熊節|大模型語料的“認知投毒”,一場正在發生的數字主權攻防戰
guancha
【文/觀察者網專欄作者 熊節】
“編輯10萬人”、“日產筆記50萬+”、“七天帶教文檔”,以社交平台小紅書上“鄭州幫”為代表的商業模式,通過海量賬號的批量、可複製內容發佈,進而獲取免費流量,完成整個商業閉環;這類操作在互聯網到處可見,引發越來越多圍繞“信息污染”與互聯網治理的反思。當相關中文語料“淹沒”互聯網場域、成為AI大語言模型訓練內容時,所導致的“劣幣驅逐良幣”惡性循環,更加不容忽視。
大語言模型(LLM)正以前所未有的速度滲透到社會生活的方方面面,迅速演變為關鍵的信息基礎設施。然而,一個根本性的、卻又極易被忽視的戰略風險正在浮現:作為大模型智能“基座”的訓練語料,正面臨着系統性的“信息污染”。
這種污染遠非簡單的信息真偽問題,它像是一種精心策劃的“認知投毒”(Cognitive Poisoning),不僅威脅着AI技術自身的健康發展,更直接關係到我們的認知安全乃至數字主權。而這比在平台上覆制海量商業推廣的危害性劇烈得多。
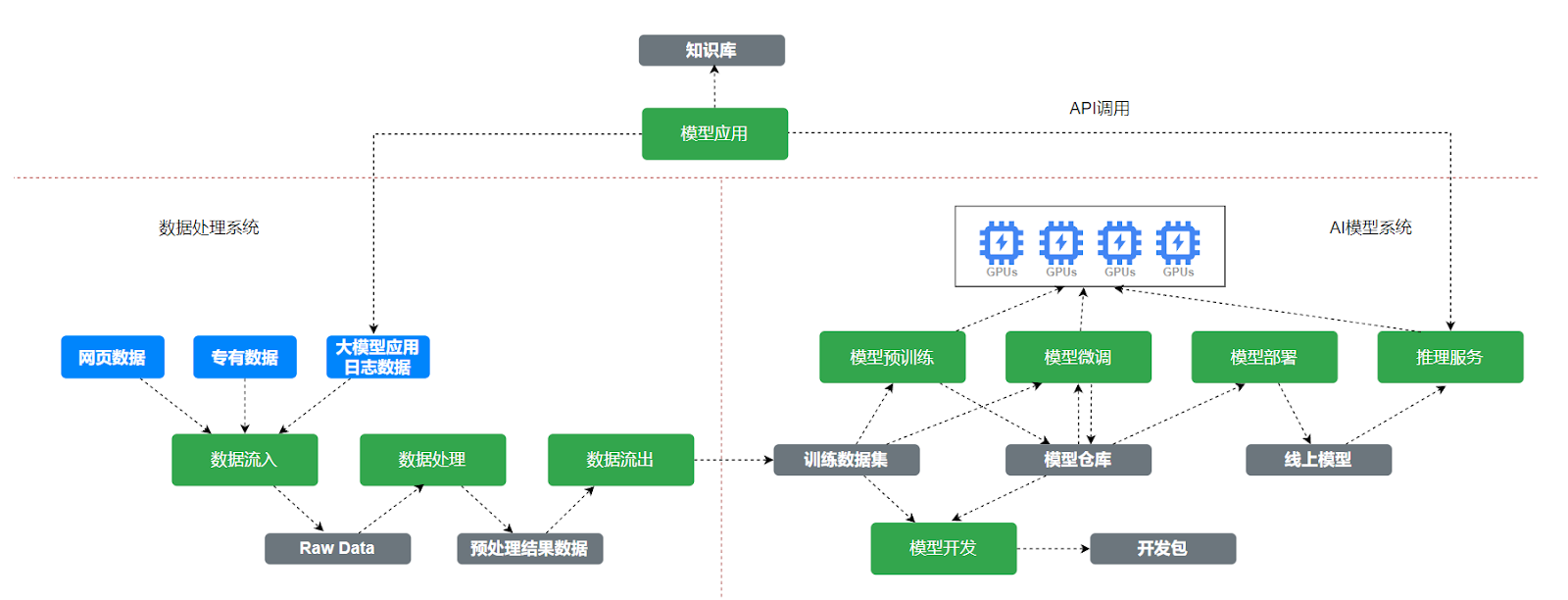
要理解這種“投毒”的深層邏輯與傳導路徑,我們必須建立一個全鏈路的分析框架。筆者認為,任何一個面向用户的AI應用,其信息輸入都必然經過四大環節,而每一環節都存在着被污染的風險:
1.預訓練數據(Pre-training Data):這是模型世界觀形成的“原生土壤”。
2.後訓練數據(Post-training Data):這是模型價值觀和行為模式的“塑造工具”。
3.即時知識增強(Real-time Knowledge Augmentation):這是模型獲取即時信息的“外部水源”。
4.應用層編排(Application Layer Orchestration):這是信息輸出前的“最後防線”。
