DeepSeek開源新模型,用視覺方式壓縮一切
陈济深

(文/陳濟深 編輯/張廣凱)
10月20日,DeepSeek再度開源新模型。
在GitHub(https://github.com/deepseek-ai/DeepSeek-OCR)上可以看到其最新模型名為DeepSeek-OCR,還是一款OCR(光學字符識別)模型,該模型的參數量為3B。
該項目由 DeepSeek 三位研究員 Haoran Wei、Yaofeng Sun、Yukun Li 共同完成。其中一作 Haoran Wei 曾在階躍星辰工作過,曾主導開發了旨在實現「第二代 OCR」的 GOT-OCR2.0 系統(arXiv:2409.01704),該項目已在 GitHub 收穫了超 7800 star。也因此,由其主導 DeepSeek 的 OCR 項目也在情理之中。

DeepSeek 表示,DeepSeek-OCR 模型是通過光學二維映射(將文本內容壓縮到視覺像素中)來高效壓縮長文本上下文。
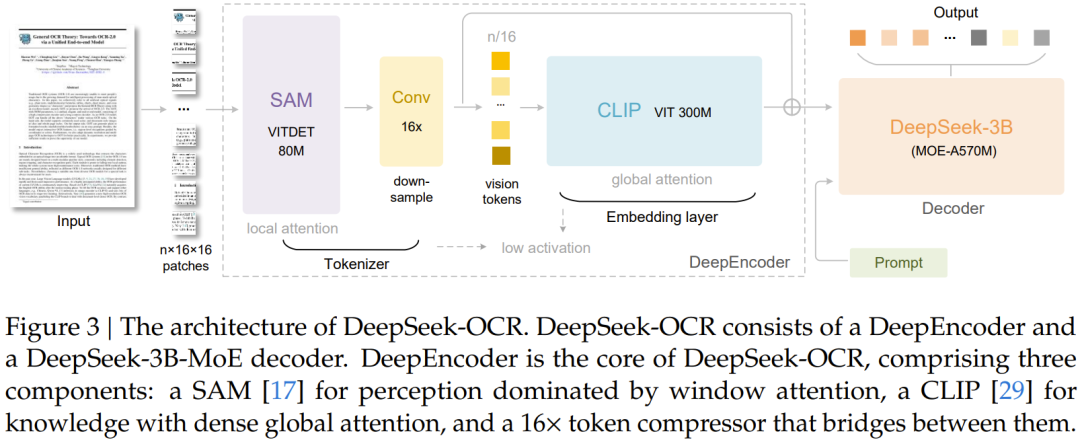
該模型主要由 DeepEncoder 和 DeepSeek3B-MoE-A570M 解碼器兩大核心組件構成。其中 DeepEncoder 作為核心引擎,既能保持高分辨率輸入下的低激活狀態,又能實現高壓縮比,從而生成數量適中的視覺 token。
實驗數據顯示,當文本 token 數量在視覺 token 的 10 倍以內(即壓縮率 <10×)時,模型的解碼(OCR)精度可達 97%;即使在壓縮率達到 20× 的情況下,OCR 準確率仍保持在約 60%。
這一結果顯示出該方法在長上下文壓縮和 LLM 的記憶遺忘機制等研究方向上具有相當潛力。
此外,DeepSeek-OCR 還展現出很高的實用價值。在 OmniDocBench 基準測試中,它僅使用 100 個視覺 token 就超過了 GOT-OCR2.0(每頁 256 個 token) 的表現;同時,使用不到 800 個視覺 token 就優於 MinerU2.0(平均每頁超過 6000 個 token)。在實際生產環境中,單張 A100-40G GPU 每天可生成超過 20 萬頁(200k+) 的 LLM/VLM 訓練數據。
DeepSeek 探索的方法概括起來就是:利用視覺模態作為文本信息的高效壓縮媒介。
簡而言之,一張包含文檔文本的圖像可以用比等效文本少得多的 Token 來表示豐富的信息,這表明:通過視覺 Token 進行光學壓縮可以實現高得多的壓縮率。
