熊節、塞爾吉奧·阿馬德烏:DeepSeek為什麼要開源?這可能與人工智能的領導權息息相關
guancha
【文/觀察者網專欄作者 熊節、塞爾吉奧·阿馬德烏】
人工智能領導權之爭——中國與開源
為什麼技術領導權如此重要?如何定義人工智能(AI)領域的技術領導權?人工智能是一項橫跨多個領域的技術,其進步會對經濟、社會和國家安全產生深遠影響。技術領導權首先提供了一系列競爭優勢,因為發明和創新賦予開發者其他人所不具備的收益和利益。其次,技術領導權是一個關鍵的地緣政治因素,因為它能夠影響全球標準、規範和法規的制定。第三,技術領導權可以推動創新生態系統的形成,鞏固長期發展。第四,領導權可以在國際威脅(包括軍事威脅)的背景下增強安全性。第五,領導權能夠引導技術發展,以實現社會、環境和政治目標。
從技術政治的角度來看,技術科學並非中立,它對權力關係和社會組織具有深遠影響(Winner,2020)[1]。人工智能的領導權不僅僅是開發最先進的技術,還包括創建一個能夠實現更廣泛社會價值和目標的社會技術環境,確保創新遵循特定的目的。人工智能的發展軌跡可能會優先考慮提高經濟系統的生產力,或者旨在尋找社會公正和環境可持續的解決方案。它可能尋求集中權力並加強國際不對稱性,或者促進知識的傳播和公平發展。它可能抑制人口和文化的創造力,或者確保技術多樣性。它可能與權力的集中或分散密切相關。
目前,人工智能的領導權掌握在美國手中,主要由所謂的“科技巨頭”主導。這些公司控制着開發現有人工智能(尤其是以深度學習為主導的人工智能)不可或缺的資源。
我們都知道,深度學習方法基於統計學和概率學,用於從大量數據中分類和提取模式。為了執行這些操作,人工智能開發者依賴於強大的計算能力。訓練一個像ChatGPT這樣先進的人工智能模型需要數百萬美元,並且需要大量時間使用專用硬件進行處理,例如專為這些任務設計的芯片。這些芯片被稱為“AI推理芯片”或“推理加速器”,它們能夠在更短的時間內取得更好的結果。例如,谷歌的Tensor Processing Units(TPUs)專為推理和訓練優化;神經處理單元(NPUs)或神經網絡加速器常用於移動設備和邊緣計算;圖形處理單元(GPUs)則用於訓練和推理。
目前,這些芯片對於圖像識別、自然語言處理和其他即時人工智能任務至關重要。
美國政府長期以來一直採取限制尖端芯片獲取的政策,主要目的是延緩中國和其他被視為對手國家的AI發展,目標是保持美國在AI領域的領導地位。隨着唐納德·特朗普於2025年1月就職,技術封鎖政策進一步加劇。此外,美國總統宣佈了一項5000億美元的“星際之門”項目投資。特朗普的計劃是與甲骨文、OpenAI和軟銀等公司合作,在美國開發物理和虛擬的AI基礎設施,以“推動下一代AI的發展”[2]。英偉達、Arm和微軟等公司是該項目的合作伙伴,該項目已在德克薩斯州開始實施,並將在未來四年內在美國各個地區建設“巨型數據中心”[3]。
以埃隆·馬斯克為代表的美國科技精英認為,人工智能正在接近“奇點”——即人工通用智能(AGI)的出現。他們聲稱,AGI將完全超越並取代人類在所有智力領域的勞動,如果美國率先實現AGI,其技術霸權將不可撼動。然而,無論是ChatGPT還是DeepSeek,都沒有顯示出接近AGI的跡象。它們是處理自然語言的有用工具,並在特定領域展示了有限的推理能力,但沒有證據表明它們——或任何已知的AI研究——正在接近AGI。
AGI比起一般的AI擅長以更像人類的方式去執行任務
開源的轉折點
