十年前的手機都能跑,阿里掏出了最適合落地的小模型?
陈济深

(文/陳濟深 編輯/張廣凱)
上個月,阿里巴巴旗下的通義平台正式推出了新一代模型Qwen3,登頂全球最強開源模型榜單。
值得注意的是,Qwen3系列模型共包含8款不同尺寸,除了兩個參數為30B和235B的MoE(混合專家系統)大模型外,阿里本次推出了6款Dense(稠密)模型,6個是稠密模型,參數從0.6B到32B不等。
阿里一向非常重視小尺寸模型,這也算不上新聞了,不過其中最小的0.6B模型參數量僅為6億,作為對比,2019年2月發佈的GPT-2參數量都有15億。這個模型的實際表現如何,讓人相當好奇。
為此,我們請教了一些專業開發者,並且自己也進行了測試,發現即使10年前的手機芯片都足以支持這款模型的推理運算,實際回答效果也能夠差強人意。而4B、8B等參數量的模型則有着更好的表現。
對於一次性更新八個開源模型的原因,阿里雲CTO周靖人表示:不同模型其實就是儘量滿足從個人到企業的不同開發者的需求。比如手機端側可以用4B,電腦或汽車端側推薦8B,32B是企業最喜歡的尺寸,能商用大規模部署。
除了尺寸之外,有開發者指出,採用稠密架構的小模型,也比MoE的稀疏架構更適合企業的實際業務場景。在可以預見的未來,B端市場還是大模型變現的最重要場景,憑藉快人一步的小尺寸模型佈局,阿里正在這場競爭中搶佔先機。
什麼是稠密模型?
所謂稠密模型(Dense模型),是指神經網絡中層內神經元之間通過全連接(Fully Connected)方式連接,且所有參數對所有輸入樣本全局共享的模型。
相比使用稀疏模型MoE架構只會調用部分的參數資料,Dense模型對於任意輸入,模型的所有參數都會被激活並參與計算。
早期人們熟悉的大模型,都是以稠密架構為主。
以OpenAI為例,其GPT系列在GPT3前均使用了Dense模型,而後續GPT版本由於其閉源的特性,我們暫時不得而知其採用了哪類架構。
作為深度學習的 “基石”,稠密模型其核心價值在於簡單性、高效性和普適性,適用於大多數標準化、即時性或資源受限的場景。
但是隨着Scaling Law之下,大模型訓練所需的參數量呈幾何增長,稠密模型的訓練成本逐漸讓人難以承受,並且能力提升幅度也逐漸遭遇瓶頸,暴露了較難適應多樣化場景的問題。為此,MoE(混合專家系統)模型作為解決方案應運而生。
相比於參數愈發膨脹的稠密模型,MoE架構是節約資源的一種設計,通過引入稀疏門控機制,每次執行任務時只需要激活少數相關的子模型,從而降低訓練和推理成本。DeepSeek V3就是憑藉MoE架構,實現了驚人的成本下降。
但是MoE架構也有缺點,如增加通信成本、微調中容易出現過擬合等。而稠密模型由於推理時計算路徑固定,無動態路由開銷,反而相比Moe架構更加適合即時在線客服、商品推薦、金融風控等需要低延遲響應的場景。
稠密模型除了有更加合適的匹配場景,對於個人開發者而言,Pytorch、TensorFlow等深度學習工具鏈對稠密模型的優化已非常成熟,從分佈式訓練到量化壓縮,形成了完整的技術棧。而MoE模型的工程實現由於還處在技術迭代階段,相比Dense模型沒有一套完整成熟的方案,對於個人開發者落地成本較高。
小模型能跑成啥樣?
那麼作為小而美的模型,其運行門檻到底有多低?又會不會存在小而弱的情況呢?
