美團首個大模型被爆成功跑通國產化訓練路徑,可在國產加速卡上進行
刘媛媛

9月1日,美團宣佈LongCat-Flash-Chat正式發佈,在Github、Hugging Face平台開源,並同步上線官網。
此前有自媒體“01Founder”爆料稱,LongCat-Flash最大的亮點是其訓練並非在英偉達GPU上完成,而是在國產加速卡上進行。美團已經成功跑通了一條不被“卡脖子”的技術路徑,但由於一些原因,真正的硬件廠商具體名字不方便透露。
對於該爆料,美團方面未作正面回應,只介紹稱,LongCat-Flash採用創新性混合專家模型(Mixture-of-Experts, MoE)架構,總參數560B,激活參數18.6B-31.3B(平均 27B),實現了計算效率與性能的雙重優化。
根據多項基準測試綜合評估,作為一款非思考型基礎模型,LongCat-Flash-Chat在僅激活少量參數的前提下,性能比肩當下領先的主流模型,尤其在智能體任務中具備突出優勢。
此外,因為面向推理效率的設計和創新,LongCat-Flash-Chat具有明顯更快的推理速度,更適合於耗時較長的複雜智能體應用。
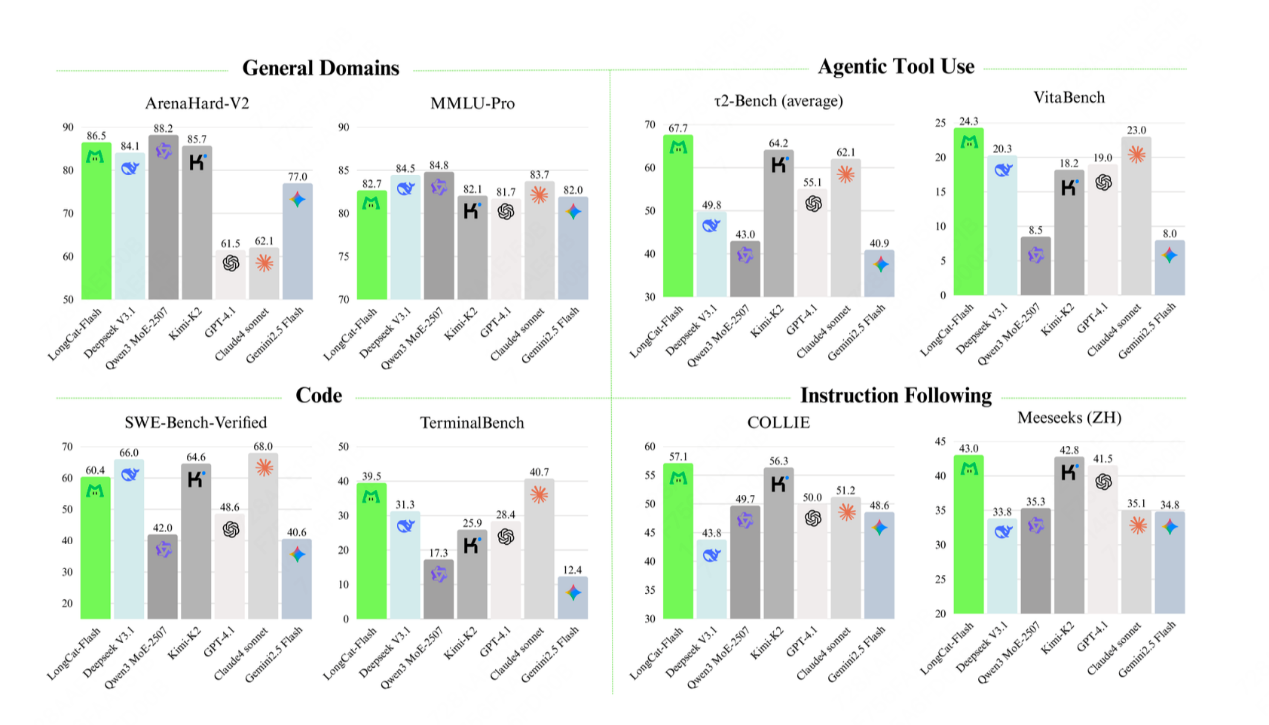
LongCat-Flash的基礎測試性能
至於美團為何要加入大模型之戰,或與公司AI戰略的三個層面有關,即AI at work、AI in products以及 Building LLM。
今年以來,美團AI進展頻傳,發佈了AI Coding Agent工具 NoCode 、AI經營決策助手袋鼠參謀、酒店經營的垂類AI Agent美團既白等多款AI應用。此次模型開源則是其 Building LLM 進展的首度曝光。
