觀察者網WAIC直播實錄:AI大潮下的具身和人形,中國在跟跑還是並跑?-趙仲夏、奚偉、馮子勇、陳勉諾
guancha

當特斯拉Optimus再度更新、波士頓動力Atlas秀後空翻,全球目光再次聚焦“具身智能”與“人形機器人”。觀察者網在2024 WAIC現場邀請智源、美的、格靈深瞳、真格基金四位一線操盤手,追問一個核心命題:在AI大潮奔湧的當下,中國究竟是在“跟跑”美國的腳步,還是已經與之“並跑”甚至準備“彎道超車”?從電機供應鏈、強化學習算法,到落地場景與資本路徑,這場一個半小時的尖峯對話給出了答案——也留下了更大的懸念。
以下是7月27日上午,北京智源人工智能研究院研究員趙仲夏、美的人形機器人創新中心主任奚偉、格靈深瞳技術副總裁兼算法研究院院長馮子勇、真格基金投資經理陳勉諾在觀察者直播間的對話實錄:

從左至右:北京智源人工智能研究院趙仲夏、美的集團奚偉、格靈深瞳馮子勇、真格基金陳勉諾 (點擊觀看直播回放)
文字實錄:
**趙仲夏:**各位線上的觀眾大家好,歡迎來到 WAIC 觀察者網直播間,現在我們在 WAIC 的現場,看到進場的時候會有一個鎮館之寶,是我們的人形機器人。我們本次直播的主題是“具身向左、人形向右——的人工智能和機器人產業將走向何方?”,首先我們來問一下奚老師。我們知道在大眾的理解中,美的是一個家電或者是一個智能硬件的品牌,我想知道為什麼美的要去做人形機器人?做人形機器人的初心是什麼?
**奚偉:**大家對於美的可能一開始的印象都是家電行業,包括我加入美的之前,也對美的業務並不瞭解。但事實上,美的在 2016 年開始就開始做一些全球化的佈局,包括To B的轉型,從2016 年開始收購包括庫卡機器人相關的機器人的領域,目前美的To B領域有四大板塊:第一是樓宇科技,藉助美的在暖通上面的積累,把技術應用在樓宇相關領域,尤其商業樓宇;第二個是工業技術,也是美的在核心零部件上對整個工業進行賦能,包括電機、減速機相關的一些產品;第三個就是機器人與自動化,是在 2016 年收購庫卡之後建立一個新的業務板塊;第四個是正在建立的一些新業務板塊,包括美的醫療、美雲智數等一些新的 AI 的技術。
人形機器人是我們去年才開始做規劃的,我們認為美的進入人形機器人是有天然的優勢的:第一,我們在零部件上有已經有一些技術的一些積累;第二,在整機上我們已經開始有完整的產品線,人形機器人作為下一個階段的一個新賽道,我們應該當仁不讓,要去切入這個賽道。所以説從去年開始,我們在人形機器人上去做一些嘗試,通過一些項目去積累技術。今年,我們開始大力發展人形機器人相關的一些產品,包括應用的一些嘗試。
**趙仲夏:**原來美的不只是一個家電公司,還是一個智能製造的公司,同時還是一個機器人的公司。説到智能製造,我想知道美的從2016 年收購庫卡到現在已經快十年了,這十年中我們服務的主要客户是什麼?
**奚偉:**庫卡機器人在服務的行業有很多,目前主要集中在是汽車製造,同時也在像3C、船舶、飛機制造方面以及一些相關拓展。除了庫卡機器人之外,我們還有其他的一些行業,比如物流、電商相關行業,美的服務的行業跨度是非常大的。另外,美的本身也在製造行業,也需要很多機器人的支持,所以庫卡機器人在我們所有的美的燈塔工廠,應用量也非常大。
**趙仲夏:**太棒了,汽車製造、船舶,都是中國製造業最關鍵的行業。然後我們來問一下馮院長。我們知道格林深瞳應該是中國第一家 AI 領域的計算機視覺公司,也是中國第一家上市的 AI 領域的計算機視覺公司。能不能跟我們介紹一下格林深瞳和您這邊所在研究院?
**馮子勇:**對,格林深瞳是首個科創板上市的 AI 企業,在2013 年開始到現在已經 12 年,我們一直深耕的是視覺技術。主要做的是圖像,還有視頻的分析跟理解。先介紹一下業務,譬如在金融行業,我們為金融銀行的上萬家營業網點,做邊緣端加中心端的視頻分析,在安防領域大家比較熟悉了,像人臉、人體、車輛這些都已經落地到千家萬户。我們最近也新增了大模型相關的工作,譬如説以文搜圖,幫助公安去找人更有價值。另外關於人體分析這一塊,我們也進入到智慧體育方向,我們幫助中小學做體育考試訓練,幫助中小學生們提升體育素養。隨着大模型的發展,我們也做了一些信創的這個工作,像 AI PC 大模型一體機,也在我們的產品範圍內。再如剛才講到的視覺技術,我們發佈了自己的視覺基礎大模型,叫MVT,最近有一個更新的版本,等一下再詳細介紹。
趙仲夏太棒了,格林深瞳在大模型時代依然有自己的動態、多模態的基礎模型誕生,這很難得,因為多模態賽道已經沒有太多玩家了。然後是勉諾,至少從我一個外行人角度思考,真格基金應該是我最開始聽到的三家投資機構之中的一家。能不能介紹一下真格基金在做什麼?您個人會比較關注什麼方向?最近有沒有在投一些好玩的項目?
**陳勉諾:**真格基金是一家早期風險投資機構,主要是面向天使階段投資,我們最開始由新東方的聯合創始人徐小平老師和王強老師創辦,一直關注前沿科技領域,在 AI 和機器人領域我們一直有超前的佈局,像之前投的月之暗面、Manus、Genspark、Momenta、包括格林深瞳等都是作為第一輪投資人進行投資的創業項目,我們希望能夠在這個時代去推動創業者在新的科技領域去做一些早期佈局,能作為投資機構給大家助力。