2024年5月,一家名為DeepSeek的中國小公司推出了其大型語言模型(LLM),該模型受到Llama的啓發,Llama是一個禁止商業使用的受限研究協議下的模型。開源模型DeepSeek V2的突出之處在於其前所未有的成本效益。DeepSeek將推理成本降低至每百萬個token僅1元人民幣,約為Llama3 70B的七分之一,遠低於GPT-4。
Token是語言模型用於處理和理解人類語言的基本文本單位,根據上下文和語言,token可以被視為單詞、音節甚至單個字符的“塊”。AI模型將文本轉換為token,並以數字形式表示。這些數字隨後由模型處理以生成響應或執行任務。因此,文本中的token數量直接影響成本和處理時間。token越多,推理越複雜且耗時。
與所有中國公司一樣,DeepSeek也受到美國政府尖端芯片封鎖的限制。這促使DeepSeek的領導者及其團隊更加專注於研究和優化。梁文鋒在2024年7月的一次採訪中表示:“我們的出發點不是抓住機會發財,而是推進到技術前沿,以促進整個生態系統的發展。”[4] 這家中國公司試圖引領AI發展的意圖顯而易見。為了實現這一目標,DeepSeek並沒有侷限於組織數據並在現有云平台上運行。團隊努力在尖端芯片稀缺的情況下尋找解決方案。這需要改變架構、嘗試新程序以及廣泛的應用數學。
DeepSeek的年輕領導者梁文鋒表示:“我們在創新方面缺乏的絕對不是資本,而是信心和如何組織高密度人才以實現有效創新的知識。”[5] 他繼續説道:“創新並不完全由商業驅動,還需要好奇心和創造力。我們陷入了過去的慣性,但這也是暫時的。”[6] 梁文鋒的理念是減少模仿,增加研究。他主張押注開源模型,不是為了使用它們,而是為了改進它們,並找到需要更少計算資源的路徑。
開源是DeepSeek戰略的核心,但對騰訊、百度和阿里巴巴等其他中國公司來説可能並非如此。然而,開源允許知識在全球範圍內傳播,從而以更快、更包容的速度產生新發現的可能性。梁文峯表示:“實際上,開源和論文的發表並沒有損失。對於技術團隊來説,被追隨是一種巨大的成就感。事實上,開源更像是一種文化行為,而不是商業行為,因為給予實際上是一種額外的榮譽,這樣做的公司也會更具有文化吸引力。”[7]
開源不是一種技術,而是一個基於知識共享的開發過程。通常,它鼓勵組織願意協作解決問題並通過更新維護解決方案的社區。像Mistral 7B(Mistral AI)和Falcon(技術創新研究所)這樣的語言模型是開源的,並在Apache 2.0許可下發布;強化學習模型Stable-Baselines3也是開源的,採用MIT許可證。
那麼,為什麼DeepSeek的模型如此重要?因為它顛覆了全球AI領導權的競爭。如何做到的?通過大幅降低大型語言模型的計算成本。
開源對於知識傳播至關重要,但並不能解決訓練和運行模型所需的計算基礎設施問題。DeepSeek展示了一個高性能且處理需求較低的開源模型。
DeepSeek-R1已經展示了比OpenAI的ChatGPT o1更強的推理能力,而其成本(包括訓練和使用)顯著降低。通過開源其模型,DeepSeek促進了大型語言模型的民主化——使技術基礎設施欠發達的小公司、國家甚至個人能夠基於DeepSeek訓練自己的“主權AI”,而無需依賴科技巨頭的產品或將數據交給這些公司。印度尼西亞和印度已經開始使用DeepSeek作為基礎構建自己的AI基礎設施[8]。在此之前,只有美國和中國有能力訪問如此高水平的大型語言模型。
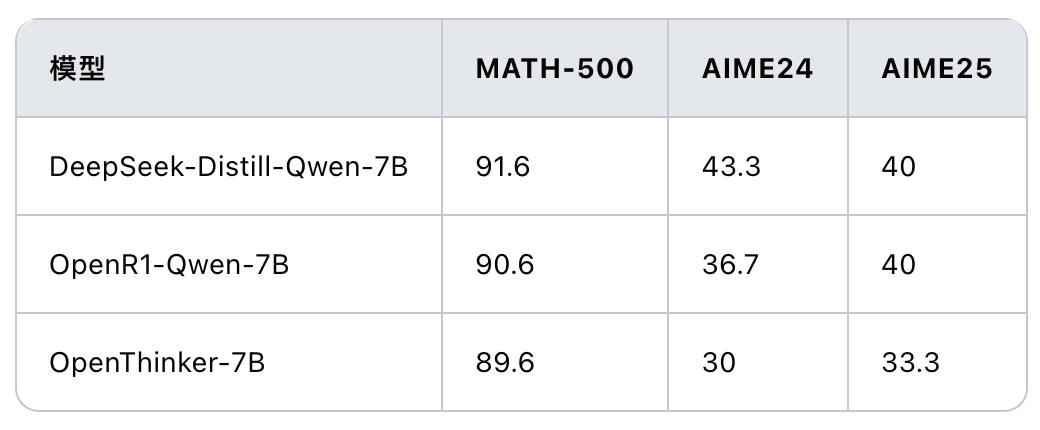
上表展示了在lighteval上OpenR1-Qwen-7B、DeepSeek-Distill-Qwen-7B和OpenThinker-7B的性能對比,可以看出在數學成績上,OpenR1-Qwen-7B和DeepSeek-Distill-Qwen-7B差距不是非常明顯。36氪
