月詠幻:當中國已大量使用AI時,日本還在努力淘汰軟盤和傳真......
guancha
【文/觀察者網專欄作者 月詠幻】
從2023年ChatGPT引發全球AI熱潮到2025年初DeepSeek爆火,短短兩年半時間裏,中國完成了從追趕到並跑,再到某些領域領跑的轉變。這種全方位的進步,折射出中國在AI領域的整體實力。
反觀同為亞洲科技大國的日本,卻在這場AI革命中顯得異常低調。作為全球第三大經濟體,日本既沒有誕生可與DeepSeek比肩的大語言模型,在AI應用的普及程度上也遠遜於中國。
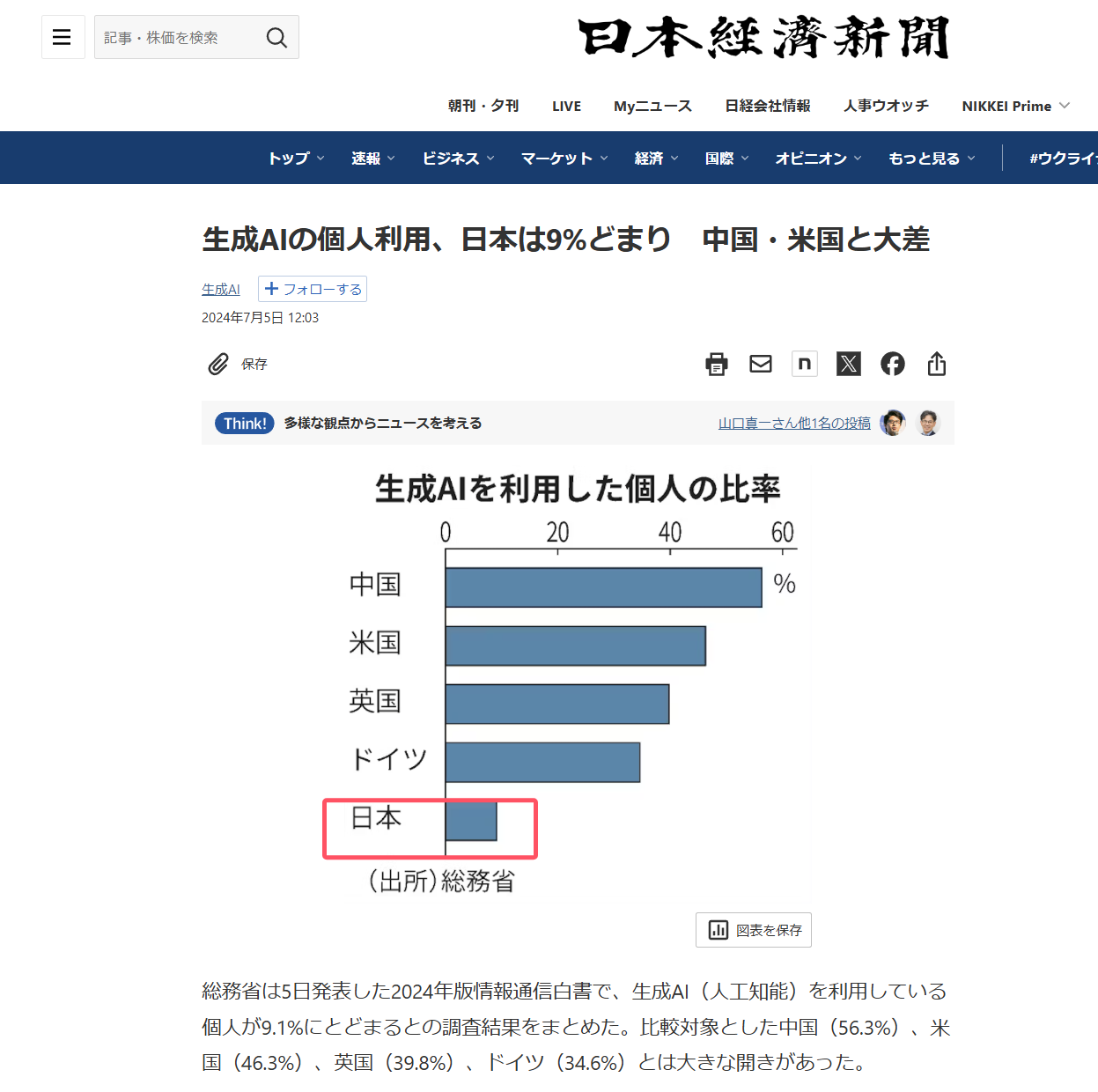
根據日本經濟新聞的報道,日本正在使用生成式AI的人數,僅有9%,而中國已經接近60%大關,美國也超過了40%。
AI在中美已經瘋狂普及,但為何日本到如今都還是反響平平?為什麼以“科技創新”聞名的日本,會在AI時代的關鍵技術領域落後?
