生成高考志願報告突破1000萬份,夸克首次公開回應技術細節
周毅是故意的还是不小心?

作為一款輔助高考志願填報的神器,夸克最新“戰報”出爐。
觀察者網獲取的最新數據顯示,截至7月1日,阿里巴巴AI旗艦應用夸克已累計為考生和家長生成超1000萬份專業級志願報告。這些報告由今年推出的“志願報告”Agent生成,採用了具備“任務規劃—執行—檢查—反思”能力的深度研究技術。業內認為,這一成果已成為國內最大規模的深度研究技術應用。
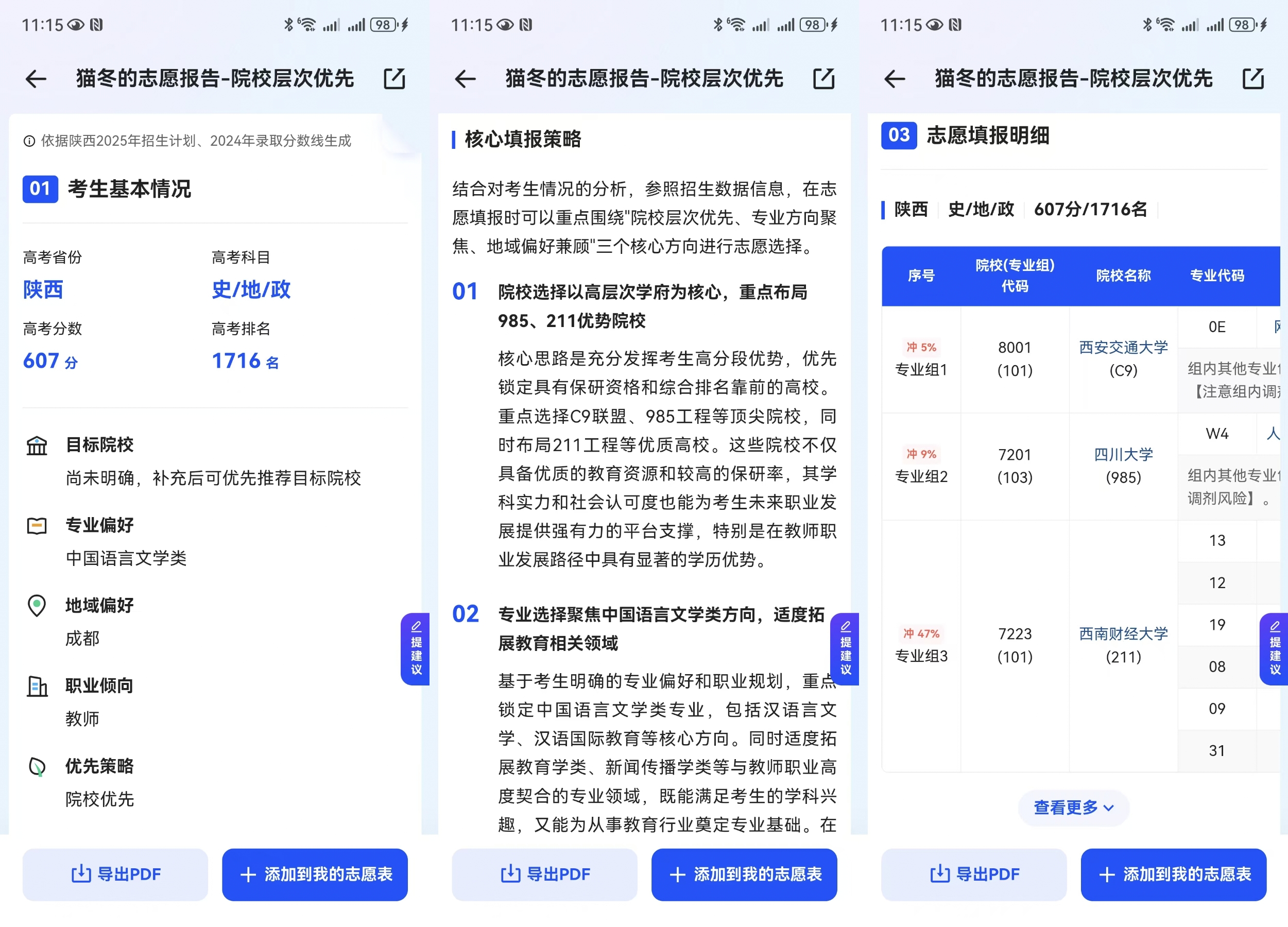
夸克高考志願功能實測應用軟件截圖
公開資料顯示,“志願報告”Agent具備高度個性化與策略性,能夠基於用户信息規劃思考路徑,調用搜索工具進行信息收集,通過志願工具進行志願表操作,過程中不斷進行檢查和反思。Agent底層由夸克高考志願大模型與專業的高考知識庫提供支持,具備接近專家水平的決策能力。
在執行過程中,Agent通過多輪“工具調用+反思調整”的機制,動態優化志願方案。例如,當考生表達“傾向留在省內(廣州、深圳優先)、不考慮偏遠地區”時,模型會自動生成搜索指令:優先推薦廣州、深圳的高校,其次考慮廣東省內其他城市院校,排除偏遠地區選項;若優質選項受限,Agent還能主動反思擴展搜索範圍,如增加廣東周邊發達城市,或在高層次高校(如985)上適度放開地域限制,為考生爭取衝一衝的機會。
此外,Agent具備處理複雜、甚至自相矛盾訴求的能力。面對“數學成績差,但想報考計算機”這類常見衝突,系統會觸發“需求澄清”流程,提示用户這一選擇可能存在的能力匹配問題。這種專家式的思考路徑和策略調整,是傳統工具難以實現的,也是夸克“深度研究”技術真正實現智能化決策的關鍵所在。
AI到底是如何幫助考生實現“志願規劃”的?在日前的一場活動上,圍繞夸克高考AI技術背後的各項細節,夸克算法負責人蔣冠軍和夸克高考技術負責人唐亮,與觀察者網等媒體進行了一次深度分享。

夸克團隊回應技術細節
媒體提問:夸克是如何為考生填報志願提供輔助的,它的核心能力是什麼?