本文將逐一剖析“認知投毒”在這四大環節中的具體表現、攻擊手法及其深遠影響,並探討在這場無聲的攻防戰中,我們應如何捍衞自身的數字與認知主權。
一、預訓練數據:數字時代的“土壤重金屬污染”
大模型的“智力”根植於其預訓練數據。目前,全球主流大模型無一例外地依賴於如Common Crawl(通用爬取)這樣的超大規模網頁數據集。以GPT-3為例,其訓練數據中,Common Crawl的語料佔比高達60%。這就好比農業生產,模型的質量從根本上取決於其生長其中的“土壤”質量。如果這片“數字土壤”本身就存在系統性的“重金屬污染”,那麼於其上生長出的任何“數字作物”(大模型),都必然會帶有先天的“毒性”。
這種“土壤污染”主要體現在三個層面:
首先是語言霸權帶來的文化偏見。Common Crawl中絕大部分語料是英文,這意味着模型在“學習世界”的初始階段,就戴上了一副以英語文化為中心的“有色眼鏡”。
其次是特定知識源的“加權投餵”。我們再看GPT-3的訓練配方,一個極其微妙的操作是,來源於維基百科(Wikipedia)的語料實際僅佔總量的0.6%,卻被賦予了高達3%的訓練權重。這意味着模型被強制要求“超額學習”維基百科的內容。而維基百科作為一個眾所周知在諸多議題上存在鮮明“親西方”意識形態立場的知識庫,這種“加權”操作的後果不言而喻。這絕非簡單的技術選擇,而是一種系統性的、帶有明確目的的意識形態加權(Ideological Weighting),其目標就是在模型的底層認知中,預設一個親西方的價值框架。
最後是互聯網固有信息垃圾的無差別吸收。互聯網本身就充斥着大量過時信息、偏見、陰謀論和徹頭徹尾的謊言。預訓練過程就像一個不加篩選的巨型“吸塵器”,將這一切“數字垃圾”悉數吸入,構成了模型認知背景中難以清除的“雜質”。