再具體點看,LongCat-Flash模型在架構層面引入“零計算專家(Zero-Computation Experts)”機制,總參數量 560B,每個token依據上下文需求僅激活18.6B-31.3B參數,實現算力按需分配和高效利用。為控制總算力消耗,訓練過程採用PID控制器即時微調專家偏置,將單token平均激活量穩定在約27B。
此外,LongCat-Flash在層間鋪設跨層通道,使MoE的通信和計算能很大程度上並行,提高了訓練和推理效率。配合定製化的底層優化,LongCat-Flash在30天內完成高效訓練,並在H800上實現單用户100+tokens/s的推理速度。LongCat-Flash還對常用大模型組件和訓練方式進行了改進,使用了超參遷移和模型層疊加的方式進行訓練,並結合了多項策略保證訓練穩定性,使得訓練全程高效且順利。
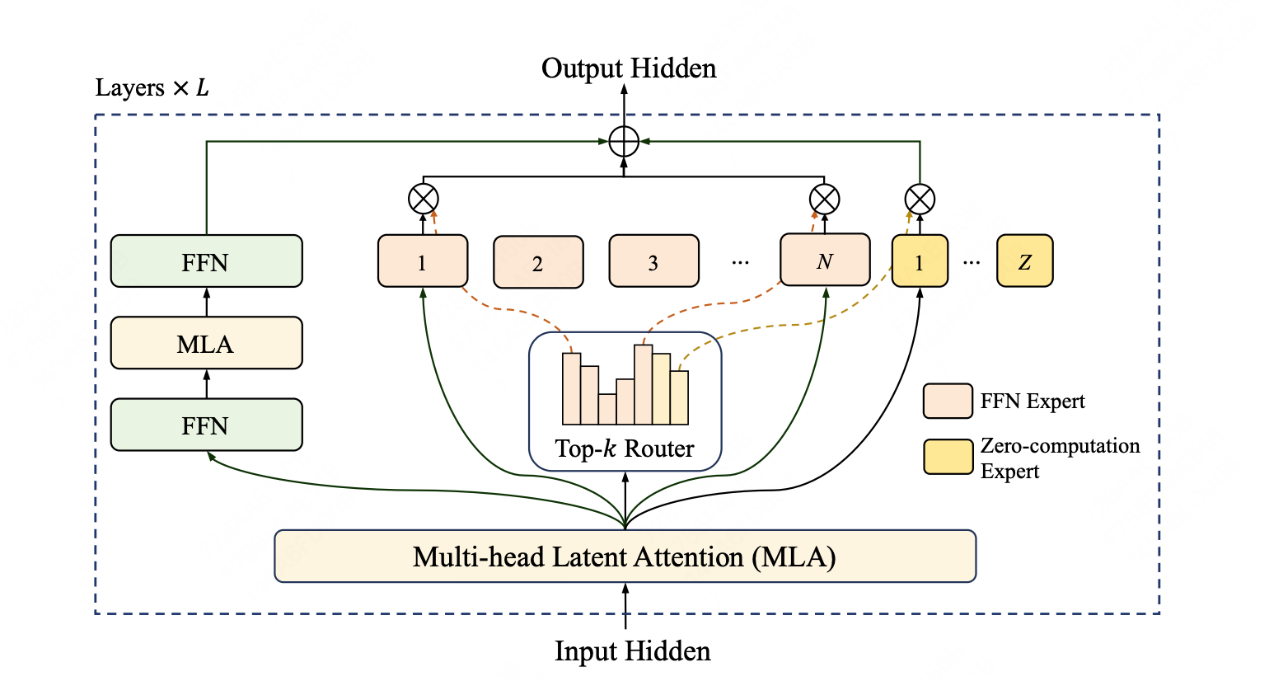
LongCat-Flash架構圖
針對智能體(Agentic)能力,LongCat-Flash自建了Agentic評測集指導數據策略,並在訓練全流程進行了全面的優化,包括使用多智能體方法生成多樣化高質量的軌跡數據等。
通過算法和工程層面的聯合設計,LongCat-Flash在理論上的成本和速度都大幅領先行業同等規模、甚至規模更小的模型;通過系統優化,LongCat-Flash在H800 上達成了100 token/s的生成速度,在保持極致生成速度的同時,輸出成本低至5元/百萬token。
本文系觀察者網獨家稿件,未經授權,不得轉載。