潘攻愚:從四個角度全面駁斥美方對DeepSeek的質疑和污衊-心智觀察所、潘攻愚
guancha
【文/觀察者網專欄作者 潘攻愚】
DeepSeek“小扣發大鳴”,半年多的時間,不但從LLM通用模型的V2迭代到了V3,而且進一步推出了主打推理能力的R1模型。從訓練成本、架構調整和開源模式等多個維度技驚全球,引發了一股山呼海嘯般的讚譽。春節期間大洋彼岸資本市場的大幅震盪以及開年後國內“DeepSeek概念股”的大漲,讓這一現象持續成為坊間熱議的焦點。
DeepSeek的成功,順應了pre-training到推理的AI大模型的必然演化過程。DeepSeek的崛起為何是順天應時之舉?不妨先來看兩段話。
去年2月下旬,英偉達CEO黃仁勳接受美國科技媒體Wired採訪時説:“英偉達今天的業務可能是40%的推理和60%的訓練,這是一件好事,因為這讓你意識到AI終於成功了。如果英偉達的業務是90%的訓練和10%的推理,你可以説AI仍處於早期研究階段。”
去年12月,OpenAI的CFO Sarah Friar在接受科技媒體《信息》(The Information)採訪時説:“OpenAI的ChatGPT Pro開放給C端用户的套餐每月200美元,實在是太便宜了,它合理的價格應該是每月2000美元。”進一步結合她上下文采訪的言外之意,她主要是説OpenAI“心善”,秉承一股AI為大眾平權服務的道義感,才沒把價格搞得那麼高。今天,他們這種偽善的畫皮在DeepSeek R1開源模型面前徹底被撕下。
這兩段話相當有代表性,一個指向AI技術應用的演進方向,一個則事關AI推訓模式落地的商業化問題,這兩個層面的問題相互纏繞,互為表裏。
就在OpenAI牽頭搞“星際之門”,將算力的Scale Law延伸到了民間資本市場和國家投資領域,試圖把AI產業和美國國運綁定之時,DeepSeek對其做了一個釜底抽薪式的敍事消解。
眾聲喧譁之下,來自大洋彼岸的質疑,甚至是帶有惡意性質的詆譭同樣值得關注。
分析美國AI大模型行業某些頭面人物帶有驚慌失措心理的評論,可以進一步深化我們對DeepSeek到底真正打到了對方哪些痛處的認知。大洋彼岸的詳細分析數據和質疑聲音,以知名半導體諮詢機構Semianalysis總裁Dylan Patel和Anthropic的CEO Dario Amodei為代表性,這兩家的文章在中文互聯網世界被翻譯後大量轉載。

Anthropic的CEO Dario Amodei
他們主要從GPU囤貨、成本測算、非技術性營銷、以及模型數據蒸餾不合規等四個角度,試圖告訴公眾DeepSeek的突破其實沒那麼“硬核”。
一、搖唇鼓舌DeepSeek囤貨“敏感性”高端GPU
按照Semianaylsis的測算,“DeepSeek大致擁有10000張H800 GPU芯片、10000張H100 GPU芯片,以及大量H20 GPU芯片”。
Dario Amodei在長文中轉述了Semianaylsis的測算,認為DeepSeek手上擁有的用於訓練和推理的Hopper架構的英偉達GPU卡(閹割版和非閹割版都算在內)差不多有5萬張,這個量和美國主要頭部的AI模型訓練機構如OpenAI、Deepmind等差距在兩三倍左右,結合基於合成數據(synthetic data generation)和強化學習進行推理能力提升的後訓練(post-training)方法,他認為DeepSeek本來就站在巨人的肩膀上,又用了巨量的GPU,才有了今天的成果。
為什麼Dario Amodei要用Semianaylsis的數據給自己拉大旗扯虎皮呢?
