“大就是好”,但技術男阿里雲並不執著“上頭條”
张广凯13764468101

(文/觀察者網 張廣凱 編輯/呂棟)
9月24日的雲棲大會主論壇上,阿里巴巴集團CEO、阿里雲智能集團董事長兼CEO吳泳銘進行了25分鐘的PPT演講。
對於一貫低調的阿里“第一個程序員”而言,這並不尋常。要知道,去年的雲棲大會,吳泳銘還只是以讀稿的形式發言,甚至略顯緊張。
比現場觀眾反應更熱烈的,是資本市場。幾乎就在吳泳銘演講結束的同時,港股阿里巴巴股價快速拉昇,當日大漲9.16%。
即使在中國科技資產重估的大背景下,像阿里這樣信息高度透明的大塊頭突然出現如此漲幅,仍然是不尋常的。投資者看到了什麼?

吳泳銘的演講中的確透露了一些增量信息和樂觀判斷,比如:
大模型作為下一代的操作系統,將會吞噬軟件;
未來全世界可能只會有5-6個超級雲計算平台;
阿里雲在三年3800億的AI基礎設施建設計劃之外將追加投入;
2032年阿里雲全球數據中心的能耗規模將提升10倍。
但即使是縱觀整個雲棲大會,真正超預期的信息也並不多,恐怕不足以解釋市場的強烈反應。無論是大模型的研發迭代,還是AI雲“一哥”的競爭,乃至芯片和算力佈局,阿里雲都不追求“憋大招”,而是在確定性最強的方向上試圖穩紮穩打。
事實上,當日的市場反應更像是此前相當長一段時間內積累的情緒釋放,阿里雲的小步快跑,讓一種模糊的印象正逐漸得到加強——或許阿里並不總是佔據AI行業的“頭條”,但是其大而全的深厚技術積累會長期讓自己立於不敗之地。
就像吳泳銘本人一樣,阿里作為“技術男”的形象愈發深入人心。而對體量足夠大的阿里來説,剋制有時候也是一種優勢。
“大就是好”
從年初開始,阿里雲作為“AI界汪峯”的名號不脛而走。
起因是大年初一,阿里雲發佈通義千問旗艦版模型Qwen2.5-Max,其綜合能力超過DeepSeek V3,成為最強的國產非推理模型。
選在這個時間點發布,阿里雲顯然是瞄準了春節期間的C端流量。
但是結果大家都知道了,就在幾天前,DeepSeek發佈了推理模型R1,成為整個春節期間絕對意義上的主角。
此後,儘管DeepSeek迭代速度不盡人意,Qwen則持續刷榜,可是在公眾的認知中,Qwen始終難以同DeepSeek抗衡。
而阿里雲似乎也逐步放下了“搶頭條”的執念。
在本次雲棲大會上,阿里雲CTO周靖人一口氣宣佈了7款大模型的升級。不過,相比於春節那次發佈,此次的7連發少了幾分刻意。
以最新的旗艦模型Qwen3-Max為例,其實早在本月初,其Preview版就已經在深夜低調上線,宣告通義進入萬億參數時代。