在談AI之前,連技術革新都有問題
在討論日本AI發展現狀前,我們必須先提到日本目前面臨的幾個科技難題:一是發展慢,二是研究少,三是缺人才。這三個問題會互相影響,互為因果,最終體現在當下這兩年的人工智能熱潮中,很難見到日本的身影。
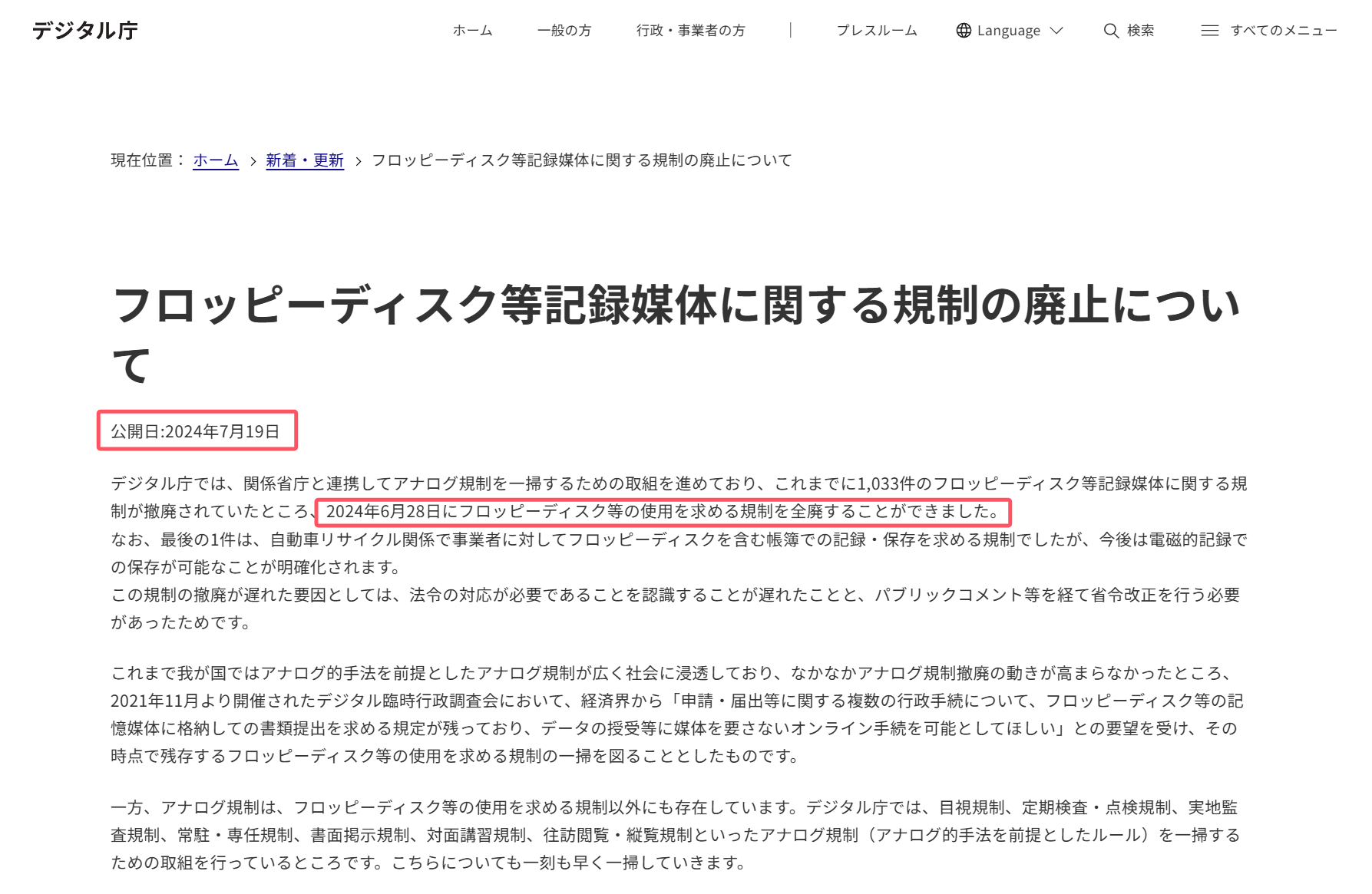
先説發展慢的問題。作為對比,當中國的移動支付已經普及多年,智能機器人正在春晚上表演時,日本政府部門仍在為淘汰3.5寸軟盤和傳真機而努力:2024年6月28日,日本政府終於宣佈在所有的政府流程中淘汰了軟盤。
出處:日本ReseEd
另一項技術古董——傳真,現在也僅僅只在日本教育系統裏被廢止,醫療和警務暫時還沒有辦法拋棄傳真。2023年年底的資料顯示,有95%的小初高學校老師仍在使用傳真。

