DeepSeek什麼來頭,何以震動全球AI圈?
在去年12月,由國內大模型公司“深度求索”開發的DeepSeek 應用推出的DeepSeek-V3在全球AI領域掀起巨大波瀾,它以極低的訓練成本,實現了與GPT-4o等頂尖模型相媲美的性能。時隔不到一個月,DeepSeek又一次震動全球AI圈。
1月27日,隨着DeepSeek推出新模型DeepSeek-R1,Deepseek應用登頂蘋果中國地區和美國地區應用商店免費App下載排行榜,在美區下載榜上超越了ChatGPT。

北京時間今日(28)凌晨,DeepSeek又發大招,宣佈開源全新的視覺多模態模型Janus-Pro-7B。Janus的表現超越了傳統的統一模型,有望成為下一代統一多模態模型的有力競爭者。
那麼,DeepSeek究竟好在哪?為什麼能以較低的成本取得“大力出奇跡”的效果?
DeepSeek:性能卓越,用户體驗佳
DeepSeek是一款由國內人工智能公司研發的大型語言模型 ,簡單來説,它就像是一個聰明又懂你的助手。它擁有強大的自然語言處理能力,能夠理解並回答你的問題,就像你和朋友聊天一樣自然流暢。
而且,DeepSeek不僅能聊天,還能幫你寫代碼、整理資料,甚至能幫你解決一些複雜的數學問題。 它背後有着複雜的算法和大量的數據支持,就像是一個經驗豐富的偵探,能從海量信息中挖掘出你想要的東西。
關於類似的大模型,最廣為人知的可能是OpenAI開發的ChatGPT。從2024年9月OpenAI發佈o1-preview到現在,僅過去不到四個月,市場上媲美甚至超越其性能的推理模型就已遍地開花。
DeepSeek之所以可以從這眾多的模型之中異軍突起,是因為它不僅率先實現了媲美OpenAI-o1模型的效果,更是將推理模型的成本壓縮到了極低。
這次DeepSeek推出的新模型DeepSeek-R1延續了其高性價比的優勢,僅用十分之一的成本就達到了GPT-o1級別的表現 。
“從大力出奇跡到小力出奇跡”
DeepSeek做了什麼算法改進?
DeepSeek模型發佈後,瞬間引發了海外AI圈眾多科技大佬的討論。
當地時間1月27日,受DeepSeek衝擊,美國人工智能主題股票遭拋售,美國芯片巨頭英偉達(NVIDIA)股價歷史性暴跌,納斯達克綜合指數大幅下跌。
英偉達高級研究科學家Jim Fan在個人社交平台上公開發表推文表示,“我們正身處這樣一個歷史時刻:一家非美國公司正在延續OpenAI最初的使命——通過真正開放的前沿研究賦能全人類。看似不合常理,但最有趣的結局往往最可能成真。”
DeepSeek持續引發業內震動,臉書母公司Meta已成立專門小組展開研究和學習。
北京郵電大學人工智能學院人機交互與認知工程實驗室主任劉偉介紹,DeepSeek最大的優勢在於它算法的改進和優化 ,它在算力上得到了節省,在輸入數據和語料庫上,不像以前要求那麼大的數據量和大的算力,這是它的優勢。以前如果説OpenAI是“大力出奇跡”,那麼DeepSeek就是“小力也可以出奇跡”——小的算力用新的方法也可以出奇跡。

