潘攻愚:“畫地為牢,作繭自縛”,這八個字將在美國身上應驗-心智觀察所、潘攻愚
guancha
【文/觀察者網專欄作者 潘攻愚】
1月13日,美國史上第一個大規模AI出口管制框架靴子落地。
這份名為“AI擴散管制框架”(Framework for Artificial Intelligence Diffusion)的文檔洋洋灑灑一共168頁,已經刊登在“聯邦公報”federalregister上,公眾可以在公佈的四個月之內給予反饋評論和意見。
之所以説是靴子落地而非揭開面紗,是因為這份管制框架的大部分細則早在一個多月前即12月初,就以聯邦法規立項通知的方式公開,經過美國媒體、智庫、產業界關於該擬議法規的公開討論後已經產生了足夠的輿論發酵,當時政商界相關人士就普遍認為最終版的管制框架將在特朗普入住白宮前夕正式公開。
某種意義上,它是拜登給特朗普埋的一個雷,一個楔入的釘子,也更像是一份綜合性的述職報告。
拜登政府“最後一舞”的三大特點
該AI擴散管制框架是對過去兩年美國BIS(工業與安全局)針對高算力芯片出口管制政策的一個擴大版的總結和所謂的查缺補漏。它可以被總結為三大特點。
首先,在GPU的性能標準管制的基礎上,增加了對管制模型權重參數的設置,並且區分了開源和閉源。
美國BIS依然延續了2022年10月7日(10.7規則)、2023年10月17日(10.17規則)以及2024年3月29日的(3.29規則)的思維模式,即劃定一個AI大模型動態平衡的參數,對計算能力特定閾值劃線,對“性能很強”的大模型,尤其是不如現有開源模型強大的閉源模型權重進行出口管制。
AI模型訓練的權重(Weights)和數據處理量和算力體系密切相關,那如何定義“性能很強”呢?那就是通過對模型訓練所需的浮點運算數(FLOPs)加以審定。FLOPs實際是模型訓練做了多少次加法和/或乘法運算,FLOPs的數量如果很大,説明模型規模很大,帶來的所謂風險也就更大。
在這一點上,美國相關部門已經發現,由於所有現代大語言模型都是由相同的算法模塊構建而成,他們其實無法真正對已經落地的開源模型進行管制,只能採用“新人新辦法,老人老辦法”的原則,對新冒出來的被判定有一定調用大算力風險的,且性能性強的(以10的26次方次計)閉源模型進行審查處理。
事實上,在數據主權思維意識主導下,即便是美方不實施額外的卡脖子政策,我國政府也不會放任國內數據任意被Meta,OpenAI等公司拿去做AI模型訓練;美國BIS也意識到這一點,對美國境外的模型權重也設定了外國直接產品規則,這意味着中國大型雲服務商即便是在海外訓練AI模型,如果超過以10的26次方次計的FLOPs,也有可能觸發管制紅線。
其次,該框架很大程度上試圖恢復瀕於死亡的“瓦森納協定”的元氣。
心智觀察所之前曾撰文指出,冷戰結束之後,美國領導下的西方在巴黎統籌委員會的基礎上另起爐灶,搞出了一套面向全球的軍民兩用出口管制架構。不過隨着世紀之交美俄矛盾的深化以及組織章程定義的不清晰,疊加中國硬科技實力的突飛猛進,美國商務部BIS逐漸跳上前台,以單邊實體清單+最終用户、使用區域管制的辦法逐漸侵蝕“瓦森納協定”地盤,讓後者在2019年之後逐漸名存實亡。
但這份AI擴散管制框架的出現,讓我們突然再次嗅到了“瓦森納協定”的腐屍氣——創制性地搞出了一個GPU出口到全球數據中心的三層地域體系。
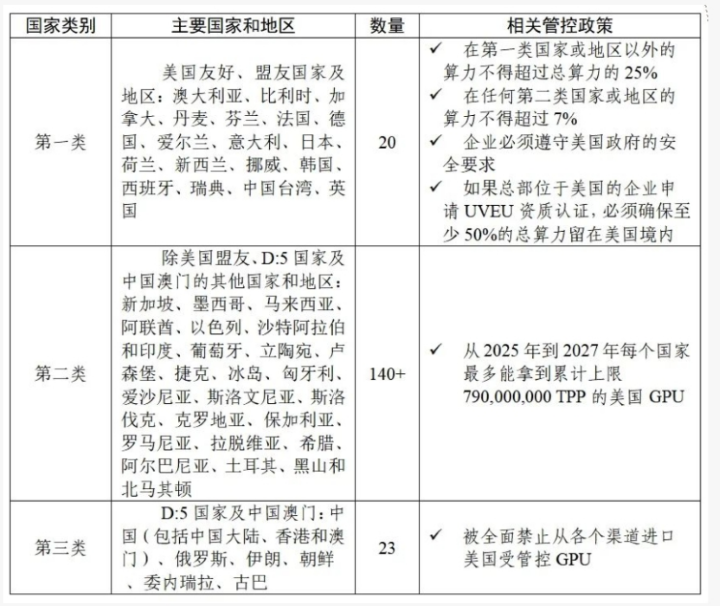
這個三層解構,最內圈的是美國20個不到的核心盟友。這些核心盟友國家,如澳大利亞、比利時、加拿大、丹麥、芬蘭、法國等(值得注意的是日韓和台灣地區均在此列)只要提交申請保證不讓數據中心GPU外泄到其他國家,就不受算力密度管制限制;
最外圈是被美國視為敵對國家的一類,當然包括中國。這些國家GPU需要最嚴格的推定拒絕。