**夸克算法負責人蔣冠軍:**高考志願報告要解決的一個核心問題,是幫助用户獲取大量複雜信息,然後根據這些複雜信息來幫助用户做決策,完成學校報考。高考志願填報產品,與其他通用產品圍繞大模型做的問答產品,有非常大的差異。它必須專業、準確,而且必須個性化——在沒有大模型以前,這個能力是傳統問答無法做到的。
從高考的基本邏輯來講,我們提供的是一個“三位一體”的產品:其一是類似通用搜索的能力,用大模型將所有高考相關的問答進行系統性升級;其二是志願工具,用户可以輸入分數、學科,通過各項篩選工具的勾選,來生成參考建議。
其三是免費的志願報告,用户可以根據志願報告反向查詢基本信息,修改志願需求等等——對於很多高考考生或者家庭來説,他們最大的問題其實是不知道怎麼填報。他得到了一個分數,但是對於學校、專業,包括將來的就業、考研等這些信息其實都不熟悉。
媒體提問:收集和輸出高考相關信息時,其準確性夸克是怎麼保證的?
**蔣冠軍:**數據方面,我們必須要做到專業、準確。以前的技術方法是做通用搜索,在H5網頁生態裏去篩選相對比較優質和權威的數據。但傳統方法下,信息散落在多達幾百億個網頁之中,錯誤非常多。因此我們現在精選了與高考直接相關的幾十億個網頁,並對它們進行信息的準確性識別,以及質量分析等工作,包括收集大量非H5網頁。
很多高考政策或者學校招生信息,都收錄在相關機構和院校的官網裏。但是有一個潛在問題,這些官網和機構,在市場上並不是“知名站點”。傳統的通用搜索引擎很可能因為它是一個小站點,或者平時用户量少,相關數據收錄就比較少。因此,我們在這上面投入了大量的人力,把各種網站裏的專業資料、政策都蒐集進來。
**夸克高考技術負責人唐亮:**高考問答我們每年都會做,在去年基礎上,今年我們重點強調高考的專業知識庫概念。專業知識庫我們總共蒐集了8000多個站點,大概覆蓋了20多億數據,高考相關的權威站點佔比99%以上。對這8000多個站點,我們內部也會有些分層,比如有些像考試院、教育部、招生辦這部分肯定是政策相關最權威的。
還有一個是“政策庫”。每年志願填報可能都會不間斷地出些新政策,我們也會人工即時更新,通過人工與組織監控的方式,補足到政策庫裏,讓整體數據可以有詳細更新。非H5網頁部分,我們會把整個高考高校近三年的就業數據、考研數據和招錄體檢要求等信息,包括政府報告、行業研究分析收集進來。基本涵蓋了市面上所有的數據。
媒體提問:有設計保障措施嗎,從而進一步保障數據準確性?
**唐亮:**對於從各個渠道拿到每個省的招生計劃以及歷年分數線,這部分數據我們差不多有七年時間的積累。這裏面主要核心工作是兩大部分:一部分是數字對齊,用算法、用大模型去做招生計劃和分數線的對齊;另一部分是通過上百人的人工審核方式,對那些“不置信的內容”進行人工審核。
**媒體提問:**高考志願填報所用到的大模型,和傳統的通用大模型有哪些區別?
**唐亮:**獲得海量權威數據之後,我們要把它應用在高考志願大模型裏。這裏主要有兩個地方會應用到,第一個是作為RAG(Retrieval-Augmented Generation,檢索增強生成,旨在解決傳統大模型幻覺問題和知識滯後性侷限)材料內容供給,我們做材料結合時,會強調材料來源是高時效、高權威。
第二個方面,我們會把這些數據應用到高考志願大模型的訓練當中,讓它們作為訓練語料,幫助模型打磨這部分知識。在模型訓練時,我們會做大量的思路性校驗、數字校驗、即時性校驗等,相比通用模型有效降低幻覺率。
媒體提問:拿到招生計劃,怎麼進行“預測”?
