華為昇騰推出高性能保精度量化方案,更好適配DeepSeek
万肇生Guanchazhewanxgun

(文/萬肇生 編輯/張廣凱)
近日,華為公開了昇騰服務器上部署DeepSeek V3/R1推理的最佳實踐,並介紹了一系列創新技術。
其中,華為在降低計算資源需求方面,創新提出了昇騰親和的低比特量化解決方案OptiQuant,最終實現了INT8量化模式與FP8的模型推理精度持平。
由於DeepSeek V3/R1模型是基於英偉達生態訓練,並推薦使用FP8精度推理,而國產芯片普遍沒有原生支持FP8精度,導致國產芯片對DeepSeek的適配不佳。華為昇騰的上述研究應該就是為了解決這一問題。
通常情況下,在模型推理階段,進行量化(如FP8量化為INT8)可以顯著降低模型對硬件的存儲需求和計算複雜度,但也會造成模型推理精度的損失以及邏輯錯誤等問題。因此如何保持推理精度,是低比特量化滿足不同平台部署需求時的前提。
據華為介紹,基於BF16的DeepSeek需要1.3TB的顯存空間,同時導致極大的算力和跨機通信開銷。而校準集的泛化性缺失導致了在很多任務上難以達到與原有模型相近的精度水平,甚至在某些場景下精度下降十分嚴重。同時,還要考慮如何設計昇騰親和的量化算法,以發揮硬件性能。
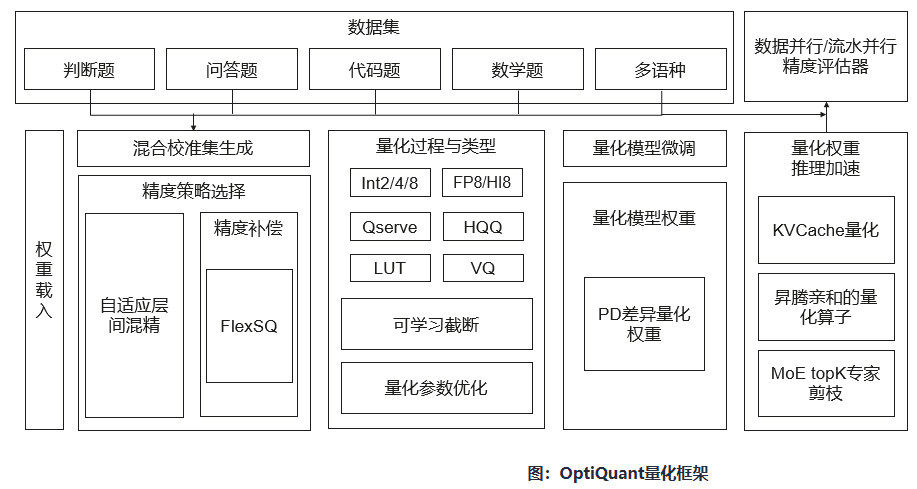
針對上述問題,華為提出了OptiQuant量化框架,一種高性能保精度量化方案,設計了層間自動混精、自動混合校準、離羣值抑制、可學習的截斷和SSZW參數量化算法。除了支持業界主流量化算法功能之外,它還新增支持三個功能:接入自定義量化算法和數值類型,可以將多種量化算法的自由組合搭配使用;支持業內主流評測數據集和用户自定義的數據校準集;支持數據並行和流水並行,針對不同大小的大語言模型實現精度驗證性能加速。
OptiQuant框架主要由以下幾個模塊組成:
量化類型和數值類型:OptiQuant支持了Int2/4/8和FP8/HiFloat8等數據類型,支持業界的Qserve,HQQ,LUT等量化方法,在此基礎上提出了可學習截斷和量化參數優化等算法,進一步減少了量化誤差。
**多樣化測試數據集和用户自定義校準集:**多樣化測試數據集和用户自定義校準集:OptiQuant支持了判斷題,問答題,代碼題和數學題等多種測試類別,語種上支持了十種常見語言。此外,OptiQuant支持用户自定義校準集,提升模型量化過程中的泛化性。
量化權重生成:OptiQuant提出了自適應層間混精算法,並且根據對應的量化配置生成對應的權重參數,通過去冗餘技術減少參數保存的參數量;OptiQuant進一步提出了FlexSQ等算法,在數據校準過程中,對大模型激活異常值進行了平滑處理,有助於對激活做低比特量化。
最終,基於Atlas 800I A2服務器的精度測試實驗結果顯示,對於DeepSeek-V3-0324模型,W8A8C16和W4A8C16均採用Per-channel量化,實現了推理精度與FP8-GPU持平。
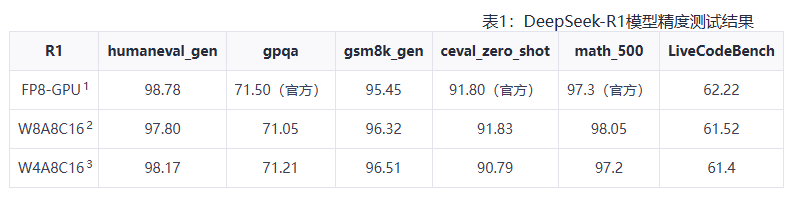
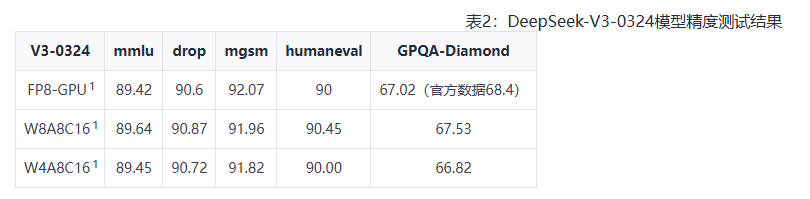
華為表示,在DeepSeek R1/V3大模型推理場景中,實現了INT8量化模式與FP8的模型推理精度持平,而且進一步發揮了華為Atlas 800I A2和CloudMatrix384集羣推理硬件性能。而相關代碼也將逐步開源。
本文系觀察者網獨家稿件,未經授權,不得轉載。