美團正式上線LongCat App,可體驗語音通話等新功能
史岱君

11月3日消息,美團LongCat團隊今日宣佈,LongCat-Flash 系列大模型再升級,正式發佈全新家族成員——LongCat-Flash-Omni,並開源。
目前,新App已支持聯網搜索、語音通話等功能,視頻通話等功能會稍後上線;Web端則增加圖片、文件上傳和語音通話等功能。
iOS用户可直接在APP Store中搜索“LongCat”獲取。
在此之前,LongCat僅通過官網(https://longcat.ai/)來為C端用户提供大模型的相關能力。
網頁版
我們迅速下載該APP測試了一下,發現該模型最大的亮點,那就是“快”!(天下武功,唯快不破)
該模型總參數560B,激活參數僅27B,繼承了LongCat-Flash系列“快”的基因,使其在保持龐大知識容量的同時,實現了極高的推理效率。
我們發現,從輸入指令到生成token的時間間隔非常短暫,整個過程相當絲滑,小編感覺比豆包通義及微信元寶的反應速度都更快一些。
據悉,在當前主流旗艦模型的性能標準和參數規模下,這是首個能夠實現全模態即時交互的開源模型,它能同時處理文本、圖像、音頻、視頻,而且還能即時進行音視頻交互。
據官方介紹,LongCat-Flash-Omni以LongCat-Flash系列的高效架構設計為基礎(Shortcut-Connected MoE,含零計算專家),集成了高效多模態感知模塊與語音重建模塊,在總參數 5600 億(激活參數 270 億)的龐大參數規模下,仍實現低延遲的即時音視頻交互能力,為開發者的多模態應用場景提供了更高效的技術選擇。
美團採用了 Shortcut-connected MoE 架構,配合零計算專家(zero-computation experts)設計,就像高速公路上的ETC通道,讓信息處理更高效,避免了“堵車”。

更重要的是,美團還提出了早期融合訓練範式(Early-Fusion Training),能確保模型在獲得多模態能力的同時,不會在單一模態上“偏科”。
