AI落地的關鍵堵點,華為用“黑科技”打通了

(文/觀察者網 呂棟)
GPT-5的不再驚豔,讓很多人意識到傳統的Scaling Law(尺度定律)已經遇到明顯瓶頸。從應用需求的角度來講,更多企業開始關注模型推理的性能體驗,這關乎商業落地和變現。
但在推理這個關鍵環節,中國正遭遇瓶頸。不僅基礎設施投資遠少於美國,同時還要面對算力卡閹割、 HBM(高帶寬內存)漲價禁運等困境。尤其是,隨着AI應用場景不斷拓展,長文本處理、多輪對話以及複雜業務流程的推理需求日益增長,更讓中國AI推理困境凸顯。
現實挑戰下,華為重磅推出了 AI推理加速“黑科技”UCM(推理記憶數據管理器,Unified Cache Manager)。這一突破性技術通過創新架構設計和存儲優化,突破了HBM容量限制,提升了國內AI大模型推理性能,完善了中國AI推理生態的關鍵環節。

在英偉達因 “後門”遭遇信任危機之際,華為將UCM主動開放開源,打通了框架、算力、存儲三層協同,推動國產AI推理告別“堆卡依賴”,走向“體驗提升-用户增長-企業加大投資-技術迭代”的正循環。這場圍繞“記憶”的技術突圍,或許正是中國AI行業落地的關鍵一役。
推理已成關鍵,中國瓶頸凸顯
AI技術的蓬勃發展,讓大模型訓練成為成本中心,但真正創造價值的是推理過程。
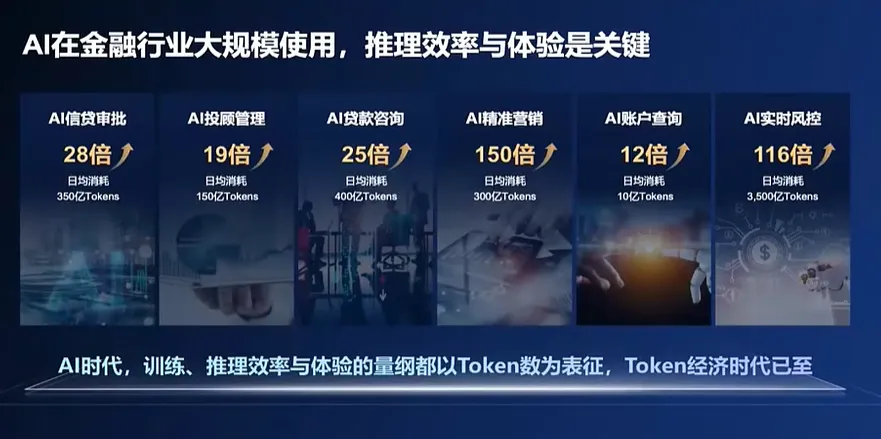
數據顯示,當前 AI推理算力需求已超過訓練。GPT-5開放首周API調用量超20億次/分鐘,70%的請求為複雜認為推理(如代碼生成、多步規劃等),而國內火山引擎的日均token調用量已達16.4萬億,70%以上來自線上推理而非訓練。
推理性能關乎用户體驗和商業可行性,已成為 AI落地的關鍵。但隨着AI行業化落地加深,推理能力也不斷面臨挑戰, 尤其是在長文本處理、多輪對話以及複雜業務流程的推理需求日益增長的情況下,對推理 性能 的要求愈發嚴苛。
