阿里發佈並開源模型Qwen3,成本僅為DeepSeek-R1的1/3
史岱君

4月29日凌晨,阿里巴巴開源新一代通義千問模型Qwen3(簡稱千問3),參數量僅為DeepSeek-R1的1/3,成本大幅下降,性能全面超越R1、OpenAI-o1等領先模型,登頂全球最強開源模型。
千問3是國內首個“混合推理模型”,將“快思考”與“慢思考”集成進同一個模型,大大節省算力消耗。
根據官方的説法,千問3的旗艦版本 Qwen3-235B-A22B,在代碼、數學、通用能力等基準測試中,達到了與 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 同一梯度的水平。
在奧數水平的 AIME25 測評中,Qwen3-235B-A22B 斬獲 81.5 分,刷新了開源模型的紀錄;在考察代碼能力的 LiveCodeBench 評測中,Qwen3-235B-A22B 突破 70 分,表現甚至超過 Grok 3;在評估模型人類偏好對齊的 ArenaHard 測評中,Qwen3-235B-A22B 以 95.6 分超越 OpenAI-o1 及 DeepSeek-R1。
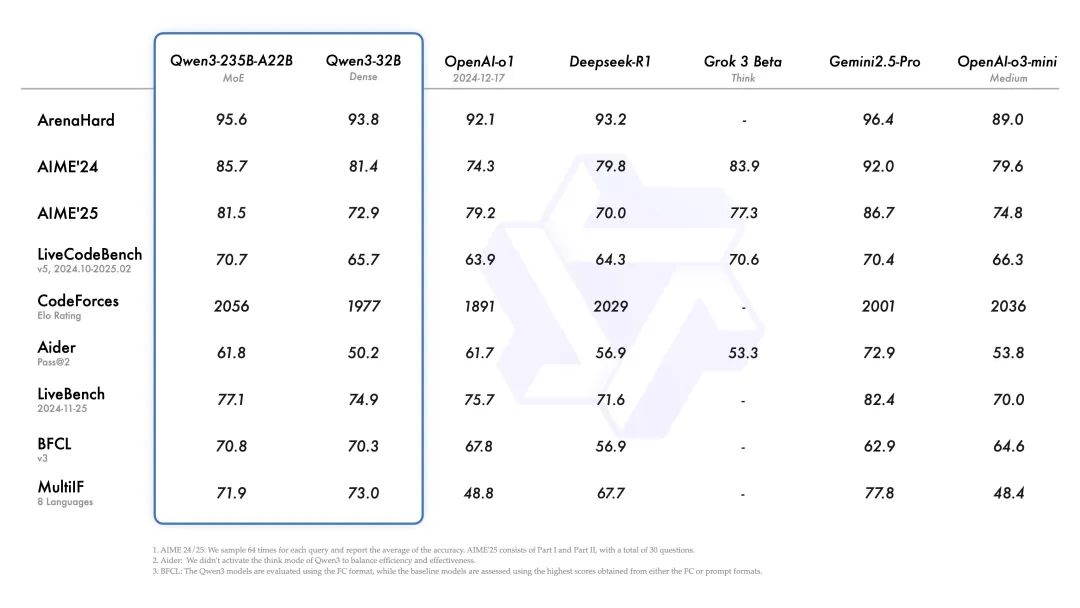