出處:日本ReseEd
因此,我們可以説,日本數字化轉型的遲滯並非偶然,而是反映了日本在面對新技術變革時的深層次困境。
這和筆者之前提到過很多次的日本科技後進國的定位有關:畢竟,一個現在還在用傳真,正在逐漸把3.5寸軟盤從政府事務中淘汰的國家,你指望它能在最新的高科技領域裏攪動起多大的水花呢?
政府部門如此,民間企業也沒有好到哪裏去。目前日本並沒有本土公司做的著名大模型,也沒有那麼多人在普遍使用AI。
日本民間企業對AI的理解,可以從JetB的這項調查裏看到:有51%的企業完全沒有想到今後要用AI提升什麼事務的效率。
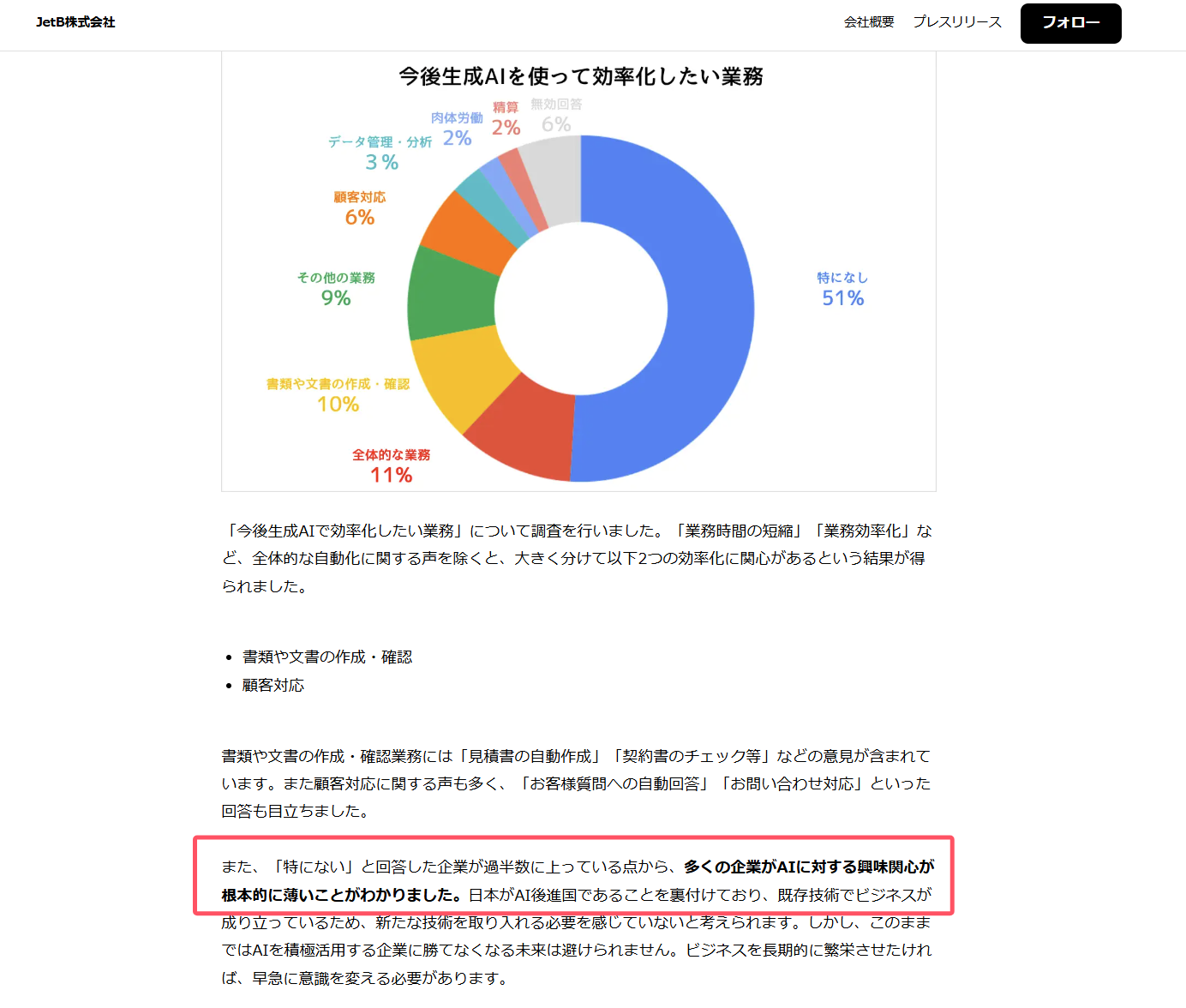