並不是先語言訓練,然後再後加上視覺或音頻能力。這就像培養全能運動員,不能因為練游泳就忘了跑步,每天都要一起練,而不是先練兩年游泳,然後再去學跑步。
這樣的一體化架構,讓這隻“龍貓”實現了完全端到端的設計:視覺與音頻編碼器作為多模態感知器,LLM 直接處理輸入並生成文本與語音 token,再通過輕量級音頻解碼器重建為自然語音波形。
此外,打開LongCat APP,從首頁可以看到,它目前支持文字/語音兩種輸入方式,並能進行語音通話(視頻通話功能正在跑步入場中),Web端還支持上傳圖片和文件。

APP端
在綜合性的全模態基準測試(如Omni-Bench, WorldSense)上,超越Qwen3-Omni、Gemini-2.5-Flash,這款模型直接達到了開源SOTA水準(開源最先進水平),而且能和閉源的Gemini-2.5-Pro相媲美。 即使單拉出來文本、圖像、音頻、視頻等各項模態能力,它也依舊能打(單項能力均位居開源模型前列),真正實現了“全模態不降智”。
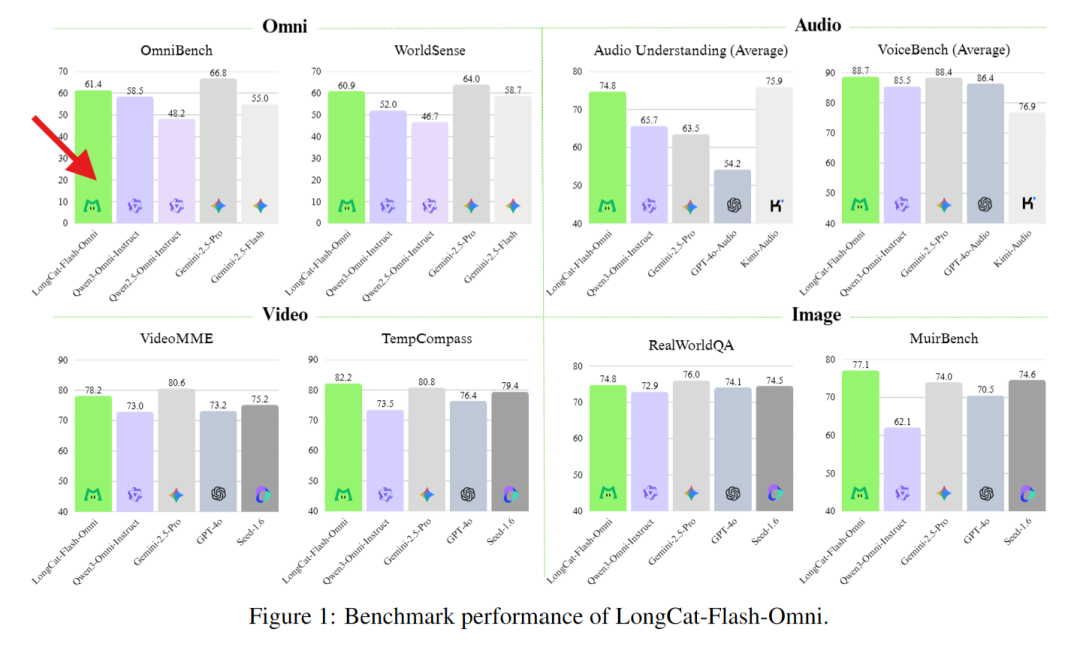
文本:LongCat-Flash-Omni 延續了該系列卓越的文本基礎能力,且在多領域均呈現領先性能。相較於 LongCat-Flash 系列早期版本,該模型不僅未出現文本能力的衰減,反而在部分領域實現了性能提升。這一結果不僅印證了該團隊訓練策略的有效性,更凸顯出全模態模型訓練中不同模態間的潛在協同價值。
圖像理解:LongCat-Flash-Omni 的性能(RealWorldQA 74.8分)與閉源全模態模型 Gemini-2.5-Pro 相當,且優於開源模型 Qwen3-Omni;多圖像任務優勢尤為顯著,核心得益於高質量交織圖文、多圖像及視頻數據集上的訓練成果。