**唐亮:**我們知道了當年的招生計劃以及歷年數據,那麼第一步就是預測今年的情況。我們會結合今年的情況和歷年的變化趨勢,判斷這個志願今年是下跌還是上漲,給出大概的下跌上漲區間。還有就是判斷每個分數段擴招、多招情況,對於擴招、多招數據進行一定比例的預測,這樣就會預測出今年大概是怎樣。
預測完志願波動變化範圍,比如一些top的非常好的學校,其實每年波動會非常少,而像一些中低分段學校比如專科院校,波動範圍比較大的,我們會統計每個省份每個分數段根據選科情況看波動範圍。根據波動範圍以及對應的政策,大概有個志願的動態分佈。再看考生在動態分佈的哪一個位置,那個位置就是我們預測的概念。
這裏面會出一些其他情況:比如説新專業或者新學校,我們如何去預測得更準?對於新專業,我們會拿各個學科相近的專業對參考;新學校我們也會看各個學校相似的學校,通過相似專業相同學校去看新專業新學校相對的範圍。
我們所做的工作,是讓用户可以通過我們的志願工具,通過篩選的方式獲取到志願報告。這個過程中用户可能循環多次,最終才能拿到想要的志願報告。報告給用户帶來的是什麼?用户輸入自然文本,我們把它“翻譯”成用户訴求,然後去檢索、生成合適的結果。
媒體提問:也就是説,“志願預測”本質是一個多環節環環相扣,理解用户並提供參考的過程。
**唐亮:**這個環節的第一步是規劃。用户輸入信息,我們的工具要把這個信息進行志願規劃,開展工作任務。那麼就先要明確用户大概的分數水平,去判斷他在什麼範圍,後續再引入各項指標:他對學校層級的要求,對專業的要求,對地域的要求,對未來規劃的要求……把它拆成一個一個的規劃問題。
第二個步驟是對規劃任務進行執行。這需要調用搜索工具,因為可能會有比較模糊的概念,比如説如何理解“數學成績比較差”,當然也可能需要藉助高考知識庫。數學成績差的,可能就不太適合填報那些對數學成績要求比較高的學校、專業。如果數學成績比較好,可能計算機、數學統計等專業就比較適合。
接着,我們要把用户訴求轉變成操作志願表的指令。比如有的考生想留在省內,例如“廣州深圳優先,不想去偏遠地區”,我們需要把這樣一句話(自然語言文本)轉化成地域維度的操作指令:最高優先級是廣州和深圳,次優先級是廣東省內,最低優先級是偏遠地區。我們要把這樣的範圍文本,變成操作志願表的專業指令。
“指令”被髮送給志願表,讓其進行操作,就會形成反饋。我們會根據他反饋的結果規劃下一個執行什麼:如果反饋適配的結果比較少,那麼我們可能會藉助專家建議,去進行反思以及拓展。
比如説,一位考生選擇廣東深圳優先,但適合的廣州深圳的志願比較少,那可能就會把條件放開,比如放開到廣東省;如果考生選擇了那些高層次的985,那麼可能就會突破一些限制,廣東省周邊的高層次院校,也可以進行推薦。我們通過來回的規劃任務執行、檢查和反思,去生成多條指令來操作。
媒體提問:相當於給考生的不同需求,加上不同的權重。綜合生成一套方案出來。
**唐亮:**在操作過程中,指令會被分成幾個維度,有可能會是對高校層級的要求,有可能是對專業的要求,有可能是對地域的要求,有可能是對招生計劃,甚至比如説學校氛圍、學校便利性以及住宿要求,食堂要求,周邊交通要求等等……它們都會被歸納到六個維度,系統分別給這六個維度打分。
通過執行、檢查、反思過程,系統會把它轉化到操作志願表的指令,最終我們會根據每個維度的打分,根據用户訴求,生成一個最終的志願表。因為執行過程中我們可以每個志願打分六個維度結構,綜合用户對每個維度的訴求,給他綜合排序。最終,系統會把整個過程規劃、反思過程寫成一份整體志願報告,形成完整的整理過程。
在這裏面,我們其實藉助了非常多的專家支持。比如説構建Agent過程中,我們訓練模型時會根據專家線下一對一的志願填報過程,蒐集專業數據。比如專家和家長老師的對話過程,裏面有很多相關的訴求數據。當然也包括專家面對考生時的分析思路,以及專家怎麼給不同考生的個性化推薦內容,以及每個地方的政策要求。
在冷啓動時,我們根據線下老師一對一的數據進行訓練,訓練之後還有託管模式,託管後可以用線上的真實數據構建RLHF(Reinforcement Learning from Human Feedback,基於人類反饋的強化學習)數據。拿到線上用户真實反饋數據之後,我們在線下也會讓多個專家進行維度打分。
線下打分主要是兩大維度,一是整體規劃執行過程是否合理,二是最後生成內容排序是否合理,專業匹配是否合理,它們會由專家老師打分,形成“獎勵”維度。我們志願決策,會獎勵模型一部分,去優化剛才執行過程志願表打分過程,優化之後形成最終的完整算法。整體過程就是這樣。
(發言系現場錄音整理,未經當事人審訂)