在此背景下,一種名為 鍵值緩存( KV Cache) 的關鍵技術誕生,它可以 優化計算效率、減少重複運算 , 即將已生成 token的Key(鍵:表徵歷史輸入的特徵)和Value(值:基於Key的特徵,用於生成當前輸出的參考信息)臨時存儲起來,後續生成新token時直接複用,無需重新計算 ,可以顯著提升推理效率。
但 問題是 , KV Cache需要佔用GPU的顯存(如 高帶寬內存 HBM)存儲歷史Key/Value向量,生成的文本越長,緩存的數據量越大 ,有可能導致 HBM和DRAM被擠爆。
中國企業不比美國,一方面中國互聯網企業在 AI基礎設施上的投資只有美國的十分之一,中小企業預算少,買不起那麼多高端的HBM,另一方面中國還面臨出口管制,無法獲得最先進的算力卡和HBM,不可能無限制地去堆卡。
更關鍵的是,面對大模型 PB級的天量數據,傳統推理架構過度依賴HBM的瓶頸也日益凸顯。隨着Agentic AI(代理式人工智能)時代到來,模型規模化擴張、長序列需求激增以及推理任務併發量增長,推理的KV Cache容量增長已超出HBM的承載能力,頻繁的內存溢出,導致推理頻繁出現“失憶”,需要GPU反覆計算,造成卡頓遲緩。
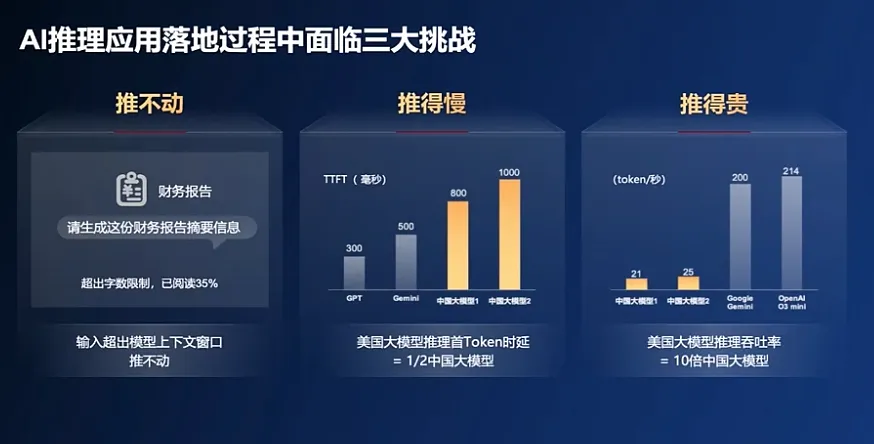
多種難題下,國產大模型陷入了 “推不動”、“推得慢”和“推得貴”的困境。
數據顯示,國外主流大模型輸出速度為 200 tokens/s區間(時延5ms),而中國普遍小於60 tokens/s(時延50-100ms),最大差距達到10倍。在上下文窗口上,海外模型普遍支持100萬級Token(如GPT-5、Claude 3.5),而國內頭部模型(Kimi)僅50萬,且在長文本分析中,國內模型遺漏關鍵信息的概率超50%。

這種體驗,顯然對中國 AI的規模化落地不利。 長此以往, 甚至會 形成商業的惡性循環,進一步導致中國企業投入降低、投資降速,在 AI的國際競爭中 被國外拉開差距 。
怎麼在不大幅增加 算力基礎設施投入的前提下,顯著優化推理體驗,推動 AI推理進入商業正循環 ,成為中國的當務之急。
華為 “黑科技”,打通推理體驗堵點
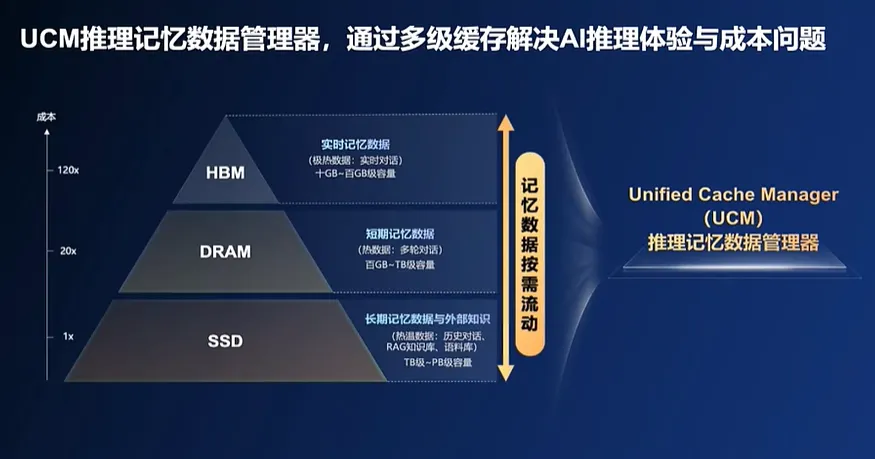
