DeepSeek-V3.2-Exp官宣發佈,性能更強,API價格腰斬
陈济深

9月29日,DeepSeek-V3.2-Exp模型正式在Hugging Face平台發佈並開源。
DeepSeek在官方微信號介紹表示,該版本作為邁向下一代架構的重要中間步驟,在 V3.1-Terminus 的基礎上引入了團隊自研的 DeepSeek Sparse Attention (DSA) 稀疏注意力機制,旨在對長文本的訓練和推理效率進行探索性優化與驗證。這種架構能夠降低計算資源消耗並提升模型推理效率。
目前,華為雲已完成對 DeepSeek-V3.2-Exp模型的適配工作,最大可支持160K長序列上下文長度。
最新核心技術突破:DeepSeek Sparse Attention(DSA)
DeepSeek Sparse Attention(DSA)首次實現了細粒度稀疏注意力機制,在幾乎不影響模型輸出效果的前提下,實現了長文本訓練和推理效率的大幅提升。
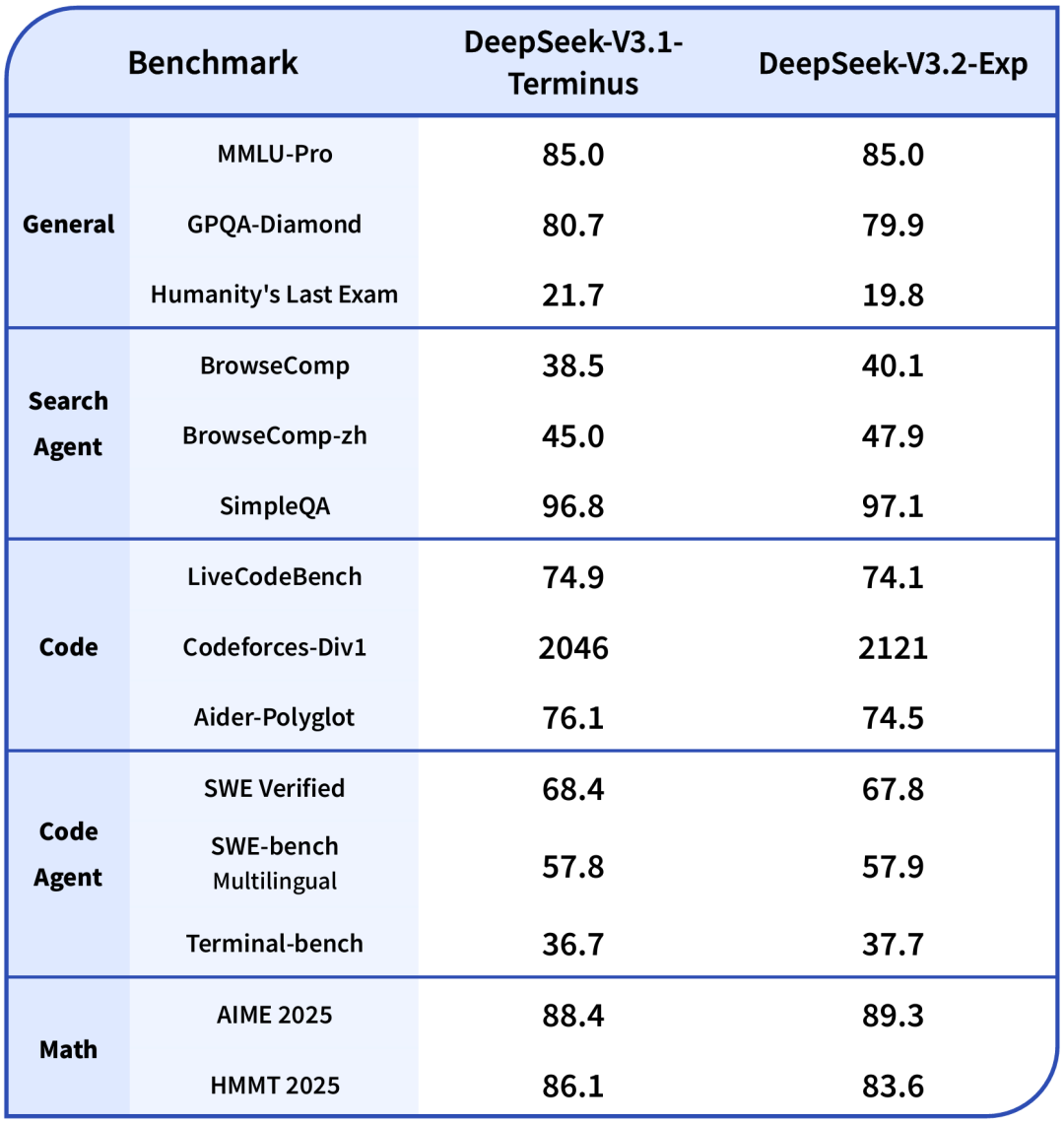
為了嚴謹地評估引入稀疏注意力帶來的影響,DeepSeek-V3.2-Exp的訓練設置與V3.1-Terminus進行了嚴格的對齊。在各領域的公開評測集上,DeepSeek-V3.2-Exp的表現與V3.1-Terminus基本持平。有效性得到了初步驗證。