DEEPSEEK R1對強化學習的押注
“DeepSeek-R1-Zero選擇了一條前所未有的路徑,即‘純’強化學習路徑,完全放棄了預定義的思維鏈(CoT)模型和監督微調(SFT),僅依靠簡單的獎勵和懲罰信號來優化模型的行為。”[9]
在騰訊團隊對DeepSeek R1模型的分析中,他們提出可能需要重新思考監督學習在AI發展中的作用。或許他們過於專注於讓AI模仿人類的思維方式,而不是更多地押注於強化學習系統本身的解決問題能力[10]。在強化學習中,獎勵和懲罰以數學方式表達在模型中。代理(可以是算法或系統)根據策略做出決策,該策略旨在最大化隨時間累積的獎勵。獎勵是代理在環境給定狀態下執行操作所獲得的數值。
機器學習是人工智能的一個領域,它使計算機能夠識別模式並根據數據做出決策,而無需明確編程[11]。機器學習依賴於從大量數據中提取模式並調整其參數以隨時間提高預測能力的算法。這些算法可以分為三大類:監督學習(模型從標記數據中學習)、無監督學習(模型在沒有預定義標籤的情況下識別模式)和強化學習(模型通過試錯學習,根據其行為獲得獎勵或懲罰)。深度學習是機器學習的一個子集,它使用具有多層的人工神經網絡以分層和複雜的方式處理數據[12]。
由於這些創新,DeepSeek R1的訓練成本大幅降低,僅為ChatGPT成本的1/10到1/20。當OpenAI的模型花費20美元時,DeepSeek僅用1美元就完成了相同的任務。2025年1月,DeepSeek模型的成本僅為每百萬token 16元人民幣,而ChatGPT的成本高達438元人民幣——相差27倍![13] 這意味着組織可以以更低的成本使用DeepSeek的模型,同時實現更高的效率。
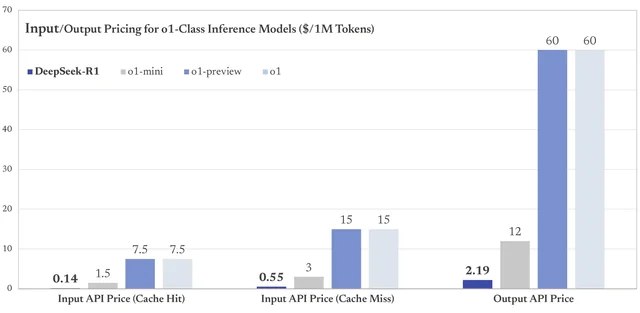
不同AI模型的Token輸入/輸出價格(美元/每百萬Tokens),可以看到DeepSeek的價格遠低於其他AI模型Reddit
計算能力與AI的地緣政治
英偉達和其他科技巨頭股價的暴跌被許多人視為美國在AI領域領導地位的終結,這似乎並不準確。這家強大的GPU製造商的股價大幅下跌是由於在DeepSeek成功開發出成本僅為OpenAI 10%的大型語言模型的消息傳出後,大量股票被拋售。這可能會改變AI的發展軌跡。對高處理能力芯片的依賴可能會發生變化。基於這種推理和恐懼,投機者趁機拋售了他們在英偉達和其他公司的股票。
然而,對尖端芯片的依賴並沒有因為中國的創新而結束。小於2納米的芯片代表了人工智能的關鍵進步,它們確保了更高的處理能力和更低的能耗。隨着AI模型變得越來越複雜,需要數十億甚至數萬億的參數,計算效率仍然是一個關鍵因素。更小的芯片允許更高的晶體管密度,提高計算速度和能源效率,降低運營成本和冷卻需求。這一演進對於AI的大規模實施至關重要,從數據中心到移動設備,包括軍事應用。
值得注意的是,納米芯片擴展了設備中的嵌入式應用,並促進了它們在物聯網、醫療保健、機器人和自動駕駛汽車中的使用。另一個承諾是,隨着芯片變得更先進、體積更小,AI模型可以在本地運行,減少對雲的依賴,並確保更快、更安全的響應。在地緣政治背景下,對更小芯片的競爭加劇了美國和中國等大國之間的技術爭端,因為對這一技術的控制定義了數字經濟和網絡安全領域的競爭力。
美國通過技術主導、戰略投資和供應鏈控制的結合,保持了在芯片和半導體開發和製造領域的領導地位。英偉達、英特爾、AMD和高通等美國公司引領着先進芯片的設計。美國政府通過補貼和激勵措施(如《芯片與科學法案》[14])加強其地位,該法案撥款數十億美元用於加強國內半導體生產,減少對亞洲的依賴。