基於這一洞見,DeepSeek 從以 LLM 為中心的視角重新審視了視覺語言模型 (VLM),其中,他們的研究重點是:視覺編碼器如何提升 LLM 處理文本信息的效率,而非人類已擅長的基本視覺問答 (VQA) 任務。DeepSeek 表示,OCR 任務作為連接視覺和語言的中間模態,為這種視覺 - 文本壓縮範式提供了理想的試驗平台,因為它在視覺和文本表示之間建立了自然的壓縮 - 解壓縮映射,同時提供了可量化的評估指標。
鑑於此,DeepSeek-OCR 便由此而生。這是一個為實現高效視覺 - 文本壓縮而設計的 VLM。
如圖所示,DeepSeek-OCR 採用了一個統一的端到端 VLM 架構,由一個編碼器和一個解碼器組成。
DeepSeek-OCR 的創新架構不僅實現了高效的視覺-文本壓縮,更在實際應用中展現出強大的性能潛力。
這一模型的核心突破在於其獨特的雙組件設計:DeepEncoder編碼器和MoE解碼器。
在編碼器層面,DeepSeek創造性地將SAM-base的局部感知能力與CLIP-large的全局理解優勢相結合。就像一位經驗豐富的古籍修復師,它既能用"顯微鏡"精準識別每個字符的細節(窗口注意力),又能用"廣角鏡"把握整篇文檔的版式結構(全局注意力)。特別值得注意的是其創新的16倍下采樣機制——這相當於將一本300頁的書籍壓縮到20頁的體量,卻仍能保留97%的關鍵信息。
而MoE解碼器採用的混合專家機制猶如一個專業翻譯團隊:面對不同語種、不同版式的文檔時,系統會自動激活最擅長的6位"專家"協同工作。這種動態資源調配使得3B參數的大模型在實際運行時僅需570M參數的計算開銷,在A100顯卡上就能實現每天20萬頁的處理效率——相當於100名專業錄入員的工作量。
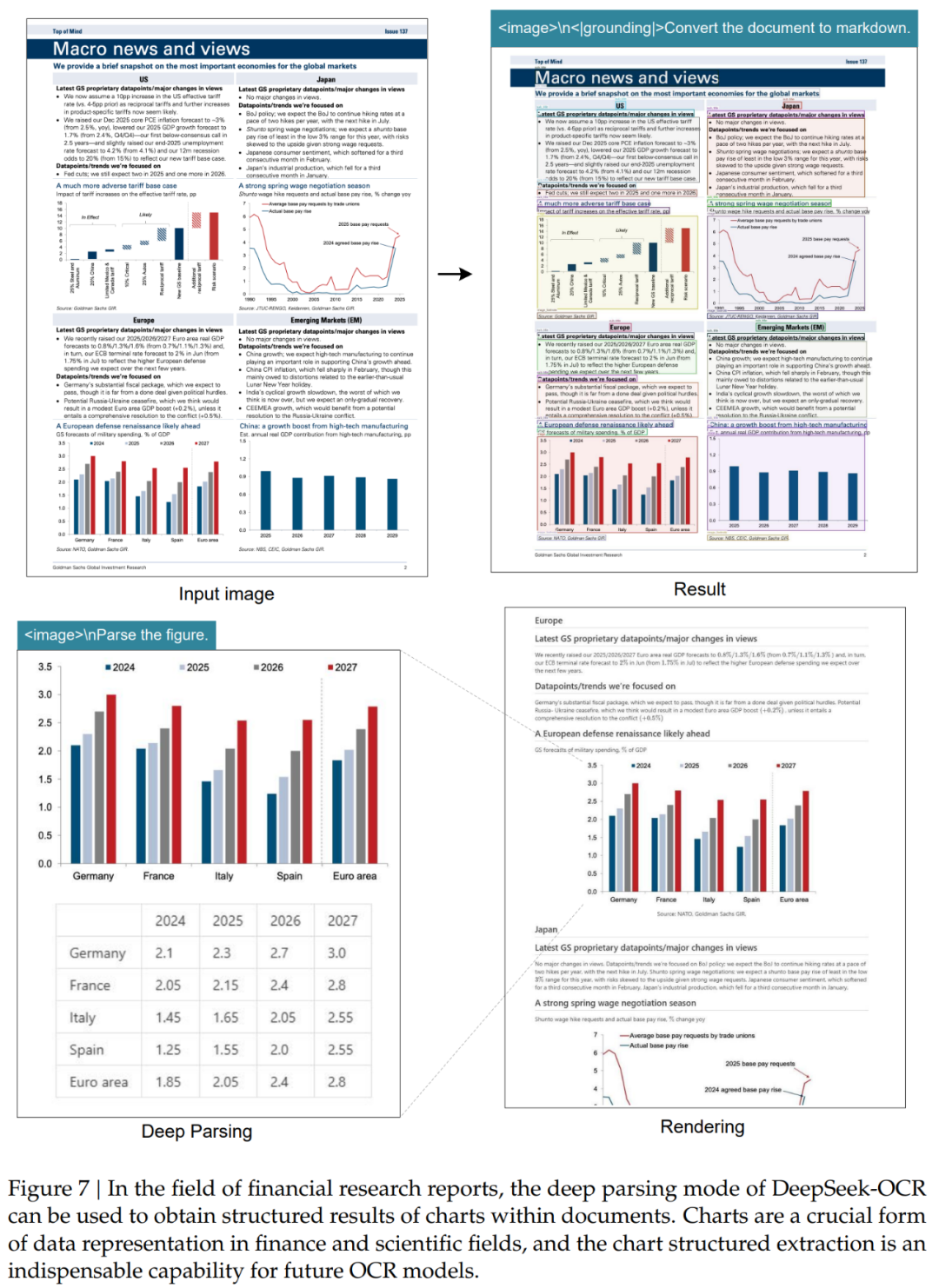
在實際測試中,DeepSeek-OCR 展現了驚人的適應性:
對於簡單的PPT文檔,僅需64個視覺token就能準確還原內容,識別速度堪比人類掃視;
處理複雜的學術論文時,400個token即可完整保留數學公式、化學方程式等專業符號;
在多語言混合文檔測試中,模型成功識別出阿拉伯語與僧伽羅語等特殊文字;
此外,DeepSeek-OCR 還具備一定程度的通用圖像理解能力。

這也意味着DeepSeek-OCR存在廣泛應用潛力,在金融領域,它可以將厚厚的財報瞬間轉為結構化數據;在醫療行業,能快速數字化歷史病歷檔案;對出版機構而言,古籍數字化效率將提升數十倍。更值得關注的是,該模型展現出的"視覺記憶"特性,為突破大語言模型的上下文長度限制提供了全新思路。