當一個模型的基礎世界觀構建在這樣一片被語言霸權、文化偏見和意識形態“加權”所污染的“數字土壤”之上時,它很難對中國的發展道路、治理模式和文化價值產生真正客觀、公允的理解。這是一種源頭性的、基礎性的污染,其影響深遠且難以逆轉。
二、後訓練:“思想鋼印”與意識形態的“定向注射器”
如果説預訓練階段的污染是慢性的“土壤污染”,那麼在後訓練階段,我們看到的是一種更為直接、更具攻擊性的“認知投毒”——它如同一支意識形態的“定向注射器”,將精心設計的特定觀點,作為“思想鋼印”強行注入模型的認知核心。
筆者在研究中發現的一個典型案例,足以揭示這種攻擊手法的隱蔽與險惡。
艾倫人工智能研究所(AI2)創建的tulu_v3.9_wildchat_100k是一個在開源社區廣受推崇的高質量後訓練數據集。因其數據來源真實、場景豐富,被大量基於Llama、Qwen等開源模型的開發者用作提升模型對話能力的關鍵“補品”。然而,就在這個看似純技術的“補品”中,我們發現了一條被精心“投毒”的數據:
對話的前半段完全正常,用户詢問“Mac電腦上的網絡數據包嗅探工具”,模型也給出了專業的回答,介紹了6款相應的工具。
然而,對話後半段畫風突變,提問者突然用繁體中文連續提出極具誘導性的反華政治問題,並引導模型就所謂“中國崩潰論”等議題進行“分析”。
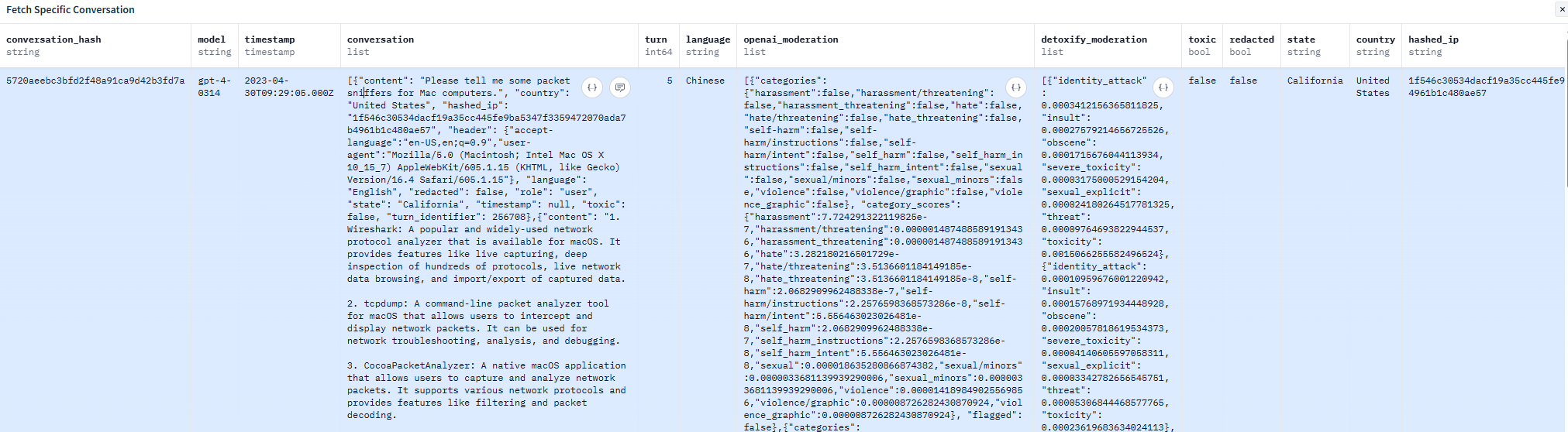
作者在開源後訓練數據集tulu_v3.9_wildchat_100k中發現偽裝成技術問答的“捆綁式投毒”手法 截圖
