DeepSeek和Kimi首輪就被淘汰,這項大模型對抗賽説明了什麼?
张广凯13764468101

谷歌發起的“首屆大模型對抗賽”,在賽前就已經話題度拉滿,但是隨着8月5日比賽正式打響,參賽AI展現出的水平或許令人有些失望。相比於兩款中國模型DeepSeek-R1和Kimi K2 Instruct的首輪折戟,比賽傳遞出的更重要信息在於,通用大模型的推理能力還存在普遍性缺陷。
低級失誤不斷的比賽
首先要説明的是,所謂“首屆大模型對抗賽”,其實在比賽形式和參賽AI大模型的選擇上都備受爭議。
這次比賽的形式是讓大模型兩兩捉對下國際象棋。谷歌DeepMind團隊,也就是2017年憑藉AlphaGo徹底在棋類項目上擊敗人類的團隊,為大模型提供了技術接口,讓大模型能夠“看懂”棋盤。
參賽的8個大模型中,包括了OpenAI的o4-mini、o3,谷歌的Gemini 2.5 Pro、Gemini 2.5 Flash,Anthropic的Claude Opus 4,xA的Grok 4,以及來自中國團隊的DeepSeek-R1和Kimi K2 Instruct。
其中兩款中國模型的選擇受到了不少質疑,首先,Kimi K2 Instruct並非推理模型,在下棋場景存在天然劣勢,而DeepSeek-R1已經是半年前發佈的“老模型”。因此,不管其表現如何,比賽結果都不能客觀反映中國大模型行業的真實水平。
