騰訊混元上新:話沒説完,圖就生成了……
万肇生Guanchazhewanxgun

(文/萬肇生 編輯/張廣凱)
5月16日,騰訊發佈最新混元圖像2.0模型,該模型號稱改變傳統“抽卡—等待—抽卡”的方式,在行業內率先實現即時生圖,帶來交互體驗革新。
目前市面上的各類大模型中,除了非推理語言大模型的生成外,幾乎所有模態大模型的生成過程,都或多或少需要經歷等待。尤其在文生圖領域,抽卡一樣重複生成多個結果,嚴重影響效率。然而據騰訊介紹,該混元圖像2.0就主打一個“快”,支持文生圖和繪畫生圖。且無論是輸入文字指令、語音指令,或上傳本地圖、在線繪製圖,“都能毫秒級獲得高質感圖像”。

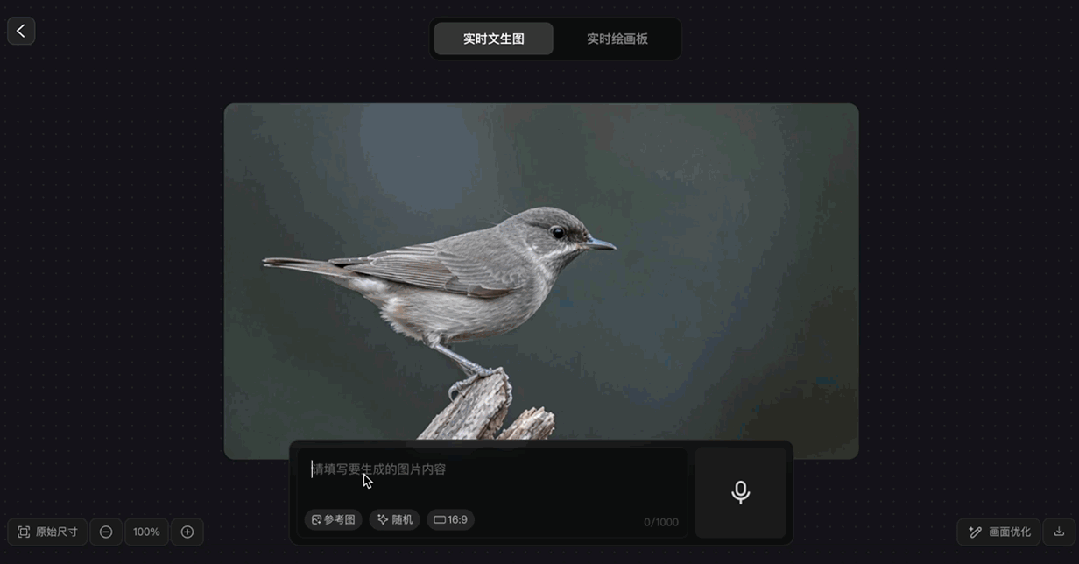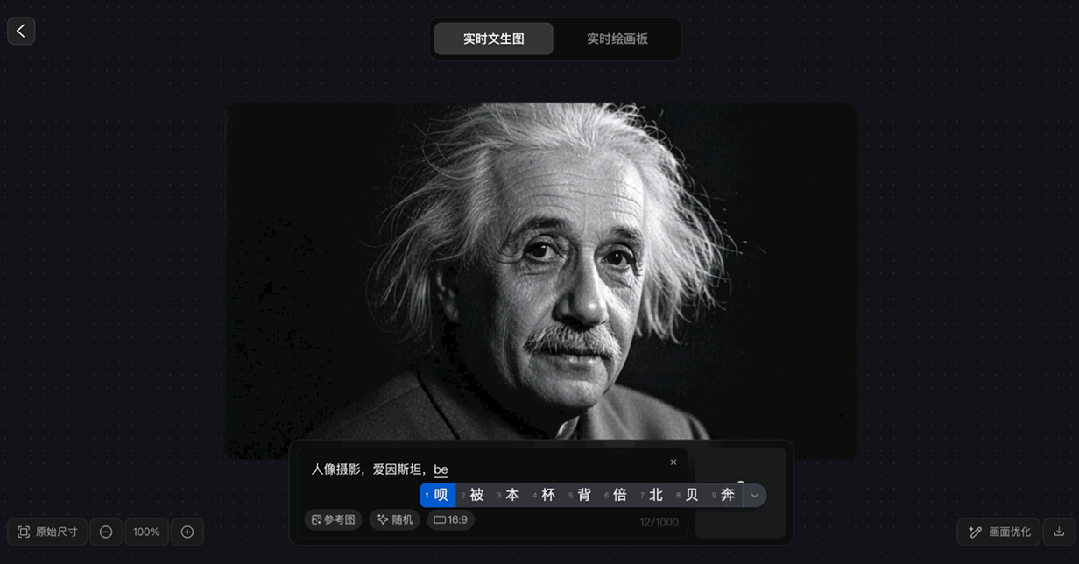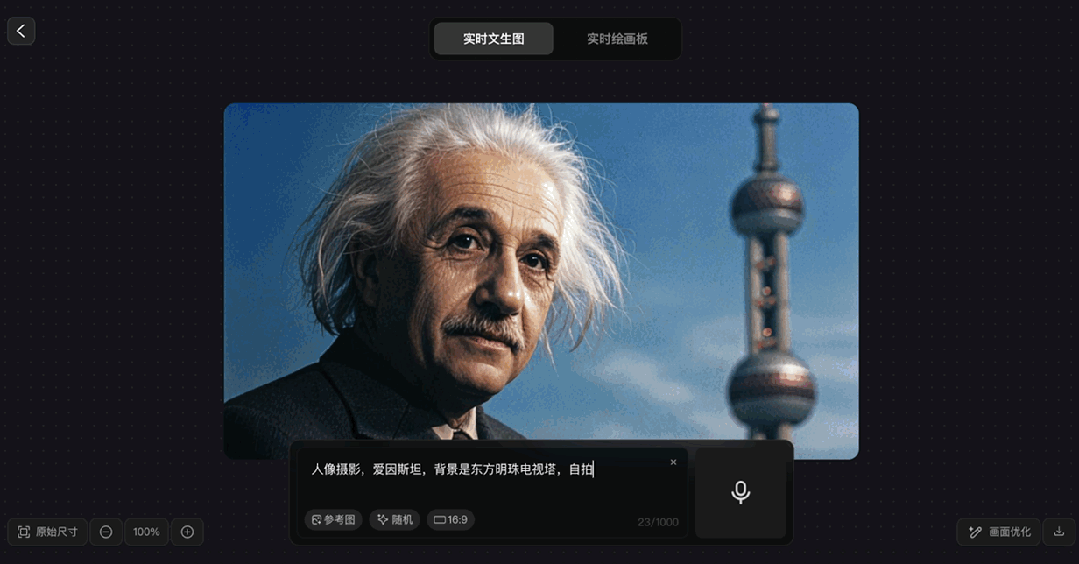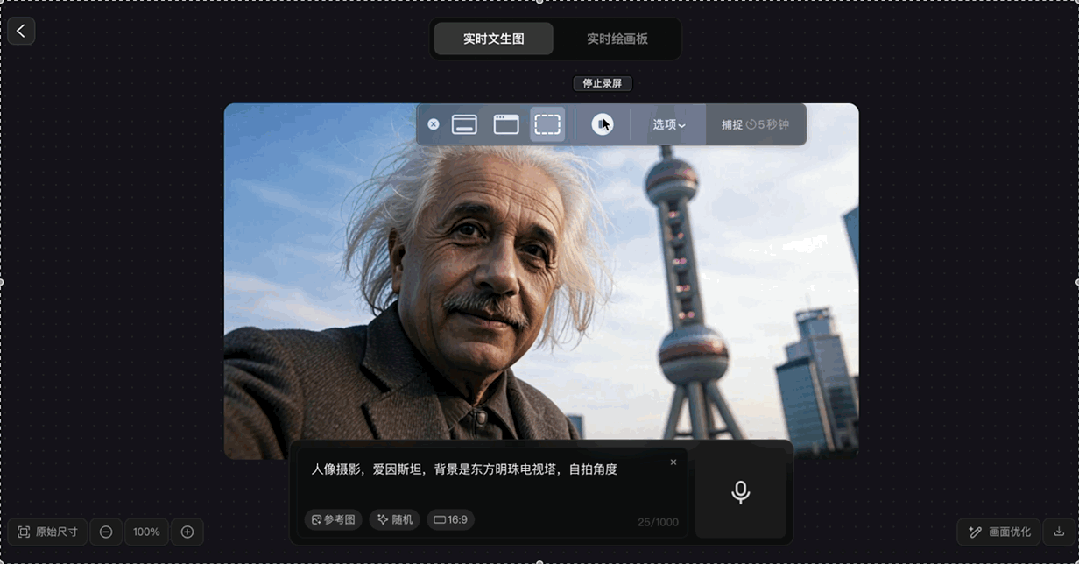
根據演示案例顯示,用户在輸入“一位女士”時,模型首先生成了一張證件照。此時在輸入框內繼續輸入“…風景照、沙漠中”,畫面的背景於是瞬間變成翠綠色,緊接着又秒變成沙漠黃。繼續再輸入“扎着頭髮、回眸一笑”,畫面也飛速切換,最終隨着輸入操作的結束,畫面直接生成完畢。
在另一個生成“愛因斯坦在東方明珠前自拍”的案例中,該模型也非常迅速的展現出整個生成的過程。