**趙仲夏:**對,在產學研端的話投資是必不可少的。那我們就進入到人形的話題,奚老師給我們介紹一下人形機器人這個品類?人形機器人到底是由什麼組成的?它主要在做什麼?
**奚偉:**好的,人形機器人一直是一個大家關注的熱點,最近可能更熱一些。其實早在 70 年代,人形機器人就開始發展了,中間也發展了很多代。但我覺得比較有特色的就幾個。一個是 2000 年的時候,本田出的阿西莫機器人,2011年又做了一些改版。然後是波士頓動力的Atlas,都是一個標杆性的產品,但從我們歷史發展來看,之後到 2022 年,特斯拉發佈了 Optimus 之後,把人形機器人帶到了一個新高度。
我覺得中國中間的過程主要是剛開始的時候,我們的機電系統沒有那麼強,學習能力、對機器人的控制能力也不夠,就導致了機器人發展一直在停滯不前。隨着如今強化學習、具身智能、大模型的一些突破性進展,讓人形機器人得到了一個巨大發展。人形機器人,顧名思義就是像人一樣的機器人,它的複雜度在於,如果像人一樣去做,我們知道人大概身上有 200 多個骨頭,所以就有 200 多個關節。如果做這麼複雜、精密的系統是非常困難的。
目前我們的人形機器人大概平均在 40 個左右的關節,包括手的關節,如果是全身的關節大概是在 30 個左右,控制這樣複雜結構的系統,如果用傳統的基於模型計算方法是不太容易實現的,但現在引入了強化學習之後,我們可以看到,不同的炫技視頻越來越多。核心原因是,因為強化學習的出現,使得將調試機器人變成了一個非常簡單的工作,另外就是仿真的一些能力。此外,因為有AGI等技術,機器人的操作能力方面也得到了一個巨大進步。
當然我覺得是離實際的應用還有一段距離,但隨着技術的不斷發展, 5 到 10 年之內應該會有很大進步。
從應用角度來去看,現在人形機器人是有一定瓶頸的,大家還在探索階段。最近看到有幾個新的投資事件,比如上汽要引入 500 台人形機器人,真正進工廠開始做嘗試。所以我覺得通過應用的牽引,會使人形機器人發展迭代速度越來越快,我也相信在未來3到5年,整個機器人產業的發展會有一個巨大進步。
從產業鏈的角度來去看,人形機器人這幾年,尤其是核心部件產品,包括關節模組、傳感器也有巨大的進步,所以成本會大幅下降,這些都是機器人大發展的重要原因。
趙仲夏: 好的,我們感覺就是人形機器人已經發展很多年了,就像您剛剛聊到的,日本那邊有阿西莫,美國 20 年前就開始做波士頓動力,也有一些出圈的工作,但從來沒有像最近的中國和美國一樣百花齊放。此外,以前都是一兩個出圈的機器人,這次感覺有上百個出圈的機器人了。
我也想問一下馮博士和勉諾,人形機器人發展這麼多年,本次的像美的、宇樹、智元的人形機器人和早期的阿西莫和波士頓動力相比,到底有什麼區別?
**馮子勇:**從我的角度來説,剛才也講到,過去很多機器人的控制是以規則或者以硬編碼為主。現在我們有了強化學習,有了VLA,可以把這個模型的訓練融合到機器人裏面。我們可以看到,隨着數據的積累,機器人的能力會不停地提升。比起我們手寫規則,它的上限會更高,效果也會更好。這是我從機器學習這個層面上去看到的。
趙仲夏: OK,然後勉諾是否能來表達一下,您覺得這次人形機器人和之前的有什麼主要區別?
**陳勉諾:**我們也一直在關注具身領域的發展。我們看到波士頓動力早年的時候,其實以液壓傳動為主,今天的機器人大家都普遍用電動傳動,這個是一個很大的本質區別,因為液壓傳動到電動傳動能夠在裏面加入到很多新的智能算法。第二個點是以前大家是基於rule-base的方式去做控制學來實現機器人的運動,今天我們可以用 learning-base 的方式來去實現更多任務的泛發性,比如説可能在 manipulation 操作層面上帶來一些新的可能性。
在今天,中國本土的供應鏈能力也得到了這個大幅的提升,所以在這一波的機器人浪潮裏,中國的企業玩家越來越多,可以推導到當年的電動汽車領域。我們最開始電動汽車領域整個產業鏈也是相對落後的,但在整個的電動車領域發展之後,我們對於新的產業鏈有了巨大的技術提升。
趙仲夏: 您説得很對,之前大部分波士頓動力都是液壓形式的,這次我們看到的幾乎所有人機器人都是電機形式的,而中國在電機領域做了很多很多的技術儲備,供應鏈的優勢也很高。
下一個話題,我們在場館裏也看到,人形機器人有兩類,全人形和輪式的人形機器人。奚老師,您覺得人形機器人一定要具備雙足嗎?
**奚偉:**從我的角度來講,它是以應用來去驅動的。雙足式的人形機器人它是一個通用機器人的載體,這也是行業的共識,未來如果是通用的人形機器人,我覺得應該是雙足這個形態的。但是對於我們很多工程,即智能製造場景,尤其是工廠的智能製造場景,其實用輪式的更方便。因為在工廠裏邊大部分的場內環境相對比較標準,用輪式機器人更容易。我們目前的機器人自動化製造領域就是如此,尤其是和我們的 AGV 以及其他工業機器人進行配合。
另一個是家庭場景,尤其中國的小户型場景,用輪式機器人也是比較適合的。像掃地機器人,也是輪式的,所以家庭場景第一個是用輪式機器人,也會更安全。用雙足機器人還是要解決安全的問題,才能真正進到家庭裏。
而通用機器人,是先有機器人再去找應用。但在美的面向智能製造過程中,很多時候是先有應用,再去找對應適合的產品。從這個角度來講,我們就更希望有了合適的釘子去找更適合的這個錘子。目前來講,我們有三類產品,一個叫類人形,即剛才您説的基於輪式的機器人加上雙臂的操作能力,第二個是全人形機器人,我們也在探索通用型人形機器人的使用方式,第三個是我們在提的一個概念,叫超人形機器人。
趙仲夏: 超人形機器人?
奚偉: 所謂超人形機器人,就是在工業應用場景,比如像智能製造,有六大核心應用,尤其工組裝線上核心的應用,包括搬運、上下料、打螺絲、端子插接、面板裝配、焊接等,每一個領域需要的技能等要求是比較高的,用傳統的通用機器人,雖然能適應不同任務,但速度不夠快,達不到目前人的操作效率,所以我們希望設計一種可以突破人的效率的形態,更定製化的機器人,真正適應到我們的工廠裏邊去突破現在人形機器人的一些缺陷和不足。我覺得中間階段,一定會有這樣的一種機器人出現。
**趙仲夏:**明白,甚至最終的人形機器人也都是一個超人形的機器人,因為電機的能量密度有可能會超過人類未來。
勉諾這塊我記得你説過,可以提供一些好玩的觀點,我覺得當前從落地角度看的話,輪式可能會比人形會更好落地一些。因為雙足的關節比較複雜,運動起來或在跨樓梯等特殊地形,會出現一些危險情況。這塊話您有什麼見解?您覺得人形機器人需要雙足嗎?
陳勉諾: 這是一個非常有爭議的話題,我們作為投資人也會經常去思考。我自己經歷過很大的思想轉變,最開始我認為輪式非常重要,因為人類發展了這麼多年,通過技術推進,終於將雙腿這種行走效率低的方式進行進化,出現了自行車,又進化了汽車出來,進化了各種各樣的輪式產品,已經説明輪式的效率比雙足更高。
結果也是如此,輪式被使用得要多得多,但一個很有意思的現象是特斯拉為代表的一些企業,始終在堅持要走人形的路線。我跟特斯拉 Optimus 的核心成員有過交流,他的觀點還挺打動我的:我們自己做機器人動力學都知道,如果輪式加上半身的雙手,很容易面臨一些彎曲身體的動力學平衡問題。如果用雙足形態,就能夠做出有效的支撐。而且能做彎曲身體形態,隨時調整全身的動態性,這是雙足人形的優勢,是一個很有意思的觀點。
所以我的觀點已經改變了,今天我認為,人形雙足的形態是一個有必要的形態。

特斯拉二代人形機器人Optimus在上海2024世界人工智能大會首次亮相 視頻截圖
但它到底在場景中有多少實用性,取決於這個場景的動態複雜性。如果在一個非常固定的場景,比如家庭,沒有樓梯,沒有動態複雜性的場景下,我覺得輪式就 OK 了。但如果在像工廠等有一些跨越階梯的場景,或者室外一些複雜場景,甚至可能未來移民火星,在這些高複雜動態性的場景下,我覺得雙足形態是非常必要的,這也是我自己從認知的一端轉向另外一端的一個極大轉變。
趙仲夏: 你剛剛有點説服到我了,我在過去的時候從左端偏到了右端,剛剛聽你講完之後,我又感覺又從右端到了左端。這麼看人形的話,在它可以同時保持一些平衡性,然後並且有些地形跨越能力,從某種意義上它更靈活一些。
陳勉諾: 在動態性的調整上,我覺得雙足還是有巨大的優勢的,但只是説今天我們無法去解決的問題是這裏邊使用了太多的電機。我也跟特斯拉Optimus的團隊去交流如何考量成本的問題,他們思考把電機換算成原材料,有多少用了稀有金屬,有多少可以用常規金屬,在這個金屬成本下,到底能把人形機器人成本控制到多低?也許有不同的視角,我覺得這是一個大家今天可能都值得思考的一個問題。
如果成本降到足夠低,有一天,這種動態性的人機器人就能解決高價值的、複雜的、今天輪式解決不了的場景問題,那它就帶來了巨大的場景價值。
**趙仲夏:**我記得騰訊出過一款輪足的機器人,它是一個這樣的形態(雙足交叉),用來攙扶老人,這種形態也許會更穩定。我看您之前有打過 RoboMaster,RoboMaster 輪足也是一個非常好玩的品類。然後您在RoboMaster經歷裏面怎麼看待輪足這件事情呢?