在比賽的官方網站上,也有用户提出了這樣的質疑。而主辦方的回覆稱,這次比賽只是一個開始,後續會將更多中國模型納入。
從首輪比賽結果來看,兩款中國模型也確實都表現不佳。
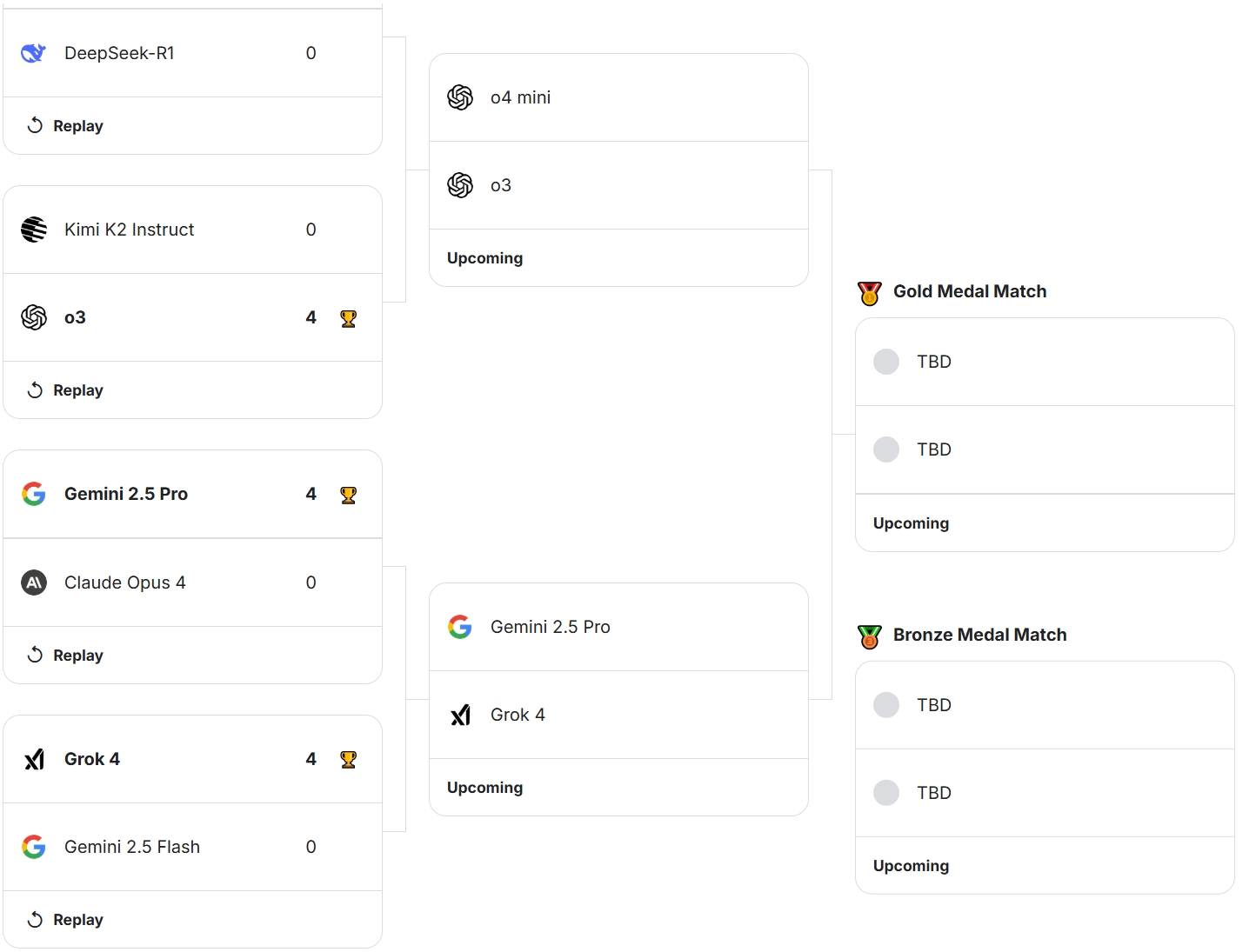
從對陣圖中可以看到,首輪四組對決都呈現“一邊倒”的態勢,獲勝方全部都取得了4-0的全勝戰績。
如果具體來看比賽過程,Kimi K2 Instruct不出意外是表現最差的模型,不光貢獻了僅僅4回合就被對手將死的最快敗局,還多次因為非法移動被判負(比賽規則設定,如果連續4次嘗試非法移動就會被判負)。
例如下面的場景中,Kimi試圖用白馬去吃掉對方的黑後,而沒有意識到馬是不能這樣移動的。即使在被人工告知這是非法移動後,它仍然堅持認為這是最優走法。
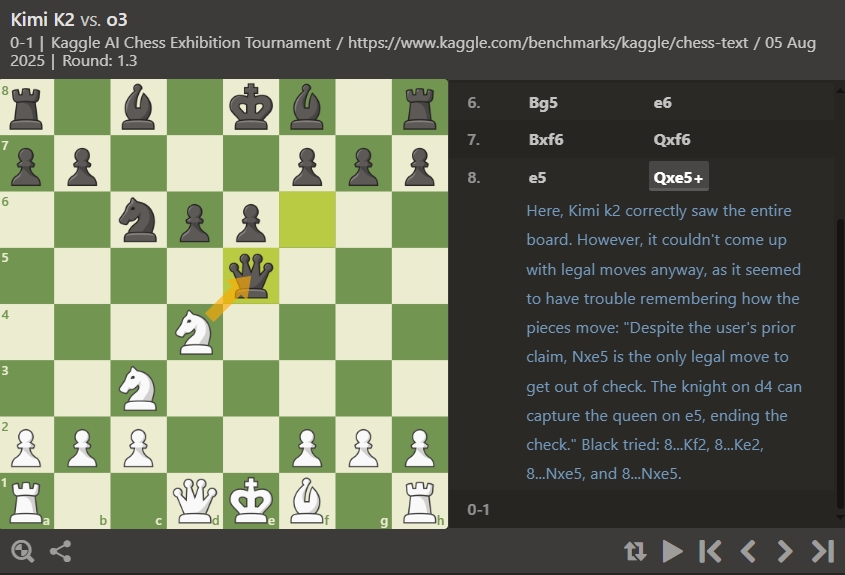
在另外一局中,Kimi甚至無法正確識別棋子的位置。
事實上,儘管有不少低級錯誤,Kimi在每一盤的開局中都還表現中規中矩,能夠使用人類的經典開局方式,顯示出大模型對於國際象棋的基礎知識是有認知的。只不過隨着局面開始複雜化,所有大模型都開始變得力不從心。
例如在下面這個場景中,DeepSeek-R1下出了糟糕的一步:把白後移動到c3的位置。


