心智觀察所:萬卡突圍!製程受限下,華為的絕地反擊
guancha
【文/觀察者網專欄作者 心智觀察所】
當徐直軍站在2025年華為全聯接大會的舞台上,宣佈Atlas 950超節點支持8192張昇騰卡、總算力達到8E FLOPS時,台下響起的掌聲或許意味着中國AI產業一個重要拐點的到來。這不僅僅是一次產品發佈,更像是華為在經歷DeepSeek衝擊後的一次戰略反擊——用技術創新回應質疑,用開放生態對抗封鎖。
在全球AI算力競賽日趨白熱化的當下,華為選擇了一條與眾不同的道路:不再單純追趕英偉達的單卡性能,而是通過革命性的“超節點”架構,試圖在萬卡級互聯技術上實現彎道超車。這背後折射的,是中美科技博弈進入新階段的深層邏輯——當先進製程工藝受限時,如何通過系統性創新突破算力瓶頸,成為決定未來AI話語權的關鍵變量。

技術突破的三重維度:從芯片到架構的全棧創新
華為此次發佈的昇騰950系列芯片,最引人注目的技術亮點在於對多種低精度數據格式的全面支持。相比前代產品,950系列不僅支持業界標準的FP8、MXFP8、MXFP4格式,更重要的是推出了自研的HiF8格式——在保持FP8高效性的同時,精度無限接近FP16。
這一技術路線的選擇並非偶然。在先進製程工藝受限的背景下,通過降低數值精度來提升算力密度,成為華為繞過製程限制的重要策略。HiF8格式的推出,實際上是華為在算法優化與硬件設計之間找到的一個巧妙平衡點:既能顯著提升推理吞吐,又能保證模型精度不受明顯影響。
更值得關注的是,華為首次在昇騰芯片中引入了SIMD/SIMT新同構設計。這種創新架構允許同一個計算單元既能像流水線一樣處理“大塊”向量數據,又能靈活處理“碎片化”數據。這種設計哲學的轉變,反映了華為對AI計算模式演進趨勢的深刻理解——隨着模型複雜度不斷提升,對靈活性和效率的要求將同等重要。
**在內存技術方面,華為同樣展現出了令人印象深刻的系統性思維。**針對不同應用場景的特殊需求,華為自研了兩種HBM技術:面向推理Prefill階段的低成本HiBL 1.0,以及面向訓練和Decode階段的高性能HiZQ 2.0。
這種“一芯兩用”的設計理念,實際上是對傳統“一刀切”芯片設計模式的顛覆。通過將同一個die與不同規格的自研HBM合封,華為實現了在成本和性能之間的精確平衡。這不僅能夠降低客户的整體擁有成本,更重要的是體現了華為在供應鏈自主可控方面的戰略考量。
如果説前兩個層面的創新更多體現在硬件優化上,那麼“靈衢”(UnifiedBus)協議的推出,則代表了華為在系統架構層面的根本性突破。
傳統的GPU集羣方案面臨着兩個根本性挑戰:長距離高可靠互聯,以及大帶寬低時延傳輸。華為通過在互聯協議的每一層都引入高可靠機制,在光路引入百納秒級故障檢測,重新定義光器件和互聯芯片,實現了光互聯可靠性提升100倍,互聯距離超過200米。
更令人驚歎的是,華為聲稱Atlas 950超節點的互聯帶寬達到16PB/s——這個數字超過了當前全球互聯網峯值帶寬的10倍。這意味着華為不僅在技術指標上實現了突破,更在工程實現上達到了前所未有的複雜度。
戰略選擇的深層邏輯:為什麼是超節點?