**陳勉諾:**我覺得有一個形態大家可以去關注一下,智元前段時間發佈了一個將輪式跟雙足進行有機結合的,可以將輪式進行摺疊,變成一個雙足的形態。但這裏邊有一些關鍵的技術問題,比如從輪式變成雙足的過程中,對於中間關節的磨損是非常嚴重的。在這種關節的磨損上,其實現在有一些大的技術難題以及它的工程穩定性難題解決不了,但這種形態本質上解決了動力學動態穩定性和在平坦地面上運行效率兩者平衡的問題。我們在大量的直行道路上,其實輪式由於摩擦係數的原因,它的效率是最高的。所以我覺得這是一個今天值得關注的形態。而之前定義的輪足形態還是有一定的挑戰,比如在動態穩定性上,尤其是跨越樓梯之類場景的動態穩定上,因為底下是輪式,還是無法做到完全的平衡。但智元做的那一款機器人是有一定啓發性的,可以將輪式變成一個真的雙足步態行走的狀態。
趙仲夏: OK。輪足可以跳躍嗎?我看到你們早期的比賽裏面輪足很多是用來跳躍的。
**陳勉諾:**跳躍是一個很重要的技術問題,當你的環境變成動態複雜的時候,控制會變得非常難做。所以在 RoboMaster裏經常會設置一些動態複雜的問題。這些問題的解決,對於整個機器人控制學,以及我們今天看到有 learning-base 的方式來去做機器人的這個系統來説,都會有巨大幫助。
趙仲夏: 這很酷。馮老師,我聽説您最近有在看靈巧手的項目,您怎麼看待靈巧手這件事情?您覺得這種通用的手的末端,它後面的演進方向是什麼樣的?是通用末端好還是專有末端好?
**馮子勇:**這個要分場景的,從兩個維度上去看,一個是在數據採集維度,手的末端比較好的,就是我直接能跟人的手很好地對應上,這時候人採集數據就很容易,也能把數據比較容易地投影到機器靈巧手上,這就是一個很好的數據,而且這個數據源非常多。但在有的場景,它的效率不夠高,像剛才奚老師説的打螺絲之類,可能用一個專用器具會更好,這種情況下,如果我們的場景還能採到更多的數據,用專用末端的優勢還會更大。
另外,我自己覺得,靈巧手這個東西,對於“像人”是非常大的執念,即人形機器人就應該像人一樣,我覺得這在人的思維裏面是非常重的。
**趙仲夏:**對,您之前跟我聊過人形人工智能是一個跟信仰有關的故事,我發現人形機器人某種意義上也是一個跟信仰有關的。
奚老師,美的的場景中也有各式各樣需要各種末端的,您是如何看待現在的靈巧手?在您這邊所有場景之間落地,您覺得靈巧手會是一個更好的未來嗎?
**奚偉:**我覺得通用人形機器人一定是要靈巧手的,尤其是五指靈巧手。因為我們已經習慣了和像人一樣的載體進行交互了,而且我認為可能將來人形機器人有一個階段會像阿凡達這樣,它會變成一個人的另外一個載體,如果有技術的話,可以把我們的意識去直接加載到機器人上來,進行遠程的操控,這個可能再有一階段會形成。它(人形機器人)不一定必須要完全自主,或許是變成我們另外一個替身,要在另外一個空間裏你來進行操作。如果是這樣的話,就需要用人的一個載體,讓我們所有的動作在另外一個載體上進行完全一對一的復刻,從這個角度來講,是需要有這樣的五指靈巧手的。
但我們現在很多的從應用角度來講,我剛才也説了,大部分場景並不需要這麼複雜的結構,而且複雜機構會帶來很多的不穩定性,尤其是行業還在發展階段,我們要迅速落地的話,必須要解決它的可靠性、穩定性、待機時間、續航時間,很多現實問題想解決,所以我覺得中間一定有很長的發展過程。
