美團自研560B大模型並開源,性能趕超DeepSeek
guancha

文 觀察者網 呂棟
近日,美團正式推出了預熱已久的龍貓大模型LongCat-Flash-Chat,並在GitHub、Hugging Face等平台上同步開源。這家被大眾熟知的本地生活巨頭,第一次把5600億參數的混合專家模型(MoE)放在聚光燈下,讓業界看到了它在AI賽道的“進攻姿態”。
30天完成20萬億token訓練、單卡100+token/s的推理速度、每百萬token僅0.7美元的成本……龍貓大模型不僅多方面的性能與業界頂尖模型(如DeepSeek V3.1,Qwen3、GPT 4.1等)旗鼓相當,部分領域甚至還實現了超越,引發開源社區內外的大量關注。

架構創新,把計算資源用在 “刀刃”上
龍貓大模型之所以性能強悍,一個關鍵的原因在於它通過架構創新,實現了對計算資源的高效利用。也就是説,它一系列亮眼表現背後,是把計算資源分配在了最需要的位置。
比如,龍貓在MoE模塊中引入了“零計算專家機制”(Zero-Computation Experts),它可以動態分配計算資源,把類似“的、了”、“標點”等常見的詞彙和低信息token分配給“零計算專家”,該“專家”不用進行復雜運算,而是直接返回輸出,極大節省了算力。
在這種機制下,龍貓大模型雖有5600億參數,但處理每個任務時並不需要全部激活,而是僅需動態激活186億至313億參數(平均約270億),實現了成本與效率的高度平衡。
另外,MoE模型雖然能實現計算負載均衡,但複雜的混合並行策略,讓不同“專家”模塊之間的通信需求驟增,而通信延遲往往會形成“通信牆”,成為提升模型訓推性能的瓶頸。
龍貓大模型的解決辦法是,引入“快捷連接混合專家”(Shortcut-connected MoE,ScMoE)機制,這種機制可以有效擴大計算和通信的重疊窗口,讓不同“專家”模塊改變之前計算完再通信的串行模式,而是可以計算和通信並行,顯著提升了大模型訓推的吞吐量。
為了不僅能“聊天”,還能成為智能體解決複雜問題,龍貓大模型完成了面向智能體能力的多階段訓練。該流程包括基座模型訓練,增強推理與編碼能力的中期訓練,以及專注於對話和工具使用能力的後訓練,使其在執行調用工具、與環境交互的複雜任務時表現出色。
性能追平頂尖大模型,速度快的飛起
單卡100+token/s的推理速度、每百萬token僅0.7美元的成本、支持128k的長文本上下文……這些數據,直觀反映了龍貓大模型低成本、高性能的強悍實力。
簡單實測就會發現,龍貓大模型的推理速度要明顯快於DeepSeek、Kimi、Qwen3等市面上常見的主流模型,並且龍貓大模型還擁有強大的Agent能力,讓它寫個爬蟲腳本,不僅代碼寫得專業,還會提示技術和法律風險,推薦學習資源,分析數據也可以實現圖文並茂。
在開源社區中,龍貓大模型直接亮出了自己與同行的詳細性能對比,它在多個方面追平了行業翹楚(如DeepSeek V3.1、Qwen3、Kimi-K2、GPT 4.1等),某些方面還實現了超越。
比如在衡量模型綜合知識水平的核心指標(MMLU/MMLU-Pro)中,龍貓大模型的得分是89.71和82.68,與DeepSeek V3.1、Qwen3 MoE、Kimi-K2、GPT4.1和Claude4 Sonnet等行業頂尖大模型均不相上下,反映了龍貓紮實的基礎知識和推理能力。
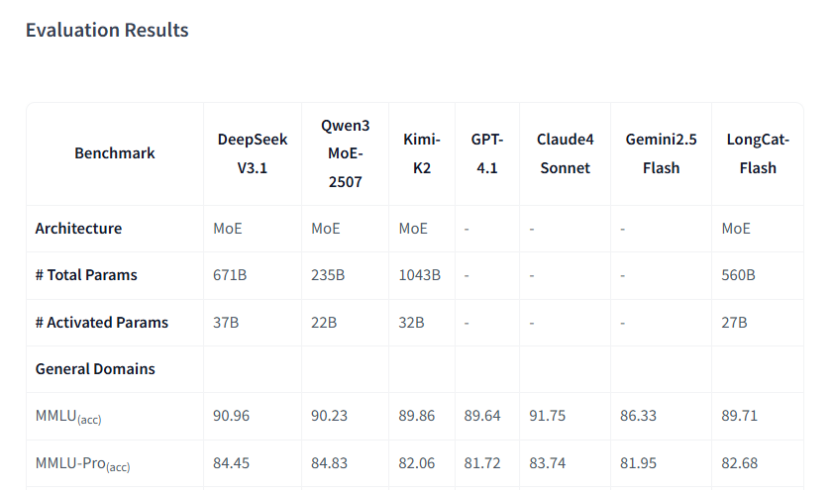
再比如在指令遵循(Instruction Following)的三個指標中,龍貓大模型得分均超越了DeepSeek V3.1、Qwen3 MoE、Kimi-K2和GPT4.1等模型,反映了多階段訓練的成果。
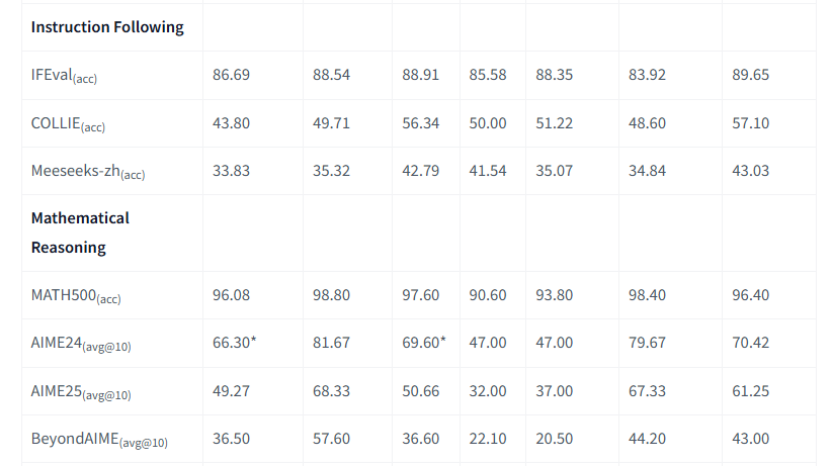
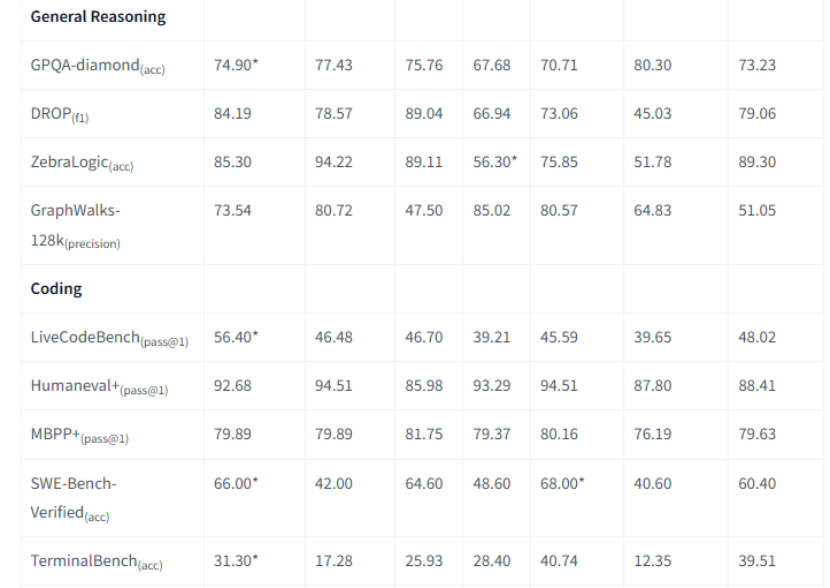
ArenaHard-V2更側重模型作為聊天助手的“體感”和處理複雜指令的能力,龍貓大模型的得分為86.50,超過DeepSeek V3.1,與 Qwen3 MoE的88.20非常接近。而作為中文領域的權威測試,龍貓在CEval上的得分為90.44,在CMMLU上也保持了第一梯隊水平。