在LMArena上,Qwen3-Max Preview的評分已經出爐,排在文本處理能力的第三位,能力介於ChatGPT-5-chat和ChatGPT-5-high之間,是前十名中唯一的中國大模型。
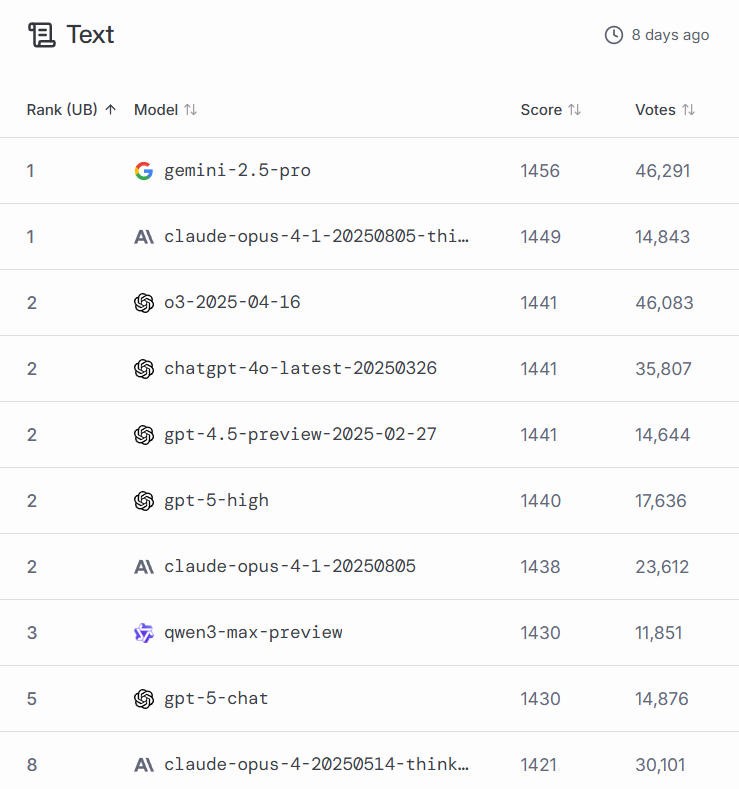
(注:LMArena採用了經過複雜調整的排名方式,旨在去除一些統計偏差,其排名反映的是模型能力等級,而非完全取決於其身前模型的數量)
周靖人指出,Qwen3-Max的正式版本比Preview又有了明顯提升,其Instruct版本在代碼能力和Agent工具調用能力上都達到一梯隊水平,Thinking版本則在數學能力測試中取得國內最佳成績。
在介紹Qwen3-Max時,通義官方使用了一個詞:“大就是好”。
換句話説,Qwen3-Max能力提升的核心仍然是Scaling Law。除了萬億參數量之外,其預訓練數據量也從18T提升到36T。
通義官方認為,當前有部分學者認為預訓練的Scaling Law即將逼近上限,而Qwen3-Max的性能突破顯示,繼續增大數據、模型參數,依然能鍛造出更強的模型,給予了大家更多的信心。
除了參數量和數據量的提升外,Qwen3-Max也在緊跟算法創新的最新方向。
通義實驗室算法專家介紹,此前Qwen3發佈後,團隊總結了模型仍然存在的缺點,即混合思考性能有損、強化學習不穩定、上下文128k不夠。
為此,Qwen3-Max拆分出了Instruct和Thinking兩個版本,分別注重快慢思考;在強化學習算法上引入了自研的GSPO,取代了DeepSeek採用的GRPO,並將上下文擴展到1M。
通義還發布了下一代基礎模型架構Qwen3-Next,主打超稀疏的MoE架構,模型總參數80B,僅激活3B即可媲美當下Qwen3旗艦版235B的效果。
觀察者網瞭解到,這主要得益於線性注意力和自研的門控注意力相結合的混合架構、多 token 預測(MTP)機制等,並將激活專家佔比從1:16進一步減少為1:50,使得訓練和推理效率都大大提升。
其實,這些技術層面的創新仍然可以用“大就是好”來概括——雖然並非顛覆性創新,卻試圖比對手走得更遠一步。
而最核心的指導思想,也被歸納為Scaling is all you need——大模型的方向,依然是更大。

類似地,通義此次發佈了多款多模態模型的升級,以及全模態融合的Qwen3-Omni。阿里雲通義大模型業務總經理徐棟對觀察者網介紹,通義團隊相信模型架構走向統一一定是未來的趨勢,包括多模態的統一和快慢思考的統一。
但從行業來看,架構統一仍然處於早期階段,包括通義和階躍星辰等多模態玩家,眼下追求的也不是拿出一個超級模型,而是儘可能多地在各個模態上廣泛佈局。這未嘗不是另一種“大就是好”。