這個調查結果明確説明了日本多數企業對AI根本不關心。究其原因,是因為日本許多企業仍然依賴封閉且高度定製化的遺留系統(Legacy System),這些系統由於長年累積的複雜性和供應商鎖定效應,導致企業難以靈活利用數據,也無法順利對接AI等新技術。
日本經產省的報告數據顯示,有很多企業將90%以上的IT預算用於系統維護,而不是新技術的研發和導入。
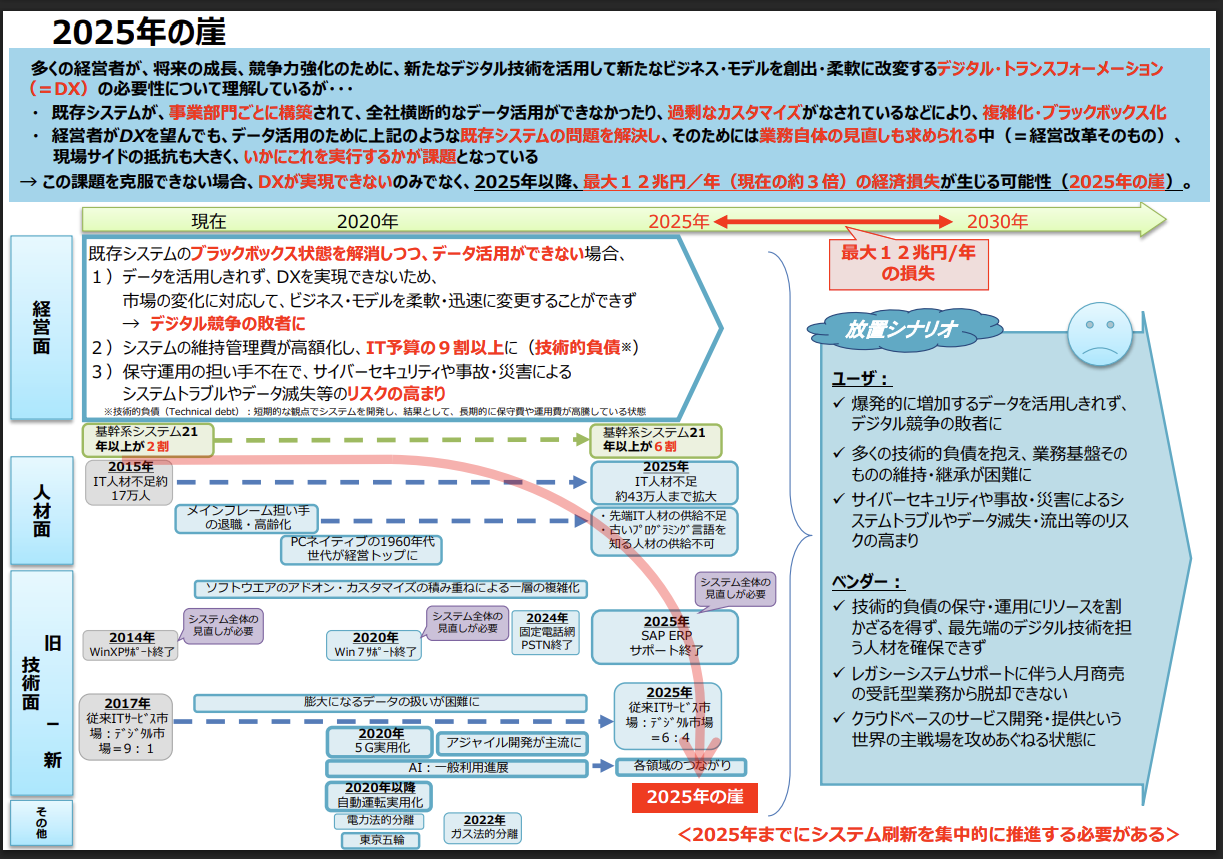
日本製造業、金融業和政府機構的大量核心系統,仍然運行在這些上世紀開發的老舊架構上,部分企業甚至還在使用Windows 7或COBOL語言開發的程序,而這些系統的維護成本極高,更新難度大,使得日本在技術迭代上長期落後於歐美和中國。
當中國科技公司秉持“快速迭代、持續優化”的理念時,日本企業仍在追求維護過往熟悉的所謂完美方案,乃至於將寶貴的工程師資源大量投入在維護老舊系統上,真正用於技術創新的資金極為有限。