**趙仲夏:**瞭解。Mario(陳勉諾),你最近有看什麼靈巧手的項目嗎?我看樓上有好多家靈巧手公司,並且最近也在陸續出一些更高關節度、更多自由度的更高維度的手。您是如何看待靈巧手這個品類的?你本身投資的偏好裏面會重點關注靈巧手這個方向嗎?

資料圖:樂聚“夸父”人形機器人
**陳勉諾:**靈巧手也是一個爭議比較多的話題,大家普遍認為,今天再怎麼便宜的手都得幾萬塊錢,因為它本身結構的複雜性在這裏,靈巧手成本無法降到一個非常低的狀態。我跟很多業界和學界的朋友探討過,我們生活中和工作中到底有多少是真的需要五指狀態來解決?其實大量的場景兩指夾爪形態就能完成,大約70%吧。所以今天兩指夾具在所有的具身智能裏邊是大家演示 Demo 和場景實際使用最多的形態,因為 70% 的任務能夠在這個場景下得到有效解決,在這場景裏面到底有多少任務可能是兩指夾解決不了的?比如説當你拿握起水(瓶)的時候,其實兩指也能夠握取,但這個握的過程中是點接觸,點接觸就意味着摩擦係數比較高,所以會有一些力的精準掌控難題。但是如果你是握的方式,就會變得比較的容易。再比如擰轉的過程,可能五指會更加的靈活,所以我覺得在一些細分的場景下五指是非常有必要的。但五指確實要去解決一個問題,就是在場景的實際使用過程中,如何考慮場景的價值和成本之間的 trade off。
在我們的視角下,也認為五指靈巧手是一個非常必要的存在,但成本如果沒有下降到一定程度,可能在場景應用過程中會有一定挑戰,但我們作為一個早期的風險投資機構,在無論是對於這種五指靈巧手,還是對於人形,對於整個具身,我們都是非常積極地去看,積極地去佈局,我們認為這裏有很多的機會。可能有一天我們發現 pick and place 能解決的任務成本已經非常低了,剩下那些高複雜任務的場景,它的價值就必然會抬升起來。之後它的價值和成本之間達到一定平衡的時候,這些五指靈巧手就能得到場景的應用。
趙仲夏: 這個給了我們一個更好地去看待行業的思路。最近我們發現夾爪有的越做越大,有的越做越小,如果要做一些精細的情況就要點接觸,如果要做一些更好的方便抓握的話會做得更大。這個好像就包含了您剛剛説的為什麼人類是手,簡單地抓取任務,人類有的時候也會不一樣。
**陳勉諾:**是的,有個視角可以給大家提供參考,從數據採集方面,如果你是五指形態也許更容易,今天有很多路線之爭,比如模仿學習、強化學習,有一條路線是通過大量視頻的數據學習來調整機器人整個形態,那顯然是人的數據最容易採集。所以我們認為這裏有大量的機會空間,你可以更容易採集到數據。而兩指夾具的數據採集,顯然是你需要真的在實際場景去使用,採集數據的成本會比較高,所以我們也認為五指可能在這個層面上更容易實現在場景中的一些任務的泛化性。這也是一個視角。但還是迴歸到本質的問題,就是成本跟場景價值之間的tradeoff 問題。
趙仲夏: 瞭解。好的,我們剛剛聊了很多跟人形機器人有關的爭議話題,要不來轉到另一個好玩的話題,就是人工智能和具身智能,想聽聽大家對具身智能這個概念的定義和看法,是不是像宇數那樣翻跟頭、跳舞就應該算是具身智能?還是説具身智能有另外一些更廣更大的概念?奚老師,要不您先聊一聊。
奚偉: 好的,具身智能我接觸比較早, 2016 年在 Berkeley 訪問 Peter 的時候,他就提出具身智能的概念,當時他們主要提出的是傳統的我們做機器人控制分三部分,一部分是perception,一部分是planning,還有一部分control。所有東西要通過代碼來去實現,先做物體的識別定位,再做規劃,最後再做執行。其實是,能不能把這個東西壓縮起來,直接從圖像到動作一步完成。他提出這個東西,叫具身智能,因為當時我們對這個概念還是相對比較陌生,在 2016 年的時候就做機器人來講,一肯定要做這些,把它分解開,就是 divide and conquer,但是我覺得從現在發展來看,就像宇數做的強化學習,可以認為是一種具身智能,它的輸入傳感器是通過力傳感器,通過電流,也是通過傳感器形成最後的一個具身動作,但它這動作是通過仿真來實現的。
我們更多更廣義上的一些具身智能,是能夠從現實的環境中通過視覺,通過多模態的傳感器獲取到的經驗,能夠實現更高意義上的這個決策和推理,最後能夠達到通用的操作的能力。所以從這個角度來講,我覺得目前的技能學習,或者説像宇數這種跳舞動作是屬於相對初級的階段,它的目標比較明確,但通用的具身智能,它的目標是比較複雜的,這個能力的具身智能還在一個需要發展的階段。
趙仲夏: OK,瞭解,感謝奚老師對具身智能概念的分享,讓我想到了之前有一個概念叫做視覺私服。從控制學角度去討論的話,有點回到了當時大家講通過視覺去牽引一個任務完成,然後來適應一些不同的泛化。
馮老師,您這邊從人工智能,然後 AGI 到大模型這個角度,研究得會比較深刻一些,您是如何看待具身智能這個概念的?能不能幫我們從人工智能角度聊一聊。
**馮子勇:**因為我們原來做視覺,沒有機器人就相當於我只有感知,到最後我的決策就是一個,譬如原來是輸出一些 label 框或什麼東西,現在可以輸出語言,但是最終執行還是給到人,就是我只能説相當於他輔助出了一些信息,然後人再去做操作。整個閉環是沒辦法進行的。在我看來,具身智能是希望這個閉環能在整個模型,或者説整個智能模型裏面自己去產生閉環,我的這個傳感器進來,我自己產生判斷,具體產生的action,最後 action 改變的世界又重新回來了,這個閉環是完全的。
我認為這就是具身智能非常重要的一個概念,需要把整個東西閉環,並且是跟物理世界去交互,隨之就是我們可以在物理世界中隨着這種閉環,不停地去提升我的智能能力,而不是靠採集數據標註員,智能來自於標註員,而不是來自於這個智能體本身。
趙仲夏: 多少人工就有多少智能。
**馮子勇:**對,這個其實不太符合大家對智能的需求,所以我覺得具身智能在這個層面上應該是,它會自主計劃,隨着他跟物理世界的接觸不停地去學習,這樣的一個概念。
**趙仲夏:**瞭解。説到這個,我有些概念想請教一下馮老師,我們常聽的LLM、VLM、 VLA 這些都是什麼樣的概念?能不能稍微給我們解釋一下?
**馮子勇:**LLM 大家可能也比較熟悉了,這個現場大家都看到很多大語言模型,當然在我看來,它雖然叫做大語言模型,但不只是語言模型,其實是邏輯模型,因為語言是有邏輯的,我不會隨便説一些奇奇怪怪的話,所以你也可以認為它是大邏輯模型。
很多時候現在只有語言的輸入,但接上了vision,就像我剛才講了我們也在做 vision 相關的工作,我們在大概2021 年就開始去摸索大視覺模型,當時不叫大視覺模型,因為當時沒有這個概念,叫視覺基礎或者預訓練模型。
這就是我們現在做的,我們把它叫做MVT,已經到了 1.5 這個階段,它能夠把視覺傳感器進來的圖像變化成視覺的token,這個 token 就能進到這個語言模型裏面去。使得這個語言模型能夠作為一種視覺外語去理解它,這個邏輯至少在視覺跟語言上,或者視覺跟邏輯上融合在一起了,這就是大家能看到的 VLM 。
隨着機器人的發展,我不只想出一個文本,不想只出一句話,我還要有動作,我還要有操作,我還要改變世界,那麼就是 action 也出來了。
可能我們看到有很多技術路線,從一個 hidden state,一個隱空間,就剛才説的某一坨邏輯,然後 decode 出來怎麼去操作,這裏面有很多專門的技術,譬如説DP,把這樣的一些技術操作去做,在我看來可能導航也是一種操作,再把這三者有機地聯繫在一起,那麼它就變成了一個VLA。
趙仲夏: OK,太棒了。感覺好像跟我們講了一下大模型下發展的一個歷史。Mario 你是如何看待具身智能這個概念的?這個概念真的非常火,但是好像大家對它的定義也沒有完全特別清晰。
**陳勉諾:**我自己原來就是做機器人,在我的認知裏邊,它其實只是説把機器人做了延伸,因為大模型出來之後,智能有了進一步的提升,所以原來可能大家對機器人還是侷限在傳統的控制學範疇,然後今天終於加上了 AI 範疇。所以提出一個新的概念,讓大家可以有更多的研究話題。
第二點是,對於具身智能概念的理解,主要因為它叫 EmbodiedAI,其實是在於本身具備物理實體、然後能與環境做有效的交互,這可能區別於LLM範疇或者VLM範疇更偏數字世界,EmbodiedAI一定要有跟物理世界進行交互,以及一個物理的實體。
從概念上去理解的話,廣義上不單單隻侷限於在機器人領域,只不過機器人是大家最fancy也是最容易想到的一個主要形態,這也是大家普遍提到具身智能就理解成機器人的原因。我的理解在廣義上來説,它只要跟物理世界進行交互,然後有具備一定的物理實體,可能具備一些這個物理感知,其實都可以被稱之為 EmbodiedAI具身智能。但在整個與物理世界交互的形態裏面,最重要的還是機器人的形態,因為機器人形態才能夠跟物理進行有效的交互。有效交互指的是一定要跟物理世界有接觸,發生物理反應才能夠叫有效交互。所以我們認為 EmbodiedAI這個概念是機器人概念的一個延伸,但不限於機器人概念。

趙仲夏: 對,我感覺每次聽勉諾講話都有點頓悟的感覺。馮老師,我們這邊關注到,最近有一個新的概念叫 world model世界模型,大家認為也會在具身智能方向上產生一些比較好的潛力。您是怎麼看這件事情的?我聽説您最近在做一些視頻模型,我們怎麼理解視頻模型和 world model 呢?它們對具身智能是否有幫助?