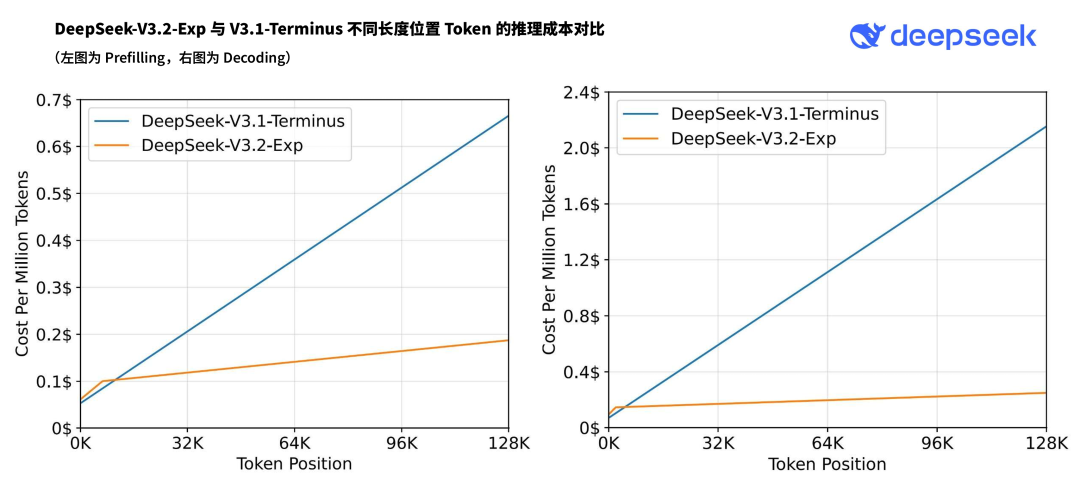
API成本將腰斬
隨着新模型服務成本的顯著降低,DeepSeek 同步採取了重磅舉措:大幅下調官方 API 價格,降價幅度超過 50%,新價格已即刻生效。目前,官方 App、網頁端和小程序均已同步更新至 DeepSeek-V3.2-Exp 版本。

DeepSeek 現已將 DeepSeek-V3.2-Exp 模型在 Huggingface 和 ModelScope 平台上全面開源,相關論文也已同步公開。
作為一款實驗性版本,DeepSeek 認識到模型仍需在更廣泛的用户真實場景中進行大規模測試。為便於開發者進行效果對比,DeepSeek 為 V3.1-Terminus 版本臨時保留了 API 訪問接口,且調用價格與 V3.2-Exp 保持一致。該對比接口將保留至北京時間 2025 年 10 月 15 日 23:59。
此外,為支持社區研究,DeepSeek 還開源了新模型研究中設計和實現的 GPU 算子,包括 TileLang 和 CUDA 兩種版本。團隊建議社區在進行研究性實驗時,優先使用基於 TileLang 的版本,以便於調試和快速迭代。
本文系觀察者網獨家稿件,未經授權,不得轉載。