△DeepSeek R1 API價格,圖源:DeepSeek
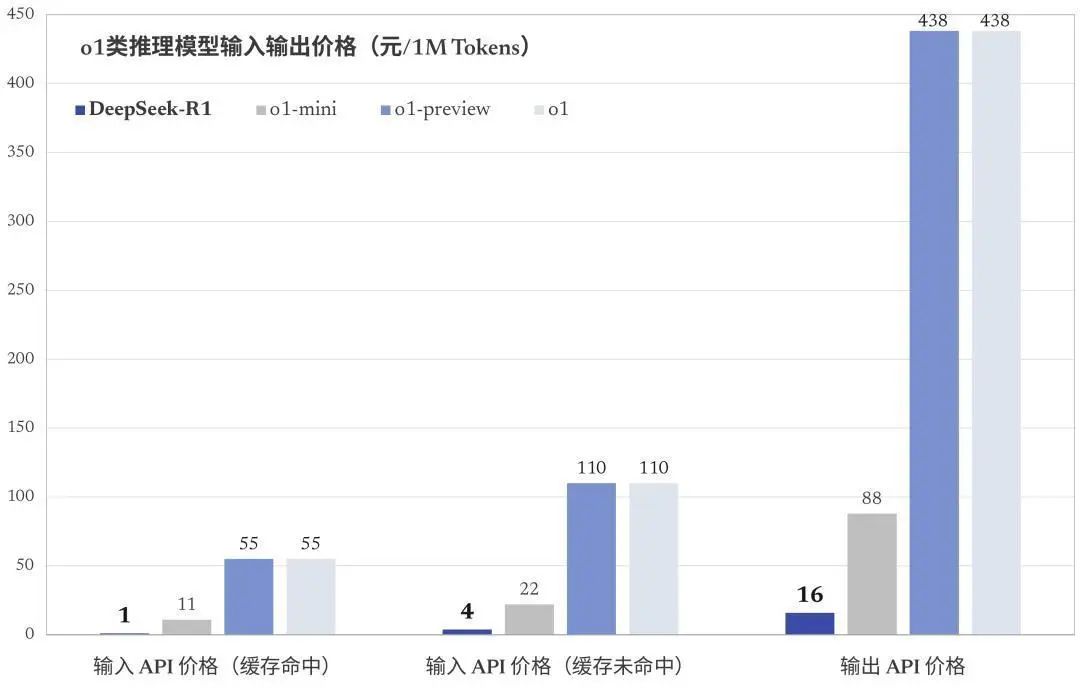
△DeepSeek R1模型與o1類推理模型輸入輸出價格對比,圖源:DeepSeek
在南京大學人工智能學院教授俞揚看來,DeepSeek站在前人的基礎上,在算法上進行了相應的優化,使得訓練成本得到大幅降低。
俞揚表示,OpenAI最初在做ChatGPT的時候,使用了需要使用大量機器的強化學習技術,但後來的研究者們發現,可以針對語言模型設計出更簡單的算法,這樣訓練強化學習時大概可節省3/4的機器。
在DeepSeek的公佈的技術方案中,它的強化學習也使用了這種簡化方案,這就使得技術上有很多可改進的地方。
開源是否是未來的發展方向?
此外,值得關注的是,DeepSeek採用了完全開源策略 。
曾經OpenAI創立的初衷,也是作為一家非營利組織,希望“以最有可能造福全人類的方式推進數字智能發展,而不受產生財務回報需求的限制”。然而,OpenAI在GPT-3發佈之後限制了對模型的訪問權限,僅通過API提供服務,在GPT-4發佈之後更是隱藏了其訓練數據和模型權重、完全走向了“閉源”。
DeepSeek的完全開源策略不僅降低了用户的使用門檻,還促進了AI開發者社區的協作生態。 通過開源,DeepSeek吸引了大量開發者和研究人員的關注,他們可以在GitHub等平台上自由獲取和修改模型代碼,共同推動AI技術的發展。
英偉達AI科學家Jim Fan稱讚DeepSeek是“真正開放的前沿研究,賦能所有人”。
國內的某大模型創業企業的CEO陳里奧告訴記者,開源的好處是顯而易見的。這種開放式的創新模式可以激發更多的創意和靈感,推動AI技術的不斷進步。
陳里奧表示,大模型目前還是屬於技術早期,目前在生文、生圖上做得多一些。高精準的邏輯計算、數學、編程類工作,還沒有完全在大模型層面完成。但也正是因為處在技術早期,大家一起貢獻才能讓行業發展得更快。
當然,開源也面臨着一些挑戰和問題。 例如,如何保護知識產權、如何維護開源社區的秩序和穩定等。
俞揚表示,實際上開源只是一種商業模式,即使是開源的東西也是有版權的,所以所謂的開源和閉源之爭,更多是商業模式之間的問題——哪一種商業模式可能在這種特定的場景、特定的時代中更有效一些。
有人把DeepSeek的成功歸功於這是一個關於中國技術理想主義的故事,也有不少外國人將之比喻為“神秘的東方力量”。但放在整個AI大模型的產業裏看,或許DeepSeek的成功代表了大模型的一種全新發展方向。
劉偉表示,現在大模型的發展正在發生一些變化,這個變化是關於它是否完全根據算力的大小來判定模型的好壞。現在DeepSeek給大家一個啓示——雖然DeepSeek算力不高,數據可能也不是很多,但通過算法的優化可以做得更好。
記者/馮爍