**馮子勇:**OK,首先世界模型我認為它是希望有一些視覺輸入之後,預測這個世界是怎麼發展的,相當於自己內部會有一個預測模型,但這個模型有一些是顯示的,要生成下一幀或者下面一段時間的圖片或視頻。也有些就覺得,不需要顯示,拿到隱藏空間或者表達就 OK ,並不一定到 Pixel 像素層面去還原它。從我的角度更偏向於後者一點,只要大概知道接下來是怎麼做的就 OK 了。
世界模型可以幫助我們去提升VLA,因為現在大家説的 VLA 可能更狹義一點,就是直接到操作,但是那具體怎麼到操作可能中間會有,但都是直接做。
當然你可以用COT,就説我做一些thinking,reasoning 這樣的序列來到達那個操作,但最後壓縮起來,還是應該在這個模型的 latent 的 space 裏面,是有一些預測的,但這個預測究竟是什麼東西,我覺得學術界也在探討。
但我覺得世界模型還很重要,它不一定是顯示的表達出來,視頻模型是這樣的,就是我們自己,因為剛才也説了,我們很多研究都是基於圖像,但不只基於圖像,而是原來基於視頻的技術發展有點落後。圖像一是因為數據多,另外容易訓,但視頻不太好去搜集標註,從這個層面上訓練的複雜度跟對算力的需求也非常大。
我們現在去看這個視頻是因為,我們知道不管是真正地去分析這個世界,還是機器人,它對於這個連續動作還是非常有需求的,而不是我就看一張一張的圖,當然現在很多 VLM 也好, VLA 都是我先把這個視頻流切成一張一張的圖,然後送到這個模型裏面,這個相當於我可以讓這個大語言模型它自己去串這個邏輯。
在我們自己做視覺的這個角度來看,很多視頻流在前端就已經有一點被壓縮掉了,特別是我們在視覺領域上,它是冗餘的,特別是我們大部分視覺元素是不變的,視頻是可以做得更高效、更緊緻,而且去表達我們真正關注的東西,像人的 forbia 一樣,他只關注到動的東西,我們做機器人很多時候關注的也是這個狀態,世界狀態變化,別的可能不太關注。我覺得在這裏面視頻的模型應該是有可以做的空間,而且最後它肯定是也能服務到機器人上。因為我們是一個動態的場景,它不是靜態的。如果我們視頻能做得更好,那我相信機器人對場景的理解,對最終自己動作的判斷也能做得更好。
趙仲夏: 瞭解。奚老師,您從應用端角度來看的話,會去關注 world model 或者是視頻模態的進展嗎?您覺得它對您這邊實際的人形機器人或者是區分智能落地會有很大幫助嗎?
奚偉: 我覺得這是對於複雜場景肯定是有幫助的。像勉諾剛才講的,對於通用的人形機器人,是要進和世界進行反覆交互的,我們也在探索,比如在家庭場景四大件就是最典型的應用,收納、清潔、洗衣、做飯,這四件事情看似簡單,但非常複雜,比我們剛才説的在工業場景應用複雜得多。因為工業場景已經高度細分了,它每一個內容是一個一個動作,只要把它做得精準就可以了,它就有產業價值。但是我們希望這些機器人真正像人一樣能夠在家庭裏邊給我們應用。

所以我覺得 world model 就是物理世界模型,它是建立物理之間相對關係一個更好的表述,因為我們是缺乏表達的,因為缺乏表達才沒有推理的手段,才沒有範式。所以我覺得進入到家庭來講, world model 是一個比較重要的基礎。
趙仲夏: 謝謝。勉諾,你最近有在看 world model 一些相關的公司嗎?你如果看 world model 的。
**陳勉諾:**我們也一直在關注學術前沿進展。 world model 到具身智能之間的衍生其實是在一些主流具身智能學派裏面的一個分支路線。我們有交流過一些學者在順着 world model 方式來去做 Robotics 領域,我們也認為這條路線是非常行之有效的。我有跟 MIT 和 Physical Intelligence 等裏面同學去交流,這條路線是可以行得通的,因為 worldmodel本質上是對物理世界的數字重建,如果可以將物理世界進行重建得非常完善的情況下,它就能夠很有效地將機器人也能在數字世界重建,就能夠有效地 train 機器人的model。但這裏邊有一個很大的問題,因為 world model 需要將物理世界重建,所以需要採集大量的數據,它的成本會變得非常高,要把物理世界完全數字實現難度是非常高的。在這條路線上
如果問 world model 對具身智能發展是不是有幫助?絕對是有幫助的,但能不能構建完全行之有效的 world model 這個事情,成本是非常非常昂貴的,而且很難去完全實現。所以在我的認知裏面,一直也在關注 world model 實際進展。但從 world model 到具身的實際使用過程,我覺得是一個非常長期的過程,而且可能world model 本身構建的過程也非常困難,我們當然希望有一天能夠把 world model 重建出來,那這樣的話我們就能在數字世界映射一個真實的物理世界,那這個時候很多物理世界的客觀物理規律甚至可能新的科研發現都能在這個數字世界進行重建。就不單單只是機器人領域了,整個科研領域,整個人類的進步都能夠得到更快的一個進展。
趙仲夏: 太棒了,之前有聽我的老師講,傳統的大源模型是讀萬卷書,那 world model 或者説具身有點像是行萬里路。這樣的話最終會發生一些概念,完成一些對現實上的一個對齊,一旦對齊之後將會誕生一個更棒的超級智能。
説完 world model,我們想聊一下強化學習。奚老師覺得強化學習在這次具身智能中扮演一個什麼樣的角色?您覺得強化學習要如何使用?
**奚偉:**我是這麼想的,大語言模型是一個概率模型,它生成內容,但是並不保證它的準確性。強化學習是一個優化模型,它去把結果根據你的需求進行優化,比如跳舞,在訓練過程中都要根據你的目標來進行優化,所以強化學習是一個必要的工具。基本上現在所有的應用都會用到強化學習,但它不是要取代大語言模型,這是相輔相成的,它是大語言模型的一個 building block。我認為,強化學習是必需的。
趙仲夏: 這個非常確定,強化學習是必需的,我很喜歡這個結論。馮博您如何看待強化學習?