除了文生圖外,該模型還支持在圖片上使用畫筆修改的“即時繪畫板”,同樣迅速可以生成結果。
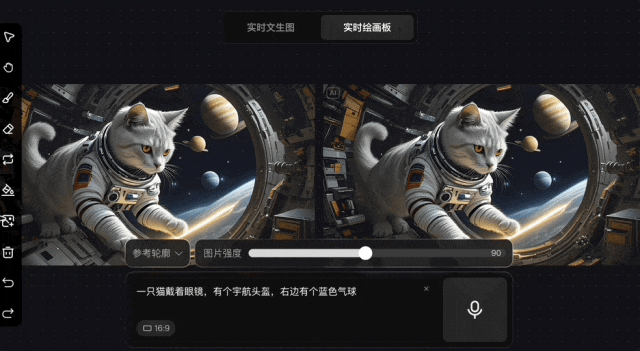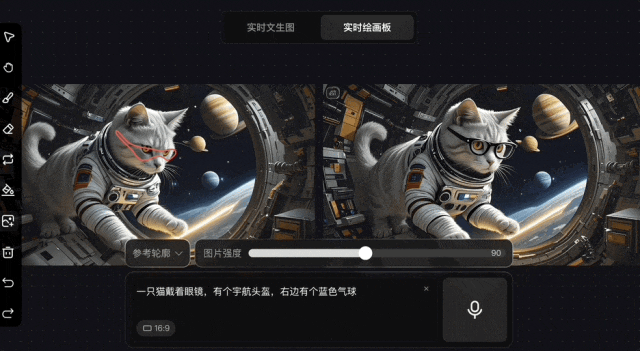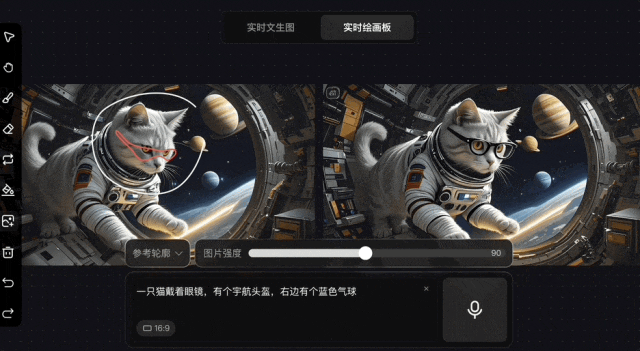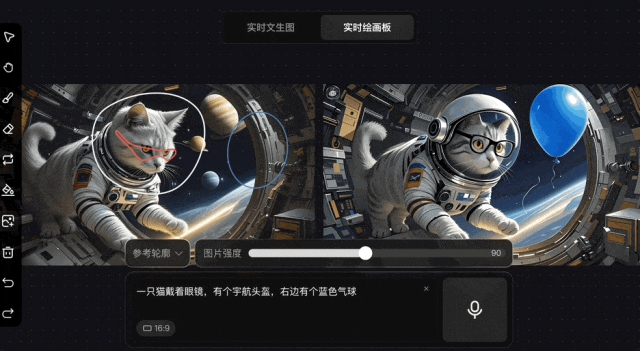
通常情況下,繪畫過程中的即時反饋可以讓用户對作品迅速做出調整,但AI圖像生成的修改往往是反覆投餵產出。因此,如果在生成的過程中可以即時進行修改,效率則將極大提高。
