智譜發佈GLM-4.6,聯手寒武紀,摩爾線程推出模型芯片一體解決方案
陈济深

9月30日,國產大模型“六小龍”之一的智譜發佈GLM-4.6新模型。
作為GLM系列最新版本,GLM-4.6在真實編程、長上下文處理、推理能力、信息搜索、寫作能力與智能體應用等多個方面能力有所提升。
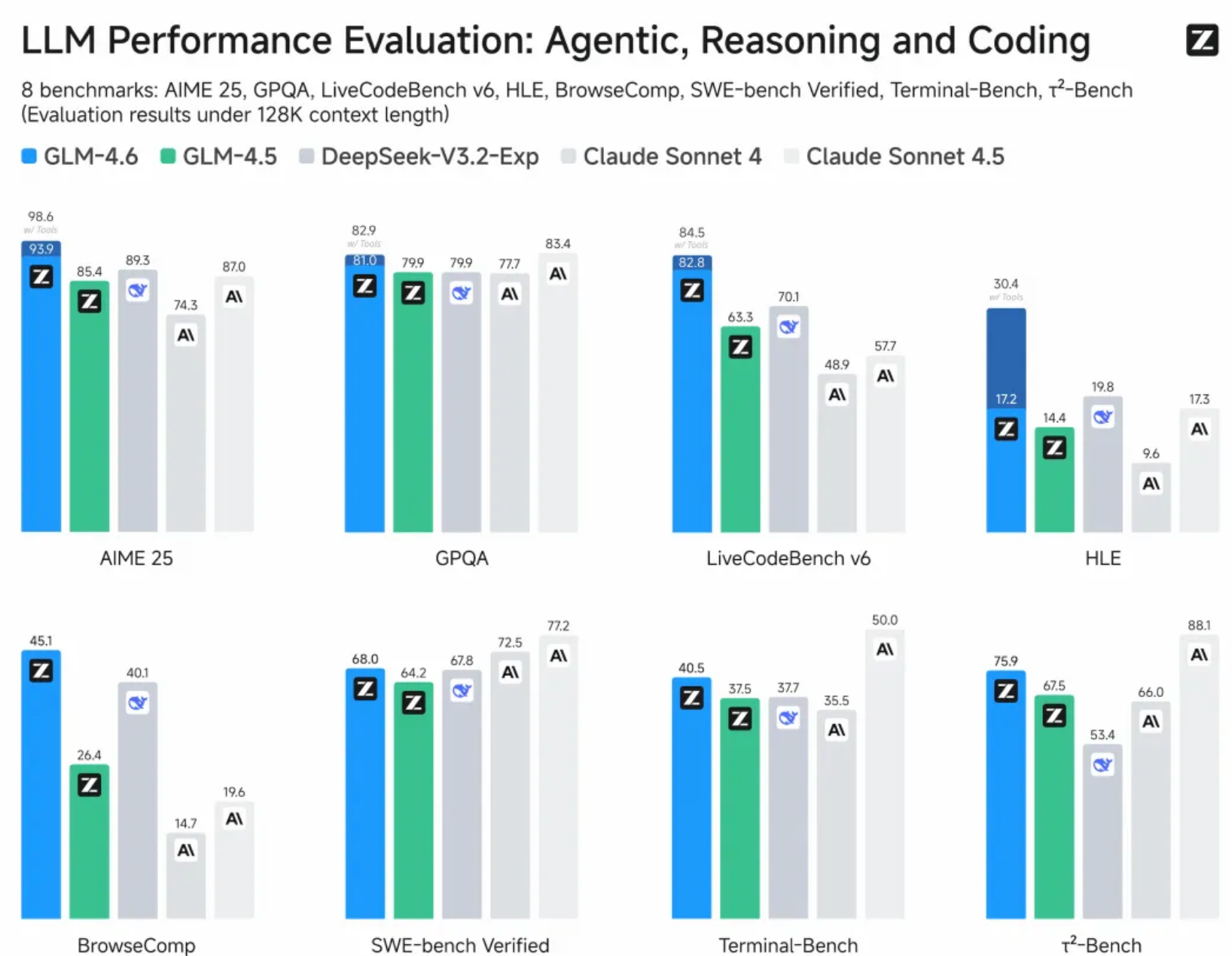
官方信息顯示,此次升級表現在公開基準與真實編程任務中,GLM-4.6代碼能力對齊Claude Sonnet 4;上下文窗口由128K提升至200K,適應更長的代碼和智能體任務;新模型提升推理能力,並支持在推理過程中調用工具;搜索方面增強模型的工具調用和搜索智能體。
另外,“模芯聯動”是此次新模型發佈的重點,GLM-4.6已在寒武紀國產芯片上實現FP8+Int4混合量化部署,這也是行業首次在國產芯片上投產的FP8+Int4模型芯片一體解決方案,在保持精度不變的前提下,降低推理成本,為國產芯片在大模型本地化運行上探索可行路徑。
FP8是8位浮點數(Floating-Point 8)數據類型,動態範圍廣、精度損失小;Int4是4 位整數(Integer 4)數據類型,壓縮比極高,內存佔用最少,適配低算力硬件但精度損失相對明顯。此次嘗試的“FP8+Int4 混合” 模式,並非簡單將兩種格式疊加,而是根據大模型的“模塊功能差異”,針對性分配量化格式,讓該省內存的地方用Int4壓到極致,該保精度的地方用FP8守住底線,實現合理資源分配。
具體到模型適配過程中,佔總內存的60%-80%的大模型核心參數通過Int4量化後,可將權重體積直接壓縮為FP16的1/4,大幅降低芯片顯存的佔用壓力;推理環節積累的臨時對話數據可以通過Int4壓縮內存的同時,將精度損失控制在 “輕微”範圍。而FP8可重點針對模型中“數值敏感、影響推理準確性”的模塊,降低精度損失、保留精細語義信息。
除了寒武紀,摩爾線程已基於vLLM推理框架完成對GLM-4.6 的適配,新一代GPU可在原生FP8精度下穩定運行模型,驗證MUSA架構及全功能GPU在生態兼容性和快速適配能力方面的優勢。
寒武紀與摩爾線程此番完成對GLM-4.6的適配,標誌着國產GPU已具備與前沿大模型協同迭代的能力,加速構建自主可控的 AI 技術生態。接下來,GLM-4.6搭配國產芯片的組合將率先通過智譜MaaS平台面向企業與公眾提供服務。
本文系觀察者網獨家稿件,未經授權,不得轉載。