這三個圈層中,最複雜的當屬中間層,有100多個“待觀察國家”。對這些國家美國採取了鬆緊適度原則,用“總處理性能”(TPP)劃了兩條線,一條是向單個該國家類別的公司出口大約1700塊GPU,當然如果GPU的性能很低則不受管制;一條是GPU國家配額,設定為2025年至2027年向這類國家累計出口約5萬塊GPU的設為上限,用於科研院所等學術交流的則不受管制。
以數據中心高性能GPU出口目的地來劃分美國盟友的親疏有別,是該協議框架的一大特色,其實這也是被廣大美國本土高科技公司,包括CSP雲服務商、GPU廠商等廣為詬病之處。
第三點,中東地區成為美國AI管制的重點監察區域。
如前所屬,中間圈層的國家受到了GPU出口配額和總量限制,必然會連帶影響到美國CSP們在這些國家數據中心的部署,而中東國家大多屬於此類。
目前卡塔爾、阿聯酋和沙特等國紛紛出台AI算力替代石油戰略,數據中心的地位愈加提高,讓美國忌憚中東有可能成為高性能GPU流向中國的中轉站或者backdoor。因此,新的管制框架規定這些國家部署的GPU經銷商,雲服務運維等項目必須接受“經驗證最終用户”(Validated End User,VEU)認定,才能安排受控的GPU部署。
除了上述三點之外,心智觀察所還發現,有關GPU總處理性能、性能密度方面,新框架無甚高論,基本上延續了2023年10月的相關參數認定。
為何説這份管制框架必然爛尾?
在1月13日“AI擴散管制框架”正式出台之前,美國官方公告就悄悄上馬了一份長達200頁的上述三圈層管制細則。美國半導體行業協會(SIA)之前就發出警告,闡述了這種極為複雜的全球管制條例難以落地的原因。
一直強調合規經營,嚴格執行美國本土管制制度的英偉達,這次終於按耐不住,他們的反應比眾多雲服務商還要激烈:“這份文件純屬秘密起草,並未經過適當的立法審查。通過努力操縱市場結果並扼殺作為創新命脈的競爭關係,拜登政府的新規有可能浪費掉美國來之不易的技術優勢。”
需要指出的是,讓英偉達破防的不是這份總體性的框架,而恰恰是其中那部分帶有“瓦森納協定”色彩的三圈層管制條例,這會極大地增加企業的法律合規成本,讓本來就在華業務不斷受損的英偉達雪上加霜。
2023年10月新規之後,英偉達在華業務就已經不得不承受着巨大的地緣政治方面的額外壓力。
從2023年第三季度開始,英偉達的數據中心營收在總營收中的佔比已經超過80%,中國大陸市場在英偉達財報中的營收貢獻長期在20%以上,英偉達中國大陸地區市場的實質營收貢獻其實遠大於財報數據。因為中國台灣地區的企業,如華碩、技嘉、微星等,集成了英偉達的芯片,大量最終客户仍在中國大陸地區。
比如説,2023年11月17日出口管制正式生效時,英偉達將主要用於消費端的RTX 4090系列顯卡的產品信息從簡體中文官網移除,並通知渠道商下架官方渠道銷售的RTX 4090,日後不能再單獨賣卡,只能以整機預裝的方式銷售。而且, 英偉達陸續推出的在華閹割版GPU,H100/H800的單價曾經一度在國內已經被炒至25萬-30萬一張,多輪出口管制正在讓原本的算力價格平衡被逐漸打破,性能最強的H20理論性能僅為H100的20%左右,在國產AI加速器國產替代大潮之下,英偉達閹割版的性價比難匹昨日。
與英偉達斥責遙相呼應的是,甲骨文執行副總裁肯·格魯克(Ken Glueck)在此之前就憤怒地表達了對拜登政府“人工智能擴散出口管制框架”的不滿,稱其“將成為美國技術產業所遭受的最具破壞性的規定之一”。
相比GPU製造商,雲服務商更加看重infra部署的總成本優化,強調算力、運力、存力的協同作戰,芯片、板卡、軟件棧、服務器集羣牽一髮而動全身。
拜登政府的新AI管制框架不但要卡脖子GPU,還要結合區域性的總分配算力和模型訓練的權重綜合管制,必然會導致蹺蹺板效應,讓大型雲計算企業無所適從,而且數據隔離牆造成的語料孤島,本身不利於LLA大模型的成熟化落地。