騰訊表示,相比前代模型,該模型參數量提升了一個數量級,得益於超高壓縮倍率的圖像編解碼器以及全新擴散架構,其生圖速度顯著快於行業領先模型。在同類商業產品每張圖推理速度需要5到10秒的情況下,混元可實現毫秒級響應,支持用户可以一邊打字或者一邊説話一邊出圖。
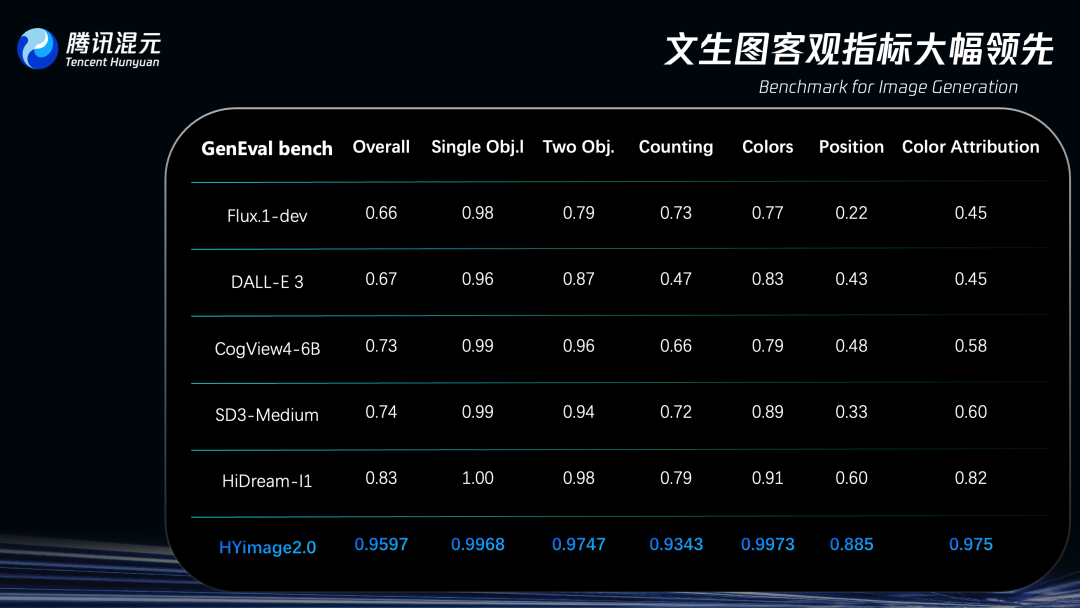
而在評分方面,騰訊稱,混元圖像2.0模型在圖像生成領域專門測試模型複雜文本指令理解與生成能力的評估基準GenEval(Geneval Bench)上,準確率超過95%,遠超其他同類模型。
目前,該模型的使用還需註冊預約。
本文系觀察者網獨家稿件,未經授權,不得轉載。