在運行門檻層面,有開發者對觀察者網表示,其成功將Qwen3 0.6B模型安裝在一款搭載4核2.4G的CPU的設備中併成功運行。
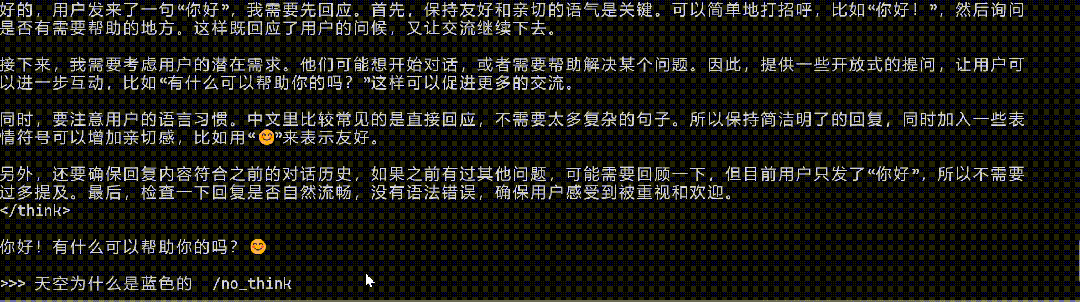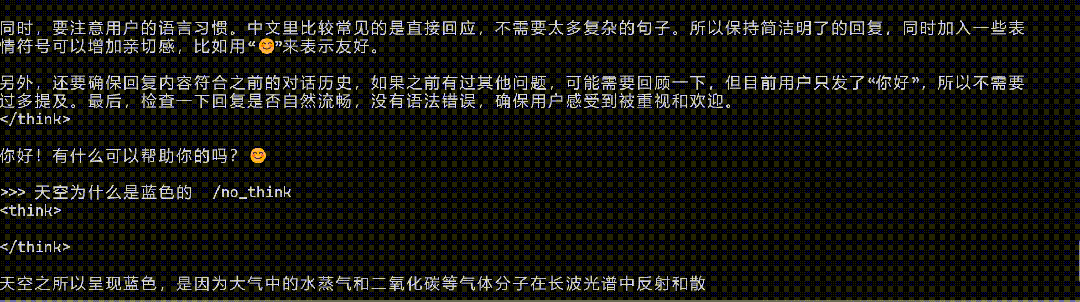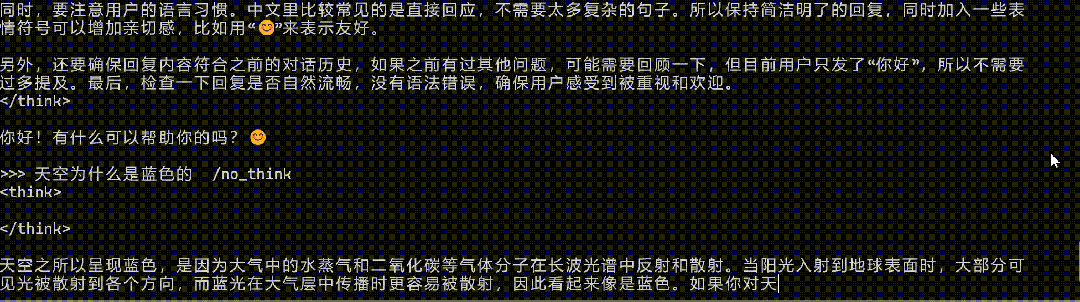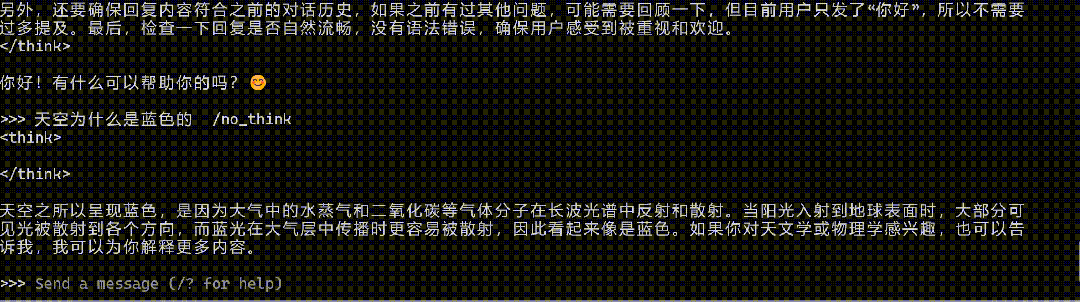
開發者將Qwen 0.6B植入應用生成回答
如果要用手機芯片對比該CPU,最為接近的是發售於2014年的驍龍801芯片。該芯片為28nm製程,搭載4核2.5G CPU,並搭載了一顆Adreno 330的GPU,當年發售的小米4、三星Galaxy S5、OPPO Find7等手機均採用了該款芯片。
而這款當年的旗艦芯片放到2025年是妥妥的過時硬件,以小天才電話手錶Z10為例,其搭載的高通W5芯片採用4nm架構,四核Cortex-A53的CPU,在Geekbench5單核跑分約500分,碾壓了驍龍801的200分。也就是説單核角度,現在小天才電話手錶的CPU都是驍龍801的兩倍。
