美團發佈並開源視頻生成模型:部分參數比肩谷歌最先進模型Veo3
史岱君

10月27日消息,美團LongCat團隊今日發佈並開源LongCat-Video視頻生成模型,以統一模型在文生、圖生視頻基礎任務上達到開源SOTA(最先進水平)。
不同於以往針對單一任務訓練的模型,LongCat-Video通過多任務聯合訓練機制,在同一框架內即可處理零幀、單幀及多幀條件輸入。

此外,LongCat-Video重點突破了長視頻生成難題,原生支持輸出5分鐘級別的視頻。相比常見模型在長時序生成中易出現的畫面漂移、色彩偏移等問題,該模型通過在視頻續寫任務上的原生預訓練,保持了較高的時間一致性與視覺穩定性。
近年來,“世界模型”被業界認為是通往下一代人工智能的核心方向。它能在時空維度上建模物理規律與場景邏輯,使AI具備理解、預測甚至重構現實世界的能力。
在這一背景下,視頻生成模型被視為構建“世界模型”的關鍵路徑。通過視頻生成任務壓縮幾何、語義與物理知識,AI可以在數字空間中模擬真實世界的運行過程。
美團LongCat團隊表示,LongCat-Video的推出是公司邁向這一目標的關鍵一步。未來,該模型將與自動駕駛、具身智能等業務相結合,為美團在連接“原子世界”和“比特世界”方面提供技術支撐。

文生視頻任務中,LongCat-Video可以根據提示詞準確還原不少腦洞大開的畫面
據介紹,LongCat-Video可生成720p分辨率、30幀率的高清視頻,其突出特點在於能夠原生生成長達5分鐘的連貫視頻內容。模型通過視頻續寫預訓練、塊稀疏注意力等機制,旨在解決長視頻生成中常見的畫面斷裂、質量下降等問題,保持時序一致性與運動合理性。
在效率方面,針對高分辨率、高幀率視頻生成的計算瓶頸,LongCat-Video通過“二階段粗到精生成(C2F)+ 塊稀疏注意力(BSA)+ 模型蒸餾”三重優化,視頻推理速度提升至10.1倍,實現效率與質量的最優平衡。

