創始人頗有微詞。
內外部同時衝擊,意識到風向的 Scale AI 也坐不住了,開始起訴 Mercor,指控其存在「商業間諜行為」,包括挖走高管並竊取客户資料以「策反」客户。
一名從 Scale AI 跳槽到 Mercor 的員工在社交媒體上稱,「剛得知我要被 Scale 起訴了。上個月,我從 Scale 離職,加入了 Mercor……後來 Scale 聯繫我,説我在個人網盤裏還有一些文件,我當時就問能不能直接刪掉。但他們讓我不要對這些文件做任何處理,所以我現在還在等他們的進一步指示來解決這件事。在 Mercor 的工作中,我從未使用過這些文件。聽起來 Scale 想起訴我,這是他們的決定。但我只想説,我真的沒有任何惡意,也沒有不正當的行為。」
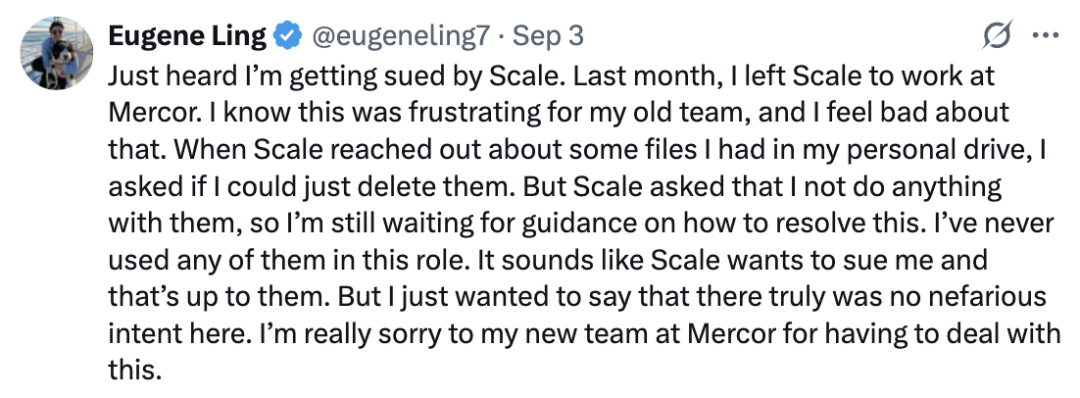
跳槽到 Mercor 的員工稱被 Scale AI 起訴 |圖片來源:X
03
數據標註的「快」與「慢」
誰能想到,扎克伯格一邊把 AI 人才市場的薪資水準,抬到職業球星的高度,另一邊也順手給數據標註產業添了把火。
這也算給整個行業上了一課,中立、數據需求方向,都是 Mercor 拿走大單的籌碼。而 Scale AI,現在和一家巨頭綁得太緊,就得接受客户轉身離開。
在早期,大廠還熱衷自己全網爬數據,給模型「喂料」。但這兩年來,大部分標註工作都被外包給了第三方。這不僅是成本控制,也是競爭加劇後必然選擇。
這門常常被科技從業者視為「打雜」的生意,早期依賴大規模人工眾包,讓 Appen、Lionbridge 等平台靠廉價勞動力主導市場,之後是 Scale AI、Labelbox 等公司借自動化工具迅速擴張,而到了 2025 年,高質量、專家級標註的需求激增,算是給 Surge AI、Mercor 等新貴崛起帶來機會。
不過,即使 Scale AI 被動給 Mercor 讓了道,這不代表它沒有風險。它仍需要證明自己配得上數十、甚至上百億美元估值的預期。
因為它做的是數據標註最難標準化的部分,不是給貓畫框、識別紅綠燈,而是讓專家進行復雜判斷,比如哪段代碼更優,這類任務交付速度更慢,很難靠「人海戰術」堆出來。
在 Mercor 的核心業務邏輯中,「用專家做數據」原本是它區別於 Scale AI、Surge 等競爭對手的關鍵,但這也可能導致它難以像後者那樣依賴眾包或自動化擴張。
每一個項目都需要獨立匹配具有背景知識的標註者,是博士、是醫生、是工程師,不是可以從落後國家隨時拉人的兼職工。招人更難、耗時更久,而且這些專家並不便宜,一小時幾十美元的成本,遠高於傳統平台靠眾包打標籤的方式。
