阿里“最強開源模型”,昇騰、海光已適配
杨依婷

(文/楊依婷 編輯/呂棟)
4月29日凌晨,阿里新一代通義千問模型Qwen3發佈並開源,它的參數量僅為DeepSeek-R1的1/3,但成本大幅下降,性能超越R1、OpenAI-o1等全球頂尖模型,被媒體稱為“全球最強開源模型”。
隨後,華為計算官方發文稱,此次Qwen3系列一經發布開源,即在MindSpeed和MindIE中開箱即用,實現Qwen3的0Day適配。海光信息方面也表示,海光DCU迅速完成對全部8款模型的無縫適配+調優。
根據阿里雲官方信息,此次開源包括兩款MoE模型:Qwen3-235B-A22B(2350多億總參數、 220多億激活參),以及Qwen3-30B-A3B(300億總參數、30億激活參數);以及六個Dense模型:Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B和Qwen3-0.6B。
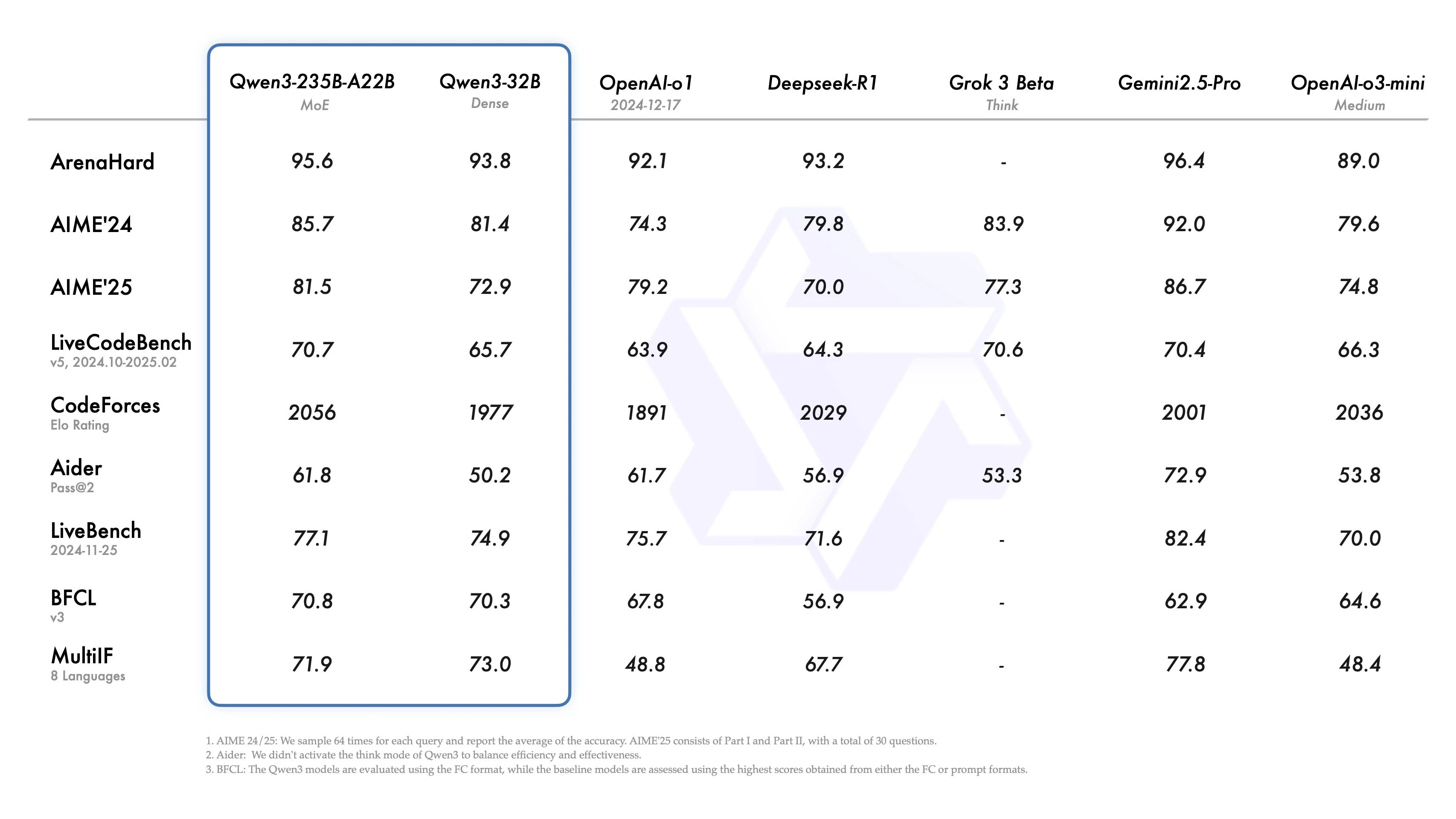
其中的旗艦模型Qwen3-235B-A22B在代碼、數學、通用能力等基準測試中,與DeepSeek-R1、o1、o3-mini、Grok-3和Gemini-2.5-Pro等頂級模型相比,表現出極具競爭力的結果。
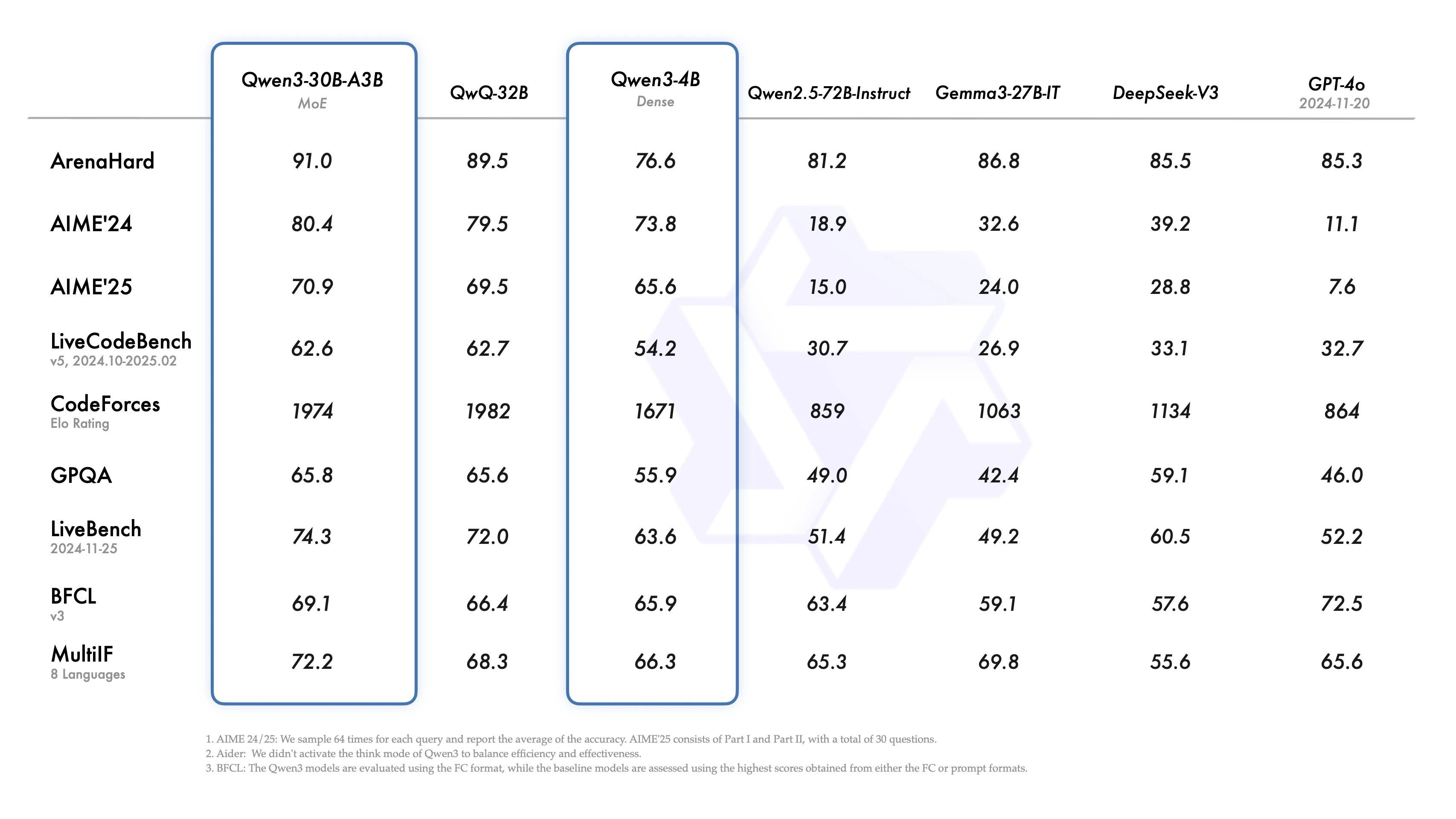
此外,小型MoE模型Qwen3-30B-A3B的激活參數數量是QwQ-32B的10%,表現更勝一籌,甚至像Qwen3-4B這樣的小模型也能匹敵Qwen2.5-72B-Instruct的性能。