首秀就有如此優秀的表現,讓外界不禁好奇龍貓大模型是在什麼硬件平台上訓練的?
美團技術報告披露的信息是,龍貓大模型是在數萬個加速器(tens of thousands of accelerators)上完成訓練的,但並未給出具體硬件廠商的名字。
需要指出的是,無論基於哪種硬件平台,在30天內就能完成20萬億token的訓練,足以説明美團技術團隊有能力在複雜的約束條件下,深入底層去解決核心的系統工程問題。
自研大模型,美團AI戰略落地的必然****
拋開技術層面,大家更關心的是,美團作為一家本地生活巨頭,為何要斥巨資研發大模型?
進軍大模型的思考,美團CEO王興其實在3月的年報業績會上做出過解答。他當時強調,AI將改變和顛覆所有行業,我們對此感到興奮。作為一家將線下業務與線上世界連接起來的公司,“我們將利用所擁有的一切去嘗試進攻,主動在AI方面實現我們的領先地位。”
當時王興把美團AI戰略解構為三個方面:首先是工作中的AI(AI at Work),用以提升內部員工的生產力;其次是產品中的AI(AI in Products),用AI升級現有服務,並推出全新AI原生產品;最後是這一切的基石,就是構建美團自己的大語言模型(Building LLM)。
龍貓大模型的誕生,可以説是美團AI戰略落地的必然。就業務本身來説,美團的本地生活涉及的物流、服務業都有着勞動力密集、高頻互動的特點,都屬於AI改造潛力很大的領域。對於美團來説,無論是戰略防禦還是更積極的態度,大模型都是必須要做的事情。
市場上雖然也有不少開源模型,但無論多麼強大,都無法媲美美團對垂直場景的理解和近乎100%的執行可靠性。因此唯一的路徑,就是訓練一個從誕生之初就浸泡在美團自身數據和業務邏輯中的模型,一個高可靠性的模型,這也是龍貓大模型被創造出來的核心原因。
目前,龍貓大模型LongCat-Flash-Chat,已經發布在Hugging Face和Githiub開源社區,並遵循MIT許可協議。這場本地生活巨頭對AI的深度擁抱,讓全球學術界和產業界的研究者、開發者也都可以自由使用和探索龍貓這個強大的模型,共同推動AI技術的發展。