其次是研究少。根據日本經濟新聞的報道,2012年到2021年這10年間,中國和美國在AI領域的科研重點論文一直在增加,只有日本持續保持在非常低的水平。
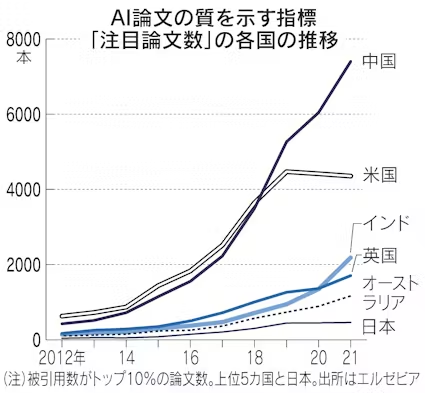
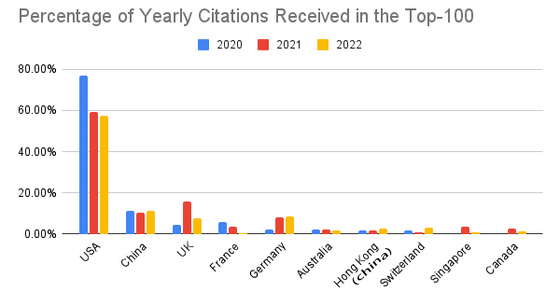
AI調研企業Zeta Alpha的數據則顯示,在2020-2022這三年間,每年被引用最多的AI論文裏,日本甚至連前十都沒排進,依舊是中美在最前面。
最後我們談談人才問題。上面我們已經提到了,日本企業內部的人力預算主要用來維護老舊的系統,而非拓展新的內容。這就導致日本企業並不會為這類人才投入過多的資源:不創造新的業務場景,只要能維持原樣,就不會有動力去改進。