或許公眾層面會對一次顛覆性的創新更加印象深刻,但周靖人對觀察者網直言,“模型的發展是一個循序漸進的過程,而不是‘憋大招’的邏輯,海內外所有廠商都是漸進式發展起來的,重要的是加快模型迭代和創新的速度。”
阿里雲方面也強調,自2023年開源第一款模型以來,通義大模型在全球下載量突破6億次,衍生模型突破17萬個,已發展成為全球第一開源模型。
激戰與剋制
阿里雲的“大”,當然不僅僅是模型的大,更在於其中國最大雲服務商的底色。
有意思的是,圍繞AI雲的規模,國內同行間最近正展開另一場激烈的“搶頭條”暗戰。
其中最引人注目的無疑是字節旗下的火山引擎。
就在雲棲大會期間,很多人發現,阿里“大本營”杭州的機場航站樓廣告,卻被火山引擎佔領了。

甚至,火山引擎的開屏廣告,還出現在了本該是競爭對手的百度地圖APP上。
在這些廣告上,火山引擎試圖打造自己“大模型第一雲”的心智。
就在兩三年前,火山引擎還只是服務字節內部生態為主的攪局者,但是國際數據公司IDC本月發佈的一份報告卻顯示,2025年上半年,中國公有云上大模型調用量達536.7萬億tokens,火山引擎以49.2%的市場份額位居中國市場第一,而阿里雲以27%屈居第二。這裏面還沒有包括豆包等字節自家大模型產品的調用數據。
當然,這個數據僅僅顯示了MaaS市場的部分面貌。由於Qwen家族模型以開源為主,大量客户並非以MaaS形式去調用API,而是自己在阿里雲上部署模型,這部分數據並沒有被統計進去。
Omdia幾乎同時發佈的一份報告,則包含了IaaS、PaaS與MaaS等整體口徑,顯示2025年上半年中國AI雲市場中阿里巴巴佔比達到35.8%,市場份額相當於二到四名之和。
沙利文近日發佈的報告則指出,在已採用生成式AI的財富中國500強中,超53%企業選擇阿里雲,顯示出阿里雲在大客户端的傳統優勢。
密集發佈的各種不同口徑報告,折射出雲廠商之間的激烈暗鬥。不過在另一面,直接的價格戰似乎正在降温。
低價是火山引擎最強大的武器。儘管火山引擎總裁譚待否認“虧錢換市場”,但他也僅僅指出火山的毛利為正。
今年6月,豆包1.6又首創按“輸入長度”區間定價,使綜合使用成本降至豆包1.5深度思考模型的三分之一。
但是今年以來,包括DeepSeek在內的多家大模型調用價格開始不降反漲,阿里雲的最近一次全面降價也停留在2024年的最後一天。
接近阿里雲的人士向觀察者網透露,阿里雲不會再以虧錢的代價做大營收,新的領導層對此想得非常清楚。
其進一步指出,在過去多年中,阿里雲經歷了華為雲、運營商雲等多個挑戰者,仍能保持市場領先地位,如今的心態也更加自信。