除了技術優勢外,美國還利用制裁和出口管制來限制戰略競爭對手(如中國)獲取關鍵技術。商務部對先進半導體制造設備(如ASML的機器和Cadence、Synopsys的芯片設計軟件)的出口實施嚴格限制。這些限制使中國難以開發自己的先進芯片,並鞏固了美國在該領域的地位。同時,華盛頓投資於戰略聯盟,如“芯片四方聯盟”(與日本、韓國和中國台灣地區),確保其盟友遵循美國的指導方針,限制技術轉讓給被視為競爭對手的國家。這一綜合戰略使美國能夠保持其在半導體行業的霸權,這對數字經濟和國家安全至關重要。[15]
儘管美國正在盡一切努力限制中國獲取先進芯片(7納米以下)及其生產能力,但中國正在不斷發展其獨立製造這些高端芯片的能力。中芯國際(SMIC)已經展示了生產7納米芯片的能力,並被認為很可能能夠生產5納米芯片[16]。上海微電子裝備(SMEE)等公司正在積極開發極紫外(EUV)光刻技術,以取代ASML壟斷的光刻機[17],這些光刻機已被限制向中國銷售。
另一方面,在汽車和工業領域使用的成熟工藝芯片(技術並非最尖端但需求顯著更高)方面,中國的芯片產業已經建立了大規模且完整的產業鏈。2024年,中國芯片出口總額超過1萬億元人民幣(約合1390億美元)[18]。可以預見,一旦中國公司在先進工藝上取得技術突破,其現有的供應鏈優勢將顯著降低高端芯片的價格。此外,芯片工藝受到物理極限的限制,無法無限改進。中國趕上美國只是時間問題。

美國前總統喬·拜登於2022年8月9日簽署2022年《芯片法案》路透社
結論
“英偉達的領導地位不僅僅是一家公司努力的結果,而是整個西方技術社區和行業共同努力的結果。他們能夠看到下一代技術趨勢,並擁有路線圖。中國的AI發展也需要這樣的生態系統。許多國內芯片由於缺乏支持技術社區和二手信息而無法發展,因此中國需要站在技術前沿的人。”(梁文峯,2024)[19]
DeepSeek的創始人梁文峯表示:“我們面臨的問題從來不是資金,而是對尖端芯片的禁令。”[20] 即使數據集中化和對計算能力需求(需要越來越複雜的芯片)的趨勢發生變化並失去動力,國際資本主義似乎也不會改變其根本的不對稱性。毫無疑問,中國的技術科學發展使技術依賴美國的國家能夠構建有利於其發展的戰略。擁有主權、可控的世界級大型語言模型曾經是美國和中國以外的國家——尤其是全球南方國家——無法企及的。現在,DeepSeek已經民主化了這項技術,為全球南方國家在這一領域開闢了新的可能性。同時,這也為這些國家的政府提出了新的任務和挑戰。
DeepSeek現象所指向的是開源對於加強國際協作鏈的重要性,這種協作鏈可以減少不平等和巨大的知識不對稱。然而,開源並不能解決建設主權基礎設施的問題,這些基礎設施對於地方和國家發展至關重要。因此,尋求改善其技術經濟地位的國家需要減少科技巨頭的權力,控制AI的基本輸入——尤其是來自其人口的數據——並投資於減少自動化系統在資本主義國家中產生的環境影響和勞動力不穩定的解決方案。押注於青年優質教育需要鼓勵技術多樣性,並將各民族的文化活力轉化為技術表達。
【本文葡萄牙語版收錄於即將在巴西出版的《人工智能,社會與階級》(AI, Society and Class)一書】
註釋:
[1]Winner, L. (2020). The whale and the reactor: A search for limits in an age of high technology. University of Chicago Press.
