阿里雲發佈QwQ-32B:僅用1/20參數比肩滿血DS-R1,可在消費級顯卡部署
连政guanchazhewanxgun

3月6日凌晨,阿里雲發佈並開源全新的推理模型通義千問QwQ-32B。官方稱,這個新模型僅僅擁有320億參數,但在性能上比肩6710億參數的滿血版DeepSeek R1。
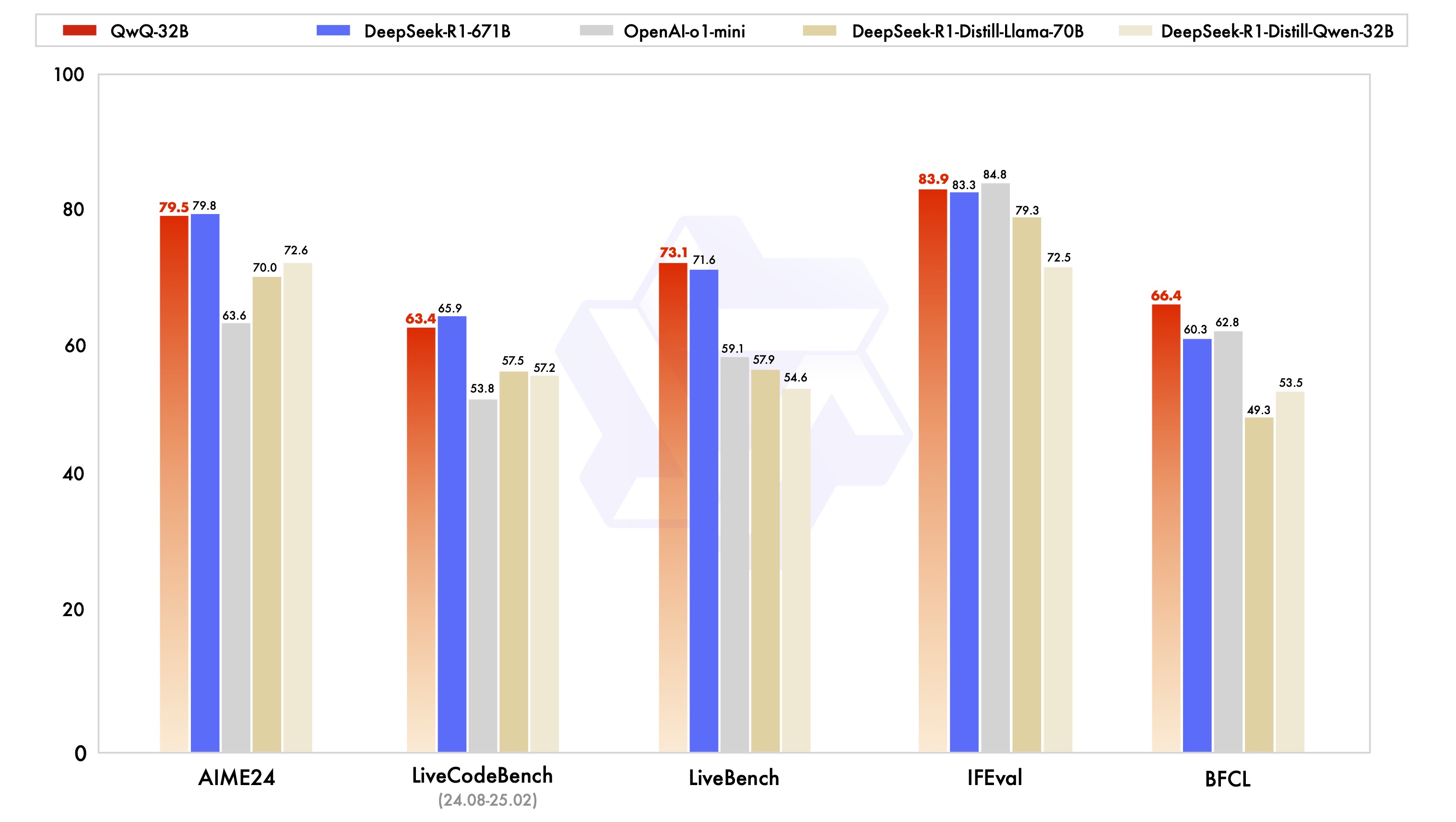
目前,阿里雲並未發佈還完整技術報告,但官方數據顯示,QwQ-32B僅在編程競賽(LiveCodeBench)和美國數學競賽(AIME24)兩項略遜於滿血的DeepSeek-R1,其餘三項則全面超越。此外更是碾壓完全超越了OpenAI-o1-mini。
阿里雲解釋稱,團隊此次基於Qwen2.5-32B模型,探索了擴展強化學習(RL)的技術方案,並發現強化學習訓練能夠持續提升模型性能,尤其在數學與編程任務中表現顯著。該團隊還提到,通過持續擴展強化學習訓練的規模,中型模型也可以實現與巨型混合專家模型(MoE)相媲美的性能。
此外,QwQ-32B還滿足更低的資源消耗需求,適合快速響應或對數據安全要求高的應用場景,開發者和企業可以在消費級顯卡上將其部署到本地設備中,進一步打造高度定製化的AI解決方案。阿里稱,QwQ-32B已多個平台基於寬鬆的Apache2.0協議開源,所有人都可免費下載模型進行本地部署,或者通過阿里雲百鍊平台直接調用模型API服務。

值得一提的是,此前OpenAI曾因遇到技術瓶頸,將原來的GPT5.0降格為GPT4.5進行發佈,之後還透露將降低強化學習訓練的優先級,轉向監督學習(SSL)和語言模型(LM)為核心的技術路線。而QwQ-32B的發佈則證明了強化學習路線仍有潛力,可以繼續提升模型的性能。
千問QwQ-32B模型中還集成了與智能體Agent相關的能力,使其能夠在使用工具的同時進行批判性思考,並根據環境反饋調整推理過程。通義團隊表示,未來將繼續探索將智能體與強化學習的集成,以實現長時推理,探索更高智能進而最終實現AGI的目標。
本文系觀察者網獨家稿件,未經授權,不得轉載。