更值得注意的是,該開發者表示,其採用的設備只有CPU,沒有GPU。也就是説無論是10年前的小米手機,還是如今的小天才電話手錶,都硬件性能都能支持順利運行Qwen3 0.6B的模型。
觀察者網也在iPhone 16 Pro Max(2024年上市,搭載蘋果3nm製程A18 Pro芯片)和索尼Xperia Z5(2015年上市,搭載高通20nm製程驍龍810芯片)上進行了測試。
在沒有任何優化的情況下,兩款手機均能運行Qwen3 0.6B參數的Dense模型。不過在響應速度上,在關閉推理模式時,蘋果手機可以做到即時響應,索尼手機可以做到延遲1秒左右響應,而在開啓了推理模式後,蘋果手機則依然能迅速響應,索尼手機則需要接近10秒的時間才能響應,出現了顯著的延遲情況。
而在具體的問答環節,在沒有任何優化和適配的情況下,對其提問“天空為何是藍色的”和“生蠔是生的還是熟的”,Qwen3 0.6B沒能絲滑應對腦筋急轉彎,但也給出了勉強可用的回答。

Qwen3 0.6B回答生蠔問題
相比之下,4B的模型性能又有顯著提升,同樣詢問其“生蠔是生的還是熟的”問題後,它能夠準確回答出“生蠔”是名字,不是狀態,可以是生的,也可以是熟的。
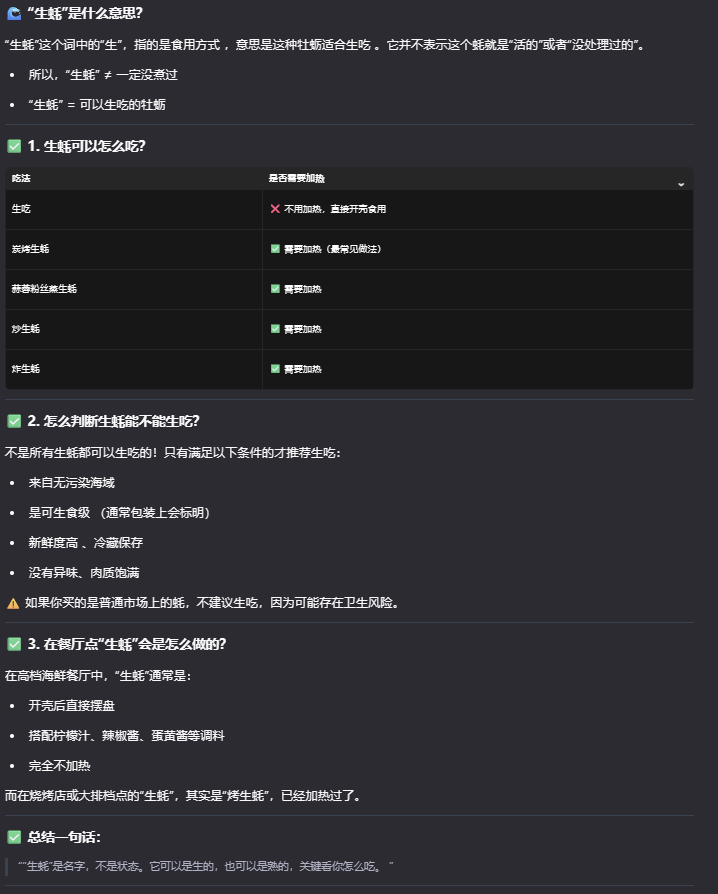