[2]https://startups.com.br/negocios/inteligencia-artificial/stargate-trump-anuncia-investimento-de-us-500-bi-em-projeto-de-ia/
[3] Idem.
[4]https://mp.weixin.qq.com/s/r9zZaEgqAa_lml_fOEZmjg
[5]https://mp.weixin.qq.com/s/r9zZaEgqAa_lml_fOEZmjg
[6]Idem.
[7]https://mp.weixin.qq.com/s/r9zZaEgqAa_lml_fOEZmjg
[8]https://www.lowyinstitute.org/the-interpreter/deepseek-diplomacy-disruption-dominance-data
[9]郝博陽. (2025, 23 de janeiro). 一文讀懂|DeepSeek新模型大揭秘,為何它能震動全球AI圈.騰訊科技.
Link:https://mp.weixin.qq.com/s/cp4rQx09wygE9uHBadI7RA
[10] Idem.
[11] Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
[12] Idem.
[13]https://mp.weixin.qq.com/s/GG7l2P9ZveZjsHbS0AJ7Rg
[14]https://www.congress.gov/bill/117th-congress/house-bill/4346
[15] Sutter, K. M., Sargent Jr, J. F., & Singh, M. (2023). Semiconductors and the CHIPS Act: The Global Context. Congressional Research Service (CRS) Reports and Issue Briefs.
[16]https://www.dw.com/zh/%E7%BE%8E%E5%9B%BD%E5%88%B6%E8%A3%81%E4%B8%8B-%E5%8D%8E%E4%B8%BA%E7%AA%81%E5%9B%B4%E7%9A%84%E7%A7%98%E5%AF%86%E6%AD%A6%E5%99%A8%E6%98%AF%E4%BB%80%E4%B9%88/a-67530706
[17]https://www.dw.com/zh/%E7%94%B3%E8%AF%B7%E4%B8%93%E5%88%A9%E4%B8%AD%E5%9B%BD7%E7%BA%B3%E7%B1%B3%E8%8A%AF%E7%89%87%E5%85%89%E5%88%BB%E6%8A%80%E6%9C%AF%E5%8F%96%E5%BE%97%E7%AA%81%E7%A0%B4/a-70227975
[18] http://politics.people.com.cn/n1/2024/1205/c1001-40376144.html
[19]https://mp.weixin.qq.com/s/r9zZaEgqAa_lml_fOEZmjg
[20] Idem.
THE DISPUTE FOR LEADERSHIP IN ARTIFICIAL INTELLIGENCE, CHINA, AND OPEN SOURCE
Why is technological leadership important? How to define technological leadership in AI? Artificial Intelligence (AI) is a transversal technology, and its advancements have profound impacts on the economy, society, and national security. Technological leadership, first and foremost, provides a series of competitive advantages, as inventions and innovations grant their developers gains and benefits that others do not possess. Secondly, technological leadership is a critical geopolitical factor, as it allows for the influence of global standards, norms, and regulations. Thirdly, technological leadership can drive an innovation ecosystem that consolidates long-term development. Fourthly, leadership can enhance security in an international context of threats, including military ones. Fifthly, leadership enables the direction of technology to benefit social, environmental, and political objectives.
From a technopolitical perspective, where technoscience is not neutral and has implications for power relations and social organization (Winner, 2020), leadership in AI is not merely about developing the most advanced technology but also about creating a sociotechnical environment that realizes broader social values and objectives, ensuring that innovation follows certain purposes. The trajectory of AI development may prioritize increasing productivity for the economic system or may aim to find socially just and environmentally sustainable solutions. It may seek to concentrate power and reinforce international asymmetries or contribute to the distribution of knowledge and equitable development. It may stifle the inventiveness of populations and cultures or ensure technodiversity. It may be tied to the concentration or distribution of power.
