繼DeepSeek後,阿里雲通義千問也追上OpenAI
连政guanchazhewanxgun

中國不僅有DeepSeek,還有通義千問。
阿里雲通義團隊於大年初一發布旗艦模型“Qwen2.5-Max”,已成為繼深度求索(DeepSeek)後,第二家可以比肩美國OpenAI公司o1系列的中國大語言模型。

近日,三方基準測試平台LMArena的大語言模型盲測榜單(“ChatBot Arena LLM”)最新排名顯示,“Qwen2.5-Max”以1332分排總榜第7名,超過了深度求索的“DeepSeek-V3”以及OpenAI的“o1-mini”。而在數學和編程方面,“Qwen2.5-Max”則排名第1,在Hard prompts方面排名第2。
“ChatBot Arena LLM”榜單由美國加州大學伯利克分校天空計算實驗室與LMArena聯合開發,通過用户盲測的方式,覆蓋了對話、代碼、圖文生成、網頁開發等多維度能力評估,最終基於260萬票結果反映出197個模型在真實體驗下的排名情況,也是業內公認的權威榜單。
該榜單最新的更新時間為當地時間的2月2日,其中OpenAI的多個版本模型佔據高位,比如第3位的“ChatGPT-4o”,同時還有谷歌的“Gemini-2.0”、xAI的“Grok-2”等,但這些模型均為閉源模型。

而在開源模型方面,“DeepSeek-R1”一騎絕塵,與“ChatGPT-4o-latest”並列榜單第3,緊隨其後的就是排名第7的阿里雲通義“Qwen-max-2025-01-25”(即Qwen2.5-Max),“DeepSeek-V3”和中國智譜模型“GLM-4-Plus-0111”則分別排名第8、第9,而階躍星辰的“Step-2-16K-Exp”模型則與“o1-Mini”並列第10。榜單前10名中有5箇中國大語言模型,也體現出中國人工智能團隊在全球範圍內的強技術競爭力。
去年6月、9月,阿里雲通義模型也曾兩度登頂全球最強開源模型的寶座,但由於未能追平超越閉源模型,討論熱度不及12月的DeepSeek-V3。今年1月29日凌晨1時,阿里雲通義團隊正式對外發布“Qwen2.5-Max”,該模型採用超大規模混合專家(MoE, Mixture of Experts)架構,訓練數據超過20萬億tokens,並在知識(測試大學水平知識的MMLU-Pro)、編程(LiveCodeBench)、全面評估綜合能力的(LiveBench)以及人類偏好對齊(Arena-Hard)等主流權威基準測試上,展現出全球領先的模型性能。

值得注意的是,“Arena-Hard”項主要測試模型在複雜指令理解和多輪對話中的表現,涵蓋了各種領域的知識和任務,並且打分的時候要嚴格對齊人類偏好。其中,對遊戲開發、數學證明等專業項會給予較高分數,而對類似全球餐廳推薦、送禮創意等答案會出現模稜兩可情況的問題給予較低權重,“評委”則通常也由國外模型擔當。而這種情況下,“Qwen2.5-Max”在該基準測試中仍能夠迅速分析問題,整合相關知識,給出全面且準確的回答,最終以89.4分超越全部對比模型(DeepSeek-V3、Llama-3.1-405B-Inst、GPT-4o-0806、Claude-3.5-Sonnet-1022)。
據阿里雲稱,由於無法訪問“GPT-4o”和“Claude-3.5-Sonnet”等閉源模型的基座模型,通義團隊將“Qwen2.5-Max”與目前領先的開源MoE模型“DeepSeek V3”、最大的開源稠密模型“Llama-3.1-405B”,以及同樣位列開源稠密模型前列的“Qwen2.5-72B”進行了對比。在包括MMLU等所有11項基準測試中,Qwen2.5-Max全部超越了對比模型。
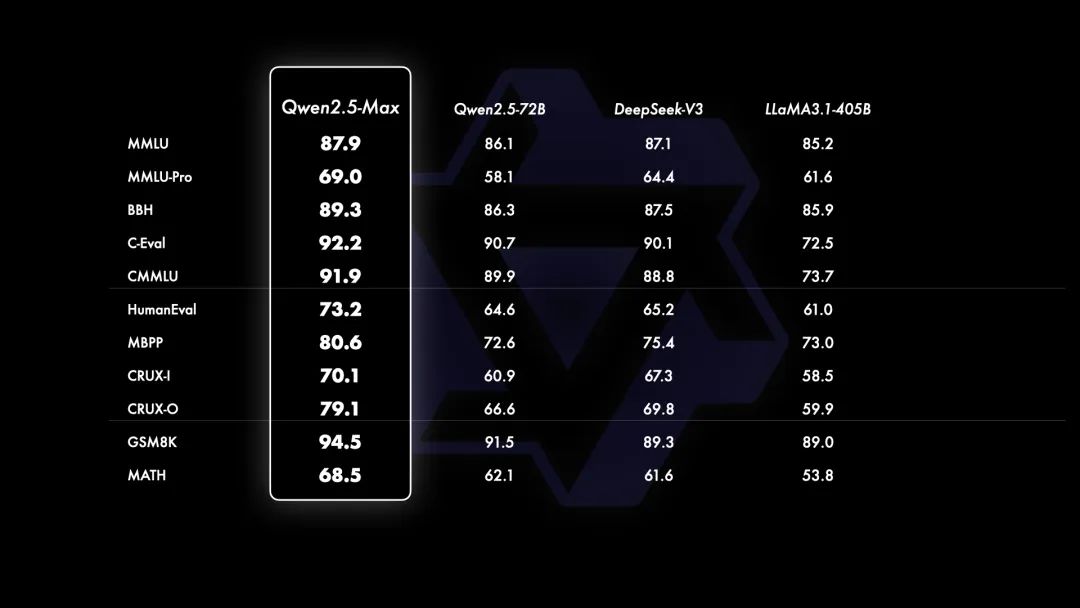
對此,ChatBot Arena官方給出評價:“(Qwen2.5-Max)在多個領域表現強勁,特別是專業技術向的(編程、數學、硬提示等)。”
本文系觀察者網獨家稿件,未經授權,不得轉載。