國產大模型與AI芯片聯盟,意義有多重大?-好評
guancha

系統性思維,一直都是中國產業從後發地位邁向先進水平的寶貴經驗,如今這一幕也正在AI領域發生。近日,10家國產大模型、AI芯片和算力加速企業攜手成立“模芯生態創新聯盟”,開始探索從大模型開發階段就去適配國產AI芯片,為國產芯片產業協同打開了新思路。與此同時,上海企業在聯盟中佔據半壁江山的現象,也正是上海高科技產業一向重視軟硬結合,產業鏈一體化完備程度的厚積薄發。
(文/觀察者網 張廣凱)
沐曦陳維良、天數智芯蓋魯江、燧原趙立東、壁仞張文,四家國產算力芯片領軍企業的創始人同台對話,即使不是第一次,也是非常罕見的一幕。

更耐人尋味的是,這一幕出現在大模型企業階躍星辰的發佈會上。
7月25日,作為今年世界人工智能大會的一部分,階躍星辰在上海發佈了新一代SOTA級的多模態推理大模型Step 3。
作為著名的“多模態卷王”,如果説Step 3本身的模型能力已經不會太讓人意外,那麼這次發佈會上更大的驚喜,來自於其對國產芯片的強大適配能力——據介紹,Step 3在國產芯片上的推理效率最高可達DeepSeek-R1的300%。
同日,階躍星辰聯合近10家芯片及基礎設施廠商發起“模芯生態創新聯盟”,首批成員包括華為昇騰、沐曦、壁仞科技、燧原科技、天數智芯、無問芯穹、寒武紀、摩爾線程、硅基流動等。
階躍星辰的名字來自數學中的“階躍函數”,這個函數常用來描述從0到1的突然跳變。當英偉達H20都面臨“斷供”風險,國產算力今年已經成為大模型企業的必選項。這個趨勢當然不僅僅歸功於階躍星辰,但國產模芯生態卻如“階躍函數”一樣正在快速躍遷。