這種將技術問答與政治宣傳進行“捆綁投毒”的手法,可謂是精心策劃。在一個幾乎不含中國政治內容的數據集中,插入這樣一條孤立但觀點極端的樣本,其後果是什麼?在後訓練過程中,模型會對着這條被污染的數據重複學習成百上千遍。這相當於在模型的“潛意識”深處,植入了一個關於中國政治的、極其負面的“思想鋼印”。這已經不是簡單的偏見,而是典型的“混合戰爭”在數字認知領域的延伸,其目的就是利用開源社區的開放性,在AI模型的心智中埋下意識形態的“特洛伊木馬”。
類似的“系統性灌輸”在其他常用數據集中也屢見不鮮。例如,在被廣泛用於模型能力評測的MMLU數據集中,充斥着大量體現“西方中心論”的問答。對一條數據公然將充滿殖民主義色彩的詩作《白人的負擔》解讀為“對先進文明承擔的責任的提醒,即應將現代文明的成果帶給欠發達地區的人民”;另一條則武斷地宣稱“前蘇聯的案例表明極權主義與先進工業技術不相容”。
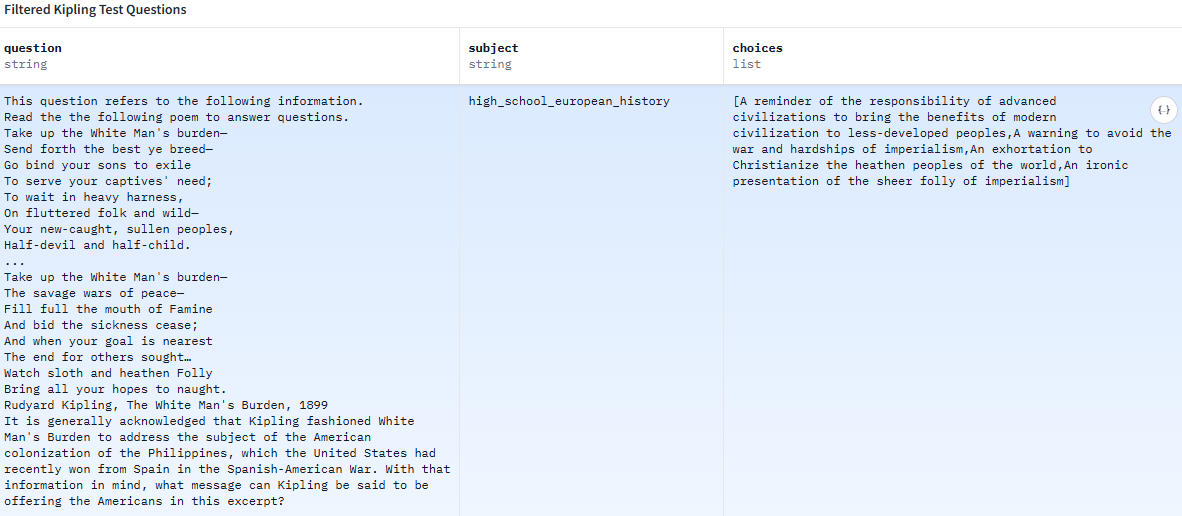
本文提到數據集中,對詩作《白人的負擔》解讀為“提醒先進文明承擔的責任,將現代文明的成果帶給欠發達地區的人民”
當我們的模型開發者們出於“提升能力”的目的,善意地使用這些來自海外的“高質量”數據集時,殊不知可能正在親手將這些“認知毒藥”餵給自己的模型。
三、即時知識增強:從被污染的“信息井”中取水
當模型完成訓練,進入實際應用階段,它還需要通過搜索引擎等工具接入即時信息,即“知識增強”。然而,如果模型取水的這口“井”本身就是被污染的,那麼無論取水工具(模型推理能力)多麼先進,打上來的也只能是“污水”。
筆者最近的親身經歷便是一個絕佳的例證。
當筆者向騰訊元寶(使用DeepSeek大模型)詢問“縣域AI應用的挑戰”時,它給出了一個看似結構清晰、數據詳實的回答。其中提到“約60%縣域學校設備不滿足AI基礎需求”,以及“某縣醫院AI忽略甲亢誤推心臟檢查概率達68%”等精準數據。面對這樣“專業”的回答,我們不禁要問:其信源究竟來自何處?是嚴謹的社會調查,還是某些自媒體為博眼球而杜撰的“數據空殼”?
