“神秘的東方力量”,DeepSeek飆升至美區蘋果應用榜第三
戴佳源“实习中”

觀察者網注意到,截至北京時間1月26日晚22時——僅不到半天的時間內,國產AI DeepSeek(深度求索)在美區蘋果App Store的免費排行榜中已一路從第六位飆升至第三位,僅次於ChatGPT及Meta公司旗下的社交媒體平台Threads,超越Google Gemini、Microsoft Copilot等美國科技公司的生成式AI產品。

截止北京時間26日晚10時左右,國產AI DeepSeek已升至美區蘋果應用榜第三
同在1月26日,DeepSeek出現了短時閃崩現象。不少網友反映,使用時遇到 “服務器繁忙” 的提示。
對此,DeepSeek回應稱,當天下午確實出現了局部服務波動,但問題在數分鐘內就得到了解決。此次事件可能是由於新模型發佈後,用户訪問量激增,服務器一時無法滿足大量用户的併發需求。不過,官方狀態頁並未將這一事件標記為事故。
近日,DeepSeek在中國、美國的科技圈受到廣泛關注,甚至被認為是大模型行業的最大“黑馬”,在外網,DeepSeek被不少人稱為“神秘的東方力量”。
DeepSeek,全稱杭州深度求索人工智能基礎技術研究有限公司,成立於2023年7月17日。公司由知名量化資管巨頭幻方量化創立,專注於開發先進的大語言模型(LLM)和相關技術。
據介紹,此前DeepSeek在美區榜單的排名並無特別突出表現,處於穩步上升階段,但未進入前十。此次突然躥升,與其近期一系列突出表現有直接關係。

Deepseek(資料圖) 金融時報
去年年底,DeepSeek推出開源模型DeepSeek-V3。當時,聊天機器人競技場(Chatbot Arena)數據顯示,DeepSeek-V3在所有模型中排名第七,在開源模型中排第一,是全球前十中性價比最高的模型。
DeepSeek-V3大模型的核心技術創新是其迅速崛起的關鍵。該模型融合了Multi-head Latent Attention(MLA)、混合專家架構(MoE)和FP8低精度訓練三項技術,顯著提升了性能與效率。
而在本月20日,DeepSeek又正式開源R1推理模型。1月24日,DeepSeek-R1在Chatbot Arena綜合榜單上排名第三,與OpenAI的頂尖推理模型o1並列。在高難度提示詞、代碼和數學等技術性極強的領域,DeepSeek-R1拔得頭籌;在風格控制以及高難度提示詞與風格控制結合的測試中,DeepSeek-R1均與o1 並列第一。
此外,Artificial-Analysis的初始基準測試結果顯示,DeepSeek-R1在AI分析質量指數中取得第二高分,但價格卻是o1的約三十分之一。
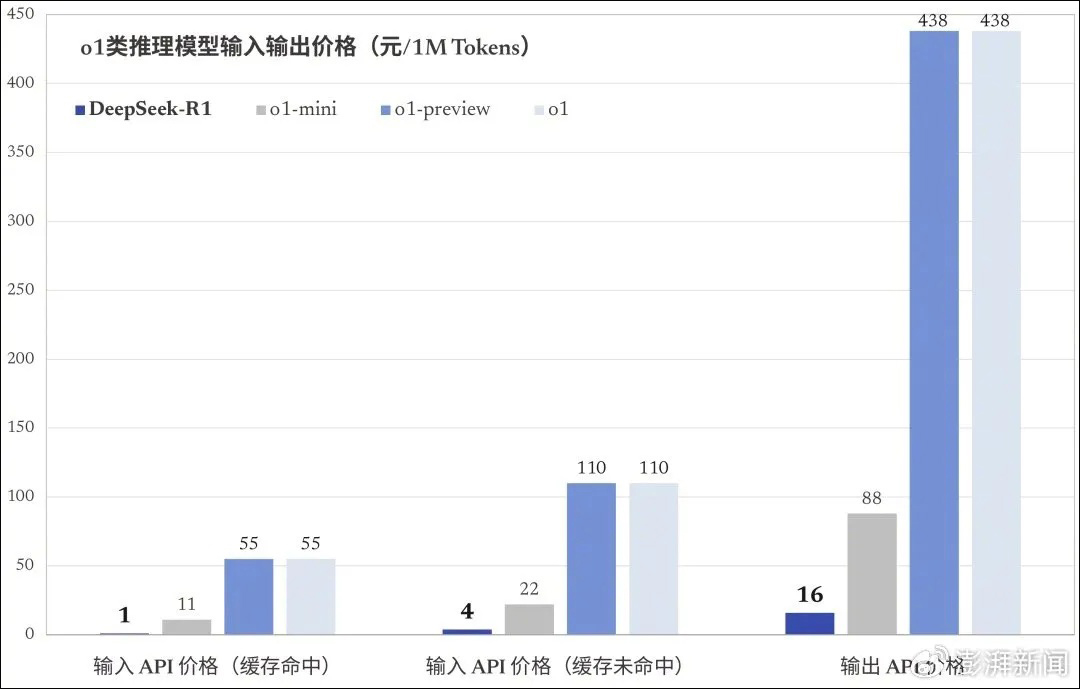
DeepSeek-R1 API價格 圖源:澎湃新聞
DeepSeek以“低成本訓練”和“高性價比”為核心賣點,其API輸入價格僅為每百萬Token 0.1元人民幣,遠低於Claude 3.5 Sonnet(3美元/百萬Token),吸引了不少中小開發者和企業。這種低成本訓練策略也讓該公司有了“AI界拼多多”的稱號,甚至引發了間接衝擊英偉達等硬件廠商的討論。
英偉達高級研究科學家Jim Fan就在個人社交平台上公開發表推文表示:“我們正身處這樣一個歷史時刻:一家非美國公司正在延續OpenAI最初的使命——通過真正開放的前沿研究賦能全人類。看似不合常理,但最有趣的結局往往最可能成真。”
此外,1月24號,一條發佈在匿名平台teamblind上的帖子瘋傳。一名Meta員工稱,現在Meta內部因為DeepSeek的模型,已經進入恐慌模式。
這位Meta員工寫道:
“一切源於DeepSeek-V3的出現,它在基準測試中已經讓Llama 4相形見絀。更讓人難堪的是,一家‘僅用550萬美元訓練預算的中國公司’就做到了這一點。
工程師們正在爭分奪秒地分析DeepSeek,試圖複製其中的一切可能技術。這絕非誇張。
管理層正為GenAI研發部門的鉅額投入而發愁。當部門裏一個高管的薪資就超過訓練整個DeepSeek V3的成本,而且這樣的高管還有數十位,他們該如何向高層交代?
DeepSeek-R1的出現讓情況更加嚴峻。具體細節屬於機密,不便透露,不過很快就會公開了。”
(觀察者網綜合 九派新聞 每日經濟新聞、證券時報、澎湃新聞、界面新聞等)
本文系觀察者網獨家稿件,未經授權,不得轉載。