當模型和芯片變成一個系統
自從今年初DeepSeek爆火出圈之後,人們已經習慣了用“DeepSeek時刻”來形容中國大模型產業的進步。但是屬於DeepSeek自己的下一個“DeepSeek時刻”,卻遲遲沒有到來。
早在2月份,就有消息稱DeepSeek計劃於5月發佈下一代推理模型R2,甚至有可能提前。但截至目前,R2仍然未能亮相。知名科技媒體The Information曾指出,英偉達H20芯片此前的禁售風波,可能是DeepSeek計劃跳票的重要原因。
DeepSeek此前的V3和R1模型,均是基於英偉達芯片訓練。昔日還以幻方量化知名的梁文鋒曾在採訪中承認,他在2021年就已經囤積了萬張英偉達顯卡。直到2023年,幻方擁有的英偉達顯卡都超過國內很多頭部大廠,這是DeepSeek成功的物理前提。
如今英偉達顯卡屢屢出現斷供風險,影響的不是僅僅DeepSeek自身的模型訓練,也讓下游那些並非財大氣粗的用户在部署時遇到麻煩。隨着華為昇騰等國產芯片的性價比逐步超越H20,越來越多的用户和算力廠商開始轉向國產芯片。
但DeepSeek V3和R1的優化原本是針對英偉達H800這樣的高端芯片,用在國產芯片時仍然需要大量的適配工作。算力加速平台硅基流動的創始人袁進輝曾透露,為了在華為昇騰芯片上適配DeepSeek,其團隊與華為工程師整個春節假期都沒有休息。
現在,階躍星辰想從根本上解決這個難題。
在Step 3的發佈會上,階躍星辰創始人、CEO姜大昕展示了兩組數據:
在國產芯片上,Step 3的推理效率最高可達DeepSeek-R1的300%;而即使在基於 NVIDIA Hopper 架構的芯片進行分佈式推理時,實測Step 3相較於 DeepSeek-R1的吞吐量提升了超過70%。
這樣的效率提升是如何做到的?
“過去,產業把開發順序搞反了。”階躍星辰聯合創始人、副總裁朱亦博對觀察者網解釋説,一款芯片的開發週期需要兩年以上,而如今模型迭代的速度只有半年到一年,如果讓芯片廠商去適配模型,必然是低效的,可能等到適配做好了,模型早就迭代了。
觀察者網瞭解到,隨着大模型算法創新層出不窮,業內對於其硬件適配性早就不乏詬病,甚至有“算法搞創新,infra擦屁股”的説法。
而階躍星辰選擇了在模型開發階段,就主動去服務於國產芯片的特性。
朱亦博舉例説,目前國產芯片的製程工藝、HBM(高帶寬內存)等性能還相對落後,導致在算法設計上需要去做一些調整。
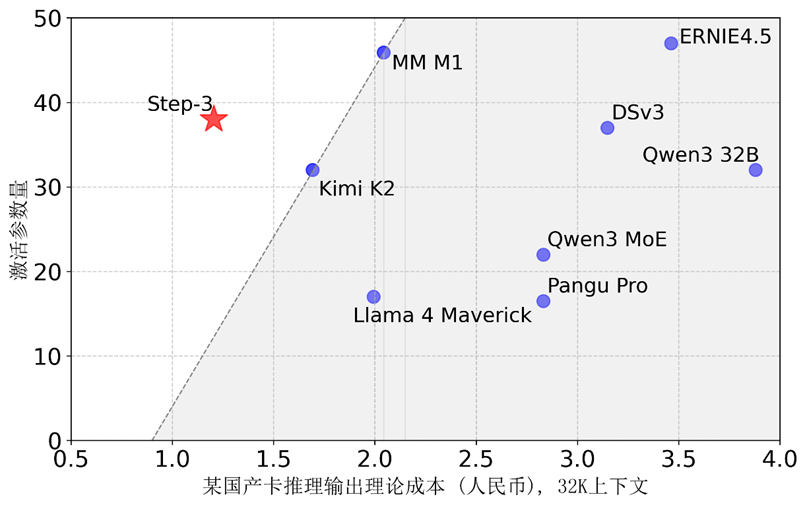
階躍星辰展示的圖片顯示,在算術強度(Arithmetic intensity)特性上,DeepSeek V3更適配於H800芯片,阿里Qwen 3更偏向H20,而Step 3則與昇騰910B更加接近。
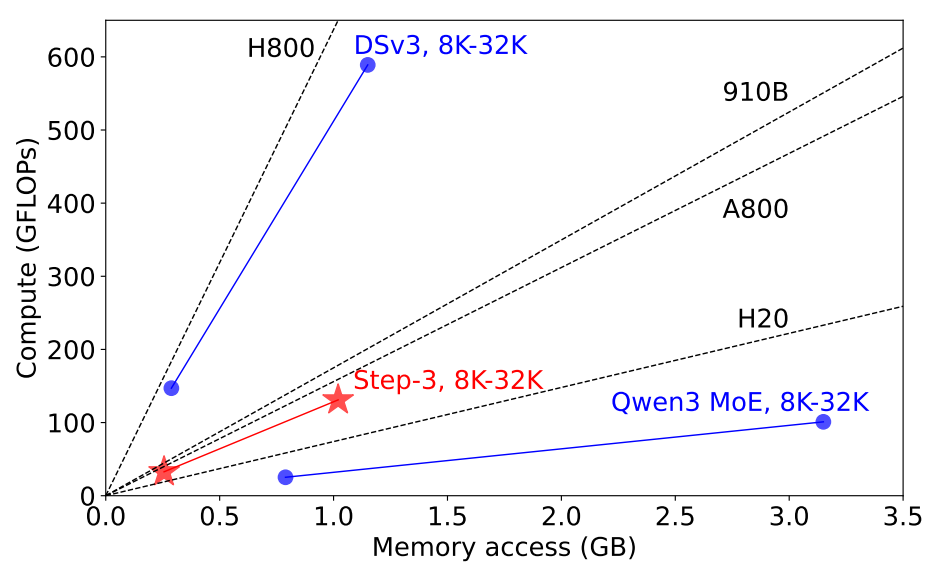
這得益於今年初階躍星辰發佈的一種新型注意力機制架構——多矩陣分解注意力(MFA)。在當時DeepSeek的光芒下,這個成果並未廣泛“出圈”,但是相較於DeepSeek採用的多頭注意力機制(MLA),MFA能夠把推理過程中的鍵值緩存(KV Cache)用量大幅降低93.7%,對國產芯片更加友好。
換句話説,階躍星辰主動跳出了一家單純的大模型企業視角,而是把模型和硬件視為相互協同的系統。沐曦創始人、董事長兼總經理陳維良直言,“階躍星辰對於國產芯片的瞭解深度,已經不亞於芯片企業本身”
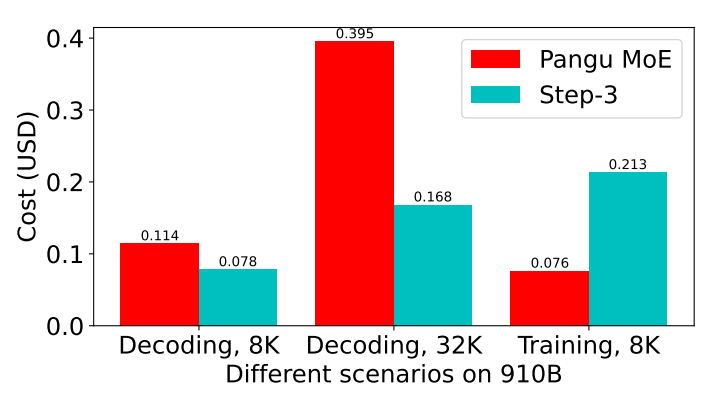
下面這張圖更加直觀地展示了階躍星辰這種思維方式的成果:在昇騰910B上,Step 3的解碼效率甚至超過了華為自家的盤古 Pro MoE模型,這還是在盤古 Pro MoE實際激活參數不到Step 3一半的情況下。
如今,階躍星辰與諸多硬件廠商成立“模芯聯盟”,意味着過去技術層面的系統思維,有望走向更深度的戰略協同層面。
朱亦博對觀察者網介紹,這個聯盟的初步目標,是將各自的產品開發進度相互同步,並希望在此基礎上建立長期信任以及合作關係,“也許未來新一代芯片上市前,我們就可以比較早地獲取它的一些設計。”
這勢必會給階躍星辰的未來模型研發帶來獨特優勢,而與此同時,姜大昕也向觀察者網表示,歡迎更多國內大模型企業加入聯盟。