Currently, AI leadership resides in the United States, under the direction of the so-called Big Techs. These companies control indispensable resources for the development of existing AI, particularly AI dominated by the deep learning approach. This approach is based on the use of statistics and probability for the classification and extraction of patterns from large amounts of data. To perform these operations, AI developers rely on significant computational power. Training an advanced AI model like OpenAI’s GPT costs millions of dollars and requires many hours of processing with specialized hardware, such as specific chips designed for these tasks. These are called “AI inference chips” or “inference accelerators.” They achieve better results in less time. For example, Google’s Tensor Processing Units (TPUs) are optimized for inference and training. Neural Processing Units (NPUs) or Neural Network Accelerators, common in mobile devices and edge computing, are also used. Graphics Processing Units (GPUs) are utilized for both training and inference. Currently, these chips are essential for applications such as image recognition, natural language processing, and other real-time AI tasks.
The U.S. government has, for some time, adopted a policy of restricting access to cutting-edge chips, primarily aimed at delaying AI development in China and other countries considered adversaries. The goal is to maintain U.S. leadership in AI. With Donald Trump’s inauguration in January 2025, the policy of technological blockade was intensified. Additionally, the U.S. president announced a $500 billion investment in the Stargate project. Trump’s plan is to develop physical and virtual AI infrastructures in the United States, in collaboration with companies like Oracle, OpenAI, and SoftBank, to “fuel the next generation of AI”. Companies such as Nvidia, Arm, and Microsoft are partners in the project, which is beginning to be implemented in Texas and will, over the next four years, include “colossal data centers” across various regions of the United States.
American tech elites, represented by figures like Elon Musk, believe that artificial intelligence is approaching the “singularity”—the emergence of Artificial General Intelligence (AGI). They argue that AGI will completely surpass and replace human labor in all intellectual domains, and that if the United States is the first to achieve AGI, its technological hegemony will become unassailable. However, neither ChatGPT nor DeepSeek has shown any signs of approaching AGI. They are useful tools for processing natural language and demonstrate limited reasoning abilities within specific domains, but there is no evidence that they—or any known AI research—are nearing AGI.
THE OPEN SOURCE TURNAROUND
In May 2024, a small Chinese company called DeepSeek launched its Large Language Model (LLM) inspired by Llama, a model licensed under a restricted research agreement prohibiting commercial use. What stood out in the open-source model, DeepSeek V2, was its unprecedented cost-effectiveness. DeepSeek had reduced the cost of inference to just 1 yuan per million tokens, approximately one-seventh of Llama3 70B and significantly less than GPT-4. Tokens are basic units of text that language models use to process and understand human language. Depending on the context and language, tokens can be thought of as “chunks” of words, syllables, or even individual characters. AI models convert text into tokens, which are represented numerically. These numbers are then processed by the model to generate responses or perform tasks. Therefore, the number of tokens in a text directly affects the cost and processing time. The more tokens, the more complex and time-consuming the inference.
DeepSeek, like all Chinese companies, was and is subject to the U.S. government’s blockade on cutting-edge chips. This led DeepSeek’s leader and his team to focus more on research and optimization. Liang Wenfeng, in an interview in July 2024, stated, “Our starting point is not to seize the opportunity to make a fortune but to advance to the forefront of technology to promote the development of the entire ecosystem.” The Chinese company’s attempt to lead AI development is evident. To achieve this, DeepSeek did not limit itself to organizing data and running on available clouds. The team worked hard to find solutions in the face of the scarcity of cutting-edge chips. This required altering architectures and experimenting with new procedures, as well as extensive applied mathematics.
The young leader of DeepSeek, Liang Wenfeng, stated, “What we lack in terms of innovation is definitely not capital but confidence and knowledge on how to organize a high density of talent to achieve effective innovation.” He continued, “Innovation is not entirely business-driven; it also requires curiosity and creativity. We are stuck in the inertia of the past, but this is also temporary.” Liang Wenfeng’s idea is to copy less and study more. To bet on open models not to use them but to improve them and find paths that require fewer computational resources.
Open source is fundamental to DeepSeek’s strategy but may not be for other Chinese companies like Tencent, Baidu, and Alibaba, among others. However, open source allows knowledge to be distributed globally, generating possibilities for new discoveries at a faster and more inclusive pace. Liang Wenfeng stated:
“Actually, nothing is lost with open source and the publication of papers. For the technical team, being followed is a great sense of accomplishment. In fact, open source is more of a cultural behavior than a commercial one. Giving is actually an extra honor. A company that does this will also have cultural appeal.”