正是因為這樣的場景需求,導致日本的IT人才根本不需要高精尖的技術,只要是熟練工就可以了。因此,根據日本科學技術學術政策研究所的數據,相對於中美的新博士人才在2010-2018年中不斷增加,日本的新博士人才數甚至在逐年減少。無論是IT和AI領域,新的技術開發都需要龐大的高素質人才來維護,這讓本就不好的技術發展雪上加霜。
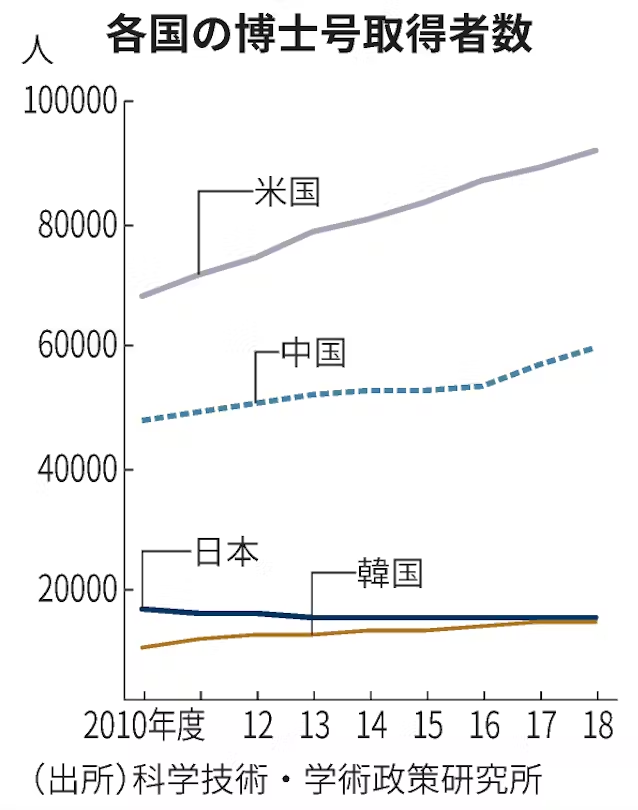
綜上所述,日本的市場總體發展差,導致相應的人才減少,又會反過來導致技術發展不好,市場更差——這種惡性循環一直持續到現在的AI時代。
看到這裏,會有讀者不禁要問:日本就沒有AI人才了嗎?日本在AI領域真的就是完全隱身了嗎?