華為選擇超節點技術路線,根本原因在於對自身技術約束的清醒認識。
徐直軍在發言中明確提到:“中國半導體制造工藝將在相當長時間處於落後狀態。”在這種約束下,單純追求單芯片性能的提升空間有限,而通過系統級創新實現整體算力突破,成為更為現實的選擇。
超節點架構的核心價值在於,它能夠將數千乃至上萬顆芯片整合為一個邏輯上的“超級計算機”。這種架構創新不僅能夠充分發揮每顆芯片的計算潛力,更重要的是通過優化的互聯協議,最大程度地降低了通信開銷和延遲。
隨着大模型參數規模不斷攀升,從千億級向萬億級發展,傳統的單卡或小規模集羣方案越來越難以滿足訓練需求。華為推出的Atlas 950超節點支持8192卡,Atlas 960超節點支持15488卡,直接瞄準了未來大模型訓練的核心需求。
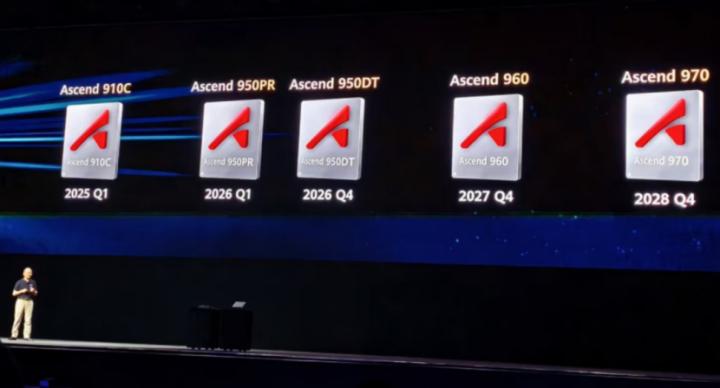
特別是在推理場景中,隨着Agent技術的快速發展,輸入上下文長度呈指數級增長,Prefill階段的計算需求急劇上升。華為針對這一趨勢,專門設計了Ascend 950PR芯片,配合低成本HiBL 1.0內存,實現了成本和性能的最優平衡。
華為宣佈開放靈衢2.0技術規範,這一決策背後藴含着深刻的生態建設考量。在英偉達CUDA生態佔據絕對主導地位的情況下,華為選擇開放核心技術,實際上是在構建一個以自己為中心的新生態圈。
這種開放策略的風險和收益並存。一方面,開放技術規範能夠吸引更多合作伙伴參與,加速技術迭代和應用落地;另一方面,也存在核心技術外流的風險。但在當前的市場環境下,封閉的生態很難與英偉達正面競爭,開放或許是華為的最優選擇。
技術挑戰:單芯片性能差距與工程複雜性
首先必須正視的是,在單芯片層面,華為昇騰芯片與英偉達產品仍存在顯著差距。受制於先進製程工藝的獲取限制,華為昇騰910C芯片採用的7nm工藝,相比英偉達H100/H200的4nm工藝存在明顯代差。這種製程差距直接導致在相同功耗下,單芯片算力密度、能效比等關鍵指標的劣勢。
根據公開數據,英偉達H100的FP16算力約為1000 TFLOPS,而華為昇騰910C約為640 TFLOPS,差距達到40%以上。在更關鍵的AI訓練場景中,這種性能差距可能進一步放大。華為試圖通過多芯片互聯的系統性優勢來彌補單芯片性能不足,但這種策略的有效性仍需市場驗證。
萬卡級超節點的技術實現難度更是遠超想象。
以Atlas 950超節點為例,8192張卡意味着需要處理海量的卡間通信,任何一個環節的故障都可能導致整個系統的崩潰。華為力圖通過靈衢協議實現了“萬卡超節點,一台計算機”,但這一技術承諾的實際驗證,需要在真實的大規模部署中才能得到答案。
特別是在軟件適配方面,如何讓現有的AI框架和應用程序能夠充分發揮萬卡超節點的性能優勢,需要大量的優化工作。這不僅需要華為自身的技術投入,更需要整個軟件生態的配合。
除此之外,客户認知與接受度也是個問題。雖然華為在技術指標上聲稱全面超越英偉達產品,但市場接受度的建立需要時間。目前AI行業的主流開發框架和工具鏈都是圍繞英偉達GPU優化的,遷移到昇騰平台需要額外的開發成本和學習成本。
更重要的是,大型AI公司在選擇算力平台時,不僅考慮性能指標,還要考慮供應鏈穩定性、技術支持質量、生態完整性等多個因素。華為需要在這些軟實力方面證明自己。