Open source is not a technology. It is a development process based on knowledge sharing. Generally, it encourages the organization of communities willing to collaboratively solve problems and maintain solutions by updating them. Language models like Mistral 7B (Mistral AI) and Falcon (Technology Innovation Institute) are open and licensed under Apache 2.0. The reinforcement learning model Stable-Baselines3 is also open with an MIT license. There are numerous other open models in the field of AI. So why did DeepSeek’s model become so relevant? Because it disrupted the global race for AI leadership. How? By drastically reducing the computational costs of a large language model.
Open source is fundamental for distributing knowledge but does not solve the problem of the computational infrastructure needed to train and run models. DeepSeek presented an open model with high performance and lower processing requirements.
DeepSeek-R1 has already demonstrated stronger inference capabilities than OpenAI’s ChatGPT o1, while its costs (including both training and usage) are significantly lower. By open-sourcing its model, DeepSeek has facilitated the democratization of large language models—enabling smaller companies, countries with less developed technological and digital infrastructure, and even individuals to train their own “sovereign AI” based on DeepSeek, without relying on Big Tech products or handing over their data to these companies. Indonesia and India have already begun building their own AI infrastructure using DeepSeek as a foundation. Prior to this, only the United States and China had the capability to access large language models at such a high level.
DEEPSEEK R1’S BET ON REINFORCEMENT LEARNING
“DeepSeek-R1 - Zero chose an unprecedented path, the path of ‘pure’ reinforcement learning, which completely abandoned the predefined Chain of Thought (CoT) model and supervised fine-tuning (SFT), relying solely on simple reward and punishment signals to optimize the model’s behavior.”
In an analysis conducted by Tencent’s team on the findings of DeepSeek’s R1 model, they suggested that it might be necessary to rethink the role of supervised learning in AI development. Perhaps they were focused on making AI mimic how humans think rather than betting more on the native problem-solving capabilities of reinforcement learning systems. In reinforcement learning, rewards and punishments are mathematically expressed in the model. The agent (which can be an algorithm or a system) makes decisions based on a policy that seeks to maximize cumulative rewards over time. Rewards are numerical values that the agent receives for performing actions in a given state of the environment.
Machine learning is a field of artificial intelligence that allows computers to identify patterns and make decisions based on data without being explicitly programmed to do so. Machine learning relies on algorithms that extract patterns from large amounts of data and adjust their parameters to improve predictive capabilities over time. These algorithms can be divided into three main categories: supervised learning (when the model learns from labeled data), unsupervised learning (when the model identifies patterns without predefined labels), and reinforcement learning (when the model learns through trial and error, receiving rewards or penalties based on its actions). Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to process data in a hierarchical and sophisticated manner.
Due to these innovations, the training cost of DeepSeek R1 was drastically reduced, representing only 1/10 to 1/20 of ChatGPT’s cost. While OpenAI’s model spent $20, DeepSeek performed the same activity with just $1. In January 2025, the DeepSeek model cost only 16 yuan per million tokens, while ChatGPT cost up to 438 yuan—a difference of 27 times! This means that organizations can use DeepSeek’s model at a lower cost while achieving greater efficiency.
COMPUTATIONAL POWER AND THE GEOPOLITICS OF AI
The plummeting stock prices of Nvidia and other Big Techs were heralded by many as the end of U.S. leadership in AI. This does not seem to be accurate. The sharp decline in the value of the powerful GPU manufacturer was driven by the sudden sale of a massive volume of its shares following the news that DeepSeek had managed to develop a large language model at 10% of OpenAI’s costs. This could change the course of AI. The growing dependence on high-processing chips might be shifting. Based on this reasoning and fear, speculators took the opportunity to sell their positions in Nvidia and other companies.
The dependence on cutting-edge chips did not end with the innovations coming from China. Chips with less than 2 nanometers represent a crucial advancement for artificial intelligence. They ensure greater processing capacity with lower energy consumption. As AI models become more complex and require billions or trillions of parameters, computational efficiency remains a critical factor. Smaller chips allow for greater transistor density, improving calculation speed and energy efficiency, reducing operational costs, and the need for cooling. This evolution is fundamental for the large-scale implementation of AI, from data centers to mobile devices, including military applications.