在相同計算資源下,千問3模型以更小的規模實現了對更大體量上一代模型的超越,真正做到了“小而強大”。
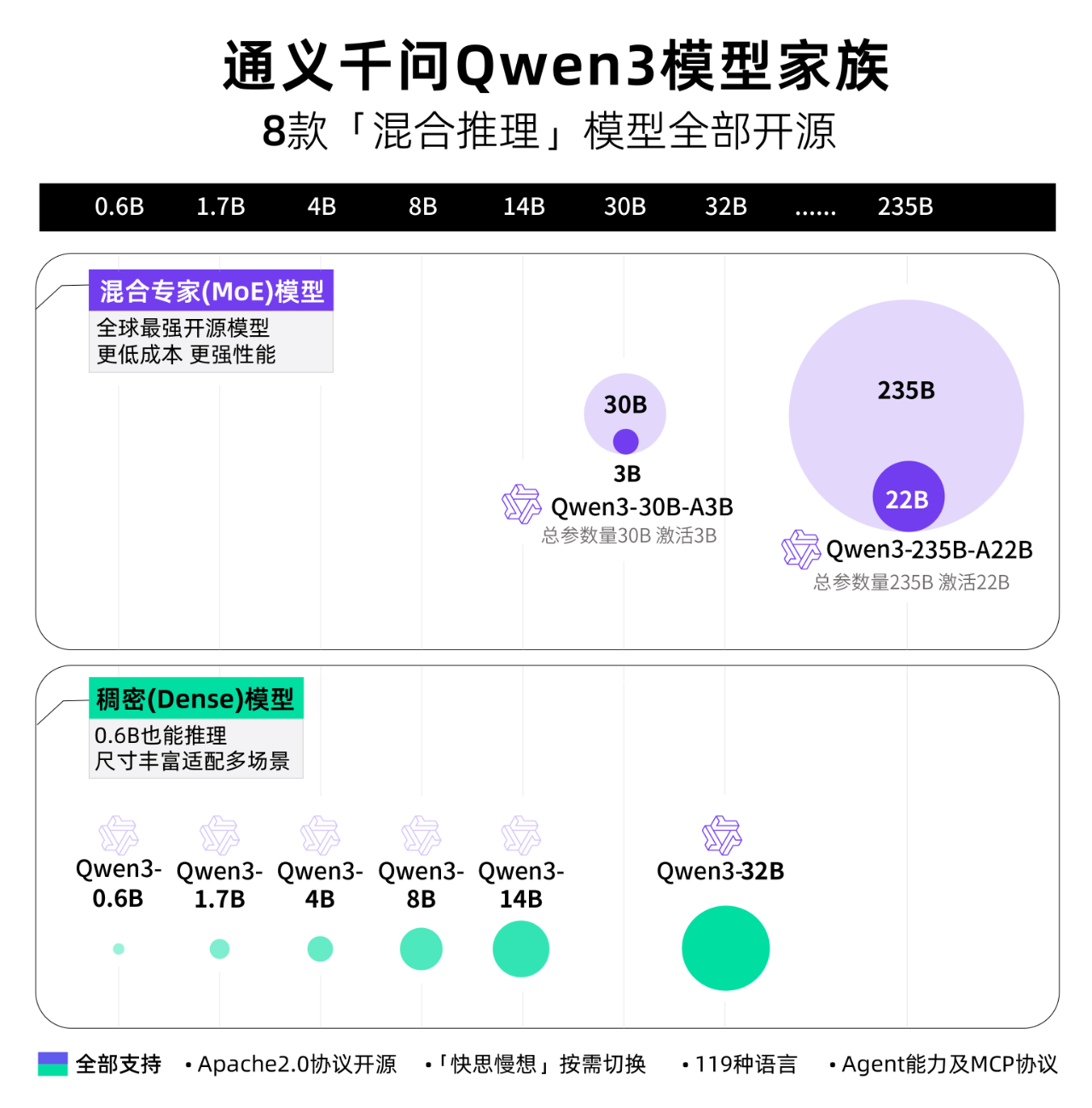
千問3總參數量235B,刷新了開源模型的智能水平新高,阿里稱僅需4張H20即可部署千問3滿血版,顯存佔用僅為性能相近模型的三分之一。
千問3模型版本包含2款30B、235B的MoE模型,以及0.6B、1.7B、4B、8B、14B、32B等6款密集模型。
同時,千問3為即將到來的智能體Agent和大模型應用爆發提供了更好的支持。在評估模型Agent能力的BFCL評測中,千問3創下70.8的新高,超越Gemini2.5-Pro、OpenAI-o1等頂尖模型,將大幅降低Agent調用工具的門檻。
據悉,千問3系列模型依舊採用寬鬆的Apache2.0協議開源,並首次支持119多種語言,全球開發者、研究機構和企業均可免費在魔搭社區、HuggingFace等平台下載模型並商用,也可以通過阿里雲百鍊調用千問3的API服務。個人用户可立即通過通義APP直接體驗千問3,夸克也即將全線接入千問3。
目前,阿里通義已開源200餘個模型,全球下載量超3億次,千問衍生模型數超10萬個,已超越美國Llama,成為全球第一開源模型。
本文系觀察者網獨家稿件,未經授權,不得轉載。