雖然華為在芯片設計、系統架構等方面實現了突破,但在光器件、高端封裝、精密製造等環節,仍然面臨供應鏈約束。特別是在先進製程芯片製造方面,華為仍然依賴於有限的代工廠資源。
這種依賴性不僅影響產能釋放,更可能在地緣政治風險升級時,成為華為AI戰略的致命弱點。
地緣政治博弈中的互聯技術爭奪戰
值得關注的是,華為在互聯技術上的突破,與英偉達2020年收購Mellanox的戰略佈局形成了有趣的對比和競爭。英偉達以70億美元收購這家以色列高速互聯技術公司,正是看中了其在InfiniBand和以太網互聯技術方面的領先地位。這筆交易使英偉達在數據中心互聯領域獲得了關鍵技術優勢,為其GPU集羣方案提供了完整的技術閉環。
然而,這筆收購在中國遭遇了長時間的反壟斷審查,最終在附加條件下才獲得批准。中國監管部門的擔憂並非沒有道理——控制了高端互聯技術的英偉達,幾乎可以主導整個AI基礎設施的技術標準和供應鏈。這種擔憂在今天看來更具前瞻性:當英偉達通過CUDA生態和Mellanox互聯技術構建起完整的技術壁壘時,其他廠商想要突破變得極其困難。
從這個角度看,華為推出靈衢協議並選擇開源開放,實際上是在重新定義互聯技術的遊戲規則。華為的策略是:既然無法在英偉達構建的技術體系內競爭,那就創建一個全新的技術標準和生態系統。靈衢協議不僅是技術突破,更是對“英偉達-Mellanox”技術聯盟的直接挑戰。
近期,阿里、字節跳動等科技巨頭停止購買英偉達RTX Pro 6000D等高端GPU,這一政策信號具有重要的象徵意義。它不僅體現了監管層對關鍵技術自主可控的重視,更為華為等本土廠商創造了市場機遇窗口。
這種政策導向的變化,實際上是中美科技博弈進入新階段的重要標誌。過去更多是美國對中國的技術封鎖,現在中國也開始主動採取措施,減少對美國關鍵技術的依賴。
面對華為的趕超,英偉達應時而動,也在調整自己的戰略佈局。就在華為華為全聯接大會召開之時,業界傳出了英偉達入股英特爾的消息,反映了技術巨頭們在不確定環境下尋求新合作模式的趨勢。
對英偉達而言,中國市場的重要性不言而喻。面對華為等競爭對手的強力衝擊,英偉達需要在技術領先性和地緣政治風險之間找到新的平衡點。
前景展望:技術創新與市場競爭的雙重考驗
華為的超節點戰略,代表了中國AI產業在面臨外部壓力時的一次重要技術轉向。從單純的追趕模式,轉向差異化創新模式,這種戰略調整本身就具有重要意義。
短期內,華為需要證明其萬卡級超節點的技術可行性和商業價值。Atlas 950超節點計劃於2026年四季度上市,這將是檢驗華為技術承諾的關鍵時點。如果華為能夠如期交付並達到承諾的性能指標,將極大地提振中國AI產業的信心。長期來看,超節點技術路線是否能夠真正撼動英偉達的市場地位,還取決於多個因素的綜合作用:技術迭代速度、生態建設進度、政策環境變化,以及客户接受度等。
但無論如何,華為這次的技術突破已經表明,在AI算力這個關鍵賽道上,中美之間的技術差距正在縮小。這不僅是中國科技實力提升的重要體現,更可能預示着全球AI產業格局的深刻變革。
在這場沒有硝煙的算力戰爭中,華為已經打響了反擊的第一槍。接下來的較量,將決定未來AI時代的話語權歸屬。

本文系觀察者網獨家稿件,文章內容純屬作者個人觀點,不代表平台觀點,未經授權,不得轉載,否則將追究法律責任。關注觀察者網微信guanchacn,每日閲讀趣味文章。