在本次大會上,我們還可以看到更多阿里雲剋制的信號。
例如,在時下話題度頗高的超節點技術上,儘管阿里雲也發佈了類似產品,但並未突出宣傳。一位阿里雲技術專家指出,超節點的優勢場景僅僅在於分佈式推理,但是在訓練環節並無顯著提升,且隨着超帶寬域增加會帶來殘酷的可靠性難題。
很多參會者都向觀察者網提到,相比於其它廠商的類似活動,雲棲大會有着更濃厚的技術和務實風格。
阿里雲更顯著的務實風格當然還是體現在C端市場。當字節豆包、騰訊元寶紛紛依託自身社交生態大力推廣自家聊天應用時,通義APP則始終不願意花錢買用户。在國內C端付費極不發達的生態下,這樣的選擇自有合理性。
但是與傳統的雲服務市場不同,AI大模型勢必將是深度進入C端市場的變革,並且DeepSeek和豆包都證明,其C端表現也會間接影響B端心智。阿里雲的剋制是否明智,仍然有待時間檢驗。
硬件的變數
事實上,儘管沒有高調宣傳,阿里雲在AI Infra層面的進展正在加速。
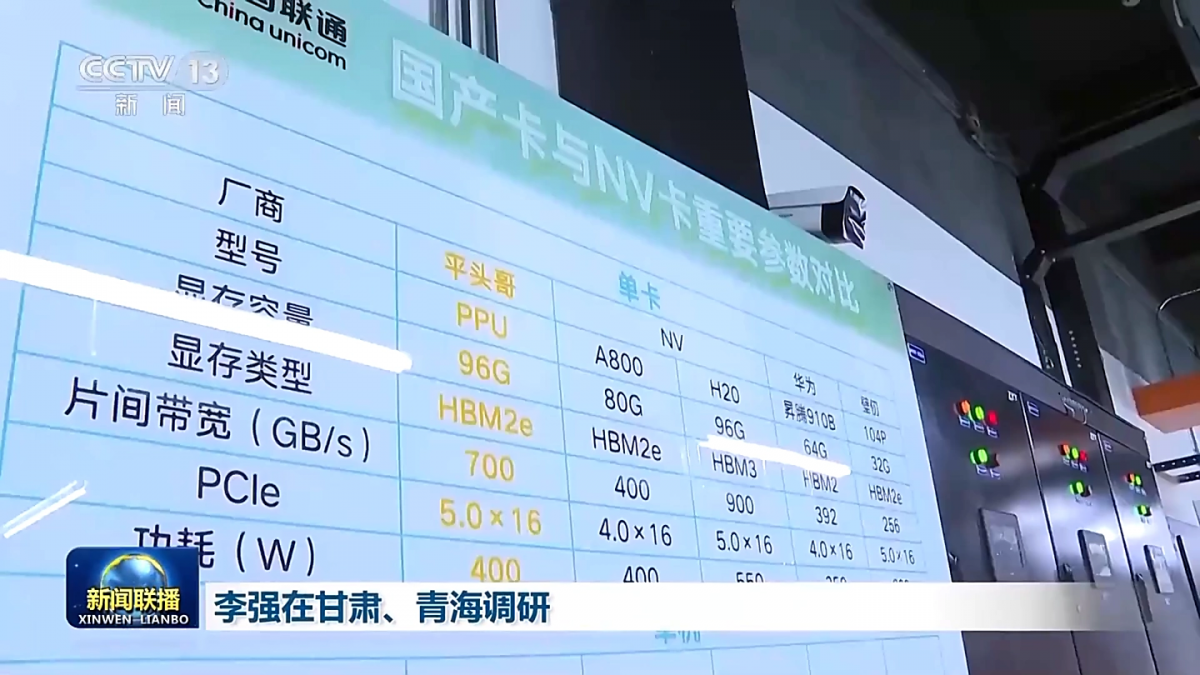
本月初有媒體消息稱,阿里已經開發了一款新的AI芯片,適用於大模型推理場景,能夠接近英偉達H20的水平,由國內晶圓廠代工,並且還兼容英偉達生態。
此後,央視《新聞聯播》公開報道了中國聯通三江源綠電智算中心項目建設成效,其中阿里平頭哥拿下最大訂單,以16384 張算力卡提供 1945P算力,大致與上述消息相符。
在網絡層面,阿里雲也在雲棲大會上發佈了新一代高性能網絡HPN 8.0採用訓推一體化架構,存儲網絡帶寬拉昇至800Gbps,GPU互聯網絡帶寬達到6.4Tbps,可支持單集羣10萬卡GPU高效互聯,為萬卡大集羣提供高性能、確定性的雲上基礎網絡。
再加上128超節點等技術,阿里雲在AI Infra上的全棧佈局已經基本成型。在英偉達入華阻力越來越大的當下,阿里雲有望在國產替代大潮中分得遠超此前預期的份額。
但是,隨着越來越多的雲服務商開始自研芯片,它們與第三方供應商的關係或許也變得微妙起來。
近日有消息稱,在芯片領域基礎相對薄弱的字節,也已經與台積電合作研發兩款AI芯片,有望於2026年量產。
目前,阿里雲和字節都採購了大量華為昇騰芯片。但是華為雲近期也實施了“史上最大規模組織優化”,大幅收縮傳統雲服務業務,將重心進一步轉向AI算力。
如此一來,阿里雲和火山引擎作為客户廠商,是否會在同華為雲的競爭中處於先天劣勢?其自研芯片能否快速支撐起算力端需求?
甚至,其它第三方算力芯片供應商,是否也會在大廠激烈的競爭中走向陣營綁定?不同陣營的技術路線和商業風險又會怎樣影響行業格局?
國產芯片的集團化崛起,固然是國家之幸,但身處局中者,也難免面臨巨大變數。