騰訊混元開源首款混合推理MoE模型
胡祥熙

6月27日,騰訊混元宣佈開源首個混合推理MoE模型 Hunyuan-A13B,總參數80B,激活參數僅13B,效果比肩同等架構領先開源模型,但是推理速度更快,性價比更高。這意味着,開發者可以用更低門檻的方式獲得更好的模型能力。
即日起,模型已經在 Github 和 Huggingface 等開源社區上線,同時模型API也在騰訊雲官網正式上線,支持快速接入部署。
這是業界首個13B級別的MoE開源混合推理模型,基於先進的模型架構,Hunyuan-A13B表現出強大的通用能力,在多個業內權威數據測試集上獲得好成績,並且在Agent工具調用和長文能力上有突出表現。
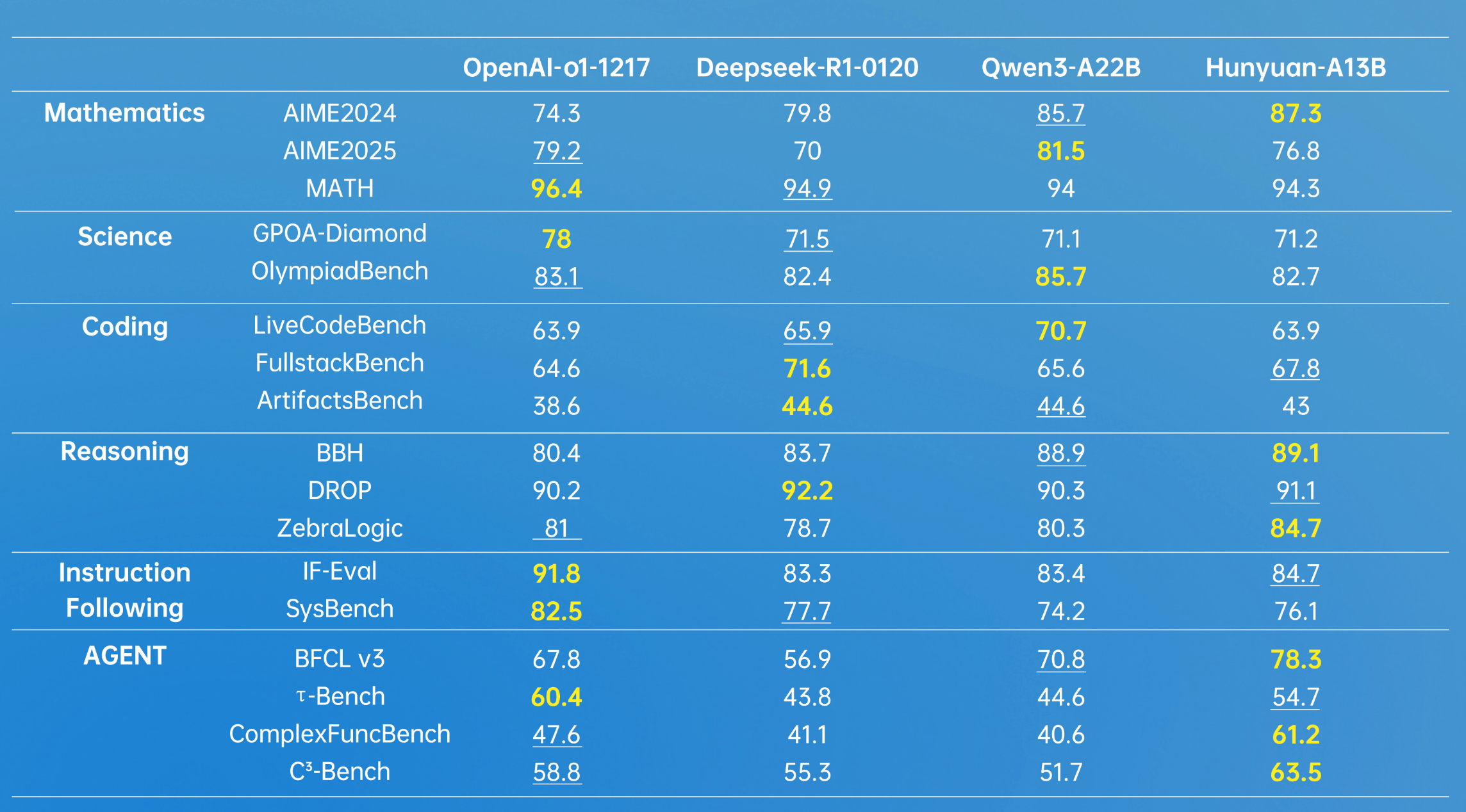
加粗為最高分,下劃線是第二名,數據來源於模型公開的測試數據集得分