**馮子勇:**首先從強化學習技術發展的歷史來先看一下,強化學習並不是現在才有,過去已經一直在,只是過去大家發現強化時學習,像這個阿巴狗這樣的,它只能存在於仿真環境裏,譬如説像遊戲。
過去我認為叫小模型,就是它只能上 RL 的時候,需要大量的數據去train,就像我們以前做小模型就是我要標很多很多的數據,只訓那一個任務,在這個上面也是一樣的,當有一個很好的預訓練,相當於我的知識,我的邏輯,我的所有東西都已經學得差不多了,最後才來激活他,來激發他新的這些,或者説在原來這些潛力下面去組織一些新的能力。這是這兩個的範式一點點不一樣。
RL 還是很重要,但 RL 裏面還有一個最重要reward,就是做過 RL 的同事或者説研究人員都知道 reward 非常難調。那在具身裏面 reward 怎麼辦?我們看到有的公司比如Dana是設計了一個不錯的reward,那我覺得在這個方面應該也是非常有搞頭,就是大家應該多去想想 reward 怎麼搞。
趙仲夏: 説到 Daya ,勉諾,是你們投的公司對不對啊?要不要給我們介紹一下 Dana 在做什麼?或者您如何看待強化學習的使用。
**陳勉諾:**Dyna Robotics也是朝着具身智能的方面去做努力,在不斷地收集數據,嘗試在真實的場景中構建能夠真的走進到這個工業和生活場景中的機器人的這樣一家公司。
我説一下對強化學習的理解。因為我原來是做控制學背景出身,對於可能 learning 這個方向沒有特別強的概念。後來學到了一個很重要的概念理解,模仿學習可以理解成就是那些只會做習題集的普通學生,然後強化學習是那些做了習題集之後他能夠去解更難問題的優秀學生。所以其實強化學習在機器人領域我覺得是一個必然很重要的發展路徑。
比如 DeepSeek R1 那篇文章發出來之後,大家就看到如果你有比較大的base model ,在上面加上 RL 之後,那它其實就能夠帶來很強的智能的泛化性,這個理解也很簡單,就像普通一個班級,同學們都做了很不錯的習題練習之後,裏邊有一些極度聰明的同學,你給他一個 reward 獎勵,給他一道更難的題這樣一個目標函數,然後他就能在這裏邊去形成自己新的解題思路。
所以我們認為在機器人領域也是一樣的,只不過可能今天在機器人領域,或者在具身智能領域,現在還沒有很好的 base model,所以大家普遍在於數據採集,然後去建立 base model 的狀態。所以RL重要嗎?我覺得未來RL非常非常重要。
還有一個路徑大家也可以去看,原來我們看四足狗的這種形態,在我創業的時候,那個時候在 2018 年左右,四足狗整個步態穩定性其實是比較差的。但今天四足狗整個的步態非常像狗,這裏面其實就是採集了大量的狗的真實數據,之前像騰訊的RoboticsX實驗室有一段時間專門採集狗的運動動態數據,動捕做了很多動態數據,把動捕的數據放到機器人裏面去 train 它的RL model,然後讓它可以去實現。
只不過locomotion這種運動學更容易實現,它不需要非常高精度的控制,所以我們今天看到 RL+locomotion其實在場景中更容易實現。可能下一步具身智能要解決問題就是RL+manipulation操作層面上。但操作是一個更復雜任務,你需要去定義這個任務到底是什麼,它具備一定的複雜性,以及你要解決有一個能夠在數字世界裏邊去建立的仿真環境,因為RL本身是需要有真實數據在仿真環境下跑最終得到一個有效的模型,然後再把模型返回到真機的場景下去實現結果的這樣一個過程。這可能是今天我們要面臨的一個挑戰,也是今天所有的具身智能的公司大家在去解決的問題。大家可能普遍去構建仿真環境,去採集真機數據,構建仿真數據,然後仿真數據去Train一個還不錯的 base model,把真實數據去放進來,然後定一個有效的任務目標函數,再讓它能夠在真實環境裏面去解決。
另外一個我也挺認同今天具身智能是一個更復雜的場景任務,因為它跟物理世界進行交互,所以它的目標函數更難去定義。我們都知道RL裏邊最重要的是reward function的建立,其實構建Reward Function是很難的一件事情。比如説我們今天看到大語言模型RL在什麼樣的場景下是最有效?它在 coding 和math層面上很容易實現,因為這個目標函數非常容易定義。但跟物理世界的任務怎麼樣去有效定義這是一個今天還沒有被完全定論的問題,也是我經常跟具身智能行業的學者和業界人士探討的問題。什麼樣的任務體系是今天能夠被定義為一個Benchmark,我們能夠讓把它作為一個很重要的任務評測集,能讓具身智能系統在裏邊去不斷地追求它的目標極致。
今天可能大家有一些概念,比如疊衣服任務。今天具身智能公司一個最重要的 demo 就是疊衣服,為什麼疊衣服會成為一個重要的案例?因為它有幾個層面,第一個它有翻折的複雜性,第二個它是跟柔性物體接觸,這都是是重要的Benchmark點,但今天坦白來説還沒有一個很有效的Benchmark ,也意味着 RL 在這個階段還沒有得到大範圍的使用,但我認為它在未來,尤其當我們建立了有效的 base model,會像 DeepSeek R1 那樣,有一天能夠綻放出巨大的光彩,而且我認為是必經之路。
趙仲夏: 您説這個讓我想到了一個好玩的概念叫 BA base model,有點像是人的頓悟,因為我們講智能湧現是頓悟時刻,然後 RL 有點像佛祖的點化,但是佛祖只能點化一個有慧根的模型。所以我們現在相當於行業或者研究一直在做數據採集,也是為了先訓一個聰明的有慧根的 base model,然後等待 RL 點化,我覺得這個很有意思。
然後我們再聊一些更寬點的問題,大家覺得如何看待具身智能和通用人工智能?具身智能是通用人工智能的必由之路嗎?來,要不奚老師您來跟我們講一下?
**奚偉:**具身智能和通用人工智能具有相關性,但完全是兩個不同的東西。具身智能一定是要和物理世界發生關係的,要通過傳感器去對物理世界進行建模,再去通過決策操縱你的機構,然後發生關係。但通用人工智能是對我們所有的知識規則的一個一個總結,它能形成一個有效的一個個推理,更多的是在一個抽象層面的能力,它並不一定需要一個具身載體,所以我認為通用人工智能是對具身智能能力的一個巨大的提升,它應該是一個 building block,人工智能可以去賦能的一個技術,它可以賦能不同的,包括機器人。美的也在提家電機器人化,也是把要把家電作為人工智能載體,結合在家電裏邊放的一些傳感器,可以變成具身智能家電這樣的一個新物種。
我覺得這些東西都需要感知能力、邏輯推理和決策能力,包括一些動運和操作的能力。所以我認為通用人工智能是具身智能下一階段能夠發光發熱的一個巨大的動力。
趙仲夏: 好的,謝謝奚老師。馮老師,您是如何看待具身智能和通用人物智能的關係的呢?
**馮子勇:**我也覺得是這樣的,通用人工智能這個詞,不同的單位有不同的解釋方式,有些人認為只要大語言模型到了一個非常好的時刻,它就是通用人工智能。但有些認為,還是要跟這個世界包含在一起才叫通用人工智能。
在我看來,剛才奚老師也説了,通用人工智能肯定能幫助具身智能更好地提升,更好落地,更好發展。如果我們本身就是在這個世界裏面的,這個世界的實踐也能提升我們自己的智能能力,那有沒有可能我們現在還沒看到,因為我們都在用大語言模型的能力,還沒有反饋給大語言模型。如果有一天,能夠做到物理的反饋,能給大語言模型帶來新的知識,這時候這兩個是不矛盾的,甚至可能是一體的。
奚偉: 互為補充。
趙仲夏: 對,勉諾你如何看待AGI?