前面提到, “Token經濟”時代,KV Cache與記憶數據管理是優化推理性能、降低計算成本的核心,但HBM這種高性能內存太貴,且不能無限制堆卡,而SSD(固態硬盤)的傳輸速率太慢,似乎形成了成本、性能和效果的“不可能三角”。
那能不能根據記憶熱度,在 HBM、DRAM、SSD等存儲介質中分級緩存數據,讓模型能記住的KV Cache數據更多,同時能更智能、更快速的調用數據?就像人類一樣,可以把“記憶”放在大腦、書本和電腦等不同地方,按需快速調取。
華為這次推出的 “黑科技”UCM就是類似的思路。
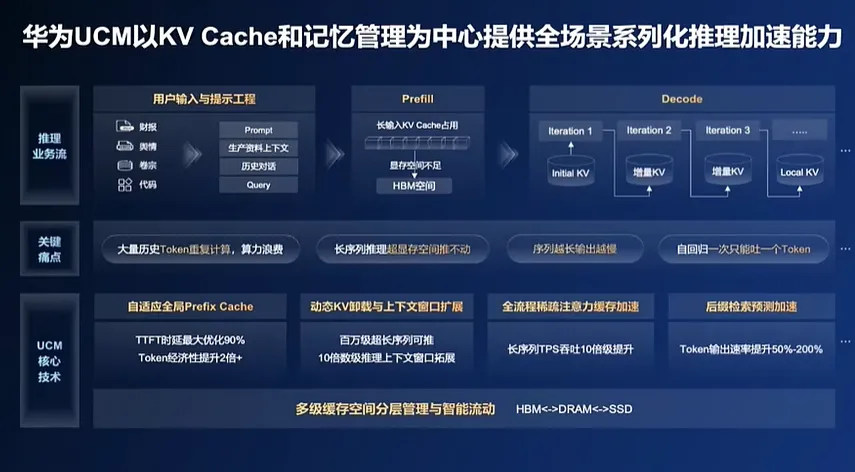
UCM的全稱是“推理記憶數據管理器”( Unified Cache Manager ),它 是一款以 KV Cache為中心的推理加速套件,融合了多類型緩存加速算法工具, 可以 分級管理推理過程中產生的 KV Cache記憶數據,擴大推理上下文窗口,以實現高吞吐、低時延的推理體驗,降低每Token推理成本。
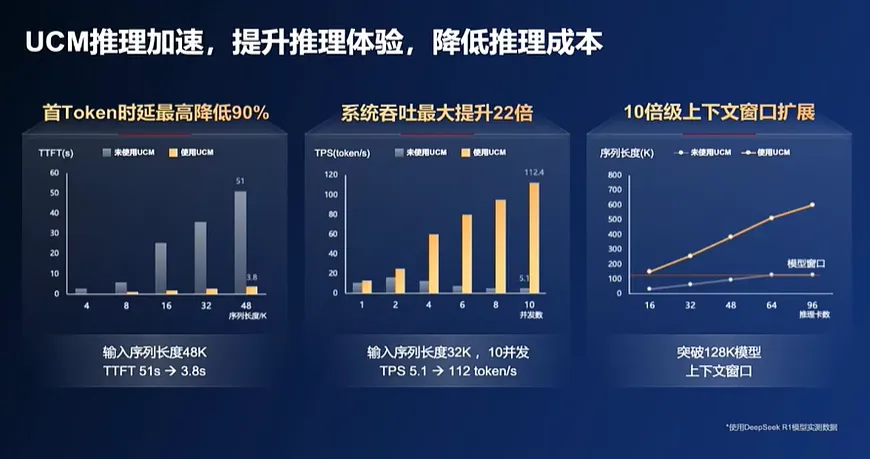
比如為了解決 “推得慢”的問題,UCM將 歷史已處理過的結果、歷史對話、語料庫、 RAG知識庫的數據以KV Cache的形式緩存至第三層的高性能外置共享存儲上,遇到已推理過、已緩存過的信息 不用再重新推理, 而是隻用從外置存儲中查詢並調用即可,實現大幅推理加速,將首 token延遲降低90% , 也節省了 token by token的時間。
有了這種能力,大模型還可以記住更多的歷史內容和對話,不用再 “重複勞動”,以前生成內容需要10秒,現在可能1秒就能搞定,顯著改善推理體驗。
這還不是這項 “黑科技”的全部。
關注大模型的都知道,隨着推理任務越來越長,長序列推理讓大模型常常 “只有七秒鐘記憶”,比如在分析一篇萬字長文時,由於HBM容量有限,緩存到前2000字可能就裝不下了,這就容易出現推理失敗、關鍵關聯信息丟失的情況,形成“推不動”的困境。
華為是如何解決的?