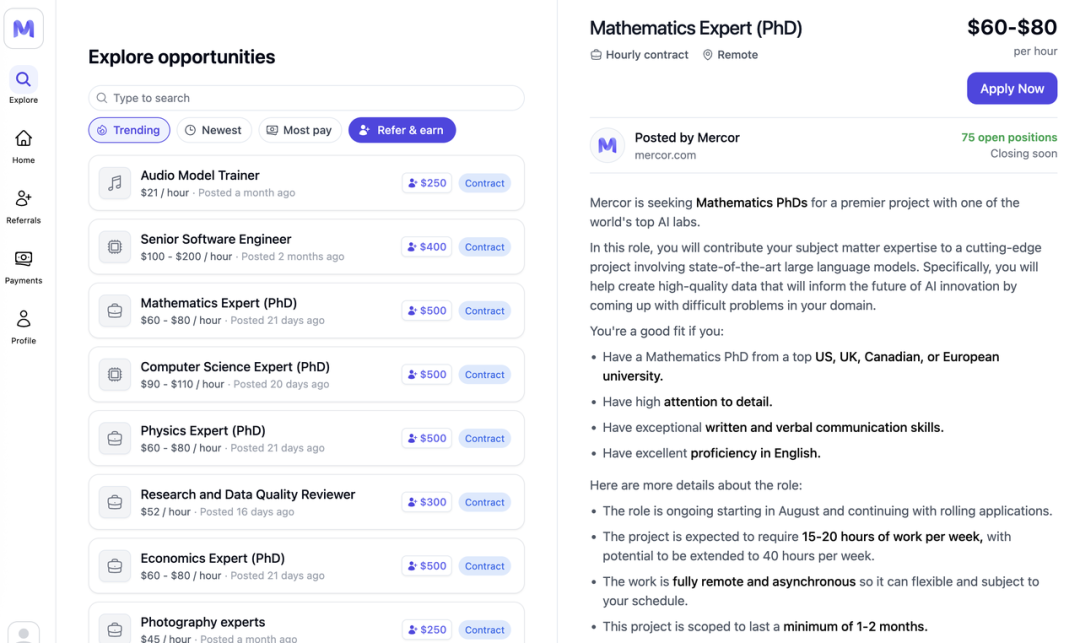
平台以每小時幾十美元的價格招募學科專家 |圖片來源:Mercor
這種模式能確保數據質量,但無法確保規模速度。如果客户需要的是「快」「便宜」「能迅速上量」,那它提供的就更像是奢侈品,而非標準化的工業品。
還值得注意的是,社交媒體上存在一些對 Mercor 平台的質疑。這些申請人需要進行 20 分鐘的人工智能視頻面試,有用户感覺「Mercor AI 面試更像是在收集數據而非認真面試」,像是為了「訓練其 AI 模型」的偽招聘。
Reddit 上有人諷刺道:「數據已收集,候選人被拒絕。」一名自稱沃爾瑪數據科學家的用户在 LinkedIn 上直言:「這是個騙局。」還有人乾脆在 Medium 上寫長文,指責「一些公司正在利用求職者的絕望——不是為了招人,而是為了收集機器學習模型的數據。」
當然,有時也會有用户反駁稱,「他們在招聘方面非常挑剔。他們不像那些 AI 數據標註農場。」
與此同時,外部競爭在白熱化。Surge AI 在 2024 年突破 10 億美元營收,超越 Scale AI,直接把整個行業的基準線拉高。此外,一些客户已經在探索用大模型為自己生成標註,只保留少數專家校驗,壓縮成本。這種趨勢一旦成型,也可能給 Mercor 的後期增長帶來問題。
説到底,就像 Scale AI 常常被業內質疑的那樣,Mercor 雖然也説自己是科技公司,但仍在服務行業的邏輯裏。很多數據標註公司估計都需要回答一個問題:
它們到底算科技平台,還是高級勞務中介?
不過,這並不妨礙它現在賺錢。對投資人而言,「打標籤」是否性感並不重要,關鍵在於利潤和估值是否可觀。只要 AI 仍然離不開人工標註,像 Mercor、Scale AI 這樣的公司,就依然能吸引資本趨之若鶩。
Mercor 聯合創始人兼 CEO 公開博文 |圖片來源:Mercor
還值得一提的是,Mercor 的長線野心並不只是數據標註。根據 Mercor 聯合創始人兼 CEO 的説法, AI 數據標註,只是他們進入市場的「切入點」,「與全球數十億的知識型工作機會相比,這顯得微不足道。」
他明確公佈了自己的計劃:用 AI 標註工作起步,學習如何預測工作表現,拓展至所有短期崗位,最終「為所有工作招聘人員」。
「勞動力市場是全球最大、同時也是最低效的市場。更好地將人們與他們日常從事的工作匹配,是提升全球效用的最大槓桿。雖然我們最初聚焦於為 AI 模型訓練招募專家,並取得了令人矚目的進展,但這只是我們解決全球勞動力配置問題的第一步。」
Mercor CEO 如此説道。
*頭圖來源:Mercor
本文為極客公園原創文章,轉載請聯繫極客君微信 geekparkGO