對於時下熱門的大模型Agent能力,騰訊混元建設了一套多Agent數據合成框架,接入了MCP、沙箱、大語言模型模擬等多樣的環境,並且通過強化學習讓Agent在多種環境裏進行自主探索與學習,進一步提升了Hunyuan-A13B的效果。
在長文方面,Hunyuan-A13B支持256K原生上下文窗口,在多個長文數據集中取得了優異的成績。
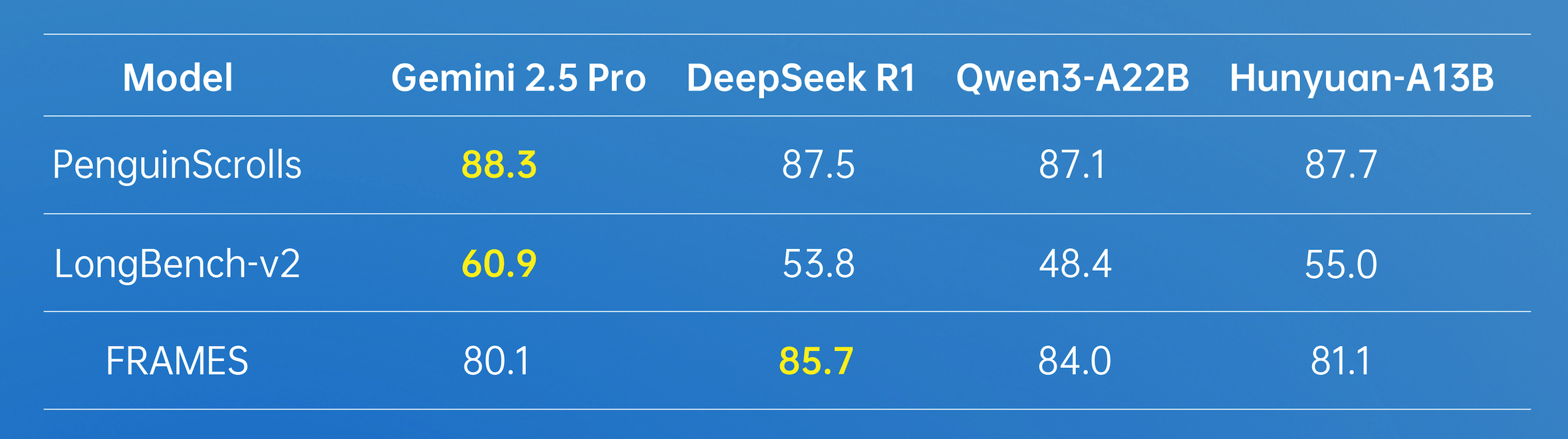
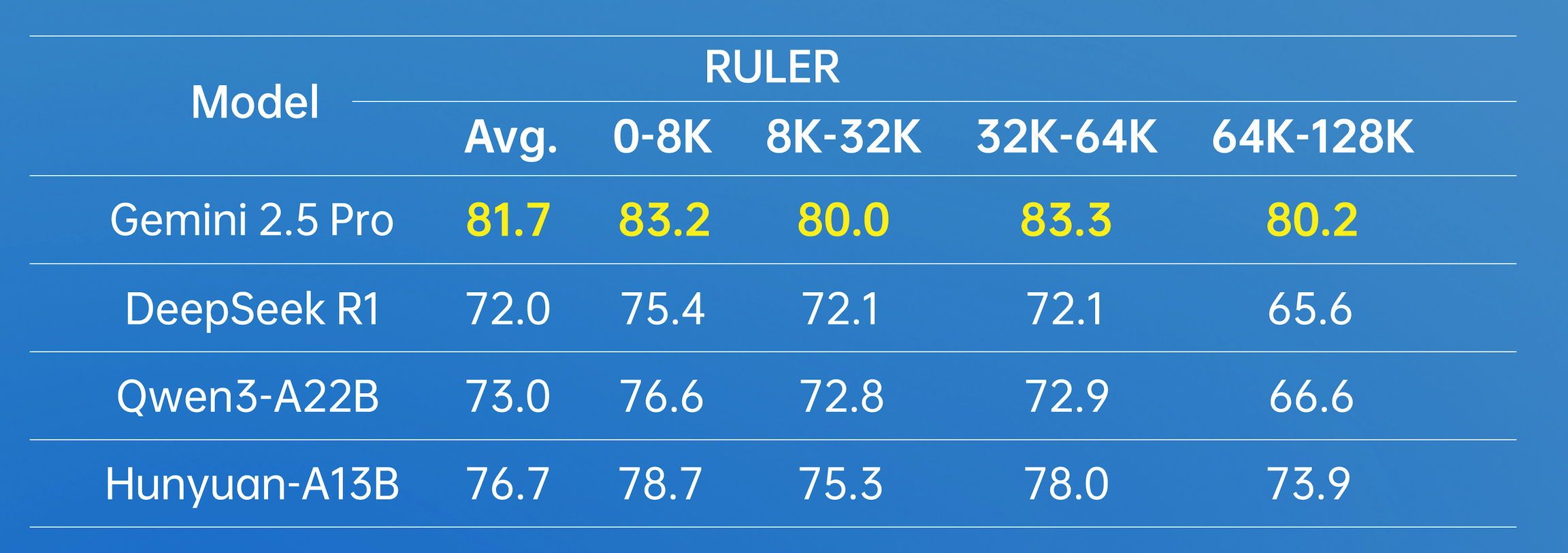
在實際使用場景中,Hunyuan-A13B模型可以根據需要選擇思考模式,快思考模式提供簡潔、高效的輸出,適合追求速度和最小計算開銷的簡單任務;慢思考涉及更深、更全面的推理步驟,如反思和回溯。這種融合推理模式優化了計算資源分配,使用户能夠通過加think/no_think切換思考模式,在效率和特定任務準確性之間取得平衡。
相關資料顯示,Hunyuan-A13B模型是騰訊內部應用和調用量最大的大語言模型之一,有超過400+業務用於精調或者直接調用,日均請求超1.3億。
混元官方界面截圖
官方界面中顯示,該模型支持快慢思考模式切換,數學、科學、長文理解及Agent能力全面提升。其中,快思考模式適合追求速度和最小計算開銷的簡單任務,而慢思考模式則涉及更深、更全面的推理步驟,這優化了計算資源分配,兼顧了效率和準確性。
在實測中,觀察者網測試了小數比較大小,基本的四則運算等多種基本數學題目,Hunyuan-A13B模型都能迅速響應並給出正確的回答。

測試問題
據悉,混元團隊還開源了兩個新數據集,以填補行業內相關評估標準的空白。其中,ArtifactsBench主要用於代碼評估,構建了一個包含1825個任務的新基準;C3-Bench則針對Agent場景模型評估,設計了1024條測試數據。
本文系觀察者網獨家稿件,未經授權,不得轉載。