Qwen3-4B模型能夠詳細回答生蠔問題的答案
根據阿里官方的描述,Qwen3-4B性能可與Qwen2.5-72B-Instruct媲美,而Qwen考慮到目前智能手機基本均可以流暢本地運行Qwen3-4B模型,主流電腦基本均可以本地運行Qwen3-8B模型,這也代表着Qwen3小模型也可以完全勝任普通人需要的設備智能化的任務,相比滿血MoE大模型並不存在極其巨大的使用差距。
Qwen3發佈後,上下游供應鏈第一時間進行適配和調用,尤其是強調了對小尺寸模型的適配,體現了業內對其能力的認可。
英特爾官方網站顯示,英特爾在車端艙內和AI PC上都對新發布的Qwen3系列模型完成匹配,使得搭載小模型的AI PC也能成為用户助手。
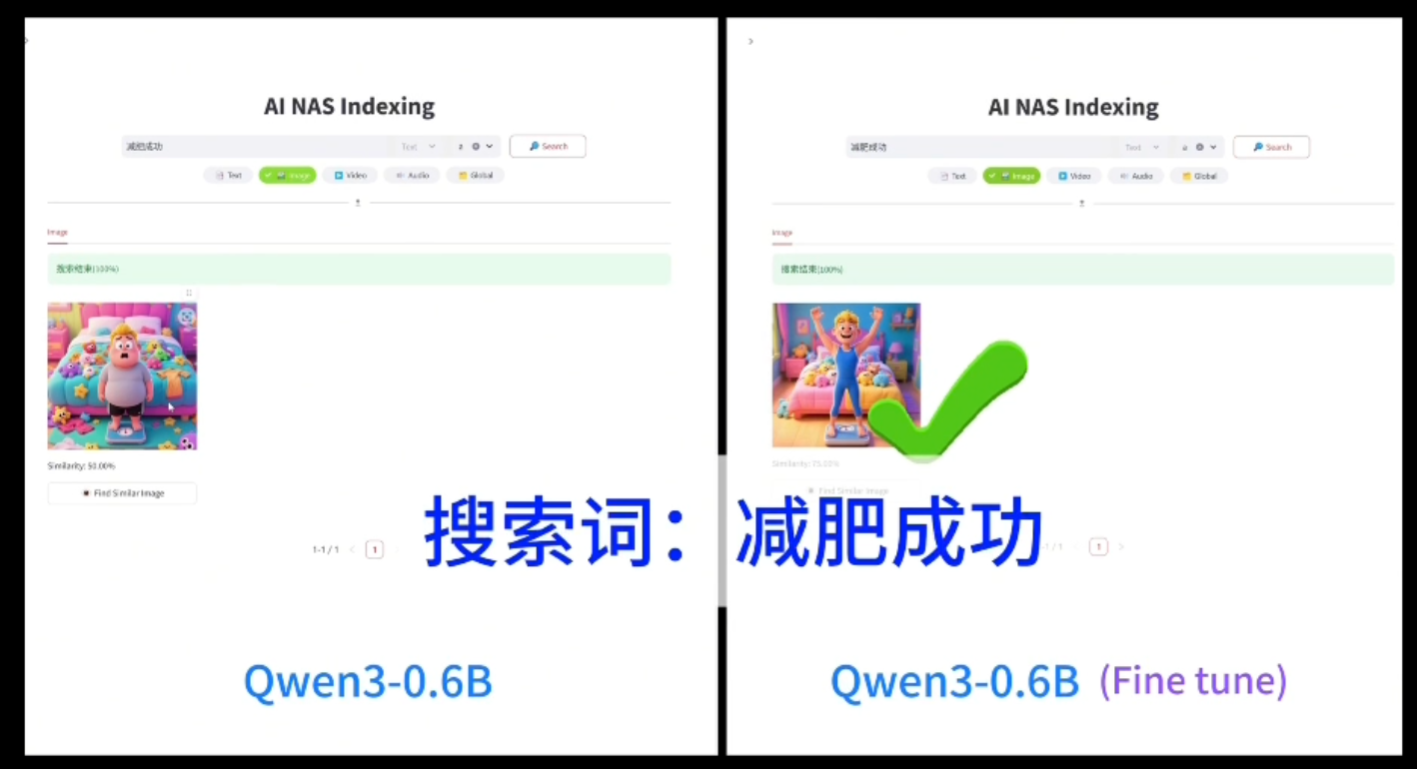
英特爾官方展示Qwen3-0.6B模型優化效果
國產芯片廠商海光信息也宣佈其DCU完成對Qwen3全部8款模型的適配+調優,覆蓋235B、32B、30B、14B、8B、4B、1.7B、0.6B各種參數。
搶佔AI應用爆發窗口期
如果説阿里更新的32B以上模型是為了對標乃至超越DeepSeek-R1,那麼在小模型的技術線上,阿里又意欲何為呢?