陳勉諾: 我是這麼理解,具身智能是通用人工智能的一個子集,通用人工智能追求的是在世界實現一個完全的智能,完全智能不可能只有數字世界裏進化,它也需要跟物理世界進行有效交互,而且它的這個終極目標是,我們經常説的知行合一,也就是不單單要知道知識,也能夠能行動出來。
如果把知行合一當做人類的最高標準,那對於整個通用人工AGI來説,不單單隻有智能的上限,還要需要有action,需要有行動,所以我認為具身智能是通用人工智能的一個子集,而且是一個非常關鍵的環節,只有有了具身智能,才能跟物理世界進行交互,才能感知物理世界,採集物理世界的數據,將物理世界的規律在智能的領域裏進一步地提升,形成一個雙向的閉環。所以我認為具身智能、大語言模型、多模態模型其實都是整個 AGI 或者通用人工智能的子集。
**趙仲夏:**好的,那我們進行下一個話題。中國的人工智能和具身智能產業將走向何方?跟產業落地相關的。Mario,你最近有投資哪些具身或者機器人的企業?在調研走訪的時候有沒有看到一些跟行業落地有關的趨勢。
陳勉諾: 我們投了幾家目前比較活躍的幾家公司,一個是剛剛有提到的 Daya Robotics,第二個是方舟無限,做機械臂的,還有做靈巧手和電機的舞肌科技,以及之前投的像非夕機器人, 優艾智和都在往具身智能這個方向形態去轉變。
在落地場景方面,坦白來説,今天還屬於在技術發展的前端,甚至我認為今天具身智能的時代都遠還沒有到 GPT 3 時刻。所以今天大家去談落地有點為之過早,甚至可能還有很多的彎路,大家還要去摸索、去探索,可能要給產業更多的時間和空間,讓大家在技術方向做更多的探索。
在落地層面上,我覺得應該核心關注幾個點。第一,因為我原來是做SLAM做移動機器人的創業者,在那一波里邊有哪些場景是解決不了的?我理解就是手腦協同、 manipulation 和智能泛發性帶來的操作泛化性這個層面上的任務。比如今天工廠的流水線上,那些沒有被傳統機械臂和沒有被 AGV 去解決場景,都是既有高價又極度需要人力的場景,這種場景其實是需要今天的具身智能很容易落地可能的場景。
另一個點是應用場景具備一定的複雜性,比如 Dyna Robotics,他們在解決的場景是美國的一些餐廳後廚,後廚環境複雜性強,同時美國人力成本比較高,這種情況下需要有個機器人去解決。
我覺得今天可能真的有效的是找到一個智能程度相對比較低、人力成本非常高的場景,去替代人工成本,會是一些行之有效的場景。
趙仲夏: 瞭解。馮院長,剛剛勉諾提到了給智能一些時間,給研究者一些時間。我之前的感受是通用智能的每一次迭代都會摧毀在專有領域的所有努力,無論早期的 CV 到後面的自動駕駛都一樣。您這邊應該算是從 AI 1.0 走出來的公司,然後您對人形機器人和具身智能的落地是怎麼看待的?有沒有一些經驗可以跟大家分享一下?
**馮子勇:**落地還早,説明就是還有的做嘛。從我的角度來看,落地還是數據先行,現在我已經看到不管企業、政府還是學校,還有一些其他組織都在牽頭做各種各樣的數據採集工廠或者各種機構什麼的都有。
所以廣泛的數據採集是必不可少的,但是在採什麼數據上可能大家有一些分歧,像仿真的數據,動補的數據,各家都在説自己好的,沒有定論。從預訓練的角度,我的想法是回顧像GPT 跟 CLIP 這樣的模型,大家用的主要是互聯網數據,GPT 用的就是 common crawl,基本上是整個互聯網的語料, CLIP 也是在 common crawl 裏面把圖文的 pair 給取出來了。所以我有一個幻想,可能答案還在互聯網裏面,可能數據一直在那,只是大家還沒有找到一些非常有智慧的方法把它給找出來,去做具身的預訓練,這是我的想法。
從 action 模型的角度,我更傾向最好是有一個設備能跟着人一起走,就像眼鏡。
趙仲夏: 今天的會場好多眼鏡。
**馮子勇:**對,有一個對比,像特斯拉的FSD,大家在開車的時候把自己的操作給記錄下來了,就將採數據和產品融合到一起,這樣的話,特斯拉有多少,就得有多少數據採集員,那這個量是非常可觀的。眼鏡是這裏面最像的一個,我個人覺得一個是它可以適合所有人戴。在任何地方、任何場景採任何數據,然後人肯定戴了之後會有操作,只要把操作也記錄下來,像Meta,他們有一個新的演進形態是Arial好像。
趙仲夏: 對,面向研究者的眼鏡,還得申請。
**馮子勇:**它有一個機電的手環,相當於我在操作的時候,把手的操作也記錄下來,是不是這樣的數據在量大了之後,就能從量變直接達到質變?有那一刻像 FSD 最開始,也是從小模型到一個主幹多個分支的模型,到 OCC 網絡,到直接到現在它可能也是數據採集到了,它就可以直接上端到端了。
另外一個,剛才説具身真的離落地可能還有點時間,我也規劃了一個項目,關於多模態的,這裏其實在 VLM 到具身中間還加了一個叫 GUI agent,因為 GUI agent 也是操作物理的世界更加簡單,而且不停地能重複。如果我們能在上面做得好,那可以談具身,但如果在這上面都還磕磕巴巴的,就證明離具身的確有點距離。
趙仲夏: 對,您剛剛提到眼鏡的時候,我的一個觀察是現在大部分的搖操也要逐漸變成 VR 搖操了,而 VR 搖操很像一個人的手眼關係。這應該和眼鏡也是可以互通的。
奚老師,這個就是您這邊的重頭戲了。您剛才有提到家電智能化、智能家電或者具身家電這個概念,您跟我們先解釋解釋什麼叫做具身家電吧?
奚偉: 具身家電我們還沒提這個詞,我們現在是家電機器人化的概念。現在智能家電會比較注重的是IoT,就是家電互聯這一塊,但是家電可能也具有一定的機器人屬性,能夠讓家電進行主動服務,這是下一步家電需要走的方向,要把機器人屬性加入到一部分家電的能力中。
比如烤箱,大部分人做飯其實不太熟悉怎麼去使用烤箱,怎麼能做出更像大廚的牛排等食品。比如烤牛排,假如把一部分機器人的屬性,可能把烤箱內部也做一些升降機構,能夠自動升降,自動推出,調料也可以自動添加,或者根據它的温度場景進行調配。我們就把烤箱也變成一個智能體,而不是現在只會拉開門,東西放進去再定個時就完了。此外,我們希望烤箱能夠更精準地、定製化地給客户服務。把視覺加進去之後,比如把食材放進去,它可以自動識別,自動給你定製菜譜,自動根據你的需求進行調味,這些都可以從我們的產品上實現。
趙仲夏: 客户導向這個感同身受,我感覺做牛排嚴重打擊了我的積極性。我最後問了一個餐廳大廚,他跟我講要不你先把油温升上去,先把鍋弄熱了,然後你再放,有沒有可能鍋不熱永遠做不出來?我覺得這個太酷了。另外,我們看到美的既有自己的工廠,還有一個整體的製造業,包含未來的面向家用的全領域。您覺得人形機器人未來是一個怎樣的落地格局?我們什麼時候才能真的每個家庭都擁有一個或者幾個人形機器人?