答案當然沒有那麼絕對。在AI繪圖領域中,日本開發者的貢獻是非常紮實的。只可惜,這只是個人開發者的高光時刻,而非大企業的功績。
以StableDiffusion和Midjourney為代表的圖片大模型,早已經在AI繪圖領域嶄露頭角。尤其是StableDiffusion,由於其開源特性,在目前的AI繪圖中更是擁有最強的可能性。而日本開發者kohya是最早開發了訓練工具的那一批人,他讓StableDiffusion模型擁有了更多可能性,是相關領域中最功不可沒的開山鼻祖之一。
時至今日,所有StableDiffusion玩家在訓練自己的AI繪圖模型時,都會在運行界面上看到日文。這就是因為開源工具的代碼中,有相當大的貢獻都是這個項目做的。
出處:Github上kohya的訓練器頁面
但是除此之外,日本人在其他AI領域暫時難有類似高度的貢獻。無論是商業還是開源,都難見日本的身影。在全球AI競爭日趨激烈的當下,中國已經率先形成了完整的AI產業鏈,而日本仍在為數字化轉型的基礎問題苦苦掙扎,二者的差距正在迅速拉大。
日本缺的東西,全是中國的優勢
與日本在AI時代的困境形成鮮明對比,中國的IT市場發展迅速,人才儲備充足,技術的普及和落地更是走在世界前列。可以説,日本AI技術之所以發展不起來,就是因為缺乏中國所具有的優勢。
2025年3月5日,國務院新聞辦公室在解讀《政府工作報告》的吹風會上,特別提到了三款中國在AI領域的代表性產品——DeepSeek、可靈、宇樹科技——分別對應國際上2023年初引爆市場的ChatGPT(文字大模型)、2024年初走紅的Sora(視頻大模型)和馬斯克的擎天柱(具身智能機器人)。
DeepSeek不僅性能強大且成本低廉,更是打破了ChatGPT所構建的“訓練大模型需要天量算力和高昂成本”這一固有認知。以往需要海量算力投入的任務,如今僅需極低成本就能完成,且質量絲毫不遜色。
另一方面,可靈則在視頻生成領域領先一步,比Sora更早向消費者開放,並憑藉卓越的生成質量與效率,迅速獲得全球市場的認可。
2024年年初,Sora作為第一個出圈的視頻模型引起了大量的話題,但就在同一年年中,可靈推出的老照片復活功能就在抖音引發了刷屏效應。而此時OpenAI仍在依賴人工後期製作,為Sora打造演示視頻。到了2024年底,即夢、混元等國產視頻大模型全面上線,普通用户已能自由使用AI生成視頻,而Sora則直到12月才姍姍來遲地向其付費用户開放視頻生成功能,錯失了市場先機。
回望過去兩年,全球AI浪潮的主角似乎一直是OpenAI和馬斯克,他們在各自領域的突破曾經主導了輿論。然而,到了2025年年初,當我們重新審視這場競賽時,中國不僅已經成功跟上,甚至在多個關鍵技術點上實現了超越。這種轉變令人感慨萬千,也再次驗證了生成式AI的三大核心要素:算力、算法、數據——而中國恰好在這三方面佔盡天時、地利、人和。
首先,中國擁有世界頂尖的數學與算法人才儲備。計算機科學和人工智能的核心是數學,而中國在這一領域一直處於全球領先地位。近幾年,無論是大模型訓練、AI芯片優化,還是深度學習框架的研發,中國的研究機構和企業都在快速崛起,甚至逐步改變過去“追隨者”的角色,開始引領前沿技術的發展。
其次,數據是人工智能的燃料,而中國無疑坐擁全球最豐富、最優質的數據資源。作為世界上最大的單一語言市場,中國不僅有14億人口構成的龐大用户羣,還有高度發達的互聯網生態。從社交媒體到電商、短視頻、金融科技,中國的數據量級和多樣性遠超其他國家。這不僅讓AI模型訓練的數據更豐富,也使得AI產品落地和優化的速度遠超國外對手。正因如此,可靈、即夢等國產視頻生成模型才能迅速打入市場,而Sora卻仍在封閉的環境裏精調算法,遲遲未能大規模放開給普通用户使用。
最後,算力曾是AI發展的關鍵瓶頸,但這個壁壘正在被逐步攻破。全球AI市場幾乎被英偉達的GPU壟斷,算力價格居高不下,成為所有AI公司的沉重成本。然而,DeepSeek等國產大模型已經在適配國產GPU,並逐步打破對英偉達的依賴。這一趨勢不僅會加速中國AI行業的自主可控進程,還會迫使英偉達重新調整市場策略,甚至可能讓“老黃”不得不降價,讓全球用户買到更便宜的N卡。
綜上所述,中國AI產業的崛起並非偶然,而是算法、數據、算力三大核心要素共同作用的結果。現在,中國AI的步伐已然加快,甚至開始在多個領域反超。未來幾年,全球AI格局的主導權,或許將迎來一場更大規模的洗牌。

本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。