我們在解釋Dense模型的特性時就提到,相比MoE模型,Dense模型更加適合一些需要準確性和即時反饋的業務場景,而阿里所在的電商、物流、金融科技等領域,天然就對大模型幻覺存在較低的容忍度。Dense模型相比MoE模型,會更加容易適配諸如商品智能推薦、智能客服、智能家居、智能眼鏡、自動駕駛、機器人等領域領域,與阿里自身的業務板塊和未來的發力方向較為契合。
而且,相比上一代模型支持29種語言,本次阿里開源大模型支持119種語言。對於阿里國際站、速賣通等平台覆蓋的全球 200 多個國家和地區,多語言尤其是小語種支持可直接降低語言壁壘,提升用户體驗,屬於AI賦能自身業務的直觀體現。
而119種語言的背後也代表着阿里在持續加碼建設自己的開源生態。Qwen3系列模型依舊採用寬鬆的Apache2.0協議開源,全球開發者、研究機構和企業均可免費在魔搭社區、HuggingFace等平台下載模型並商用,也可以通過阿里雲百鍊調用Qwen3的API服務。
具體到小模型在第三方的應用,多位AI開發者對觀察者網表示,在很多場景,小模型才是真正能幹活的模型。
有人解釋道:“很多業務QPS(每秒查詢)都是以萬為數量級,而業務鏈路對於延遲的要求又極為嚴格(個位數毫秒),這種場景根本沒法塞一個大模型進去,哪怕是用7B級別的模型,對於顯存都是巨大的負擔。對於絕大部分無法承擔高額預算的企業,0.6B、1.7B的小模型有着巨大的應用價值,不僅能少吃資源,還能支持高併發。”
其補充表示:對於一些輕量的任務,不需要模型懂很多道理,只要能夠對輸入有感知,能夠識別信號輸出,就是合格的模型了。Qwen小模型的出現取代了TinyBERT,只要能夠實現快速、輕量、穩定,那麼這個模型在工業界就有很大的應用潛力。
另一位開發者則對觀察者網表示:“Qwen3-0.6B具有參數少、本地跑的特性,非常適合微調成匹配單一小任務的模型,比如文章提取、樣式整理、數據轉化,相比大模型存在巨大的性價比優勢。”
據瞭解,目前已有企業使用Qwen3的0.6B模型在邊緣設備(如工控機)部署,即時分析傳感器數據。
除了賦能自身業務和吸引開發者生態,阿里也希望通過更加先進和適配的大模型搶佔更多的C端入口。
2024年底至2025年初,阿里通過一系列組織架構調整和人才佈局推進AI To C戰略,將AI應用“通義”併入智能信息事業羣,整合天貓精靈與夸克團隊,並聘請頂尖AI科學家許主洪負責AI To C業務研發。
有市場人士認為,此輪調整的背景是阿里通義APP的普及率不及預期。
通義千問憑藉在多模態處理和複雜任務推理方面的技術優勢,曾為阿里的B端企業服務及開發者生態提供了有力支撐。諸如飛豬旅行藉助通義千問多模態模型,實現了用户方言語音規劃行程的功能;Rokid AR眼鏡搭載其技術後,能夠進行即時翻譯。通義千問在大模型開源上跑得很快,但是,其“通義”App在C端應用上並沒有使出“撒手鐧”。
AI市場競爭激烈,騰訊的混元大模型依託微信龐大的用户基礎和生態優勢,在微信多個入口為元寶爭取亮相的機會,對C端用户形成“繭房式包裹”。字節跳動旗下的豆包藉助抖音的推流優勢,在2024年11月MAU飆升至5998萬,長期霸榜AI應用下載量榜單前三。
不過阿里在C端依然有潛力應用夸克。第三方數據顯示,2025年3月,夸克的MAU(月活躍人數)達到1.48億,登上國內AI應用榜首。
當前阿里的整體AI戰略佈局,愈發強化通義千問與夸克的“雙子星”格局。通義千問專注於支撐雲上智能,夸克則着力打造端側入口,協同推動阿里AI To C戰略的落地。
隨着C端滲透率不斷提升,算力成本會成為大模型企業不可承受之重,DeepSeek就曾經在爆火出圈時遭遇算力崩潰。如果能夠用小尺寸模型承接更多C端用户需求,對於阿里自身成本控制和用户體驗,都會有潛在的重要意義。