因為Dario Amodei心中有一個所謂的AI訓練成本的“摩爾定律法”——每一年大約能降三到四倍,如果用強化學習的方法進行推理架構調整,可以把成本降到六至八倍,但這個就是降成本的極限了。按照這種成本測算假説推斷,DeepSeek有五萬張Hopper卡。
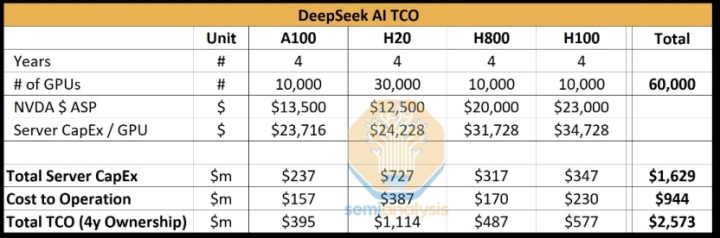
那麼,如果我們進一步追問,Semianaylsis認為DeepSeek手上有這麼多高端GPU卡,他們是怎麼算出來的?他們採用了一種類似歸謬法的推理:Anthropic單單訓練一個Claude 3.5 Sonnet的成本就高達數千萬美元,如果DeepSeek有如此神之一手能強力降本,Anthropic何必煞費苦心去找亞馬遜融資數億呢?
有關Anthropic到底是怎麼花費投資人的錢的問題,也許馬斯克手下的DOGE(政府效率部)更有興趣回答。相比微軟、谷歌一派,代表雲服務商亞馬遜一派的Anthropic CEO按耐不住跳出來寫長文的主要原因之一,是深刻覺察到在十萬到百萬級GPU基礎上的生態進行推訓,他們的Claude系列總價格是最高的,總性價比也是最低的。
DeepSeek合法擁有的H800,相比H100,主要是閹割了NVLink的通信帶寬;H20雖然也是閹割版,單卡算力僅有H100的20%,但H20可以通過多卡堆疊模式,其HBM容量(96GB)甚至高於A100/H100(80GB)。換言之,H20的顯存帶寬可以讓DeepSeek的Decode階段每生成1個Token所需時間低於A100和H100。
DeepSeek把閹割版用出了禁運版所沒有的功效,讓Dario Amodei居然發出了應該對中國大陸進一步加強GPU管制的惡意言論,這也許才是他抨擊DeepSeek的目的。
從話語體系上講,Semianalysis用Anthropic缺乏公允性的AI模型訓練成本反推DeepSeek有可能繞開管制,非法持有高端GPU,而Anthropic反過來用Semianalysis建立在沙堆之上的推論來論述DeepSeek在成本問題上並無過人之處,這其實是一個合謀式的循環論證。
二、DeepSeek隱藏了總成本(TCO)參數?
Semianalysis和Anthropic對DeepSeek總成本的推斷,還涉及到除了GPU採購之外的因素,諸如優化架構、處理數據、支付員工薪資等等,而這恰恰是我們最不太需要花費心思去反駁的。
通常意義上,H100的雲租賃成本不包括電力成本,在數據中心實際託管的IT設備的成本與佔地面積、園區環境和政策支持密切相關。
從未到中國進行過實地調研的Semianalysis,依據美國行情判斷DeepSeek的API服務成本也是欠妥當的。
美國本土的雲服務和大模型部署合作也相當複雜。與OpenAI自己的API相比,更多客户選擇了微軟進行公共和私有實例的推理,微軟當年非常聰明地用自己的雲服務積分置換對OpenAI的“天使輪投資”;而亞馬遜喜歡把他們的SageMaker平台説成是客户在雲上創建、訓練和部署模型的好工具,但自己卻用英偉達的Nemo雲原生框架代替Sagemaker,來開發他們的模型。
相比Semianalysis對DeepSeek R1模型通過MLA(Multi-head Latent Attention)優化KV Cache機制的分析,他們對DeepSeek託管、運維和員工薪資的分析更像是一種臆測。
三、DeepSeek贏在了營銷?
相比缺乏紮實一手調研和推論依據的成本估算,更讓人匪夷所思的是,無論是Semianalysis還是Dario Amodei都用了不少的篇幅闡述了DeepSeek的“營銷”手段,包括但不限於R1模型在實戰中會首先向用户展示推理的思路框架,以及DeepSeek R1故意把發佈時間踩點特朗普就職典禮等等。Semianalysis總裁Dylan Patel在近日的視頻節目中,更是指出DeepSeek的營銷勝在一個“快”上,比如説半年多以前急於推出成熟度欠奉的V2模型,意在炒作。
無利不起早的海外大廠已經用實際行動反擊了這種“營銷”説:從1月25日到2月1日,AMD的MI300X GPU、英偉達NIM微服務、英特爾Gaudi 2D Al加速器,均紛紛表示支持和接入DeepSeek V3/RI/Janus模型。如果DeepSeek沒有展示出足夠的技術實力,這些大廠為何要配合DeepSeek“營銷”呢?