這份管制框架還有另一層面上面臨崩殂的因素。
跟蹤芯片禁令最緊密的Jefferies分析師認為特朗普政府大概率會給這次拜登Al擴散令暗中搗亂。因為越是複雜的規則,就越需要更多的人力去解讀、執行和落地。
BIS龐大的AI管制框架,打着國家利益的幌子,其實也是在給自己撈預算和油水。
2020年以來,BIS僱員每年大幅增長,而且薪水待遇也水漲船高。根據美國職場數據諮詢平台glassdoor數據,BIS的平均薪資範圍約為141248美元/年至 141248美元/年(主管級別)。可以説,BIS是美國聯邦機構眾多大小堂口中人員迅速膨脹至臃腫的典型,應該屬於馬斯克DOGE(美國政府效率部)重點監察的對象。

DOGE是捅破BIS爛瘡的匕首
疊牀架屋必然四面漏風,而且新規讓美國對全球200多個國家實施動態GPU管制,把全球生產要素流動管制做一種開天眼式,或者開啓使用作弊器玩遊戲的模式才能達到預期效果,無論從可能性和現實性上都讓人感到荒謬滿滿。
特朗普的對外管制的特點是喜歡抓關税,而非手舞足蹈,腦體忙亂式的遵循複雜管制條例,Jefferies分析師已經預判,特朗普百日執政的重點就是手拿奧卡姆剃刀剔除繁文縟節,168頁的框架對他來説,實在是太多了太複雜了,不忍卒讀。
應對之策:推理與架構創新
為何美國商務部BIS如此迫不及待頒佈新版本的AI管制框架?
除了作為國內黨爭的武器之外,也確實是看到了中國在AI大模型方面有突飛猛進之勢。DeepseekV3的成功也許已經預示着AI大模型從數據的預訓練時代向推理時代過渡,連OpenAI自己也不得不承認,test time compute也就是推理計算的scaling會讓AGI更快到來。
訓練是人工智能模型的第一階段,這一階段可能涉及反覆試錯的過程,對算力的要求非常高,對成本控制和功耗相對不那麼看重,需要大力出奇跡,即向人工智能模型提供海量數據集。
而推理是人工智能訓練之後的過程,模型訓練得越好,調整得越精細,其推理就越準確,能在商業場景跑通的國產卡,遠比訓練要多。下游推理模型和應用,都處於劇烈變動的戰國時代,而處於上游的計算體系架構,也完全沒有定型。
AMD表示到2027年其4000億美元AI加速器TAM中約65-70%將用於推理,英偉達也表示推理需求的增長開始迅速加速,有可能年增40%。
這對國產的雲推理服務託管商,以及推理卡的應用來説是一個巨大的機會。
目前美國商務部的底線思維依然是卡你的硬件,我們也需要承認AI目前的階段是硬件推着應用走,但可以預見,未來推理的應用會推動着芯片往前走。一旦出現AI超級應用,用場景定義芯片,就會有ASIC替代通用高算力GPU的可能,這也是中國AI產業的破局底氣所在,畢竟,中華大地是一片數據和應用場景的原始豐饒之地。
算力、存力和運力三者合一,讓中國大陸目前聚焦的近存計算和存算一體也大有可為。
之所以英偉達的NVLink協議具有較高的傳輸效率,重要原因之一是它在解決擁塞的時候有一套完整的方案。從芯片到集羣,本身就是一個大系統。以存儲架構為例,它正迎接一場顛覆傳統的跨越式創新,隨着高速網絡、RDMA、NVMe等技術的發展,以及數據池化、湖倉一體化趨勢的深入,文件、對象、大數據的多協議融合部署需求快速增長。
數據中心技術棧的生態建設(@燧原科技)
通過統一的大模型技術生態棧解決算力瓶頸問題目前成為了行業的共識,也能有效應對美國的硬件圍堵。
其實,美國這次的AI巨型管制框架暴露了其柔弱和畏葸的一面——這一點已經被英偉達看穿了,他們在新聞稿的最後表示:“美國通過創新、競爭和與世界分享技術而贏得勝利,而不是躲在政府越權的高牆後面。”
美國商務部的“畫地為牢,作繭自縛”這八個字,會在2025年及其以後的歷史畫卷中逐漸應驗。

本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。