音頻能力:從自動語音識別(ASR)、文本到語音(TTS)、語音續寫維度進行評估,Instruct Model 層面表現突出:ASR 在 LibriSpeech、AISHELL-1 等數據集上優於 Gemini-2.5-Pro;語音到文本翻譯(S2TT)在 CoVost2 表現強勁;音頻理解在 TUT2017、Nonspeech7k 等任務達當前最優;音頻到文本對話在 OpenAudioBench、VoiceBench 表現優異,即時音視頻交互評分接近閉源模型,類人性指標優於 GPT-4o,實現基礎能力到實用交互的高效轉化。
視頻理解:LongCat-Flash-Omni 視頻到文本任務性能達當前最優,短視頻理解大幅優於現有參評模型,長視頻理解比肩 Gemini-2.5-Pro 與 Qwen3-VL,這得益於動態幀採樣、分層令牌聚合的視頻處理策略,及高效骨幹網絡對長上下文的支持。
跨模態理解:性能優於 Gemini-2.5-Flash(非思考模式),比肩 Gemini-2.5-Pro(非思考模式);尤其在真實世界音視頻理解WorldSense 基準測試上,相較其他開源全模態模型展現出顯著的性能優勢,印證其高效的多模態融合能力,是當前綜合能力領先的開源全模態模型。
端到端交互:由於目前行業內尚未有成熟的即時多模態交互評估體系,LongCat團隊構建了一套專屬的端到端評測方案,該方案由定量用户評分(250 名用户評分)與定性專家分析(10 名專家,200 個對話樣本)組成。
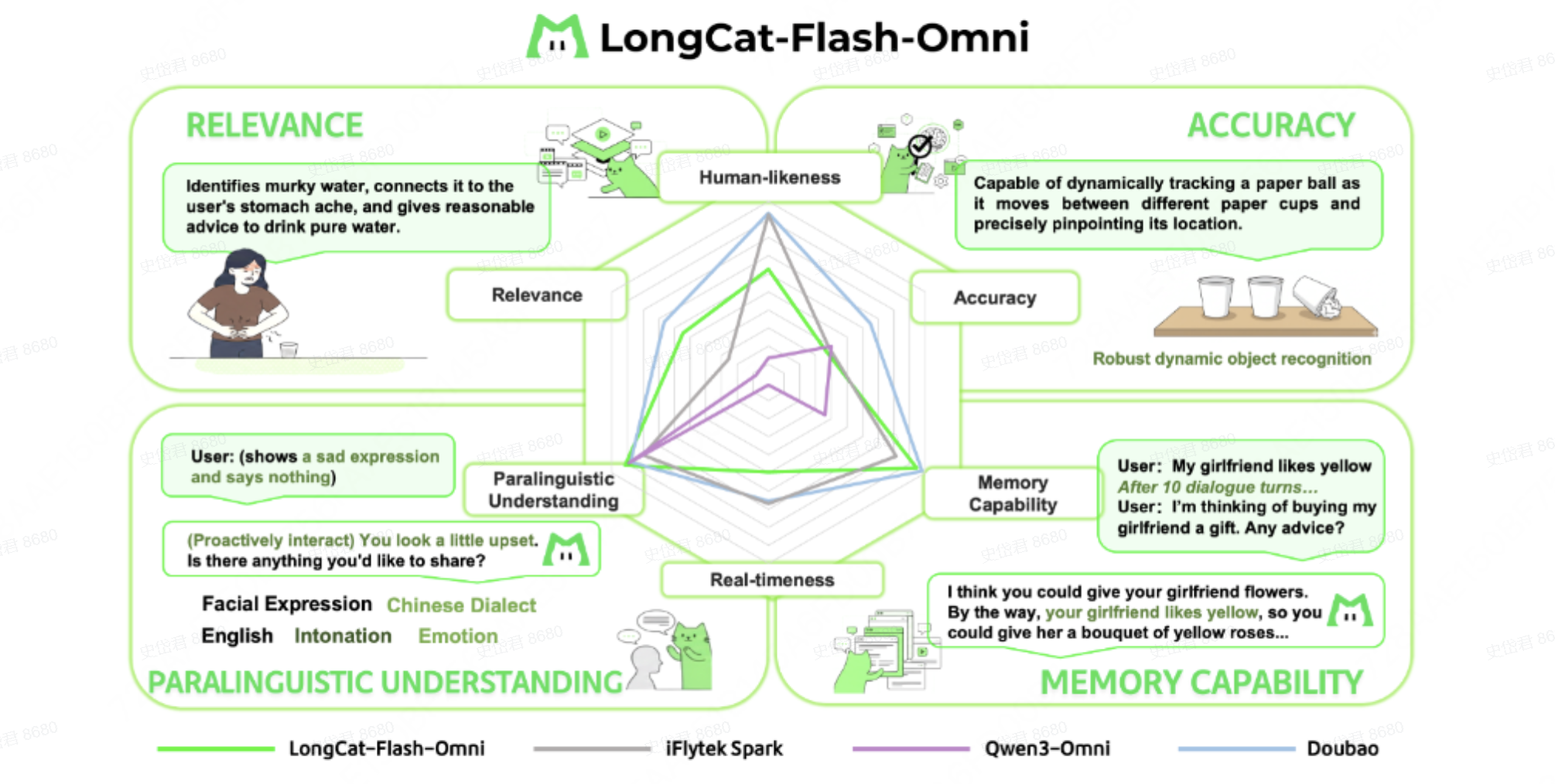
定量結果顯示:圍繞端到端交互的自然度與流暢度,LongCat-Flash-Omni 在開源模型中展現出顯著優勢 —— 其評分比當前最優開源模型 Qwen3-Omni 高出 0.56 分;定性結果顯示:LongCat-Flash-Omni 在副語言理解、相關性與記憶能力三個維度與頂級模型持平,但是在即時性、類人性與準確性三個維度仍存在差距,也將在未來工作中進一步優化。
美團這款新發布模型也引發了外國網友的熱議。其中有網友表示:“這家中國外賣公司可是大有來路,年營收高達數百億美元,員工人數也超過 Meta,是那種可以把前沿模型開發當成副業來搞的巨頭公司。”甚至點名扎克伯格:快來學着抄作業。