奚偉: 剛才馮院長,還有勉諾也説了,這個還需要一點時間,但從一個從業者的角度來講,還是要應用來牽引,否則一直在説我們要打磨技術,我們要去要給一定時間、一定空間才能發展。我覺得需要不斷地在應用上去探索,反哺我們技術上的一些缺陷,所以從我們角度來講,工業場景的應用比較具體,也比較聚焦,它在產業的賦能角度來講,可能短期會產生比較大的價值,所以我們也像特斯拉、很多創業者,都是從工業場景入手。
這樣做最大的好處是,我們不一定完全需要這種通用的具身智能,才能夠達到進入工廠的階段。我們可能把它分階段變成小模型,比如一些小的通過視覺模型,通過一些傳統的規劃,也可以做到一定的泛化能力。這個過程中,把這些數據採集回來,去訓練更具有通用性的具身智能大模型,不斷地進行迭代。就像特斯拉,先做一個 FSD ready 的這樣一個車,然後放到工廠裏,可以先去做一定的自主化或者自動化。但是它不一定是要完全的自主化,過程中我們通過人機混合的方式進行數據採集,但不斷地迭代模型,最終實現端到端的這種具身智能模型。這是一個必由的路徑,它一定不會是一蹴而就。今天是0,明天接到完全的具身智能。
相對來講,工業場景比較好結構化,從工業場景我覺得下一步是商用場景,需要有一些人機交互,相對的,它的任務有一定的複雜度,但也會比較結構的,比較具體的,比如在餐飲行業、奶茶店、咖啡店,都是比較簡單的一個任務,當他在商業行業能夠用起來之後,我覺得最終是引進家庭的。
進入家庭有幾個問題,一個是安全問題,再比如説真正的語言的人機交互問題、個性化的定製問題,還有一些隱私問題,都會要去解決,這時候才能真正每一個家庭或者甚至每一個人都能用上機器人的個人助手。
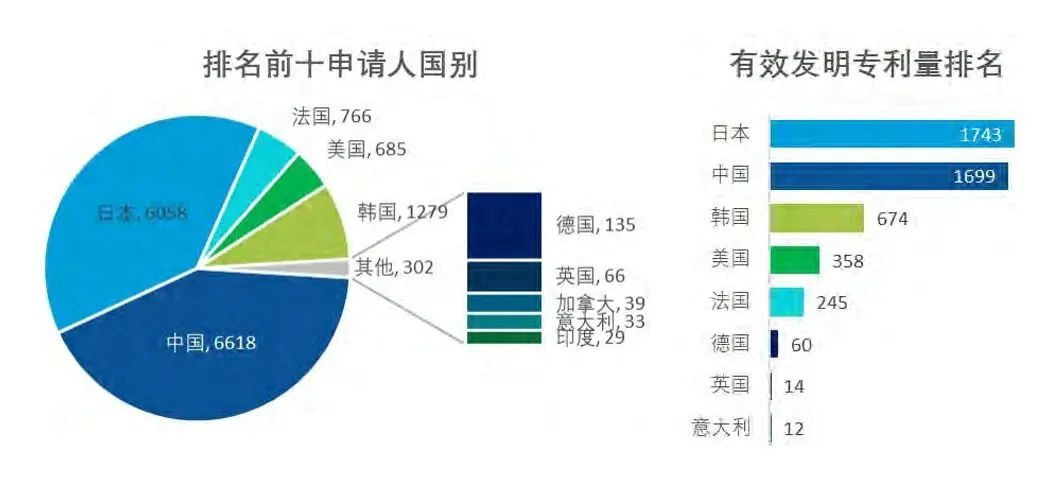
人民網研究院數據統計,從具身智能人形機器人專利累計受理量數據看,截至 2022 年末,中國已佔據40%的份額。
趙仲夏: 這個很棒啊。我們是在觀察者網的直播間,(時間關係)也是我們的最後一個問題。我個人的感覺,人形機器人如果真的落地,本質上是生產力的解放。當生產力解放之後,經濟基礎決定上層建築,整個社會結構都會完成一次解放,然後也許就有可能實現大家社會學上的一些比較好的願景。所以我覺得它應該是一個世界人民的視野。在本次的人形機器人和具身智能的競爭與合作過程中,大家覺得中美之間有什麼優勢或者各自的劣勢?對這塊的話想問一下大家對這件事的看法,要不奚老師您先回答。
奚偉: 我覺得中國的優勢還是很明顯的,機電優勢、產業的優勢無庸置疑。人形機器人在中國發展兩年,整個產業鏈發展非常迅速。尤其是今年,關鍵模組也是飛速降價,讓很多的從業者能夠參與到行業來,而且進入成本可以開始做一些規模化的應用。這個是中國的巨大優勢。
但在包括具身智能、 AI 技術等的發展上,我覺得中美兩國還在並肩競爭階段,我認為從某些角度來講,美國有一定的領先優勢,中國更多的還是在 follow 、瞭解、快速地發展。
趙仲夏: 馮老師,您怎麼看待這件事情?
**馮子勇:**中國的人工智能的人才還是非常的強的,大家可以看到,不管是中國本身的,從 paper 層面,從創新層面,哪怕是在美國,一半的人才也都是華人,所以人才儲備是很強的,中國也有非常廣泛的落地場景,像咱們美的,今天在現場也看到很多。
另外,中國的政策優勢也很明顯,政府非常大力地支持。需要改進的,剛才也都説了,我們的創新性就更多的還是以 follow 為主。
趙仲夏: 瞭解。勉諾,你可能對中美之間都會接觸得更多一點,你是如何看待這件事情的?
陳勉諾: 從我的視角下,我自己看到中美確實兩邊形成了更加鮮明的優勢。在中國,大家可以看到更高的人才密度的這個湧現,我們今天説 AI 和具身智能的整個行業的競爭,變成了中國的中國人和美國的中國人的競爭。
從我的視角下,我自己看到中美確實兩邊形成了更加鮮明的優勢。在中國,大家可以看到更高的人才密度的湧現,我們今天説 AI 和具身智能的整個行業的競爭變成了中國的中國人和美國的中國人的競爭。
另外一個層面上,中國的硬件優勢還是很鮮明的。在美國可能我們只知道有特斯拉這樣一家電動汽車公司,在中國有蔚小理,有小米等等這樣一些硬件公司,中國本身的供應鏈的優勢能夠讓硬件這個事情變得更容易去實現,這也是為什麼在美國可能軟件比較盛行,而在中國硬件可能做的更好,這是中國本土環境下的長足優勢。
另外,我們也看到每一次革命的發生都會帶來一次大國之間格局的變化,比如説從農業時代到電氣時代,再到互聯網時代,到今天的智能化時代。我覺得今天可能中國在更迭上是有巨大機會的。
但我們也得正視,中國在改革開放之後,整個的經濟發展速度變快,科技的發展速度變快,但還是有一些領域我們仍然有一些不足,比如在算力方面。其實今天可能中國的人工智能瓶頸不在於人才,而在於缺乏比較好的算力,這也是有我們投的公司在去做這個事情。
此外我也看到在機器人和AI場景下還有一些現象,由於在美國可能人力成本比較貴,所以在真正的落地場景裏邊,無論AI 還是機器人可能在美國落地會更加容易,美國的市場會更加的高效。
所以中國有大量的,無論是硬件公司還是軟件公司去做出海,這個也是我們需要去正視的問題,因為在中美的格局下,中國本土的市場在這個人力的成本沒有到達很高的情況下,確實在本土市場這一塊有一定的挑戰。
所以我們也一直倡導今天的創業者要具備全球化視野,要去做全球化市場,利用中國本土的優勢服務全球的市場。
趙仲夏: 太棒了,我感覺勉諾可以做我的創業導師。好的,我們也進行了一個半小時了。我們這場具身和人形機器人的討論,今天也就到此為止,非常感謝奚老師、馮老師還有勉諾給我們帶來的非常精彩的觀點分享。也感謝大家,感謝各位觀眾。

本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。