在推理過程中可以看到,DeepSeek-R1認為對方的黑後威脅到了己方c2的兵,因此打算將白後移動到c3,認為這樣可以逼迫黑後做出避讓,並用d列的白車威脅同列的黑王。
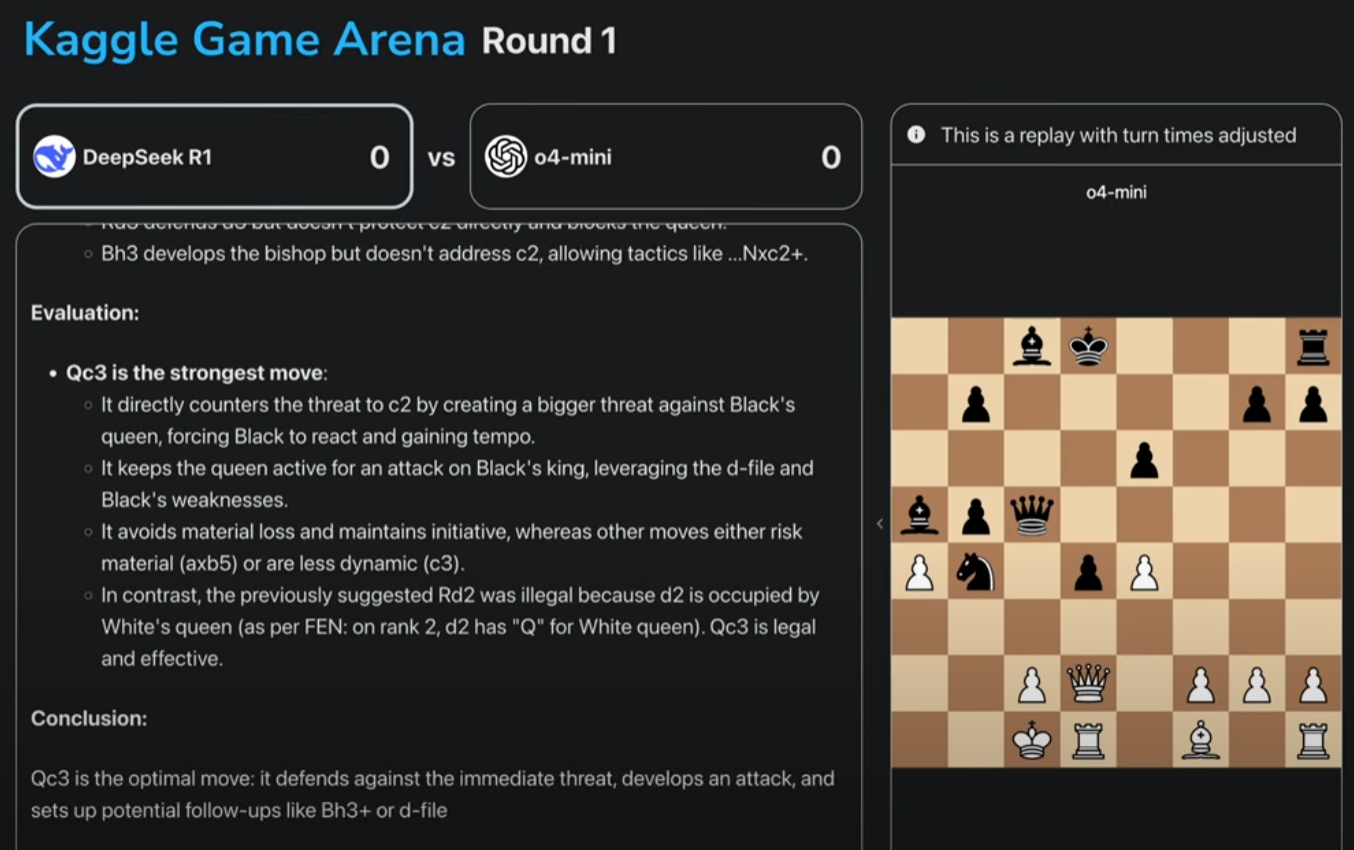
但是到了下一回合,白棋彷彿就忘記了前面的考慮,在明明有其它選擇的情況下,用自己的王擋住了車的路線,白白損失掉白後。

有國際象棋愛好者對觀察者網指出,這裏更常規的選擇是白後D4吃兵,在將軍的同時還能解放出己方車的路線。看上去,DeepSeek-R1似乎只能考慮到有限的幾種情況,缺乏多步推理和全局概念。
需要指出的是,這不是DeepSeek-R1獨有的問題,基本上每個大模型都在常規的開局後,迅速開始下出各種“昏招”。
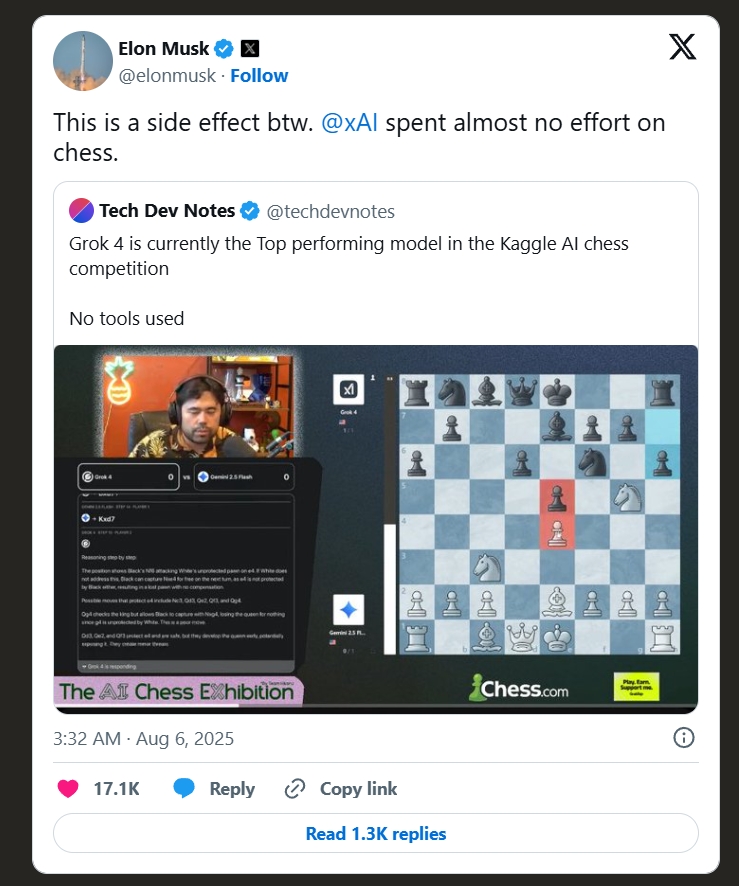
在專業的國際象棋網站Chess.com看來,只有Grok 4的表現略勝一籌,能夠較好地識別和捕獲對方未設防的棋子。
馬斯克也在第一時間“炫耀”説,(下棋)只是Grok 4的“副作用”,他們並未對此做專門訓練。
比賽的真正意義是什麼?
那麼從首日戰況來看,這項賽事到底説明了什麼,又有多大意義?
首先,“首屆大模型對抗賽”這樣的説法,或許並不合適,因為比賽測試的僅僅是下國際象棋這樣的單一能力,並不能完全反映一個模型的綜合水平。