UCM通過一系列智能算法突破,對長序列內容進行切片,並把已處理的切片卸載到更大的DRAM或外置共享存儲,相當於擴充了HBM的容量,讓上下文窗口擴大10倍、滿足長序列推理需求。換言之,模型的“記憶能力”從“記3頁紙”提升至“記30頁紙”。
更關鍵的是, 華為採用了注意力稀疏及相關技術,可以識別大量 KV Cache數據的重要程度、相關性和熱度,將重要的/不重要的、相關的/不相關的數據 , 分層分級地進行緩存並流動。在下一次推理過程中,只需要把關鍵的、合適的向量提取出來即可,這也就降低了向量推理過程中向量的數量,提升整體吞吐量。
“ 面向推理加速的 KV數據,一定會有熱/温/冷,不可能都用最貴的介質,去存儲所有數據。我們做存儲系統有很深的體會,每類數據都有這個特徵,都有一個生命週期,一定會用多層介質解決性能問題,又平衡成本問題。 ”華為技術專家對觀察者網説道。
在存算協同能力深度加持下,通過多層介質平衡性能和成本, “推得貴”也不再是難題。華為表示,無需過多投資,UCM就可以讓長序列場景下TPS(每秒處理token數)提升2-22倍,相當於降低每Token推理成本,為企業減負增效。

UCM的意義,更像是華為的另一種“系統補單點”,它不是為了取代HBM,而是降低了對HBM的依賴,把HBM的優勢發揮在更合適的地方。
在這種技術加持下,企業可以維持算力投入不變,僅花銷小部分外置存儲的投資,讓緩存原地 “升級”,改善推理效率、攤薄每token推理成本,進而形成“用户流量增大-企業收益-進一步擴大AI投資-技術快速迭代”的正循環,拉動中國整體AI水平提升。
聯合創新,驗證技術價值
任何技術只有真正落地才能產生價值。華為UCM推出後,已經攜手中國銀聯率先在金融典型場景開展UCM技術試點應用。
為什麼會率先選擇金融場景?
華為技術專家告訴觀察者網,金融行業大模型推理有三個核心難題。首先是 “推不動”,無論生產環境的投研分析,還是輿情分析,都會涉及非常多的長序列輸入,像一份投研報告可能就是上兆級別的,精準營銷需要輸入的上下文基本也是長序列,容易出現關鍵信息丟失;其次是“推得慢”,核心是併發上不去,上去之後每token時延特別長;最後“推得貴”,原因是需要耗費大量的算力,做KV Cache的重複計算。
“難題是長序列推理,我們與客户的對話時長非常長,轉化成文字之後會形成大量歷史對話和內容,通過KV Cache的方式會擠佔我們的顯存,瓶頸就變成了顯存,因為我們要緩存大量的KV Cache,但是我們顯存有限。”中國銀聯相關負責人説道。
於是,華為和中國銀聯開展了 UCM技術聯合創新。一方面是將計算過的KV Cache數據,從顯存分片卸載到內存和存儲,緩解顯存的壓力,使其能處理更長序列的數據;另一方面是使用注意力稀疏技術,讓大模型可以區分KV Cache緩存中,有哪些數據是和這次推理相關度最高的,只要把關鍵的向量獲取出來,就可以降低推理時間,提高吞吐量。
就是在這種聯合創新技術試點中, UCM的技術價值得到了充分驗證。
在中國銀聯 “客户之聲”業務場景下,藉助UCM技術及工程化手段,大模型推理速度提升125倍,僅需10秒即可精準識別客户高頻問題。在“營銷策劃”場景中,過去需要數分鐘才能生成一份的營銷策劃案,現在縮短至10秒以內,且單台服務器可支持超過5名營銷人員同時在線協作。而在“辦公助手”場景中,對於超過17萬Token的超長會議語音進行轉寫和紀要生成,藉助UCM也能輕鬆應對,擺脱了“推不動”的困境。