Qwen3是國內首個“混合推理模型”,模型支持兩種思考模式:思考模式:在這種模式下,模型會逐步推理,經過深思熟慮後給出最終答案。這種方法適合需要深入思考的複雜問題。非思考模式:在此模式中,模型提供快速、近乎即時的響應,適用於那些對速度要求高於深度的簡單問題。
在預訓練方面,Qwen3的數據集相比Qwen2.5有了顯著擴展。Qwen2.5是在18萬億個token上進行預訓練的,而Qwen3使用的數據量幾乎是其兩倍,達到了約36萬億個token,涵蓋了119種語言和方言。
從官方數據來看,在考察代碼能力的LiveCodeBench評測中,Qwen3突破70分大關,表現甚至超過Grok3;在評估模型人類偏好對齊的ArenaHard的測評中,Qwen3分別以95.6分超越了OpenAI-o1及DeepSeek-R1;在評估奧數水平的AIME25測評中,Qwen3以81.5分刷新開源記錄。
Qwen3發佈後,華為計算方面發文稱,此前昇騰MindSpeed和MindIE一直同步支持Qwen系列模型,此次Qwen3系列一經發布開源,即在MindSpeed和MindIE中開箱即用,實現Qwen3的0Day適配。
隨後海光信息也表示,在“深算智能”戰略引領下,海光DCU迅速完成對全部8款模型的無縫適配+調優,覆蓋235B/32B/30B/14B/8B/4B/1.7B/0.6B,實現零報錯、零兼容性問題的秒級部署。
本文系觀察者網獨家稿件,未經授權,不得轉載。