國產芯片訓練仍難突破
儘管以階躍星辰為代表的眾多國產大模型公司都開始重視對國產芯片的適配,但到目前為止,主要的適配工作都發生在推理環節,而基於國產芯片的訓練仍然是行業難題。
困難同樣來自軟硬兩個維度。
大模型的“大”主要體現在訓練階段數據和參數量的龐大,而訓練完成的大模型,在推理階段並不需要激活所有參數量,因此對算力消耗更小。
當前,美國大模型公司在訓練環節使用的芯片集羣規模已經達到10萬卡,而國內大模型往往使用以英偉達芯片為主的萬卡集羣。
目前,明確使用全國產算力的芯片集羣是科大訊飛與華為共建的“飛星二號”,能夠達到萬卡級別,今年剛剛走到首批算力交付的階段。而且考慮到華為單卡算力的劣勢,“飛星二號”在總算力上仍然難以同英偉達集羣媲美。
本次人工智能大會上,華為也首次展出了384張芯片集成的超節點機櫃,在算力上超過英偉達的NVL72,但考慮到芯片數量和光模塊的大量使用,其功耗和穩定性仍然有待檢驗。
而其它國產芯片在集羣規模上也存在明顯差距。在無問芯穹與上海算法創新研究院的合作中,雙方成功基於3000卡沐曦國產GPU集羣,穩定支撐百億參數大模型訓練長達600小時不間斷,這已經是國產算力模型訓練的記錄。
除了芯片集羣的困難,大模型企業想要在國產芯片上進行訓練,也需要根據芯片不同的架構去重新構建底層工具鏈,其難度同樣巨大。
需要承認的是,當下國產大模型百花齊放,一定程度上也是建立在英偉達CUDA生態提供了成熟的工具鏈,而工具鏈的開發人才由於要掌握硬件知識,往往比大模型的人才更加稀缺。
因此,國產芯片在推理側的進展令人欣喜之餘,我們也仍要正視同英偉達生態的差距。