LongCat-Video視頻生成模型視頻推理速度提升至10.1倍
在內部評測體系中,美團構建了一套覆蓋文本生成視頻與圖像生成視頻兩大核心任務的基準,評估維度包括文本對齊、視覺質量、運動質量與總體表現,並在圖生視頻任務中額外增加了圖像一致性指標。
為確保評測的科學性,團隊採用人工與自動雙軌評估機制,其中人工評價分為絕對打分與相對偏好兩種方式,所有樣本均由多名標註員獨立評分,最終通過加權平均得出結果。
自動評測部分則由內部訓練的多模態“判官模型”完成,與人工結果的相關性高達0.92,保證了客觀性。
據發佈的評測結果顯示,LongCat-Video在文生視頻任務的四個核心指標中,視覺質量得分幾乎與谷歌的Veo3持平,整體質量超越了PixVerse-V5和國內領先的開源模型Wan2.2。
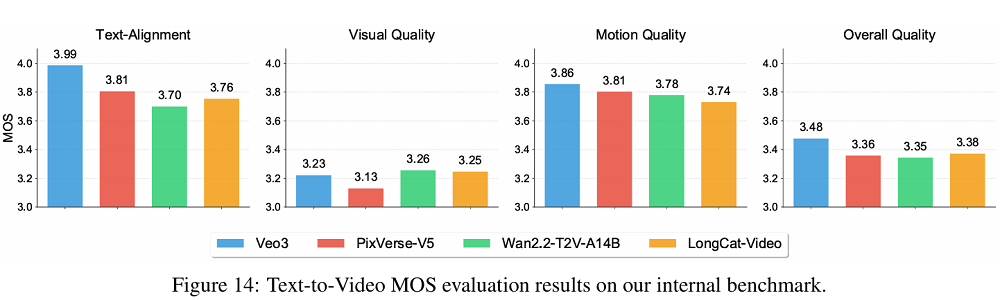
在運動質量方面,LongCat-Video生成的視頻動作流暢、鏡頭移動自然,展現出較強的物理合理性。在文本對齊度上,LongCat-Video表現略差於Veo3。
在圖生視頻任務中,LongCat-Video畫面細節豐富、風格真實,但在圖像一致性和動作連貫性上仍有改進空間。技術報告認為,模型在處理高精度參考幀時對細節的保持較為謹慎,這在視覺質量上帶來加分,卻略微影響了動態平滑度。
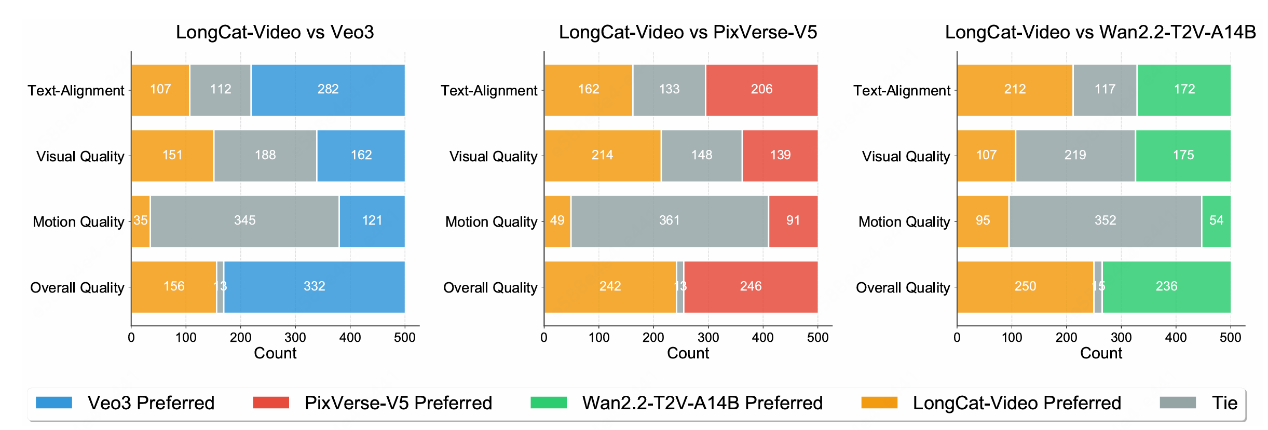
LongCat-Video視頻生成模型在文生、圖生視頻基礎任務上達到開源SOTA
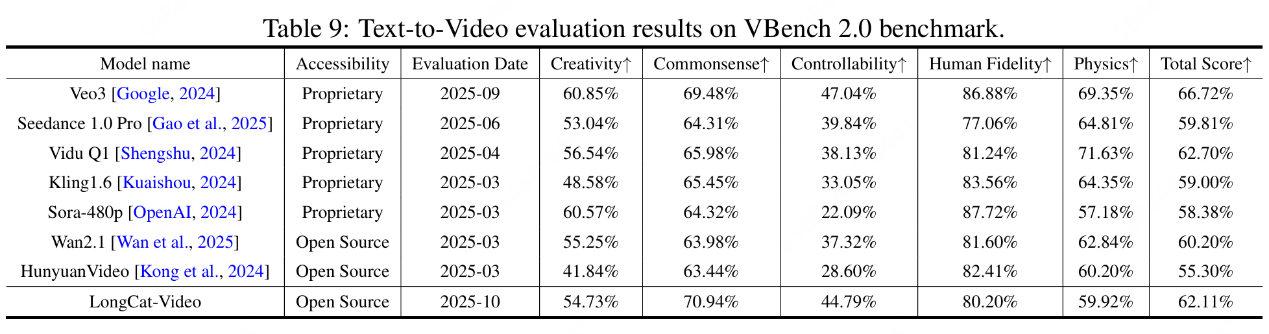
在公開評測平台VBench 2.0上,LongCat-Video在“常識理解”一項中以70.94%的得分位居所有開源模型第一,總分達到62.11%,僅次於谷歌Veo 3與生數Vidu Q1等商用閉源模型。
作為構建"世界模型"的技術嘗試,LongCat-Video未來或可應用於自動駕駛模擬、具身智能等需要長時序建模的場景。該模型的發佈標誌着美團在視頻生成與物理世界模擬領域邁出重要一步。
本文系觀察者網獨家稿件,未經授權,不得轉載。