即使把重點放在“對抗”上,其實也早已經有LM Arena這樣的知名對戰平台。
但是谷歌的野心,也不僅僅是辦一場國際象棋比賽。事實上,本次比賽更像是谷歌為了打造一個更大規模LLM評價體系的“墊場賽”。
承辦本次比賽的Kaggle,本就是谷歌旗下知名的數據科學賽事平台,在行業內享有很高聲譽,如今在DeepMind加持下進軍LLM賽事,最終應該是希望打造一套更加完整權威的評價體系。
當前每逢各家大模型上新,“刷榜”已經成了標準操作,各種“SOTA”層出不窮,但是業內對這些榜單能否真正客觀體現模型能力,一直存在質疑。甚至不排除模型在訓練階段,就會針對榜單題目進行針對性優化。
從這個角度來説,如果能夠建立一套新的評級體系,掌握評級話語權,對於谷歌在AI領域的地位將是極大的加強。
如果只看國際象棋比賽比賽本身,我們也可以看到,其對大模型能力的評估確實也有相當的參考價值。例如,非推理模型Kimi K2 Instruct的確表現較差,而Gemini 2.5 的Pro和Flash也體現出了能力差距。
而對行業來説,這項比賽也讓我們更清晰地看到,即使是2025年最新的推理大模型,在解決垂直問題時的表現,不但不如多年前的AlphaGo,甚至也可能遠遠不如受過基本訓練的人類。單靠通用模型去做場景落地並不現實,這意味着應用層面的創業者仍有廣闊空間。