Semianalysis可能忽視了一個事實:2022年年底OpenAI急於推出的ChatGPT就是走了先佔坑位然後再調試的路線,谷歌的Bard(現在已經改名Gemini)晚了一步被OpenAI搶了先手,就在於其創始團隊擔憂這種聊天機器人會搶奪搜索引擎市場從而影響谷歌營收,畢竟對谷歌來説,依靠搜索引擎導入的廣告收入佔了大頭。
這一次,OpenAI在壓力之下推出了全新的免費o3-mini(有趣的是,o3也在模仿R1展示推理思維鏈),可見“創新者困境”的魔咒和營銷無關,這是一種湧浪式的推陳出新競爭法,指責DeepSeek以快取勝是毫無道理的。
從另一個層面上看,為什麼OpenAI以及Anthropic的同推理模型不展示具體的推理思路呢?展示推理鏈路真的是一種營銷嗎?
OpenAI和Anthropic冠冕堂皇的理由是優化用户體驗界面,避免信息過載。但這個問題其實觸及到這幾家公司深層次顧慮,一方面是模型的內部工作機制(如微調策略、特定任務的優化方法)可能會讓競爭對手進行逆向工程,而且保持黑盒化的推理過程也避免了外界過分渲染這些工具的黑歷史——從一開始,ChatGPT就很有爭議性地不斷爬取《紐約時報》、《華爾街日報》等公眾媒體和數據資源進行語料訓練,其合規性經營一再遭受質疑,並一度走到法律訴訟層面。

由此可見,OpenAI、谷歌和Anthropic這些本來通過營銷起家的AI模型公司無法效仿DeepSeek所謂的“營銷大法”,非不為而實不能。
結語:模型蒸餾是DeepSeek給全人類的美好饋贈
Semianalysis總裁Dylan Patel和Anthropic 的CEO Dario Amodei對DeepSeek評述還有一個共性,就是認為R1遠不如V3有趣,其主要論據是R1很可能用了模型蒸餾。
在保證模型性能與效率的同時,推動AI技術的普惠化,將其變為水和電一樣的公共產品,模型數據蒸餾和用户知識蒸餾是一種必然之路,它不僅優化了資源利用,加速模型向本地部署和端側推理遷移,對構建可持續、高效的AI生態具有重要意義。
OpenAI團隊創立就是對谷歌AI商業化路線的一種逆反,奧爾特曼和馬斯克當時秉承了一種為全人類尋找AGI途徑的願景才取了“OpenAI”這個名字,如今OpenAI變成“CloseAI”其實已經偏離了初心。
Dario Amodei抨擊DeepSeek搞蒸餾有侵犯知識產權風險。但如前所述,這幾家美國大廠都是吃到了數據時代紅利,在《紐約時報》反應過來要搞法律訴訟之前先把語料數據“竊取”了過去,吃下去怎麼可能再吐出來?
曾幾何時,艱深晦澀的AI技術曾是學院派們的禁臠。英偉達的CUDA軟件開發者系統平台,當初讓先驅者們有機會在商業市場中一試身手。很快,AI的重心從斯坦福大學、多倫多大學和加州理工等轉移到了初創公司中。
辛頓和李飛飛加入了谷歌,吳恩達去了百度,奧爾特曼和他鬧宮斗的蘇茨克維等等一起創辦了OpenAI,他們一起把AI帶向了公眾視野。
一切的AI生產要素的流動,其實是一種人才、軟硬件技術以及資本市場的變相“蒸餾”。本來就是脱胎自OpenAI的Anthropic也是用户知識蒸餾的最大受益者。
前一段時間李飛飛團隊“50美元”復刻DeepSeek-R1,此舉恰恰藴藏着梁文峯們的美好願景——推動知識與信息的平權,AI應成為造福全人類的公共產品。

本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。