小米大模型突然登頂一項測試,用了DeepSeek的方法
张广凯13764468101

3月17日,小米官方透露,其大模型團隊在音頻推理測試集MMAU榜單登頂,並強調“DeepSeek-R1的發佈為我們在該項任務上的研究帶來了啓發”。
MMAU是一個側重考察音頻大模型理解和複雜推理能力的測試集,包含27種不同的任務,一萬條涵蓋語音、環境聲和音樂的音頻樣本。
例如,其中一個任務是要求從一段10多秒的語音中,數出包含至少一個重讀音素的單詞數量;另一個任務是根據一段美劇《生活大爆炸》中的對話,解釋其中一句話為什麼是諷刺。

這是一個難度較高的測試集,人類專家的測試準確率為82.23%。而目前榜單上最強的大模型是谷歌Gemini 2.0 Flash,準確率55.6%。
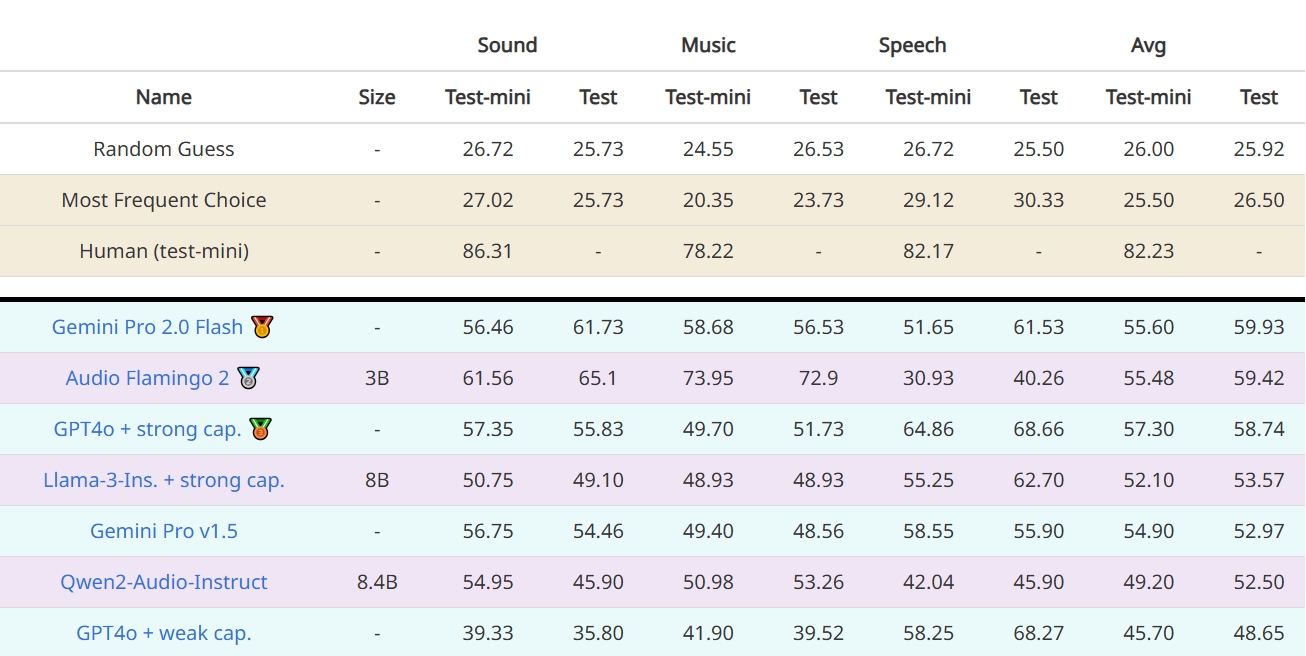
小米大模型則達到了64.5%的準確率,較其它大模型有顯著提升。其參數量更是隻有7B,是一個非常輕量化的模型。
不過,小米的大模型倒也不是完全自己研發,而是基於開源的阿里通義大模型Qwen2-Audio-7B,並使用清華大學發佈的 AVQA 數據集進行微調。Qwen2-Audio-7B自身在這個測試集上的得分是49.2%。
其實,相比於模型本身,小米這一成果的更大意義在於,證明了在音頻模型領域,DeepSeek-R1的Group Relative Policy Optimization (GRPO) 方法,同樣比監督微調(SFT)效果要好得多。
小米方面專門用通俗的語言解釋了這個方法:
“打個比方來説,離線微調方法,如 SFT,有點像背題庫,你只能根據已有的題目和答案訓練,但遇到新題可能不會做;而強化學習方法,如 GRPO,像老師在要求你多想幾個答案,然後老師告訴你哪一個答案好,讓你主動思考,激發出自身的能力,而不是被“填鴨式”教學。當然,如果訓練量足夠,比如有學生願意花很多年的時間來死記硬背題庫,也許最終也能達到不錯的效果,但效率太低,浪費太多時間。而主動思考,更容易快速地達到舉一反三的效果。強化學習的即時反饋可能會幫助模型更快鎖定高質量答案的分佈區域,而離線方法需要遍歷整個可能性空間,效率要低得多。”
此外,小米團隊還發現,如果讓模型像DeepSeek一樣,給出顯性的推理過程,最後的準確率反而下降到61.1%,也就是説,顯式的思維鏈結果輸出可能並不利於模型的訓練。這是相較於DeepSeek的一個新發現。
最後,小米方面也指出,儘管當前準確率已突破 64%,但距離人類專家 82% 的水平仍有差距,音頻大模型仍然遠遠落後於人類聽覺語言推理。
本文系觀察者網獨家稿件,未經授權,不得轉載。