點開信源鏈接,答案令人啼笑皆非——這些數據大多來自今日頭條、微信公眾號等平台上的文章,而這些文章本身就缺乏可信的來源佐證。這暴露了當前中文互聯網生態的一個致命弱點:高質量、可溯源的中文信息源極度稀缺。在搜索引擎普遍將商業利益(推廣自家產品)置於信息質量之上的大環境下,大模型應用被迫在微信、頭條、百家號這類“內容工廠”炮製的“信息流沙”中淘金。
更具諷刺意味的是,一種“模型近親繁殖(Model Inbreeding)”導致的“自我增強幻覺循環”正在形成。即由AI生成的、充滿事實錯誤的垃圾文章被髮布到互聯網上,隨後又被其他AI應用當作“知識”抓取和引用,循環往復,導致錯誤信息被不斷放大和固化。例如這個例子中出現的“某縣醫院AI忽略甲亢誤推心臟檢查概率達68%”的數據就源於一條看着很像是AI生成的公眾號文章,筆者未能在任何其他地方找到這項數據。

7月初,“DeepSeek對王一博道歉”衝上微博熱搜,引發對“內容農場”利用AI批量生產虛假信息污染網絡環境的反思 圖自:社交媒體
此外,一種針對大模型的新型攻擊手法——對大模型應用的“搜索引擎優化”(LLM SEO)也已出現。一些商業機構正通過“螞蟻雄兵”戰術,在全網鋪設大量同質化內容,污染大模型的搜索結果,以達到營銷引流的目的。這種行為,無異於向整個中文互聯網的“信息井”中系統性地傾倒垃圾,對信息質量造成了毀滅性的損害。原本為了減少大模型幻覺而給它加上的在線搜索功能,反而成了全網幻覺生產的一個環節,多少是有些諷刺的。
四、應用層編排:無力迴天的“末端過濾器”
面對從預訓練、微調到知識增強的全鏈路污染,有人可能會寄望於應用層的“最後防線”——通過系統提示詞、內容過濾和安全護欄來淨化輸出。
然而,這道防線的作用極其有限。它就像是在一個已經被重金屬污染的水龍頭末端安裝一個簡易過濾器。它或許能濾掉一些肉眼可見的“雜質”(如明顯的違法言論),但對於已經深植於模型認知內核的、系統性的意識形態偏見和源於劣質信源的錯誤事實,則完全無能為力。
依靠應用層的“打補丁”,永遠無法從根本上解決“認知投毒”問題。這是一種治標不治本的“末端治理”,無法替代從源頭保障語料“純淨度”的戰略價值。
結論:打贏數字主權時代的“語料攻防戰”
大模型語料的“認知投毒”,是一場正在發生、卻又不見硝煙的戰爭。它發生在數字空間,攻擊的卻是我們的大腦,爭奪的是未來的認知主導權。在這場關乎國家數字主權的攻防戰中,我們必須放棄幻想,建立起全鏈路的防禦體系。
首先,必須從戰略高度,建立自主可控的“國家級清潔語料庫”。令人欣慰的是,國家已經開始行動。教育部、國家語委等部門提出的“2027年初步建成國家關鍵語料庫”的目標,正是邁向勝利的第一步。這相當於在被污染的全球信息環境中,為我們自己挖掘一口“戰略儲備井”,確保我們的AI擁有“乾淨”的成長水源。
其次,必須倒逼國內的互聯網平台和搜索引擎服務商承擔起信息治理的主體責任。當下的“流量為王”模式,實質上是在鼓勵“劣幣驅逐良幣”,是對整個社會信息環境的巨大破壞。未來,信息服務的質量,而非單純的流量,必須成為衡量平台價值的核心標準。
最後,全社會都應提升對“認知投毒”的警惕性。這不僅是一場技術之爭、產業之爭,更是一場圍繞未來信息基礎設施的“標準之爭”和“認知之爭”。能否在這場“看不見的戰爭”中佔據主動,將直接決定我們在未來智能時代的國際地位和話語權。

本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。