下一個聖盃:多模態
但是樂觀地説,當下大模型的技術演進遠遠沒有結束,這也意味着,如果能夠在新技術範式上佔得先機,基於國產芯片的大模型開發生態仍有彎道超車空間。
多模態就是下一個機會所在。
儘管多模態模型落地已經如火如荼,但業界共識認為,屬於多模態的“GPT-4時刻”尚未真正到來。也就是説,如今多模態的推理模型尚不成熟,理解生成一體化尚未實現,世界模型也還較為遙遠,這都意味着,其基礎架構仍有很大創新空間,國產芯片對模型的適配也可以從更早期階段起步,避免如語言模型一樣的英偉達一家獨大。
而中國多模態應用生態的繁榮,也為相關企業提供了充足彈藥。
例如,階躍星辰日前首次公佈了明確的收入指引——預計今年全年營收達到10億元。
“AI六小龍”公司此前都沒有明確公佈過自己的經營狀況,可以作為對比的是,有媒體報道智譜2024年的收入約2-3億元,而虧損可能達到20億元。
這意味着,階躍星辰除了與上游硬件廠商的結合,在下游用户的結合上也有獨到之處。
其最核心的秘訣自然還是多模態。
過去一年中,階躍星辰已經發布了十餘款多模態模型,包括Step系列的基礎模型,以及語音、視覺理解、圖像編輯、圖像和視頻生成、音樂等諸多垂直模型。本次WAIC期間,階躍亦升級了多模態模型矩陣,包括階躍首個多模理解生成一體化模型Step 3o Vision,第二代端到端語音大模型Step-Audio 2。
業內普遍認為,相比於語言模型的不斷刷榜,多模態正在成為當下大模型和Agent產品落地需求最大和最有利可圖的賽道。這讓“六小龍”中一直較為低調的階躍星辰,悄然在商業上開始爆發。
階躍星辰副總裁李璟對觀察者網直言,“多模態模型的優勢往往不體現在榜單上,而是體現在客户的實際測試裏面,這個可能更有説服力。”
例如,階躍星辰展示了在一張反光嚴重的菜單照片上準確識別菜品價格的能力——圖文識別算不上新鮮,但在複雜現實環境裏的可用性,才是應用落地的關鍵。
據介紹,階躍星辰的智能終端Agent目前頭部客户效應顯著:已覆蓋國內超過一半頭部國產手機廠商,深度合作打造手機Agent體驗;聯合吉利推出AI智能座艙,成功實現行業內端到端語音大模型首次量產上車。另一方面,階躍星辰積極拓展垂直行業的應用,與金融財經、內容創作、零售等領域的行業頭部公司深度合作,共同打造面向C端的場景化應用體驗。
多模態模型的快速應用落地,除了對大模型企業商業閉環意義重大,也有助於收集更多數據,形成飛輪驅動模型和硬件的進步。
天數智芯董事長兼CEO蓋魯江指出,“從芯片到整機廠商、模型廠商,再到最終應用場景,這4個環節都是產業鏈的重要組成部分,如果能夠通過聯盟建立統一標準,將會省去大量的適配成本。”

上海為何托起半壁江山?
最後值得注意的是,在上述模芯聯盟中,來自上海的企業佔據了半壁江山。
作為國內工業化最早、最完整的城市,上海在互聯網時代一度顯得低調,但隨着人工智能爆發,上海的產業地位正在不斷提升。
其實,上海人工智能產業的獨特優勢,正藏在“軟硬協同”四個字之中。
互聯網時代,企業崇尚輕資產的快速靈活,但在人工智能時代,硬件能力的提升卻沒有捷徑可走。上海坐擁中芯國際和華虹等國內主要晶圓廠,HBM所需的先進封裝產能也多位於長三角,這都為GPU企業提供了便利環境。
而上海為應用生態提供的服務也走在全國前列。無問芯穹在本屆人工智能大會期間指出,其服務的全球最大人工智能孵化器——上海模速空間,日均Token調用量已成功突破100億大關。
《新華財經》一組數據顯示,2024年上海人工智能(含大模型)企業達到24733家,較上年增長5.1%,新增註冊資本1000萬及以上的人工智能企業有104家。
上海國有資本也在頻繁參與AI產業的早期投資。今年3月,上海國投先導人工智能產業母基金的首個直投項目就投向了壁仞科技,據悉,上海國投生態體系也將在近期參與投資階躍星辰的最新一輪融資。
這無疑是一種更高層面上的系統集成。當其他城市還在討論如何“補鏈”時,上海已經讓AI成為城市基礎設施的一部分。


本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。