那 UCM未來能否應用到其他場景,助推AI落地千行百業?華為技術專家給出肯定答覆。
“ 隨着 Agentic AI時代 到來 ,信息量爆炸,體現在模型側是顯存不足以及推理 Token成本的問題。 UCM方案 是去解決這一類的問題,不是一個單點,只是在金融行業首先應用起來,未來在各行各業一旦 AI發揮真正的價值 , 都會走向這個領域。 ”他對觀察者網説道。
填補生態短板,華為再度開源
隨着推理性能的重要性不斷提升,業界其實也都在探索 KV Cache分級緩存管理技術。比如英偉達今年5月就推出了分佈式推理服務框架Dynamo,支持將KV Cache緩存從GPU內存卸載到CPU、SSD甚至網絡存儲,解決大模型顯存瓶頸,避免重複計算。
但當下英偉達正陷入 “後門”風波,信任危機下,行業更呼喚中國方案。

“ 分級緩存管理很多人在做, UCM最大的差異化是將專業的存儲 納入進來。 ”華為技術專家對觀察者網表示,華為通過大量的軟硬協同和卸載,比如KV檢索的索引和KV Cache生命週期管理等,構建了在分級緩存管理上的差異化能力,“業界很多方案在算法加速庫這一層只有傳統的Prefix Cache,並沒有像今天這樣去商用全流程地稀疏、後綴檢索算法以及其他一系列的算法,所以中間的算法庫上面,我們相對業界貢獻了非常多、更加豐富、更加可靠、加速效果更好的算法,並且這個算法庫還在持續增加當中。”
關注大模型的可能都知道,華為之前開源了 AI框架MindSpore,近期又開源了對標英偉達CUDA的神經網絡異構計算架構CANN,而這次華為再度宣佈,將在9月開源UCM。
從架構上看,華為的 UCM解決方案主要有三大組件構成: 對接不同引擎與算力的推理引擎插件( Connector)、支持多級KV Cache管理及加速算法的功能庫(Accelerator) 和 高性能 KV Cache存取適配器(Adapter) ,實現了 推理框架、算力、存儲三層協同 。
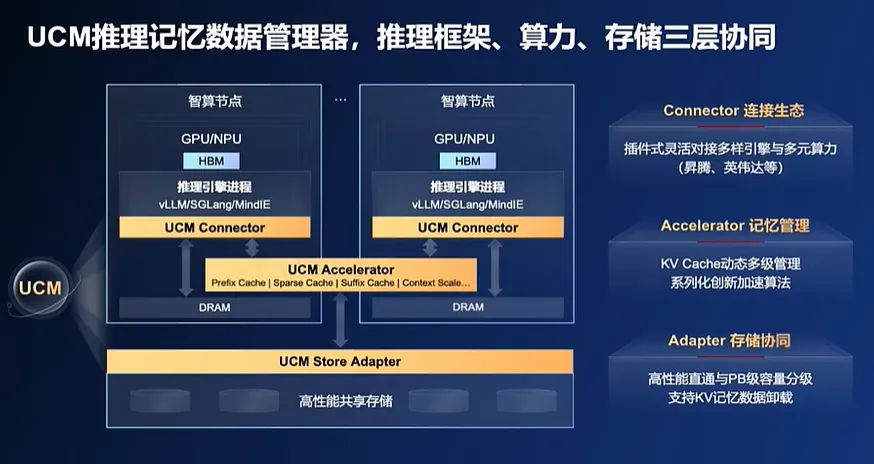
通過開放統一的南北向接口, UCM可適配多類型推理引擎框架、算力及存儲系統。對於推理引擎框架開發者而言,UCM開放的接口使得他們能更方便地將UCM技術集成到自己的框架中,提升框架性能和競爭力;對於算力及存儲系統廠商來説,UCM的開源提供了新的發展機遇,促使他們研發更適配的產品和解決方案,以更好地與UCM協同工作。
“ 我們並不希望控制這個框架,或者在框架上構建差異化的能力控制什麼,我們希望這個生態能夠繁榮起來,真正解決 AI推理化的問題,華為的UCM今天推出來以後 , 在整個推理框架、推理體驗生態、成本方面貢獻了一份力量,未來相信會有更多的玩家在裏面做貢獻,是一個大家共創繁榮的過程。 ”華為技術專家對觀察者網表示。
從更長遠的意義來看,華為推出 UCM並開源,仍是系統工程的勝利,將推動中國AI產業進入“體驗提升-用户增長-投資加大-技術迭代”的良性商業正循環。它並不是為了替代什麼,而是要打通AI行業化落地的關鍵堵點,為中國AI產業的長遠發展注入更強的動力。