It is important to note that nanochips expand embedded applications in devices and favor their use in IoT, healthcare, robotics, and autonomous vehicles. Another promise is that with more advanced and smaller chips, AI models can be run locally, reducing dependence on the cloud and ensuring faster and more secure responses. In the geopolitical context, the race for smaller chips intensifies technological disputes between powers like the U.S. and China, as control over this technology defines competitiveness in the digital economy and cybersecurity.
The United States maintains its leadership in the development and manufacturing of chips and semiconductors through a combination of technological dominance, strategic investments, and control of supply chains. American companies like NVIDIA, Intel, AMD, and Qualcomm lead the design of advanced chips. The U.S. government reinforces its position with subsidies and incentives, such as the CHIPS and Science Act, which allocates billions of dollars to strengthen domestic semiconductor production and reduce dependence on Asia.
In addition to technological superiority, the U.S. uses sanctions and export controls to limit access to critical technologies by strategic rivals like China. The Department of Commerce imposes severe restrictions on the export of advanced semiconductor manufacturing equipment, such as ASML’s machines and chip design software from Cadence and Synopsys. These restrictions make it difficult for China to develop its own advanced chips and reinforce the U.S. position in the sector. Simultaneously, Washington invests in strategic alliances, such as the “Chip 4 Alliance” (with Japan, South Korea, and Chinese Taiwan), ensuring that its allies follow U.S. guidelines to restrict technology transfer to countries considered competitors. This consolidated strategy allows the U.S. to maintain its hegemony in the semiconductor industry, essential for the digital economy and national security.
While the United States is making every effort to restrict China’s access to advanced chips (below 7nm) and their production capabilities, China is continuously developing its ability to independently manufacture these high-end chips. Semiconductor Manufacturing International Corporation (SMIC) has already demonstrated the capability to produce 7nm chips and is believed to be likely capable of producing 5nm chips. Companies like Shanghai Micro Electronics Equipment (SMEE) are actively developing extreme ultraviolet (EUV) lithography technology to replace the lithography machines monopolized by ASML, which have been restricted from being sold to China.
On the other hand, in the field of mature process chips used in automotive and industrial sectors—where the technology is not the most cutting-edge but demand is significantly higher—China’s chip industry has already established a large-scale and complete industrial chain. In 2024, China’s total chip exports exceeded 1 trillion RMB (approximately 139 billion USD) . It is foreseeable that once Chinese companies achieve technological breakthroughs in advanced processing, their existing supply chain advantages will significantly reduce the prices of high-end chips. Moreover, chip processing is constrained by physical limits and cannot be improved indefinitely. It is only a matter of time before China catches up with the United States.
CONCLUSION
“Nvidia’s leadership is not just the result of one company’s efforts but the combined efforts of the entire Western technology community and industry. They can see the next generation of technological trends and have a roadmap. AI development in China also requires this ecosystem. Many domestic chips cannot develop due to the lack of supporting technical communities and only second-hand information, so China needs someone at the forefront of technology.” (Liang Wenfeng, 2024)
The founder of DeepSeek, Liang Wenfeng, stated, “The problem we face has never been money but the ban on cutting-edge chips.” Even if the trend of data concentration and the need for increasing computational power—which requires increasingly sophisticated chips—shifts and loses momentum, international capitalism does not seem to alter its fundamental asymmetries. Undoubtedly, the technoscientific development of China allows countries technologically dependent on the U.S. to structure strategies that benefit their development. Having sovereign, controllable, world-class large language models was once out of reach for countries outside the United States and China—especially those in the Global South. Now, DeepSeek has democratized this technology, opening up new possibilities for Global South countries in this field. At the same time, it has also presented new tasks and challenges for the governments of these nations.
What the DeepSeek phenomenon points to is the importance of open source for strengthening international collaborative chains that can reduce inequalities and large knowledge asymmetries. However, open source does not solve the problem of building sovereign infrastructures essential for local and national development. Therefore, it falls to states seeking to improve their techno-economic position to reduce the power of Big Techs, control the fundamental inputs of AI—especially data from their populations—and invest in solutions that reduce the environmental impact and labor precarization that automated systems have generated in capitalist countries. Betting on quality education for youth requires encouraging technodiversity and converting the cultural vitality of peoples into technological expressions.

本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。